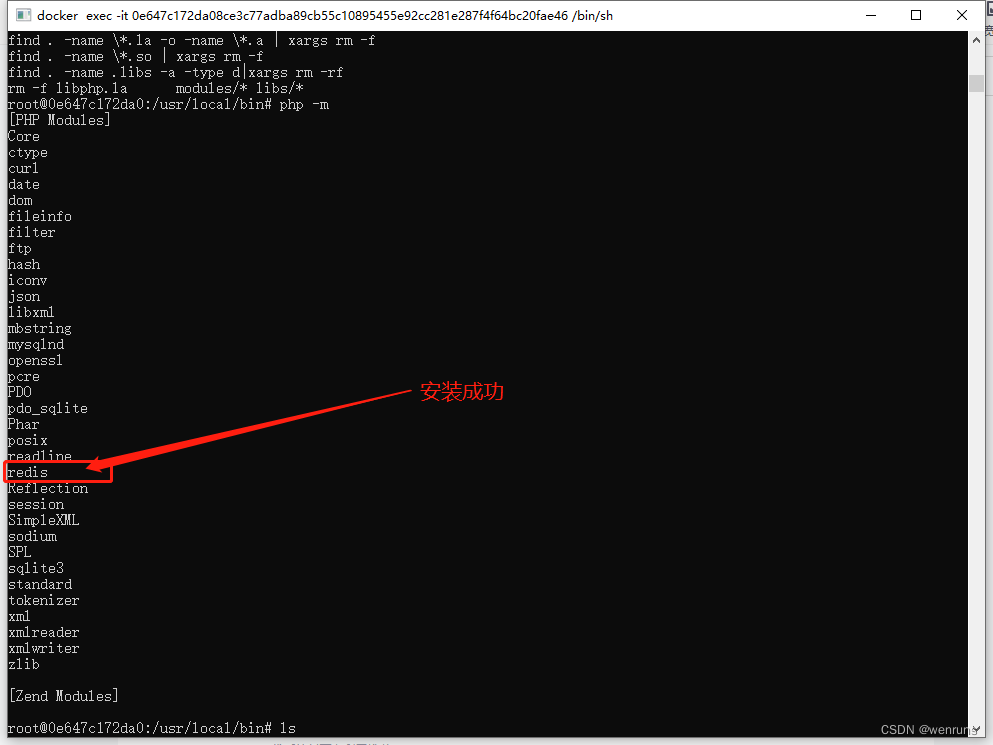
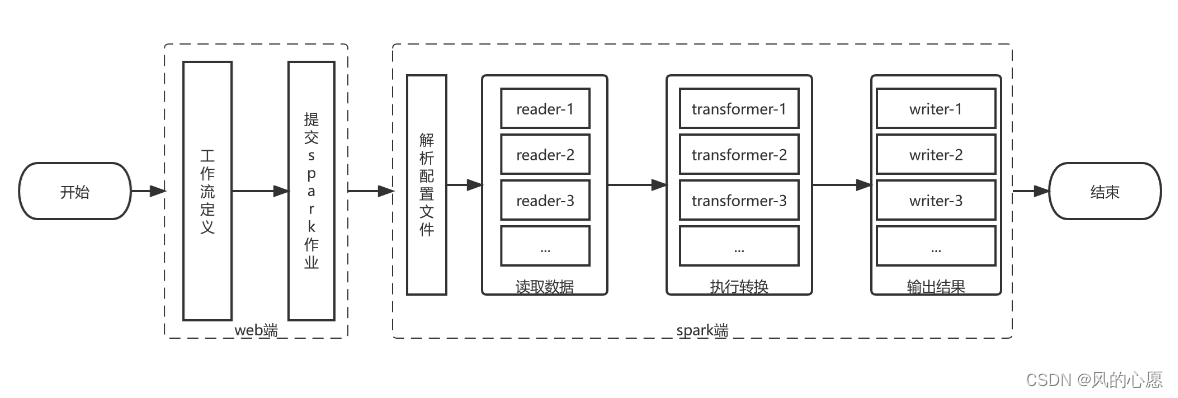
数据质量工作流程
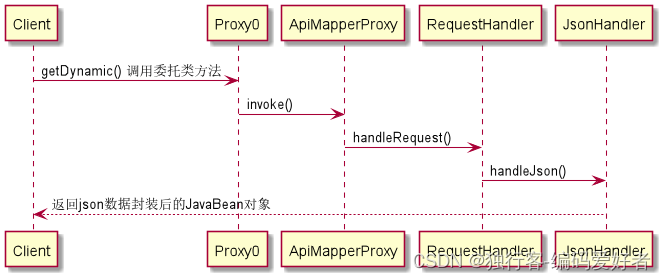
数据质量运行流程分为2个部分:在web端进行数据质量检测的流程定义,通过dolphinscheduer进行调度,提交到spark计算引擎;spark端负责解析数据质量模型的参数,通过读取数据、执行转换、输出三个步骤,完成数据质量检测任务,工作流程如下图所示。
在web端进行定义
数据质量定义如下图所示,这里只定义了一个节点。
 以一个空值检测的输入参数为例,这个json文件会以字符串形式提交给spark端
以一个空值检测的输入参数为例,这个json文件会以字符串形式提交给spark端
{
"name": "$t(null_check)",
"env": {
"type": "batch",
"config": null
},
"readers": [
{
"type": "JDBC",
"config": {
"database": "ops",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"output_table": "ops_ms_alarm",
"table": "ms_alarm",
"url": "jdbc:mysql://192.168.3.211:3306/ops?allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
}
}
],
"transformers": [
{
"type": "sql",
"config": {
"index": 1,
"output_table": "total_count",
"sql": "SELECT COUNT(*) AS total FROM ops_ms_alarm"
}
},
{
"type": "sql",
"config": {
"index": 2,
"output_table": "null_items",
"sql": "SELECT * FROM ops_ms_alarm WHERE (alarm_time is null or alarm_time = '') "
}
},
{
"type": "sql",
"config": {
"index": 3,
"output_table": "null_count",
"sql": "SELECT COUNT(*) AS nulls FROM null_items"
}
}
],
"writers": [
{
"type": "JDBC",
"config": {
"database": "dolphinscheduler3",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"table": "t_ds_dq_execute_result",
"url": "jdbc:mysql://192.168.3.212:3306/dolphinscheduler3?characterEncoding=utf-8&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql": "select 0 as rule_type,'$t(null_check)' as rule_name,0 as process_definition_id,25 as process_instance_id,26 as task_instance_id,null_count.nulls AS statistics_value,total_count.total AS comparison_value,7 AS comparison_type,3 as check_type,0.95 as threshold,3 as operator,1 as failure_strategy,'hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测' as error_output_path,'2022-11-16 03:40:32' as create_time,'2022-11-16 03:40:32' as update_time from null_count full join total_count"
}
},
{
"type": "JDBC",
"config": {
"database": "dolphinscheduler3",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"table": "t_ds_dq_task_statistics_value",
"url": "jdbc:mysql://192.168.3.212:3306/dolphinscheduler3?characterEncoding=utf-8&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql": "select 0 as process_definition_id,26 as task_instance_id,1 as rule_id,'ZKTZKDBTRFDKXKQUDNZJVKNX8OIAEVLQ91VT2EXZD3U=' as unique_code,'null_count.nulls'AS statistics_name,null_count.nulls AS statistics_value,'2022-11-16 03:40:32' as data_time,'2022-11-16 03:40:32' as create_time,'2022-11-16 03:40:32' as update_time from null_count"
}
},
{
"type": "hdfs_file",
"config": {
"path": "hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测",
"input_table": "null_items"
}
}
]
}
spark端源码分析
DataQualityApplication程序入口
DataQualityApplication#main
public static void main(String[] args) throws Exception {
//...
//从命令行获取参数
String dataQualityParameter = args[0];
// 将json参数转为DataQualityConfiguration对象
DataQualityConfiguration dataQualityConfiguration = JsonUtils.fromJson(dataQualityParameter,DataQualityConfiguration.class);
//...
//构建 SparkRuntimeEnvironment的参数Config对象
EnvConfig envConfig = dataQualityConfiguration.getEnvConfig();
Config config = new Config(envConfig.getConfig());
config.put("type",envConfig.getType());
if (Strings.isNullOrEmpty(config.getString(SPARK_APP_NAME))) {
config.put(SPARK_APP_NAME,dataQualityConfiguration.getName());
}
SparkRuntimeEnvironment sparkRuntimeEnvironment = new SparkRuntimeEnvironment(config);
//委托给 DataQualityContext执行
DataQualityContext dataQualityContext = new DataQualityContext(sparkRuntimeEnvironment,dataQualityConfiguration);
dataQualityContext.execute();
}
数据质量配置类
public class DataQualityConfiguration implements IConfig {
@JsonProperty("name")
private String name; // 名称
@JsonProperty("env")
private EnvConfig envConfig; // 环境配置
@JsonProperty("readers")
private List<ReaderConfig> readerConfigs; // reader配置
@JsonProperty("transformers")
private List<TransformerConfig> transformerConfigs; // transformer配置
@JsonProperty("writers")
private List<WriterConfig> writerConfigs; // writer配置
//...
}
DataQualityContext#execute
从dataQualityConfiguration类中获取 readers、transformers、writers, 委托给SparkBatchExecution
public void execute() throws DataQualityException {
// 将List<ReaderConfig>转为List<BatchReader>
List<BatchReader> readers = ReaderFactory
.getInstance()
.getReaders(this.sparkRuntimeEnvironment,dataQualityConfiguration.getReaderConfigs());
// 将List<TransformerConfig>转为List<BatchTransformer>
List<BatchTransformer> transformers = TransformerFactory
.getInstance()
.getTransformer(this.sparkRuntimeEnvironment,dataQualityConfiguration.getTransformerConfigs());
// 将List<WriterConfig>转为List<BatchWriter>
List<BatchWriter> writers = WriterFactory
.getInstance()
.getWriters(this.sparkRuntimeEnvironment,dataQualityConfiguration.getWriterConfigs());
// spark 运行环境
if (sparkRuntimeEnvironment.isBatch()) {
// 批模式
sparkRuntimeEnvironment.getBatchExecution().execute(readers,transformers,writers);
} else {
// 流模式, 暂不支持
throw new DataQualityException("stream mode is not supported now");
}
}
ReaderFactory 类采用了单例和工厂方法的设计模式, 目前支持JDBC和HIVE 的数据源的读取, 对应Reader类HiveReader、JdbcReader
WriterFactory 类采用了单例和工厂方法的设计模式, 目前支持JDBC、HDFS、LOCAL_FILE 的数据源的输出, 对应Writer类 HdfsFileWriter LocalFileWriter JdbcWriter
TransformerFactory 类采用了单例和工厂方法的设计模式,目前仅支持TransformerType.SQL的转换器类型
结合json 可以看出 一个空值检测的reader、tranformer、 writer情况
1个reader : 读取源表数据
3个tranformer: total_count 行总数 、null_items 空值项(行数据) 、null_count (空值数),计算sql 如下
– SELECT COUNT() AS total FROM ops_ms_alarm
– SELECT * FROM ops_ms_alarm WHERE (alarm_time is null or alarm_time = ‘’)
– SELECT COUNT() AS nulls FROM null_items
3个writer:
第一个是jdbc writer, 将比较值、统计值 输出t_ds_dq_execute_result 数据质量执行结果表,
SELECT
//...
null_count.nulls AS statistics_value,
total_count.total AS comparison_value,
//...
'hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测' AS error_output_path,
//...
FROM
null_count
FULL JOIN total_count
第二个是jdbc writer,将statistics_value写入到表 t_ds_dq_task_statistics_value
SELECT
//...
//...
'null_count.nulls' AS statistics_name,
null_count.nulls AS statistics_value,
//...
FROM
null_count
第3个是hdfs writer,将空值项写入到hdfs 文件目录
{
"type": "hdfs_file",
"config": {
"path": "hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测",
"input_table": "null_items"
}
}
目前 DolphinScheduler占不支持实时数据的质量检测。
SparkBatchExecution#execute
public class SparkBatchExecution implements Execution<BatchReader, BatchTransformer, BatchWriter> {
private final SparkRuntimeEnvironment environment;
public SparkBatchExecution(SparkRuntimeEnvironment environment) throws ConfigRuntimeException {
this.environment = environment;
}
@Override
public void execute(List<BatchReader> readers, List<BatchTransformer> transformers, List<BatchWriter> writers) {
// 为每一个reader注册输入临时表
readers.forEach(reader -> registerInputTempView(reader, environment));
if (!readers.isEmpty()) {
// 取readers列表的第一个reader读取数据集合, reader的实现类有HiveReader、JdbcReader
Dataset<Row> ds = readers.get(0).read(environment);
for (BatchTransformer tf:transformers) {
// 执行转换
ds = executeTransformer(environment, tf, ds);
// 将转换后结果写到临时表
registerTransformTempView(tf, ds);
}
for (BatchWriter sink: writers) {
// 执行将转换结果由writer输出, writer的实现类有JdbcWriter、LocalFileWriter、HdfsFileWriter
executeWriter(environment, sink, ds);
}
}
// 结束
environment.sparkSession().stop();
}
}
SparkBatchExecution#registerInputTempView
//注册输入临时表, 临时表表名为OUTPUT_TABLE的名字
private void registerInputTempView(BatchReader reader, SparkRuntimeEnvironment environment) {
Config conf = reader.getConfig();
if (Boolean.TRUE.equals(conf.has(OUTPUT_TABLE))) {// ops_ms_alarm
String tableName = conf.getString(OUTPUT_TABLE);
registerTempView(tableName, reader.read(environment));
} else {
throw new ConfigRuntimeException(
"[" + reader.getClass().getName() + "] must be registered as dataset, please set \"output_table\" config");
}
}
调用 Dataset.createOrReplaceTempView方法
private void registerTempView(String tableName, Dataset<Row> ds) {
if (ds != null) {
ds.createOrReplaceTempView(tableName);
} else {
throw new ConfigRuntimeException("dataset is null, can not createOrReplaceTempView");
}
}
执行转换executeTransformer
private Dataset<Row> executeTransformer(SparkRuntimeEnvironment environment, BatchTransformer transformer, Dataset<Row> dataset) {
Config config = transformer.getConfig();
Dataset<Row> inputDataset;
Dataset<Row> outputDataset = null;
if (Boolean.TRUE.equals(config.has(INPUT_TABLE))) {
// 从INPUT_TABLE获取表名
String[] tableNames = config.getString(INPUT_TABLE).split(",");
// outputDataset合并了inputDataset数据集合
for (String sourceTableName: tableNames) {
inputDataset = environment.sparkSession().read().table(sourceTableName);
if (outputDataset == null) {
outputDataset = inputDataset;
} else {
outputDataset = outputDataset.union(inputDataset);
}
}
} else {
// 配置文件无INPUT_TABLE
outputDataset = dataset;
}
// 如果配置文件中配置了TMP_TABLE, 将outputDataset 注册到TempView
if (Boolean.TRUE.equals(config.has(TMP_TABLE))) {
if (outputDataset == null) {
outputDataset = dataset;
}
String tableName = config.getString(TMP_TABLE);
registerTempView(tableName, outputDataset);
}
// 转换器进行转换
return transformer.transform(outputDataset, environment);
}
SqlTransformer#transform 最终是使用spark-sql进行处理, 所以核心还是这个sql语句,sql 需要在web端生成好,参加前面的json文件。
public class SqlTransformer implements BatchTransformer {
private final Config config;
public SqlTransformer(Config config) {
this.config = config;
}
//...
@Override
public Dataset<Row> transform(Dataset<Row> data, SparkRuntimeEnvironment env) {
return env.sparkSession().sql(config.getString(SQL));
}
}
将数据输出到指定的位置executeWriter
private void executeWriter(SparkRuntimeEnvironment environment, BatchWriter writer, Dataset<Row> ds) {
Config config = writer.getConfig();
Dataset<Row> inputDataSet = ds;
if (Boolean.TRUE.equals(config.has(INPUT_TABLE))) {
String sourceTableName = config.getString(INPUT_TABLE);
inputDataSet = environment.sparkSession().read().table(sourceTableName);
}
writer.write(inputDataSet, environment);
}




![[附源码]java毕业设计医院管理系统](https://img-blog.csdnimg.cn/0e32114616bf48c5ac190e57a1c99872.png)