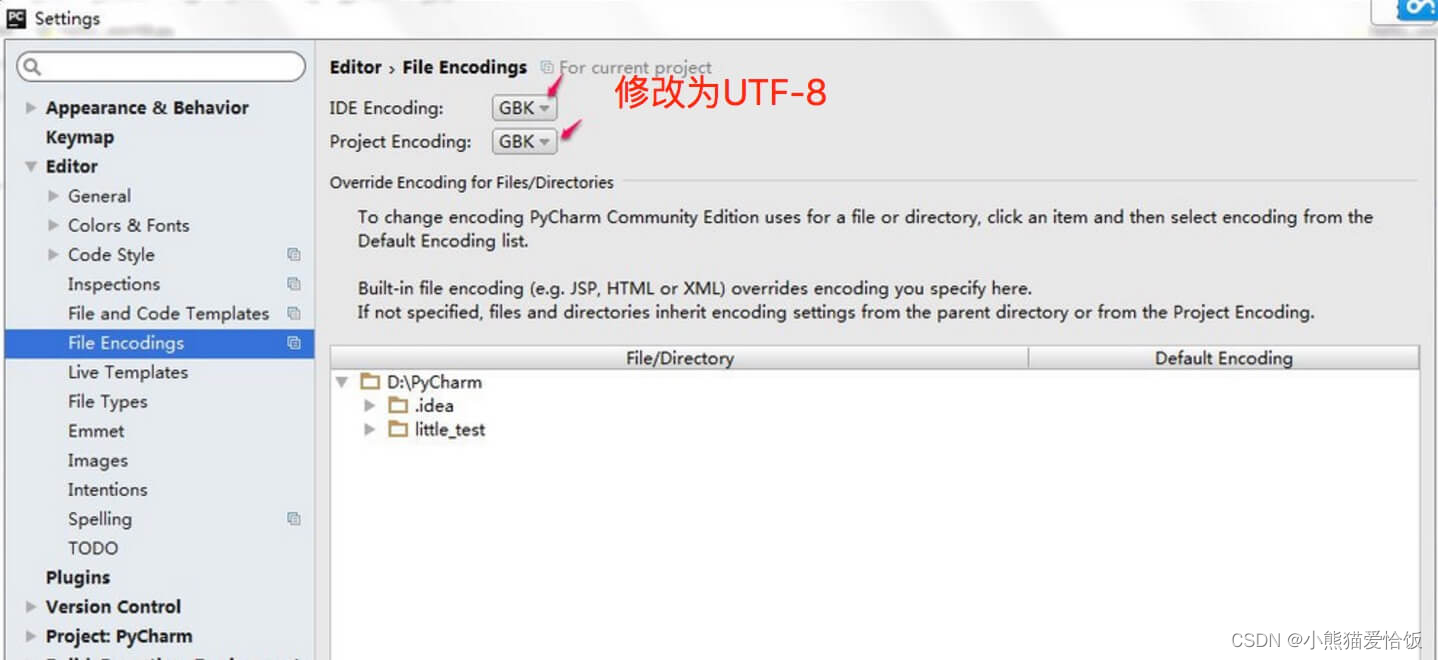
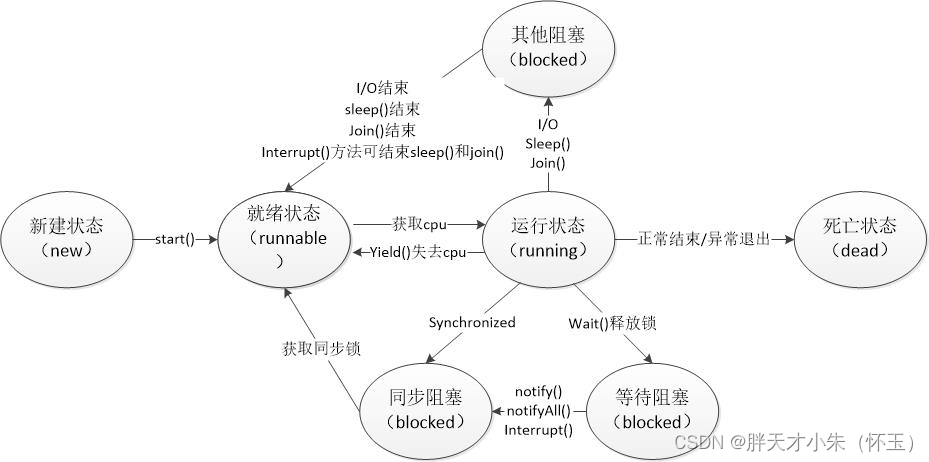
Set集合的特点:无下标,无序(新增顺序和遍历顺序不一致,新增顺序不影响遍历顺序,而且有一个固定顺序),去重(不允许重复记录)
public class TestOne {
public static void main(String[] args) {
// Set集合的特点:无下标,无序(新增顺序和遍历顺序不一致,新增顺序不影响遍历顺序,而且有一个固定顺序),去重(不允许重复记录)
// Set接口没有独有方法
Set set = new HashSet();
set.add("Jerry");//添加多个元素
set.add("June");
set.add("Tom");
set.add("Mary");
System.out.println(set); //新增顺序不影响遍历顺序,而且有一个固定顺序
set.add("Tom");
set.add("Tom");
set.add("Tom");
System.out.println(set); // 去重,同一个元素只能记录一次
}
}HashSet()的底层源码是hashMap
HashSet()里放东西,就是往hashMap里放东西
hashMap底层用一个链表数组存储元素,那HashSet()也是往这个链表数组里存元素。
Set接口实现类的底层都是Map接口的实现类
Map是键值对集合
link的list那个节点,它有preview指向上一个节点,有next指向下一个节点。所以link的list,叫双向链表
HashSet()里面的hashMap里的node就只有next。所以它是个单项链表。
hashMap底层用什么实现数这个元素?装元素?
它是个数组,但它数组里的元素是一个链表,所以那个玩意儿叫链表数组。
往数组里边儿放东西,最重要的一个要素是什么呢?如果想把一个元素存在数组里,
必须要知道什么东西?
就是下标。
数组名加访问下标。
只要拿到下标,就能往里放元素
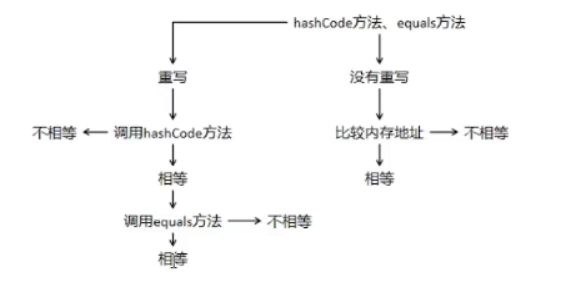
HashSet去重原理
把自己的数新增到数组里,下标怎么去确定?
1.首先调用元素的Hash Code方法,获取哈希码。
利用一个算法将哈希码经过计算变成二次哈希码。
只要是个对象,就有Hash Code,
Hash Code这个方法它返回当前对象内存地址经过哈希算法计算之后的一个整数码值。
这个整数码值叫哈希码。
2.利用二次哈希码配合一个算法,计算当前元素在数组中的下标。
3. 如何这个下标处无元素,就将元素放到数组中。
如何这个下标处有元素,我们就需要做一个判断,
调用equals方法判断原元素和新元素是否相等,如果我们发现
方法返回true意味着新元素跟原元素相等,则不执行新增操作。
当equals方法返回FALSE的时候,我们就必须要把新元素放到集合里
将新元素链接到原元素的next属性上,然后拿个链表指向它
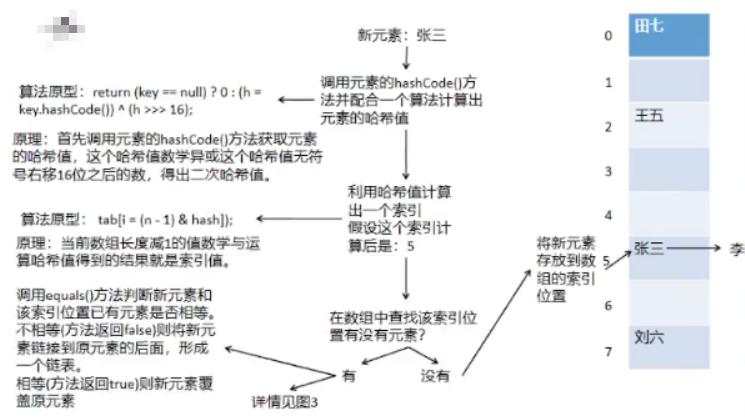
新元素不在数组里,但在集合里的原因。
如果取数据,可以把取看作是遍历。在遍历这个结构的时候,
首先遍历数组,拿下标去访问第一个元素。
但是和以往遍历数组不同的是,拿到第一个元素之后,看到第一个元素,不会直接跳到第二个元素。
看到第一个元素之后,要看一看第一个元素的next的属性。
如果next属性为空,就去看下一个元素。
如果next属性不为空,就会把next属性返回,然后再看next的next是不是为null 如果你的next的next为null,那继续看下一个元素,如果next的next不是null那继续看next。
它在获取元素的时候,会先遍历数组。然后每一个数组元素都把你当成链表去遍历。
下标是Hash Code算出来的,
Hash Code是这个对象的内存地址
内存地址是固定的,不管是先AddAdd的还是后add的,Hash Code都是一样的,算出来的下标就是一样的,遍历的顺序也就是一样的
这个数组需要扩容吗?
数组满了就往链表上放元素,理论上链表没有元素限制,
链表结构,遍历的效率低,频繁存取的效率高。而数组这种结构的特点遍历的效率高,频繁存取的效率低。
数组是需要扩容的
当我们的同一个元素在用同样的算法算下标的时候。数组长度不一样,它算出来的下标就会不一样。
在数组扩容之后,遍历顺序就有可能会变