开集识别
闭集识别
训练集中的类别和测试集中的类别是一致的,最常见的就是使用公开数据集进行训练,所有数据集中的图像的类别都是已知的,没有未知种类的图像。传统的机器学习的算法在这些任务上已经取得了比较好的效果。
(训练集和测试集的类别是一致的)
开集识别描述
开集识别是一个在现实世界中最常见的问题,但是这个问题只有你在真正实施项目的时候才会遇到,使用公开数据集是不会遇到这个问题的。
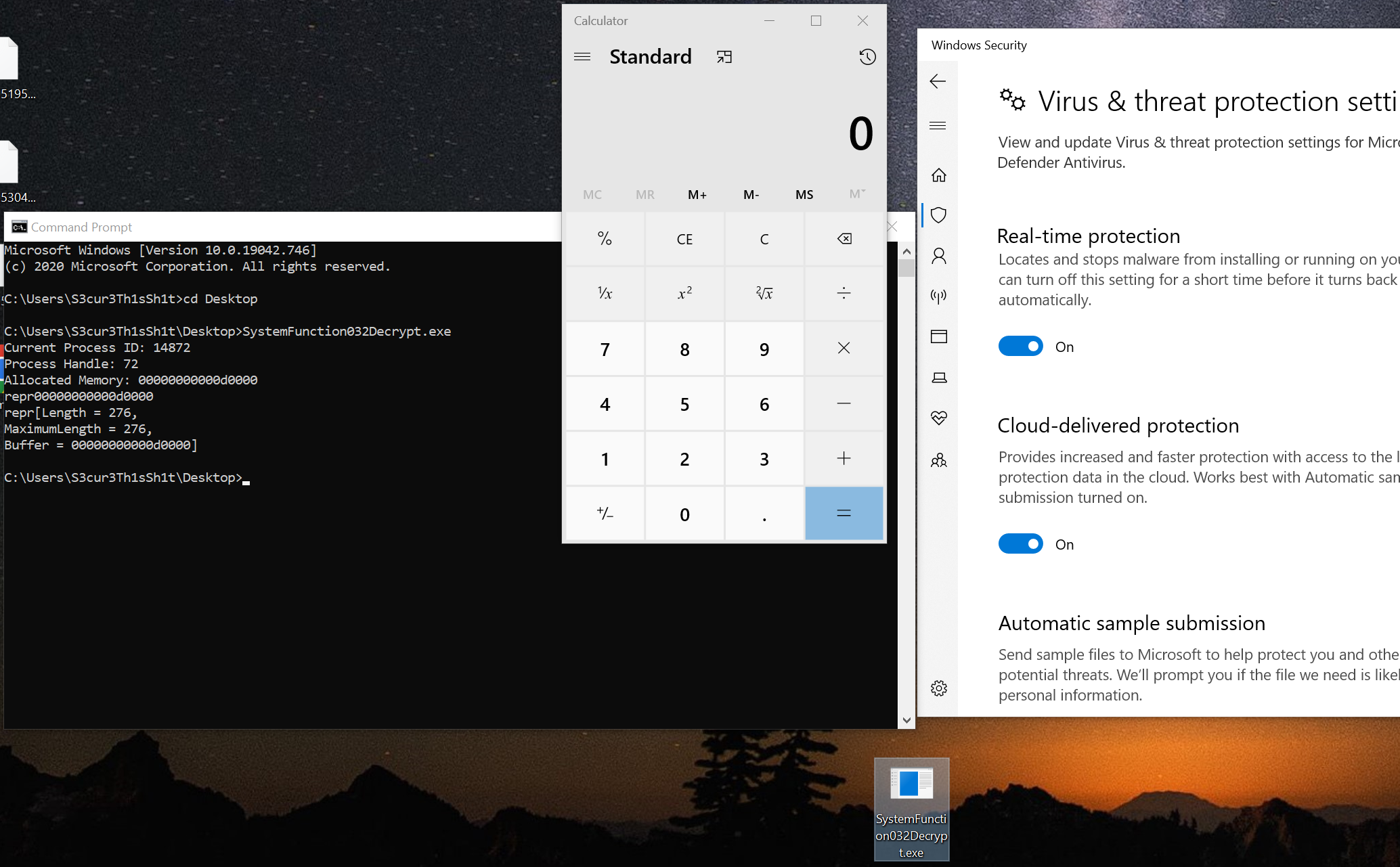
所谓的开集识别
白话说就是 在一个开放的数据集中进行识别,更为准确的说就是:测试集中含有训练集中没有的类别,而在使用测试集进行测试的时候,输入一张不属于训练集中已知类别的图像,由于Softmax的输出特性,模型有可能会将其以较高的置信度分为某一类,显然这是错误的。所以就产生了开集识别这个问题。
(测试集中含有训练集中没有的类别)
开集识别旨在解决:输入一张已知种类的图像,输出具体的某个类别,输入一张未知种类的图像,输出为unknown,或者以较低的置信度输出。
开集识别举例
示例、猫狗识别模型,输入一张荷花或者大象的图像,模型可能会告诉你80%的概率为猫。
想要的结果:输入不为猫狗的图像,模型输出为未知类别,输入猫狗图像,模型输出对应具体的类别。
开集识别学习路径
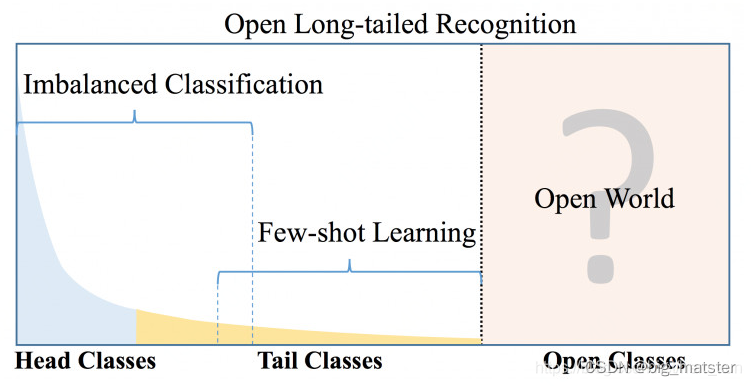
开始根据自己的遇到的情况进行查询,发现开放长尾识别问题中的开放问题就是目前自己遇到的问题,下面这张图很清晰的展示常见任务的划分标准,后续查询到了自己遇到的问题可以更为具体的归属为开集识别的问题,所以后续一直查询开集识别的一些问题,Google Youtube找到了一些资料,思路清晰了很多。
开集识别的思路
首先综述写道:现实生活中很常见开集识别的场景,但是收集所有的场景图像是不现实的,所以需要开集识别问题的研究,并且开集识别OSR和zero-shot, one-shot (few-shot) recognition/learning techniques, classification with reject option 问题挺接近的,但是仔细对比可以发现,OSR更难,比如和 one-shot对比,OSR不仅要识别具体的种类还要对未知的类别进行拒绝,下图为几种任务之间的区别,主要就是根据数据的不同分布来制定不同的解决方案。
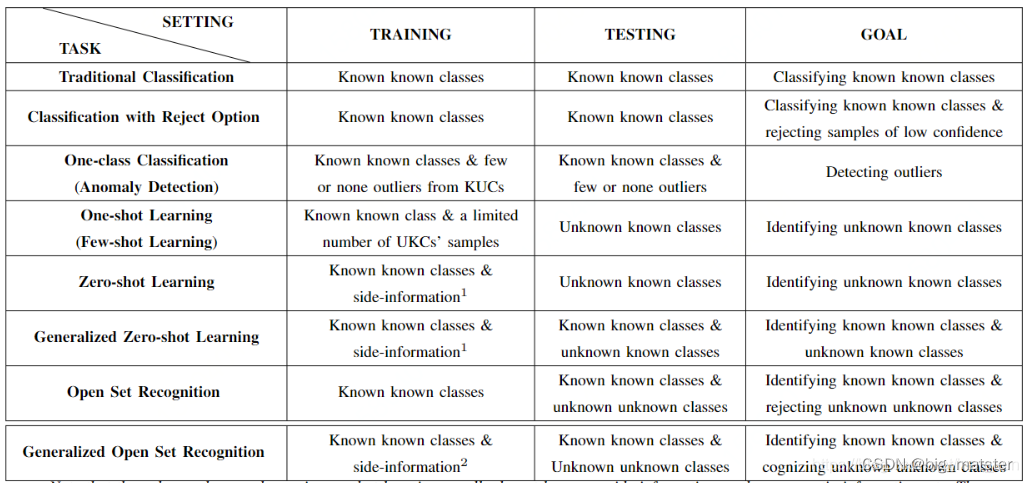
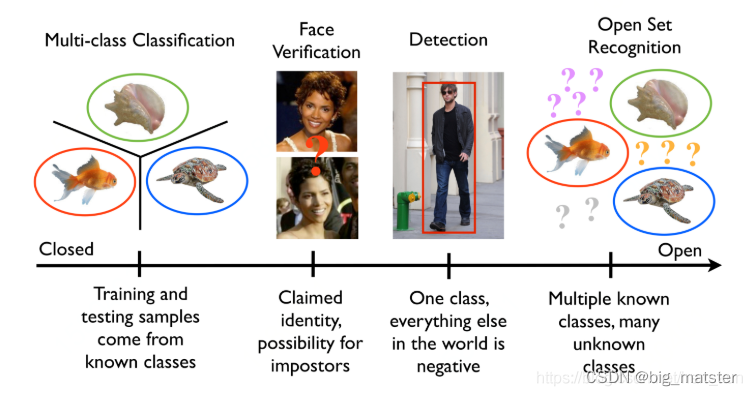
其中在开集识别中可以把数据分为 KKCS (known known classes)、 KUCS(known unknown classes)、 UKCS 、 UUCS四种,其中可以简单的认为 OSR就是想根据KKCS拒绝 UUCS.
其中大家可能在看KUCS 的时候比较有争议或者疑问,这部分数据首先归类为已知数据,但是没有具体的标签,比如我们要做一个猫狗识别的模型,我们还有另外的一些数据比如手机、大象等等,我们统一的将这些图像归为other类,也就是已知不是猫狗类,但是具体是哪一类没有标签。
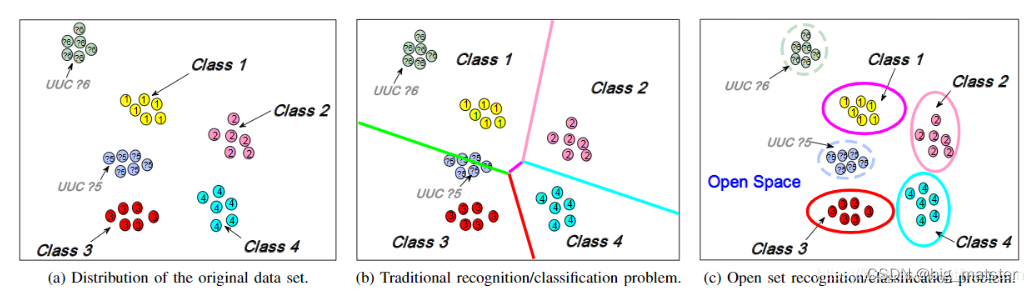
OSR开集识别可以分为两种大的模型,基于判别模型和基于生成模型,其中基于判别模型的又可以分为基于 ML 和 基于 DNN ,其中基于ML的方式就是聚类类似或者使用1VSall的方式;基于DNN的方式就是使用卷积神经网络,其中又分为是否使用EVT方式。基于生成模型就是利用数据生成的手段进行处理,常见的一种方式就是生成虚假的未知类别图像对模型进行feed。
下图展示了OSR领域目前不同方向以及进展
个人思考
就我目前的情况来说,本人更加偏向使用基于DNN的方式,一是卷积神经网络相对于传统机器学习模型拥有更强大的特征表达能力,二是生成模型生成的数据的可信度和用生成的数据feed模型得到的结果存疑,最好的数据还是真实的数据,只有数据较少且目前的解决方案无法解决目前的问题的时候才可以考虑生成方式(本人的研究方向非生成方向,所以不甚了解)。
所以后续的开集识别的解决方案还是基于卷积的操作
开集识别方案与广义零样本方案是一样的,这是说识别的目标是不同的。然后构建出的两种不同类别式的学习。
后续解决方案
* 基于 feature 的度量学习(聚类,改loss,改model等操作)
* 基于较为经典的 Openmax 的实现方式(参照openmax提出的paper)
基于ML方式
- SVM based
- Sparse Representation based (待展开)
- Distance based (待展开)
- Margin Distribution based
基于CNN的方式
前言:目前基于CNN方式的开集识别的方案最为经典的要数openmax方法,但是目前所能查到的资料对openmax解读的资料实在是太少,所以这里通过对openmax的实现过程进行讲解以达到理解的目的
以下是对个人的理解和对问题的解读
softmax是分类网络中最常见的最后一层的激活函数,用于概率值的生成,但是之前的文章说到过因为softmax的特性,导致不太适用于开集识别,所以这篇文章中提到了openmax,其可以认为是softmax的一个替代,但是在模型训练后的进行的处理,不可以简单的认为是创建了一个新的layer。由于整个文章主要就是提出openmax,所以整篇文章都是在对openmax的可行性做解释,接下来暂时不对整个文章做处理,只是对openmax以及其实现进行说明:
(Softmax用于概率值生成)
Openmax是什么
openmax是通过对softmax前一层特征的处理,也就是dense层的处理(这里的dense层不加任何的激活函数,和激活函数是分开的两层)
具体实现
通过看文章和看这些伪代码,能够大概知道openmax的计算原理,但是具体代码实现的时候面对这么多的参数,可能有的参数不知道如何计算得到,所以下面就用白话对该过程进行一个讲解。
Al1: 进行EVT拟合:

Al2: 进行Openmax的计算

白化opennax的实现:
下面是具体处理和计算的流程:只计算并保留所有预测样本正确样本(预测错误(预测值和真实label不符)输出的舍弃)的特征值(特征值的长度就是类别的长度,比如最后的类别数量为3,那么这个特征就是长度为3的向量,而不是之前一层的向量),求出所有预测正确样本的向量,根据不同的类别(真实label)将这些向量对应分开,然后分别计算每个类别对应向量的均值作为该类别的中心(可认为类别的中心点,和聚类的中心点类似)。然后分别计算每个类别中每个样本对应向量和其类别中心的距离,然后对这些距离进行排序,针对排序后的几个尾部极大值进行极大值理论分析,这些极大值的分布符合weibull分布,所以使用weibull分布(libmr中的fithigh方法)来拟合这些极大的距离,得到一个拟合分布的模型,这时候基本上已经完成了上述的Algrithms 1。
当我们来了一个新的测试图像的时候,这时候输入模型,先得到其对应的dense向量(softmax的前一层的),然后针对该向量分别针对每个类别计算与其之间的距离(共得到N(类别数量)个距离),然后针对上述得到的每个距离分别使用每个类别对应的拟合模型对其进行预测,最后会分别得到一个分数FitScores,这个分数就是指得是该测试图像特征值归属于其对应类别的的概率,所以一共是有N个分数的。然后根据该图像的最终输出(此处为softmax的输出),根据该概率分数的输出继进行排序,然后计算w的值(该值的计算就是根据采用tail的个数(即阿尔法的值)来计算的,比较简单就是一个固定的式子)
f o r , i = 1 , ⋯ α , w = 1 − F i t S c o r e s × ( α − i ) α for,i = 1,\cdots \alpha ,w = 1 - FitScores \times\frac{ (\alpha - i) }{\alpha} for,i=1,⋯α,w=1−FitScores×α(α−i)
然后将该向量分别针对每个类别计算与其之间的距离与上述得到的
W
W
W相乘,后续在进行类似Softamx操作,最终得到两个分数,一个是openmax后的分数,一个是unknown的分数。注意,这里得到的openmax的类别比Softmax类别多一个类别,也就是unknown的类别。
作者想要得到的结果是:如果输入时已知类别,那么openmax的输出是已知的具体某个类别,如果测试时输入的为未知类别,那么最终的输出就是unknow.这也i就是开集识别最终想要得到的结果,根据作者在minist数据集上的测试结果感觉还可以,使用汉字和孟加拉字母的话可以正确的识别为未知类。
该文章中很多的配图都是为了说明其设计的初衷和有效性,再看这篇文章的时候还有很多的理论不是很理解,比如weibull分布**,EVT理论等等,所以为了更好的理解和复现**就找了很多的资料,以此记录。
极值理论(EVT)
每过一段时间**,小概率时间就会发生**,比如巨大的台风,或者跳高记录被打破。但是到底这样的事件有多极端?极值理论可以回答这个问题。利用以往的记录,比如说500年来的洪水记录,极值理论就可以预测将来发生更大洪水的可能性。
极值理论关注风险损失分布的尾部特征,通常用来分析概率罕见的事件,它可以依靠少量样本数据,在总体分布未知的情况下,得到总体分布中极值的变化情况,具有超越样本数据的估计能力。
相关定义
-
开放空间风险

-
开放集识别问题
-

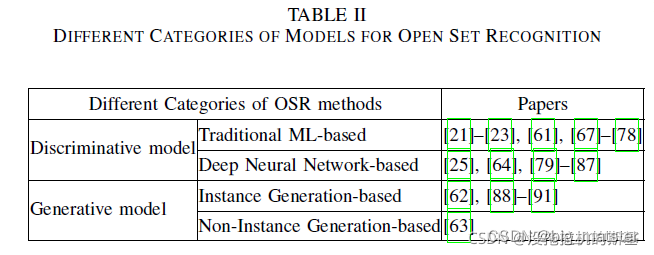
开集识别的解决方案
总结
先大致了解以下OSR识别问题,然后做技术用到的时候找相关论文再去研究一下,全部将其搞定都行啦的回事与打算。
先大致了解以下开集识别是干什么的,然后再慢慢的开始研究OSR模型,用到啥,全部将其搞定都行啦的理由与打算。