《Caffeine(Java顶级缓存组件)二》
提示: 本材料只做个人学习参考,不作为系统的学习流程,请注意识别!!!
《Caffeine(Java顶级缓存组件)》
- 《Caffeine(Java顶级缓存组件)二》
- 8. 缓存驱逐算法
- 8.1 FIFO(First Input First Output) 先进先出缓存算法
- 8.2 LRU(The Least Recently Used)最近最久未使用缓存算法
- 8.3 LFU(Least Frequently Used)最近最少使用缓存算法
- 8.4 TinyLFU算法
- 8.5 W-TinyLFU(Window TinyLFU)算法
- 9. Caffeine数据存储结构
- 9.1 Cache子类
- 9.2 Node类
- 10. 缓存数据存储源码分析
- 10.1 put()方法
- 10.2 AddTask任务类
- 11. 频次记录源码分析
- 12. 缓存驱逐源码分析
- 13. 时间轮(TimerWheel)
8. 缓存驱逐算法
如果要考虑数据的缓存,实际上有两个最为核心的话题:一个就是缓存数据的命中率(命中性能越高,缓存的性能就越好),另外一个就是缓存的驱逐,这个驱逐有两点:一个就是驱逐的算法,另外一个就是驱逐具体实现。
缓存技术发展的最初目的就是为了解决数据的读取性能,但是在缓存之中如果保存了过多的数据项,则最终一定会产生内存溢出问题,所以就必须设计一种数据的缓存算法,在空间不足的时候能够进行数据的驱逐,给新数据的缓存增加可用的空间,而为了实现这样的机制,提供有三种缓存算法:FIFO、LRU、LFU(其内部又扩展了TinyLFU算法与W-TinyLFU算法)
8.1 FIFO(First Input First Output) 先进先出缓存算法
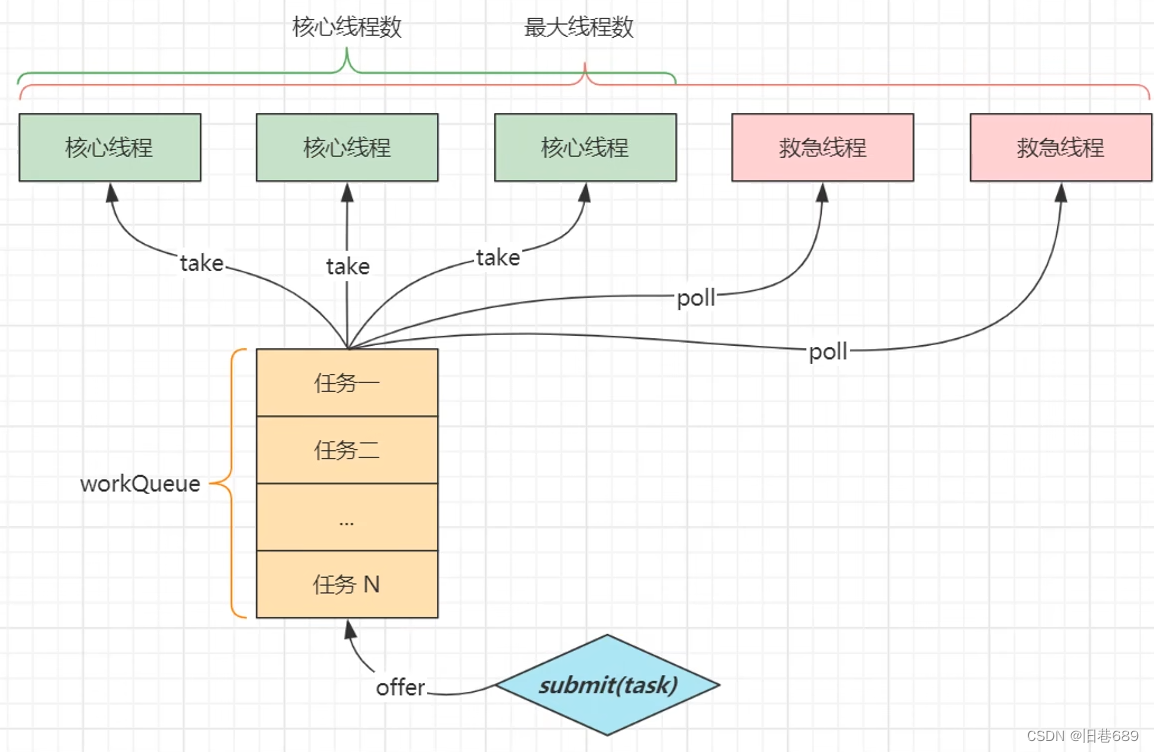
按照传统的队列的设计模式采用的是先进先出的处理算法,最早保存的数据最早出去,采用队列的形式保存所有的缓存数据,而后当缓存数据存储满了,则会将最初缓存的数据项进行清除。
这是一种早期使用的缓存算法,采用队列的形式实现缓存的存储,实现的核心依据在于:较早保存在缓存中的数据有可能不会再使用,所以一旦缓存中的容量不足时,会通过一个指针进行队首数据的删除,以置换出新的存储空间,保存新增的缓存项。
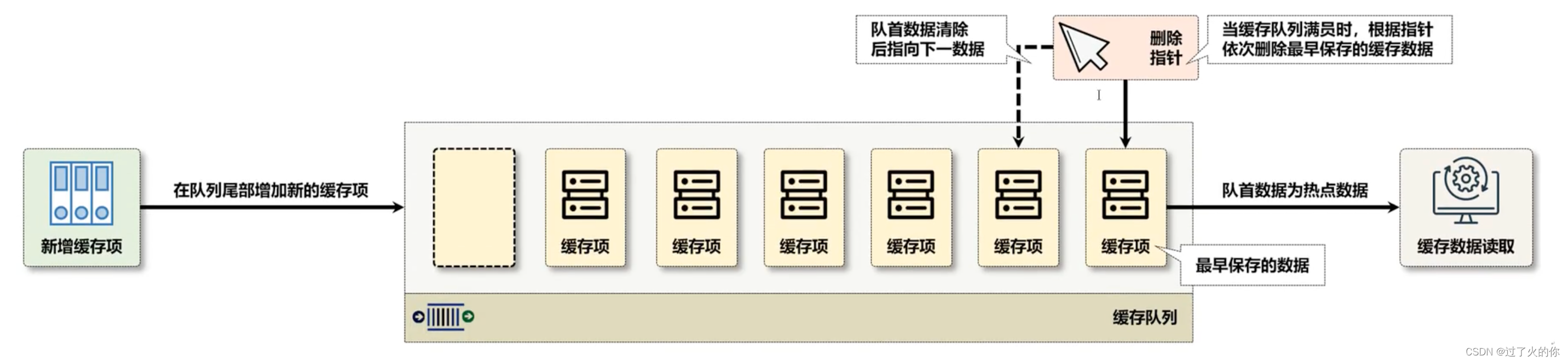
FIFO是一种实现简单的缓存算法,但是这种算法会存在有一个“缺页率”的问题,如果最早存储的缓存数据一直属于热点数据,但是由于队列长度的限制,有可能会将这个热点数据删除,而造成缓存数据丢失的问题。当缓存队列中很多热点数据被清除之后,就会增加缺页率,这样的现象被称为“Belady”(迟到)现象,而造成该现象的主要原因是在于该算法与缓存中的数据访问不相容,并且缓存命中率很低,现在已经很少使用了。
如果现在将某些热点的数据剔除了,那么当数据重新加载到缓存之中的时候,很有可能已经有几千万的用户同时发出了数据的查询指令,从而导致数据库直接崩溃。
8.2 LRU(The Least Recently Used)最近最久未使用缓存算法
针对每一个要操作的缓存项设置一些统计的信息,如果发现已经很长时间没有人去关注这个数据了,哪怕这个数据是刚刚添加到缓存之中的,那么都有可能直接被顶替掉。
该算法的主要特点不再是依据保存时间进行数据项的清除,而是通过数据最后一次访问的时间戳来进行排查,当缓存空间已经满员了,会将最久没有访问的数据进行清除。LRU算法是一种常见的缓存算法,在Redis和Memcached分布式缓存之中使用的较多。
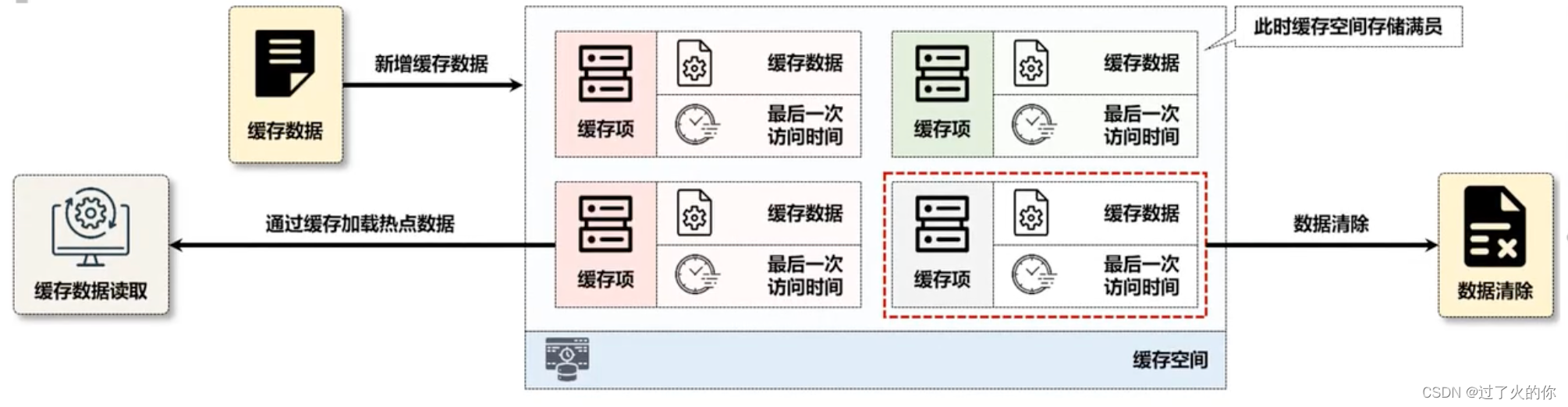
8.3 LFU(Least Frequently Used)最近最少使用缓存算法
缓存中的数据在最近一段时间内很少被访问到,那么其将来被访问的可能性也很小,这样当缓存空间已满时,最小访问频率的缓存数据将被删除,如果此时缓存中保存的数据访问计数全部为1,则不会删除缓存的数据,同时也不保存新的缓存数据。
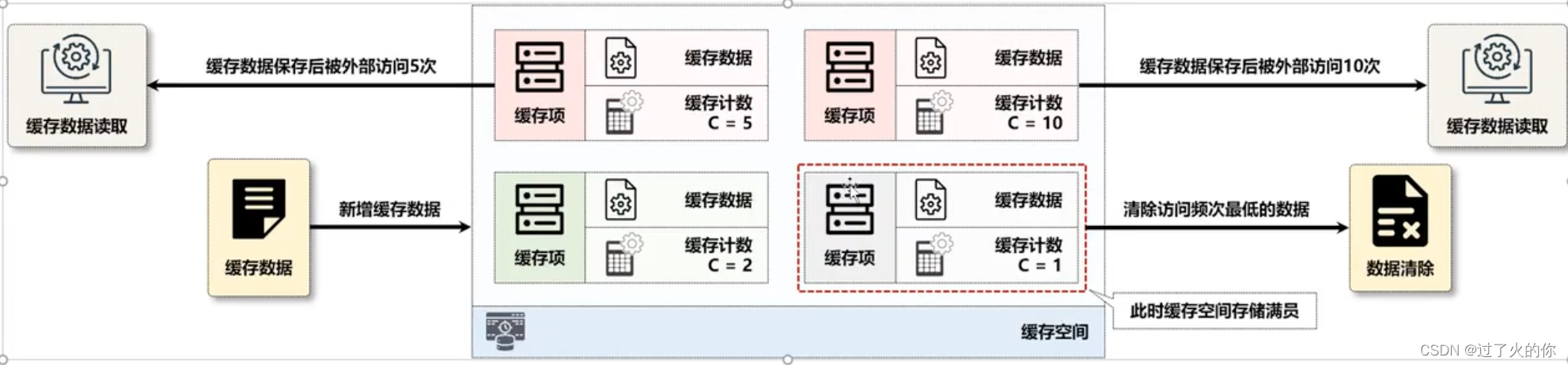
实际上以上所有采用过的缓存驱逐算法都面临一个实际的问题,如果说某些数据当时没有成为热点,而后突然在某一个时间点上又成为了一个热点,那么最终就一定会进行数据库数据的加载,从而造成整个系统不稳定的因素攀升。
8.4 TinyLFU算法
使用LFU算法可以在固定的一段时间内达到较高的命中率,但是在LFU算法中需要维持缓存记录的频率信息(每次访问都要更新),会存在有额外的开销。
由于频次的处理问题,那么在整个缓存记录空间之内,越早保存的数据,那么它的记录频次就会越高,那么这个时候就会出现新的缓存项永远无法保存的问题,哪怕某些原来的热点记录都已经不再是热点了。
由于在该算法中所有的数据都依据统计保存,所以当面对突发性的稀疏流量(Sparse Bursts)访问时会因为记录频次的问题而无法在缓存中存储。而导致业务逻辑出现偏差,所以为了解决LFU所存在的问题,就需要提供一个优化算法,这样才有了TinyLFU算法。
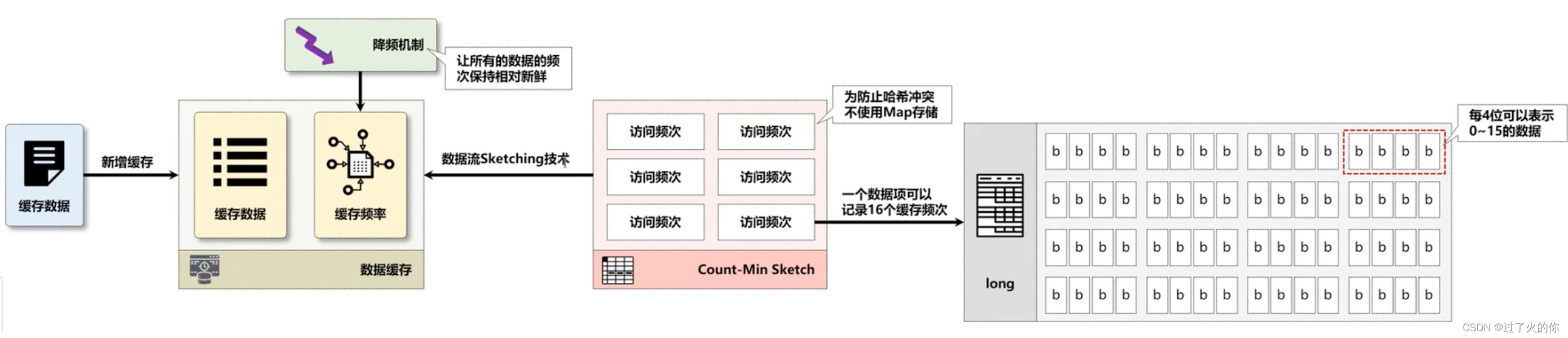
TinyLFU为了解决缓存频率信息记录空间的问题,采用了Sketching数据流技术,使用了一个Count-Min Sketch算法,==在该算法中认为数据访问15次就可以作为一个热点数据存在,而后可以按照位的方式进行统计(一个long类型可以保存64位的数据,每四位为一组,而后可以实现16个数据的统计),这样就避免采用传统的map实现统计频次的操作,从而节约了数据的体积。==而面对新的数据无法追加缓存的问题,在TinyLFU中采用了一种“保持新鲜”的机制,该机制的主要特点就是当整体的统计数据达到一个顶峰数值后,所有记录的频率都要除以2,这样已有高频次的数据就会降低频次。
TinyLFU直接解决嘞新数据和旧数据之间的缓存频次的公平设计问题,但是却没有解决某些数据又再次火爆,这个火爆程度可能只是非常短的时间间隔(5个小时左右,或者更长一点点)
8.5 W-TinyLFU(Window TinyLFU)算法
LRU算法实现较为简单,同时也表现出了较好的命中率,面对突发的稀疏流量表现的很好,可以很好的适应热点数据的访问,但是如果有些冷数据(该数据已经被缓存淘汰了)突然访问量激增,则会重新加载该数据到缓存之中,由于会存在加载完后数据再变冷的可能,所以该算法可能会造成缓存污染,但是这种稀疏流量的缓存操作确实是TinyLFU算法所缺少的,因为新的缓存数据可能还没有积攒到足够的访问频率就被剔除了,导致命中率下降,所以针对此类问题,在Caffeine中设计了W-TinyLFU(Window TinyLFU)算法。
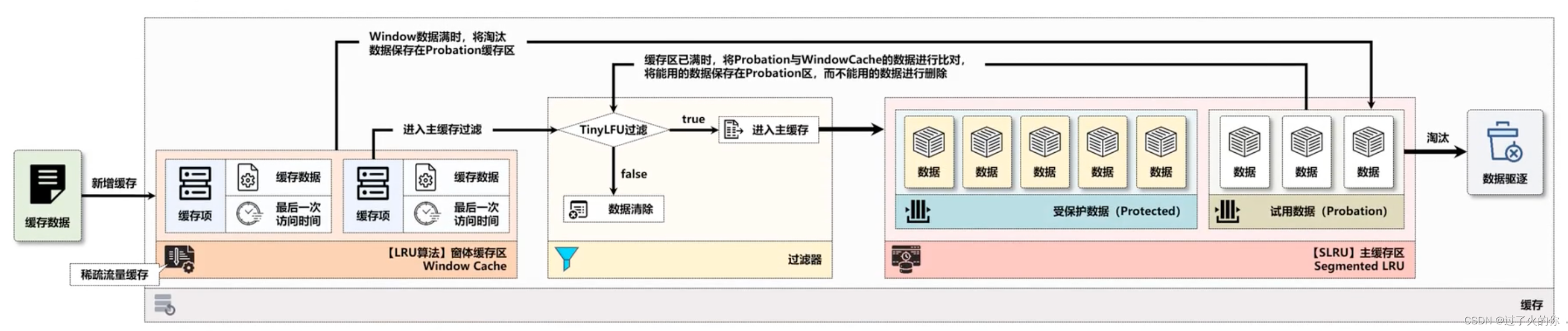
在W-TinyLFU算法之中,将整个缓存的区域分为两块,一块是Window缓存区(大小为当前缓存内存的1%),另一块是主缓存区(大小为当前缓存内存的99%),而后在主缓存区中为Protected区(大小为80%)和Provation区(大小为20%)。新增加的缓存数据全部保存在Window区域,这样就可以解决稀疏流量的缓存加载问题,当Window区域填满后,会将里面的候选缓存数据保存到主缓存区域的Probation区域内,而当Probation区域也满员后,则会通过TinyLFU过滤器进行比对,保留有价值的候选数据,而无价值的数据则直接驱逐。
传闻:某音的缓存一共设置有7个区域,这7个区域的每一个区域都是热门的数据,但是对应的是不同量级的缓存级别,每一个视频如果达到了这7个流量池,视频都会得到极大的展示。这种算法的组件肯定在外部是没有提供的,是其内部自己研发的。
9. Caffeine数据存储结构
通过之前的分析已经清除了Caffeine之中对于数据存储所使用的核心算法,那么既然清楚了算法的组成,下面就通过具体的源代码分析一下其核心的结构(只是关注其实现结构)。
9.1 Cache子类
如果想要进行结构上的分析,那么首先就要找到Cache接口,因为这个接口直接定义了所有缓存数据的操作方法,那么找到这个接口的实现子类才是关键。
interface LocalManualCache<K, V> extends Cache<K, V> {}
static class BoundedLocalManualCache<K, V> implements LocalManualCache<K, V>, Serializable {}
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef<K, V>
implements LocalCache<K, V> {
final ConcurrentHashMap<Object, Node<K, V>> data;
}
LocalManualCache是Caffeine内部提供的一个操作接口,其继承了Cache父接口,同时这个接口又提供了一个内部实现子类(BoundedLocalCache.BoundedLocalManualCache),下面观察BoundedLocalCache抽象类,观察该类中提供了一个data属性,这个属性是进行数据保存的集合。
看到ConcurrentHashMap,会联想到:
- JUC并发编程。
- 不使用long进行统计,而是使用4位的long(统计16个)。
- JUC中的延迟队列与数据缓存的实现。
- 见到Node名称,想到一些数据结构,想到Java里面提供的类集框架。
9.2 Node类
打开Node类观察其具体定义
abstract class Node<K, V> implements AccessOrder<Node<K, V>>, WriteOrder<Node<K, V>> {」
此时的Node类声明的时候没有使用public访问权限,所以其是一个包内部可以使用的结构,一个接口是进行读取顺序配置,另外一个是写入顺序配置,下面观察这两个接口定义。
AccessOrder
final class AccessOrderDeque<E extends AccessOrder<E>> extends AbstractLinkedDeque<E> {
interface AccessOrder<T extends AccessOrder<T>> {
}
}
WriteOrder
final class WriteOrderDeque<E extends WriteOrder<E>> extends AbstractLinkedDeque<E> {
interface WriteOrder<T extends WriteOrder<T>> {
}
}
AbstractLinkedDeque
abstract class AbstractLinkedDeque<E> extends AbstractCollection<E> implements LinkedDeque<E> {
通过以上的分析,可以发现Node接口最终实现了Deque(双端队列)父接口,所以在整个数据存储的时候也是按照队列的方式进行处理,至少可以在前后都能实现数据的追加。
Node类常用方法
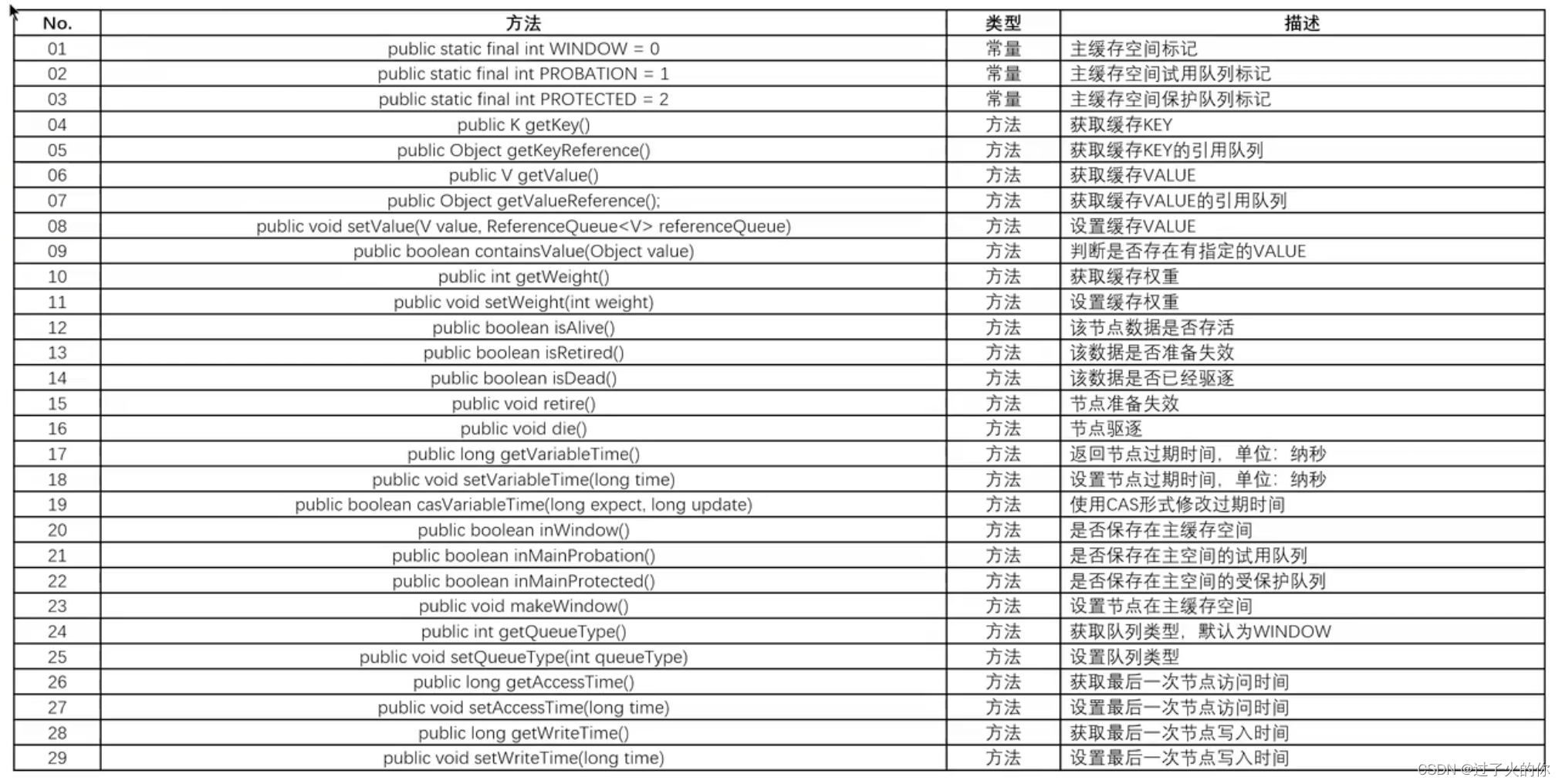
3. 第三步
打开Node类,在这个类之中可以看到里面提供了三个核心的属性项。
public static final int WINDOW = 0; //节点类型:WINDOW去节点
public static final int PROBATION = 1; //节点类型:试用区节点
public static final int PROTECTED = 2; //节点类型:保护区节点
之所以现在要求重写一个Node,就是因为Caffeine组件内部在进行缓存处理的时候,要求不同的节点保存在不同的缓存区之中,这样就可以应对稀疏流量以及访问次数的驱逐操作的实现。
Node本身属于一个抽象类,抽象类在使用的时候一定要使用子类。Node包含子类如下,包含无数种不同实现的子类,实际上每一种子类都对应着一种数据的存储方式,而考虑到与之前的联系,下面给大家介绍几个核心的子类。
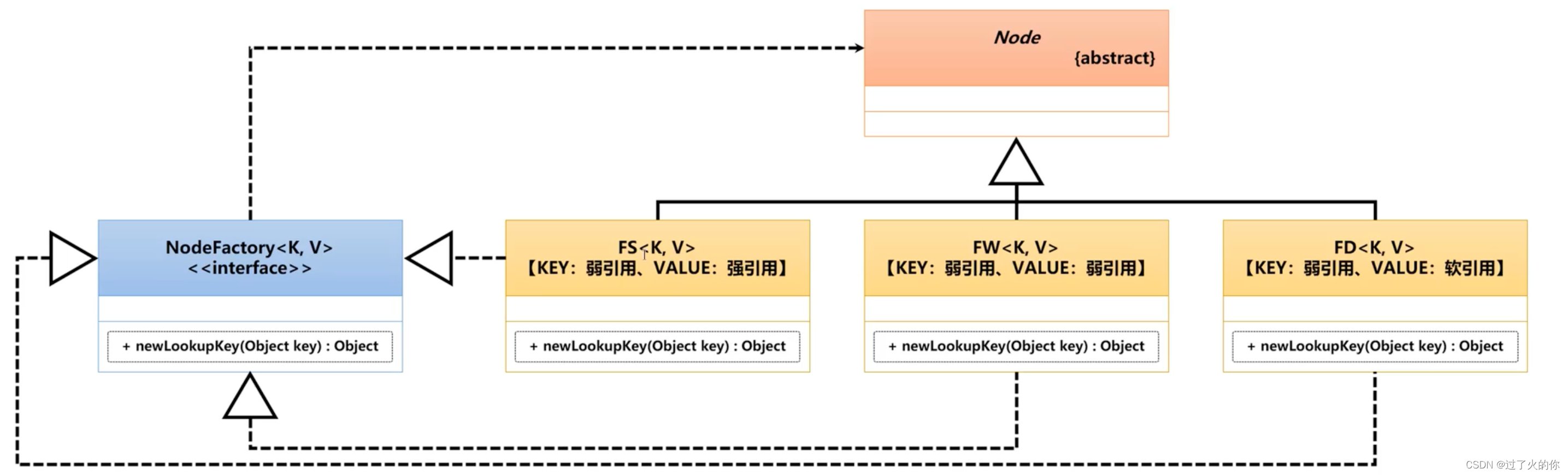
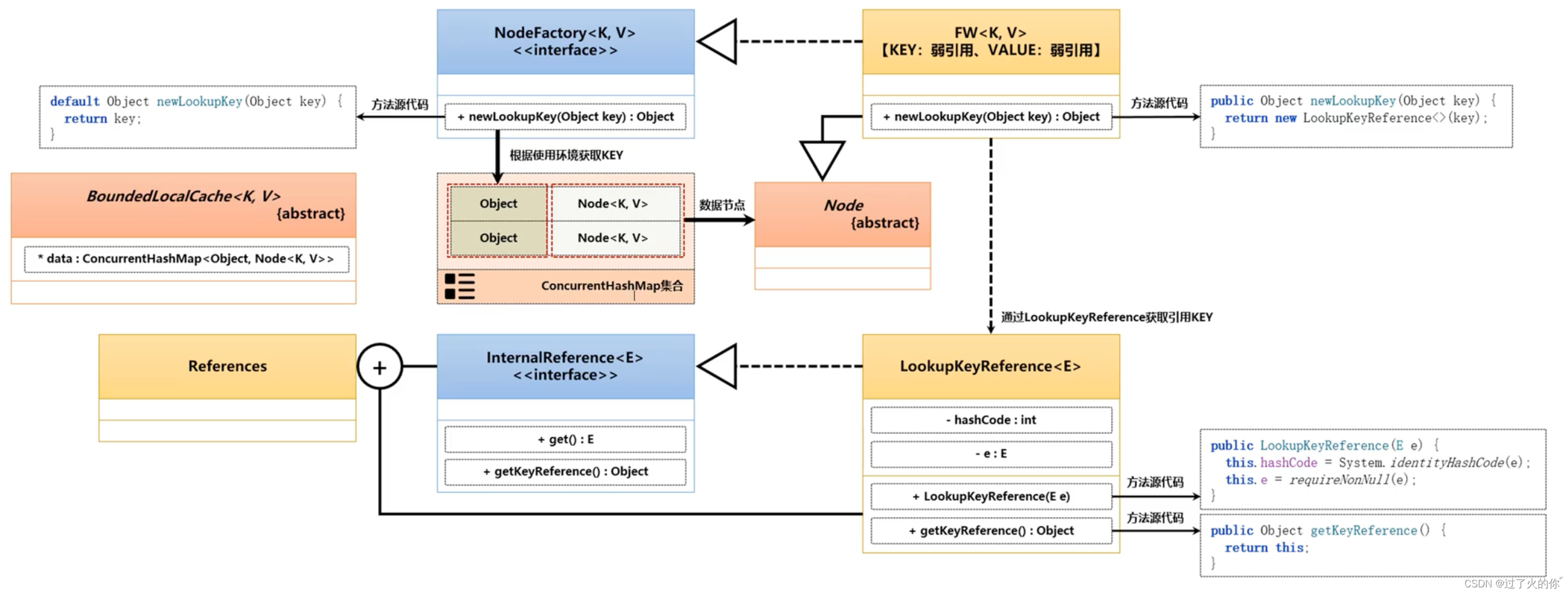
按照正常的设计思想来讲,所有的节点需要通过NodeFactory进行创建,同时这个创建是一个新的查询KEY。由于缓存会存在有更新的概念,所以是新保存还是查询已有的就需要进行统一的管理了。
下面以FW子类为例说明,观察如下的一个方法实现
public Object newLookupKey(Object key) {
return new LookupKeyReference<>(key);
}
这个方法会返回一个LookupKeyReference对象实例,观察这个类之中的核心源代码
//构造方法
public LookupKeyReference(@NonNull E e) {
this.hashCode = System.identityHashCode(e);
this.e = requireNonNull(e);
}
//get方法
@Override
public E get() {
return e;
}
观察NodeFactory接口提供的方法
default Object newLookupKey(Object key) {
return key;
}
此时可以见到的这个KEY数据就是保存在ConcurrentHashMap类里面所对应KEY的内容,也就是说保存缓存KEY的数据是一个对象,而且这个对象是由Caffeine组件提供的。
10. 缓存数据存储源码分析
10.1 put()方法
1. Cache接口中的put()方法
对于缓存操作来讲,核心话题就是数据的存储,而对于数据的存储操作,在Cache接口里面提供有put()处理方法,这个方法在存储时需要设置KEY以及VALUE,观察这个方法的定义:
/**
* Associates the {@code value} with the {@code key} in this cache. If the cache previously
* contained a value associated with the {@code key}, the old value is replaced by the new
* {@code value}.
* <p>
* Prefer {@link #get(Object, Function)} when using the conventional "if cached, return; otherwise
* create, cache and return" pattern.
*
* @param key the key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @throws NullPointerException if the specified key or value is null
*/
void put(@NonNull K key, @NonNull V value);
由于整个缓存操作过程需要对数据进行权重的处理计算,所以不允许KEY和VALUE的内容为空,如果为空就抛出异常,那么这个数据最终是如何实现存储的呢?下面我们一起分析一下源代码的实现。
2. 观察put()方法的实现类(LocalManualCache)
@Override
default void put(K key, V value) {
cache().put(key, value);
}
LocalCache<K, V> cache();
最终put()方法调用是由LocalManualCache接口来完成的,但是这个接口之中是依靠cache()方法获取了一个LocalCache对象实例,这个方法是需要由子类来实现的。
3. 分析cache()方法的子类

@Override
public BoundedLocalCache<K, V> cache() {
return cache;
}
final BoundedLocalCache<K, V> cache;
通过以上的结构分析,可以确定的是,整个存储类型的选择才是定义cache()方法的原因所在,如果想要进行具体存储分析,也是由以上的两个类型决定的,下面使用BoundedLocalCache类的结构来进行存储的分析。
4. BoundedLocalCache中的put()方法
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef<K, V>
implements LocalCache<K, V> {}
@Override
public @Nullable V put(K key, V value) {
return put(key, value, expiry(), /* notifyWriter */ true, /* onlyIfAbsent */ false);
}
观察put()方法的核心实现
@Nullable V put(K key, V value, Expiry<K, V> expiry, boolean notifyWriter, boolean onlyIfAbsent) {
requireNonNull(key);//检查KEY是否为空
requireNonNull(value);//检查VALUE是否为空
Node<K, V> node = null;//声明一个节点
long now = expirationTicker().read();//获取当前时间
int newWeight = weigher.weigh(key, value);//权重计算
for (;;) {
Node<K, V> prior = data.get(nodeFactory.newLookupKey(key));//获取节点
if (prior == null) {//节点不存在
if (node == null) {//节点为空
node = nodeFactory.newNode(key, keyReferenceQueue(),
value, valueReferenceQueue(), newWeight, now);//创建新节点
setVariableTime(node, expireAfterCreate(key, value, expiry, now));//失效配置
}
if (notifyWriter && hasWriter()) {
Node<K, V> computed = node;
prior = data.computeIfAbsent(node.getKeyReference(), k -> {
writer.write(key, value);
return computed;
});
if (prior == node) {//未存储过
afterWrite(new AddTask(node, newWeight));//数据写入
return null;//操作结束
}
} else {
prior = data.putIfAbsent(node.getKeyReference(), node);//Map集合查询数据
if (prior == null) {//未存储过
afterWrite(new AddTask(node, newWeight));//数据写入
return null;//操作结束
}
}
} else if (onlyIfAbsent) {//未关联过
// An optimistic fast path to avoid unnecessary locking
V currentValue = prior.getValue();//获取保存的VALUE数据项
if ((currentValue != null) && !hasExpired(prior, now)) {//是否失效
if (!isComputingAsync(prior)) {//是否为异步模型
tryExpireAfterRead(prior, key, currentValue, expiry(), now);//失效读取操作
setAccessTime(prior, now);//设置访问时间
}
afterRead(prior, now, /* recordHit */ false);//数据读取处理
return currentValue;//返回结果
}
}
V oldValue;//保存已经存储过的数据
long varTime;//保存时间
int oldWeight;//已有数据权重
boolean expired = false;//失效的状态
boolean mayUpdate = true;//更新的状态
boolean exceedsTolerance = false;//保存失效状态
synchronized (prior) {//同步的更新处理
if (!prior.isAlive()) {//是否还存在节点
continue;
}
oldValue = prior.getValue();//获取已有的数据
oldWeight = prior.getWeight();//获取已有的权重
if (oldValue == null) {//数据为空
varTime = expireAfterCreate(key, value, expiry, now);//失效处理
writer.delete(key, null, RemovalCause.COLLECTED);
} else if (hasExpired(prior, now)) {//判断是否失效
expired = true;
varTime = expireAfterCreate(key, value, expiry, now);//失效处理
writer.delete(key, oldValue, RemovalCause.EXPIRED);
} else if (onlyIfAbsent) {
mayUpdate = false;
varTime = expireAfterRead(prior, key, value, expiry, now);
} else {
varTime = expireAfterUpdate(prior, key, value, expiry, now);
}
if (notifyWriter && (expired || (mayUpdate && (value != oldValue)))) {
writer.write(key, value);
}
if (mayUpdate) {//判断当前更新标记
exceedsTolerance =
(expiresAfterWrite() && (now - prior.getWriteTime()) > EXPIRE_WRITE_TOLERANCE)
|| (expiresVariable()
&& Math.abs(varTime - prior.getVariableTime()) > EXPIRE_WRITE_TOLERANCE);
setWriteTime(prior, now);//写入时间
prior.setWeight(newWeight);//写入的权重
prior.setValue(value, valueReferenceQueue());//写入的数据
}
setVariableTime(prior, varTime);
setAccessTime(prior, now);
}
if (hasRemovalListener()) {
if (expired) {//存在有失效的数据
notifyRemoval(key, oldValue, RemovalCause.EXPIRED);//删除处理
} else if (oldValue == null) {
notifyRemoval(key, /* oldValue */ null, RemovalCause.COLLECTED);
} else if (mayUpdate && (value != oldValue)) {
notifyRemoval(key, oldValue, RemovalCause.REPLACED);
}
}
int weightedDifference = mayUpdate ? (newWeight - oldWeight) : 0;
if ((oldValue == null) || (weightedDifference != 0) || expired) {
afterWrite(new UpdateTask(prior, weightedDifference));//数据写入
} else if (!onlyIfAbsent && exceedsTolerance) {
afterWrite(new UpdateTask(prior, weightedDifference));//数据写入
} else {
if (mayUpdate) {
setWriteTime(prior, now);
}
afterRead(prior, now, /* recordHit */ false);
}
return expired ? null : oldValue;
}
}
10.2 AddTask任务类
观察AddTask任务类
final class AddTask implements Runnable {
final Node<K, V> node;//获取节点
final int weight;//获取权重
AddTask(Node<K, V> node, int weight) {
this.weight = weight;
this.node = node;
}
@Override
@GuardedBy("evictionLock")
@SuppressWarnings("FutureReturnValueIgnored")
public void run() {//完成数据保存的核心操作
if (evicts()) {
long weightedSize = weightedSize();//得到权重的数值
setWeightedSize(weightedSize + weight);//修改权重的数据
setWindowWeightedSize(windowWeightedSize() + weight);
node.setPolicyWeight(node.getPolicyWeight() + weight);
long maximum = maximum();
if (weightedSize >= (maximum >>> 1)) {
// Lazily initialize when close to the maximum
long capacity = isWeighted() ? data.mappingCount() : maximum;
frequencySketch().ensureCapacity(capacity);//频率的管理
}
K key = node.getKey();
if (key != null) {
frequencySketch().increment(key);//频率增加
}
setMissesInSample(missesInSample() + 1);//丢失率处理
}
// ignore out-of-order write operations
boolean isAlive;//存活状态判断
synchronized (node) {
isAlive = node.isAlive();
}
if (isAlive) {
if (expiresAfterWrite()) {
writeOrderDeque().add(node);
}
if (evicts() && (weight > windowMaximum())) {
accessOrderWindowDeque().offerFirst(node);
} else if (evicts() || expiresAfterAccess()) {
accessOrderWindowDeque().offerLast(node);
}
if (expiresVariable()) {
timerWheel().schedule(node);
}
}
// Ensure that in-flight async computation cannot expire (reset on a completion callback)
if (isComputingAsync(node)) {
synchronized (node) {
if (!Async.isReady((CompletableFuture<?>) node.getValue())) {
long expirationTime = expirationTicker().read() + ASYNC_EXPIRY;
setVariableTime(node, expirationTime);
setAccessTime(node, expirationTime);
setWriteTime(node, expirationTime);
}
}
}
}
}
}
由于在增加的时候需要考虑到数据的各项配置(节点的配置),所以Caffeine针对于数据的增加、修改及删除都提供了完整的线程控制机制,通过子线程实现这些繁琐的处理操作,所以为什么在存储数据的时候使用ConcurrentHashMap。
11. 频次记录源码分析
通过之前的分析可以发现,在进行数据增加的时候会触发一个AddTask线程进行处理,而对于数据的更新以及数据的删除也都有对应的Task处理线程类,这个时候来观察AddTask内部提供的一个处理方法。
frequencySketch().ensureCapacity(capacity);
此时的类中会调用 frequencySketch() 处理方法,这个方法返回的类型为FrequencySketch对象,这个方法是达到了容量限制存储的时候才调用的处理逻辑。
在FrequencySketch类中提供了 ensureCapacity() 方法,以进行频次数据的记录操作。
public void ensureCapacity(@NonNegative long maximumSize) {
requireArgument(maximumSize >= 0);
int maximum = (int) Math.min(maximumSize, Integer.MAX_VALUE >>> 1);
if ((table != null) && (table.length >= maximum)) {
return;
}
table = new long[(maximum == 0) ? 1 : Caffeine.ceilingPowerOfTwo(maximum)];
tableMask = Math.max(0, table.length - 1);
sampleSize = (maximumSize == 0) ? 10 : (10 * maximum);
if (sampleSize <= 0) {
sampleSize = Integer.MAX_VALUE;
}
size = 0;
}
实现所有数据的频次记录处理是由BoundedLocalCache类中的onAccess()方法完成的。
void onAccess(Node<K, V> node) {
if (evicts()) {//数据是否被清除
K key = node.getKey();//获取数据
if (key == null) {//Key位空,直接返回null
return;
}
frequencySketch().increment(key);//频次访问记录
if (node.inWindow()) {
reorder(accessOrderWindowDeque(), node);//window队列记录
} else if (node.inMainProbation()) {
reorderProbation(node);//试用区记录
} else {
reorder(accessOrderProtectedDeque(), node);//保护区记录
}
setHitsInSample(hitsInSample() + 1);//更新命中数量
} else if (expiresAfterAccess()) {
reorder(accessOrderWindowDeque(), node);
}
if (expiresVariable()) {
timerWheel().reschedule(node);//时间轮调度算法(Caffeine中最值钱的部分)
}
}
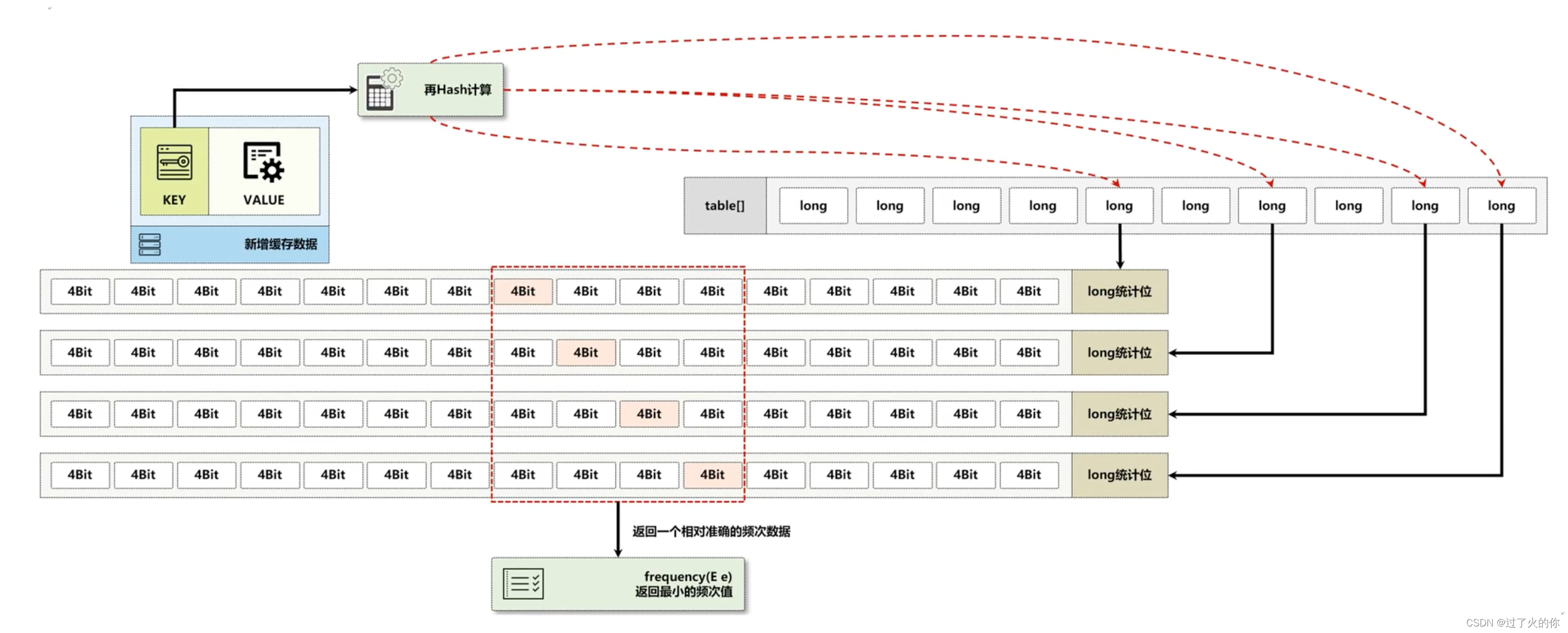
下面的核心就在于FrequencySketch类中的increment() 方法
int sampleSize;//降频的样本量,最大值的10倍
int tableMask;//获取table索引的掩码(一个long记录16个数据)
long[] table;//保存频次的数据
int size;//统计长度
public void increment(@NonNull E e) {//频次增长
if (isNotInitialized()) {//初始化判断
return;
}
//根据KEY来进行Hash数据的获取,考虑到Hash分配不均匀问题,所以要进行再Hash处理
int hash = spread(e.hashCode());//计算新的HashValue
int start = (hash & 3) << 2;//计算table中long数据起始定位
// 根据不同的种子内容,计算出不同统计数据的下标 - Loop unrolling improves throughput by 5m ops/s
int index0 = indexOf(hash, 0);//获取table下标
int index1 = indexOf(hash, 1);//获取table下标
int index2 = indexOf(hash, 2);//获取table下标
int index3 = indexOf(hash, 3);//获取table下标
boolean added = incrementAt(index0, start);//计算start+0位置的频次
added |= incrementAt(index1, start + 1);//计算start+1位置的频次
added |= incrementAt(index2, start + 2);//计算start+2位置的频次
added |= incrementAt(index3, start + 3);//计算start+3位置的频次
if (added && (++size == sampleSize)) {//样本的统计
reset();//数据的降频处理
}
}
观察incrementAt()方法操作
boolean incrementAt(int i, int j) {
int offset = j << 2;//计算偏移量
long mask = (0xfL << offset);//计算压掩码
if ((table[i] & mask) != mask) {//判断当前掩码的结果(4位内容最多就15)
table[i] += (1L << offset);//不是15追加1
return true;//频次增加完成
}
return false;//超过15的频次增加
}
观察所有缓存项的降频操作
void reset() {
int count = 0;
for (int i = 0; i < table.length; i++) {
count += Long.bitCount(table[i] & ONE_MASK);
table[i] = (table[i] >>> 1) & RESET_MASK;
}
size = (size >>> 1) - (count >>> 2);//移位的处理操作
}
在每次进行访问的时候也有频次的处理
public int frequency(@NonNull E e) {
if (isNotInitialized()) {
return 0;
}
int hash = spread(e.hashCode());//Hash处理
int start = (hash & 3) << 2;
int frequency = Integer.MAX_VALUE;//最大的频次定义
for (int i = 0; i < 4; i++) {//通过循环获取一个频次的内容
int index = indexOf(hash, i);//根据当前Hash内容获取到索引
int count = (int) ((table[index] >>> ((start + i) << 2)) & 0xfL);//获取次数
frequency = Math.min(frequency, count);//返回最小值
}
return frequency;
}
以上的各个处理方法本质上来讲就是下面的一张图形
12. 缓存驱逐源码分析
Caffeine组件的内部使用是一个W-TinyLFU驱逐算法,所以对于这种算法的实现就需要通过其源代码区分,在Caffeine内部使用了两个不同的缓存区域保存数据,如果要想进行分析,那么就需要通过查看数据存储的源代码。
数据存储之中的核心操作方法:
afterWrite(new AddTask(node, newWeight));
打开afterWrite()方法源代码
void afterWrite(Runnable task) {
if (buffersWrites()) {
for (int i = 0; i < WRITE_BUFFER_RETRIES; i++) {
if (writeBuffer().offer(task)) {
scheduleAfterWrite();
return;
}
scheduleDrainBuffers();//实现缓存页面的替换操作
}
try {
performCleanUp(task);
} catch (RuntimeException e) {
logger.log(Level.SEVERE, "Exception thrown when performing the maintenance task", e);
}
} else {
scheduleAfterWrite();
}
}
打开scheduleDrainBuffers()源代码进行分析
void scheduleDrainBuffers() {
if (drainStatus() >= PROCESSING_TO_IDLE) {
return;
}
if (evictionLock.tryLock()) {//在进行缓存数据排除的时候需要进行同步的锁定
try {
int drainStatus = drainStatus();
if (drainStatus >= PROCESSING_TO_IDLE) {
return;
}
lazySetDrainStatus(PROCESSING_TO_IDLE);
executor.execute(drainBuffersTask);
} catch (Throwable t) {
logger.log(Level.WARNING, "Exception thrown when submitting maintenance task", t);
maintenance(/* ignored */ null);
} finally {
evictionLock.unlock();
}
}
}
观察 maintenance()方法的源代码
void maintenance(@Nullable Runnable task) {
lazySetDrainStatus(PROCESSING_TO_IDLE);
try {
drainReadBuffer();
drainWriteBuffer();
if (task != null) {
task.run();
}
drainKeyReferences();
drainValueReferences();
expireEntries();//让实体数据失效
evictEntries();//实体数据的清除
climb();
} finally {
if ((drainStatus() != PROCESSING_TO_IDLE) || !casDrainStatus(PROCESSING_TO_IDLE, IDLE)) {
lazySetDrainStatus(REQUIRED);
}
}
}
观察expireEntries()方法的源代码实现
void evictEntries() {
if (!evicts()) {
return;
}
int candidates = evictFromWindow();
evictFromMain(candidates);
}
观察evictFromWindow()方法
int evictFromWindow() {
int candidates = 0;//清除候选缓存项的个数
Node<K, V> node = accessOrderWindowDeque().peek();//通过window队列获取节点
while (windowWeightedSize() > windowMaximum()) {//数据过多
// The pending operations will adjust the size to reflect the correct weight
if (node == null) {//没有节点
break;//直接退出循环
}
Node<K, V> next = node.getNextInAccessOrder();//获取下个节点
if (node.getPolicyWeight() != 0) {//权重判断
node.makeMainProbation();//保存在Probation空间
accessOrderWindowDeque().remove(node);//window队列数据移除
accessOrderProbationDeque().add(node);//probation队列头部增加数据
candidates++;//候选的个数自增
setWindowWeightedSize(windowWeightedSize() - node.getPolicyWeight());//修改window区权重
}
node = next;
}
return candidates;//获取移动缓存项的数量
}
打开evictFromMain(candidates)源代码
void evictFromMain(int candidates) {//通过主缓存区进行清除
int victimQueue = PROBATION;//使用缓冲区的标记
Node<K, V> victim = accessOrderProbationDeque().peekFirst();//头部获取淘汰节点
Node<K, V> candidate = accessOrderProbationDeque().peekLast();//尾部获取候选节点
while (weightedSize() > maximum()) {//缓存区数量过多
// Search the admission window for additional candidates
if (candidates == 0) {//移动的候选数量为0
candidate = accessOrderWindowDeque().peekLast();//获取头部一个候选节点
}
// Try evicting from the protected and window queues
//尝试通过受保护队列和window队列驱逐元素
if ((candidate == null) && (victim == null)) {//移动节点为空
if (victimQueue == PROBATION) {//队列为试用队列
victim = accessOrderProtectedDeque().peekFirst();//获取受保护队列的第一个元素
victimQueue = PROTECTED;//切换队列
continue;
} else if (victimQueue == PROTECTED) {//判断队列类型
victim = accessOrderWindowDeque().peekFirst();//获取window队列的第一个元素
victimQueue = WINDOW;//切换队列
continue;
}
// The pending operations will adjust the size to reflect the correct weight
break;
}
// Skip over entries with zero weight
if ((victim != null) && (victim.getPolicyWeight() == 0)) {//跨过零权重的实体数据
victim = victim.getNextInAccessOrder();
continue;
} else if ((candidate != null) && (candidate.getPolicyWeight() == 0)) {
candidate = (candidates > 0)
? candidate.getPreviousInAccessOrder()//获取权重为0 的候选
: candidate.getNextInAccessOrder();
candidates--;//候选的数量减1
continue;
}
// Evict immediately if only one of the entries is present
if (victim == null) {//驱逐类型为空
@SuppressWarnings("NullAway")
Node<K, V> previous = candidate.getPreviousInAccessOrder();//候选父元素
Node<K, V> evict = candidate;//候选父元素的交换
candidate = previous;//候选节点的修改
candidates--;//减少驱逐的个数
evictEntry(evict, RemovalCause.SIZE, 0L);//元素驱逐处理
continue;
} else if (candidate == null) {//候选元素为空
Node<K, V> evict = victim;//获取驱逐的元素项
victim = victim.getNextInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);//元素驱逐处理
continue;
}
// Evict immediately if an entry was collected
K victimKey = victim.getKey();//获取驱逐数据的KEY
K candidateKey = candidate.getKey();//获取候选项的KEY
if (victimKey == null) {//当前存在有驱逐KEY
@NonNull Node<K, V> evict = victim;//配置驱逐项
victim = victim.getNextInAccessOrder();
evictEntry(evict, RemovalCause.COLLECTED, 0L);
continue;
} else if (candidateKey == null) {
@NonNull Node<K, V> evict = candidate;
candidate = (candidates > 0)
? candidate.getPreviousInAccessOrder()
: candidate.getNextInAccessOrder();
candidates--;
evictEntry(evict, RemovalCause.COLLECTED, 0L);
continue;
}
// Evict immediately if the candidate's weight exceeds the maximum
if (candidate.getPolicyWeight() > maximum()) {//权重的驱逐处理
Node<K, V> evict = candidate;
candidate = (candidates > 0)
? candidate.getPreviousInAccessOrder()
: candidate.getNextInAccessOrder();
candidates--;
evictEntry(evict, RemovalCause.SIZE, 0L);
continue;
}
// Evict the entry with the lowest frequency
candidates--;
if (admit(candidateKey, victimKey)) {//试用队列的驱逐处理
Node<K, V> evict = victim;
victim = victim.getNextInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
candidate = candidate.getPreviousInAccessOrder();
} else {//候选队列的驱逐处理
Node<K, V> evict = candidate;
candidate = (candidates > 0)
? candidate.getPreviousInAccessOrder()
: candidate.getNextInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
}
}
}
以上的处理流程中,虽然看起来很麻烦,实际上本质就是进行了三个缓存区域数据节点的移动操作,所有最终的驱逐的处理操作,是由evictEntry()方法完成的。
Caffeine中会存在三个缓存空间,这三个缓存空间的实现配比是由BoundedLocalCache类负责,这个类提供了几个常量
static final double PERCENT_MAIN = 0.99d;//主缓存区所占比例
/** The percent of the maximum weighted capacity dedicated to the main's protected space. */
static final double PERCENT_MAIN_PROTECTED = 0.80d;//保护区队列所占比例
/** The difference in hit rates that restarts the climber. */
static final double HILL_CLIMBER_RESTART_THRESHOLD = 0.05d;//命中差异率
/** The percent of the total size to adapt the window by. */
static final double HILL_CLIMBER_STEP_PERCENT = 0.0625d;//window调整大小百分比
/** The rate to decrease the step size to adapt by. */
static final double HILL_CLIMBER_STEP_DECAY_RATE = 0.98d;//空间减少比率
按照之前分配的结构来讲,Window缓存空间只占整个缓存空间的1%(主缓存空间占整个缓存空间的99%),由于不同的应用场景,Window缓存空间也需要根据命中率、缓存数据量等指标进行调整,而调整的实现,是由climb()方法完成的。
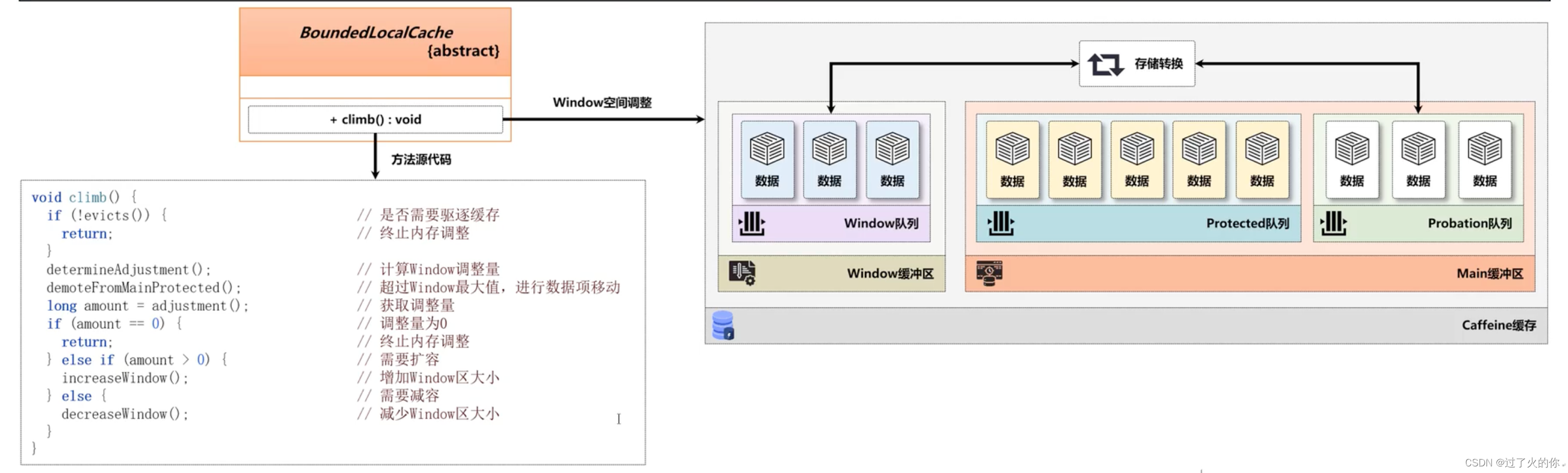
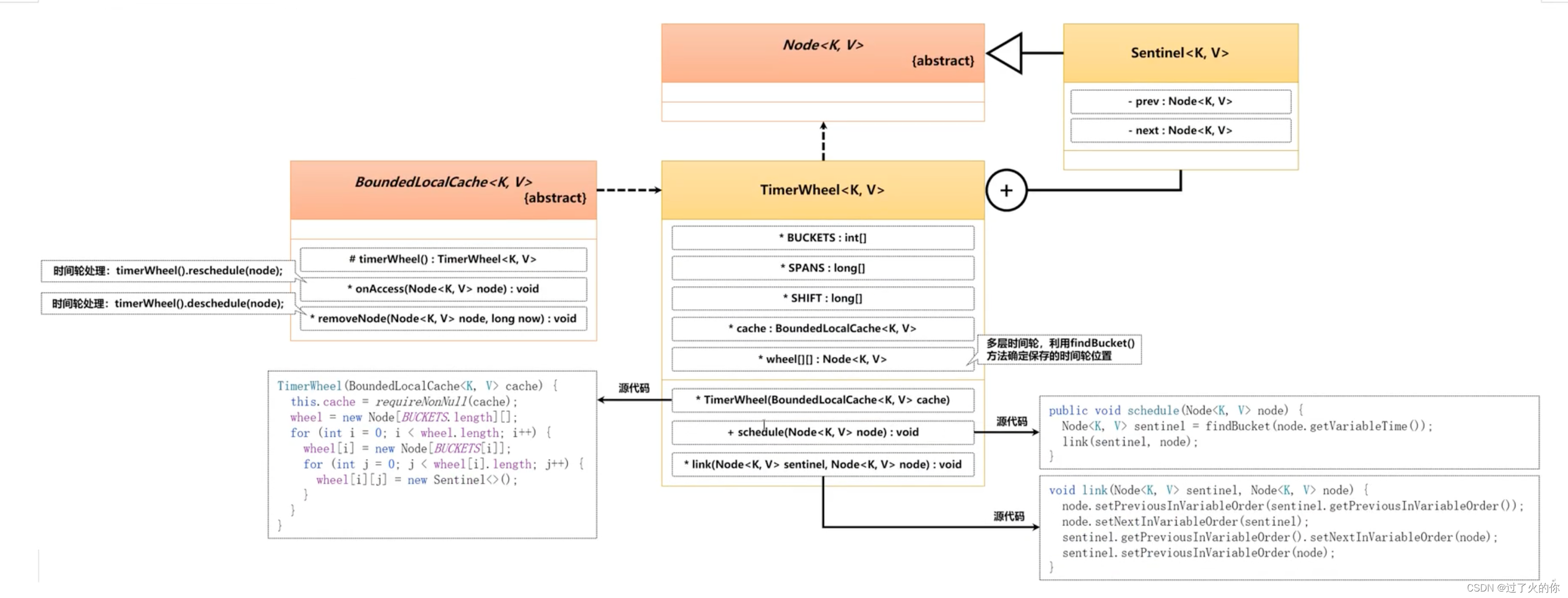
13. 时间轮(TimerWheel)
Caffeine组件在性能的处理上还有一个绝对的优势,就是时间轮的设计。通过该设计的思路可以解决数据驱逐时的性能问题,在之前进行驱逐的时候会发现有些的数据需要进行移动的处理,所有的驱逐都会调用一个专属的驱逐方法。
通过以上分析,可以发现在进行缓存驱逐的时候会存在三个特定的处理方法:expireAfterAccess()、expireAfterWrite()、expireVariably()。
现在实现队列数据存储的位置,使用的类型为AccessOrderDeque双端队列,通过之前的分析,可以发现在每次进行数据驱逐的时候都是向队列之中进行指定数据的存储,而这个存储实际上也是有目的的,队列的头部保存的是即将过期的缓存项。当过期时间一到则进行数据的弹出。
@GuardedBy("evictionLock")
protected AccessOrderDeque<Node<K, V>> accessOrderWindowDeque() {
throw new UnsupportedOperationException();
}
@GuardedBy("evictionLock")
protected AccessOrderDeque<Node<K, V>> accessOrderProbationDeque() {
throw new UnsupportedOperationException();
}
@GuardedBy("evictionLock")
protected AccessOrderDeque<Node<K, V>> accessOrderProtectedDeque() {
throw new UnsupportedOperationException();
}
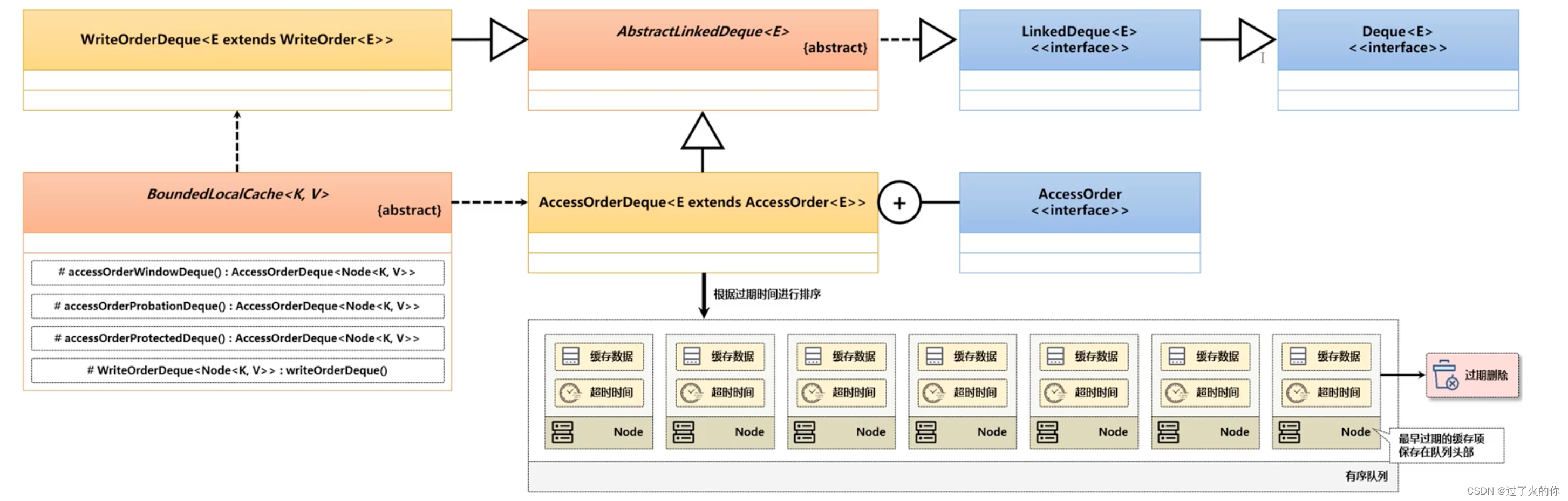
按照传统队列的处理操作,那么此时需要针对于不同的队列进行一个清除操作的实现,是需要开发者不断的进行数据的扫描后得到的,但是这样的清除的方式性能是非常差的,所以为了解决这种数据清除性能的问题,在 Caffeine 组件内部提供了一个数据的清除算法实现,这个算法为时问轮算法。
时间轮是一种环形的数据结构,可以将其内部划分为若干个不同的时间格子,每一个格子代表一个时间(时间格子划分的越短,时间的精度就越高),每一个格子都对应有一个链表,并在该链表中保存全部的到期任务。所有的新任务依据一定的求模算法,保存在合适的格子之中,在任务执行时会有一个指针随着时间转动到对应的格子之中,并执行相应格子中的到期任务,从而解決了自定义过期驱逐任务设计中的性能问题。
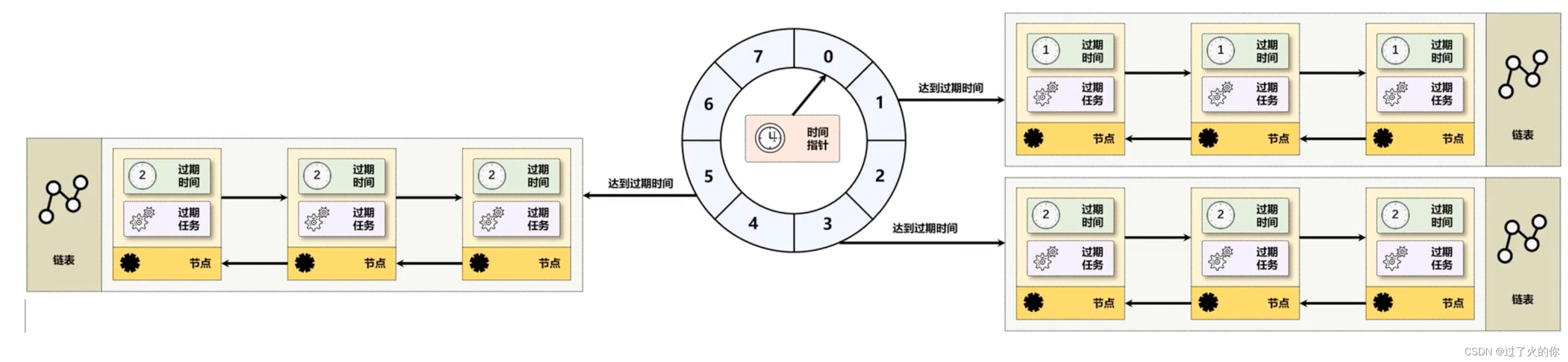
考虑到数据清除的问题,所以在每次清除之前都会将该清除的数据保存在指定时间格子上的链表之中,这样每当时间指针达到了时间格子之后就可以进行链表数据的清理操作,这样的实现,可以避免全部的队列进行扫描的处理。
由于不同应用中时间轮定义的精度不同(时间格子划分不精细),所以时间轮失效的处理仅仅只能够使用一种非实时性的方式进行处理,虽然牺性了精确度,但是却保证了性能,在 Caffeine 之中提供了 TimerWheel 类进行时间轮的功能实现





![[Power Query] 删除错误/空值](https://img-blog.csdnimg.cn/63a79e81449045ee80a038e8f4df6b82.png)
![[附源码]计算机毕业设计JAVA流浪动物救助系统](https://img-blog.csdnimg.cn/50594ad1cbb54d30804bbb344623c7bb.png)