一、Oracle AI Vector Search 概述
企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation :RAG)功能,RAG能够将LLM的生成能力与知识库的精准资料库进行检索结合,将大模型部署在内部同时将私有的数据进行LLM的检索避免泄露企业专用的数据同时提高的准确性。于是如何将数据存入向量数据库以及向量查询等这些基本功能变得必备和重要。
Oracle 23ai 虽然目前没有OP发布,提供测试的free 已经更新至23.8,AI Vector Search 在原有的Oracle强大的基础功能上专为人工智能进行增加工作负载模块,并允许根据语义搜索而不再是关键字查询数据。
单一数据库的简单性
轻松将相似性搜索与关系、文本、JSON、空间和图形数据类型相结合,从而增强应用 — 所有这些都在一个数据库中完成。
用自然语言与业务数据“对话”
使用 RAG 对您的私有业务数据进行自然语言搜索,为您所选的 LLM 提供指导。
以自己的方式开发 AI 应用
集成自己喜爱的开发工具、AI 框架和语言构建 AI 应用。
专为企业打造的 AI
轻松构建关键任务 AI 应用。利用工业级功能,实现可扩展性、性能、高可用性和安全性。
二、为什么是Oracle AI Vector Search
Oracle AI Vector Search 的最大优势之一是将非结构化数据搜索可以与业务数据的关系搜索相结合在一个系统上实现。
这不仅功能强大而且效果明显提升,因为不需要添加专门的向量数据库或者是使用其他数据库添加向量组件后拼接而成,随着系统版本和组件的升级又要新一轮的升级磨合,融合成一体,从而避免了多个系统之间数据碎片化。
例如:一个应用程序,该应用程序需要找到一个查询的房子拍摄的照片相似的房子,该房子位于选定的区域,并且具有设定了预计的预算范围。在这种情况下,要找到一个好的匹配项,需要将语义图片搜索与业务数据搜索相结合,从前的sql要做多少次的相似度查询呢。
使用 Oracle AI Vector Search模拟,创建下表:
CREATE TABLE house_for_sale (house_id NUMBER,
price NUMBER,
city VARCHAR2(400),
house_photo BLOB,
house_vector VECTOR);使用上表,查询解答基本问题:
SELECT house_photo, city, price
FROM house_for_sale
WHERE price <= :input_price AND
city = :input_city
ORDER BY VECTOR_DISTANCE(house_vector, :input_vector);从23 ai开始,AI Smart Scan 自动加速 Oracle 数据库 23ai AI Vector 通过优化进行搜索,提供低延迟并行扫描海量矢量数据。
Oracle Exadata 系统24.1.0早已引入了 AI Smart Scan,这是一组 特定于 Exadata 的优化能够提高各种 AI 向量查询作(按数量级)。利用超快的 Exadata RDMA 内存 (XRMEM) 和 Exadata Smart Flash Cache 的 Cache,并执行矢量距离 数据源的计算和 top-K 筛选,避免不必要的网络数据传输和数据库服务器处理。期待Oracle 23 ai的OP发布。
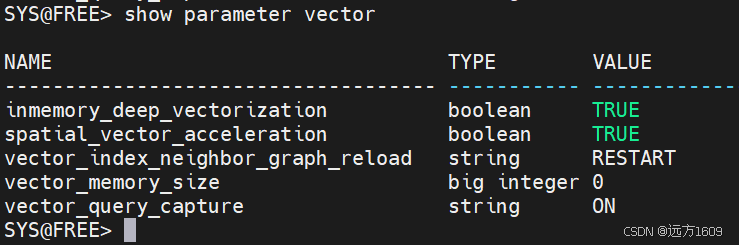
三、Oracle AI Vector Search相关参数-现在是23.8,新版可能新增参数
inmemory_deep_vectorization,
spatial_vector_acceleration,
vector_index_neighbor_graph_reload,
vector_memory_size ,
vector_query_capture
3.1 inmemory_deep_vectorization
功能定位:
此参数控制内存深度矢量化技术的启用状态,是Oracle针对分析型查询的SIMD(单指令多数据)硬件加速优化。它通过并行处理数据块显著提升复杂操作(如多表连接、聚合计算)的性能。通过内存矢量化技术提升分析查询性能,支持多级操作,是实时分析的核心引擎。
技术背景与增强:
在Oracle 21c中首次引入,但仅支持单级连接操作。
23ai的突破:支持多级哈希连接和内存分组聚合,可自动优化查询计划中的多连接键和聚合流水线。
默认启用(TRUE),无需修改SQL即可加速实时分析场景。
应用场景:适用于数据仓库、实时报表等需要高性能计算的分析负载,例如金融交易分析或大规模行为聚合等类。
3.2 spatial_vector_acceleration
功能定位:
旨在加速空间向量计算,可能利用SIMD或GPU硬件优化地理空间数据(如坐标、几何图形)的处理效率。专注空间数据的高效处理,与AI向量搜索协同支持地理信息等非结构化数据的快速检索
技术关联:
Oracle 23ai强化了对多模型数据的统一支持,包括空间数据(如地理信息、图像坐标)的向量化存储与检索。
结合AI Vector Search能力,空间数据可被编码为高维向量,实现基于相似性的快速检索(例如查找邻近地理位置)。
典型应用:
适用于地理信息系统(GIS)、物流路径优化、医疗影像分析等需高频计算空间关系的场景。
3.3 vector_index_neighbor_graph_reload参数
Oracle 23ai 中的 vector_index_neighbor_graph_reload 参数用于控制基于 HNSW 算法的邻居图索引在数据库实例重启后的自动重载行为。
该参数通过后台任务机制,实现 HNSW 索引的自动重建和加载,从而减少人工干预并提升系统可用性。
vector_index_neighbor_graph_reload 参数为RESTART(默认值)时,实例重启时HNSW索引会自动加载。
vector_index_neighbor_graph_reload 参数为OFF时,实例重启时HNSW索引不会自动加载。
SYS@FREE> alter session set container=cdb$root;
Session altered.
SYS@FREE> show pdbs;
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 FREEPDB1 READ WRITE NO
SYS@FREE> show parameter vector_index_neighbor_graph_reload;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
vector_index_neighbor_graph_reload string RESTART
SYS@FREE>3.4 vector_memory_size参数
23ai版本中添加了一个新的内存结构:向量内存池(Vector Memory Pool),主要用于存储Hierarchical Navigable Small World (HNSW)向量索引和相关元数据,同时也用于加速Inverted File Flat (IVF) 索引的创建以及对具有IVF索引的基表的DML操作。
向量内存池(Vector Memory Pool)位于SGA中,Oracle 23 ai 是通过 vector_memory_size参数控制这块内存的大小。
初次CDB级别指定当前向量池的大小(vector_memory_size)时,数据库初始化时并未分配相关内存,不能动态调整。需要通过SCOPE=SPFILE手工指定大小。之后需要 shutdown immediate ,startup实例,即可动态调整PDB的vector_memory_size,否则会报错。vector_memory_size参数可以分别在CDB和PDB级别中指定,CDB级别用于指定当前向量池的大小,PDB级别用于指定当前PDB允许的最大向量池使用量。PDB的大小要小于CDB,否则同样会产生报错。

[oracle@OL96 ~]$ sqlplus / as sysdba;
SQL*Plus: Release 23.0.0.0.0 - Production on Thu Jun 5 20:57:14 2025
Version 23.8.0.25.04
Copyright (c) 1982, 2025, Oracle. All rights reserved.
Connected to:
Oracle Database 23ai Free Release 23.0.0.0.0 - Develop, Learn, and Run for Free
Version 23.8.0.25.04
SYS@FREE> show con_id;
CON_ID
------------------------------
1
SYS@FREE> show con_name;
CON_NAME
------------------------------
CDB$ROOT
SYS@FREE> show parameter vector_memory;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
vector_memory_size big integer 0
SYS@FREE>
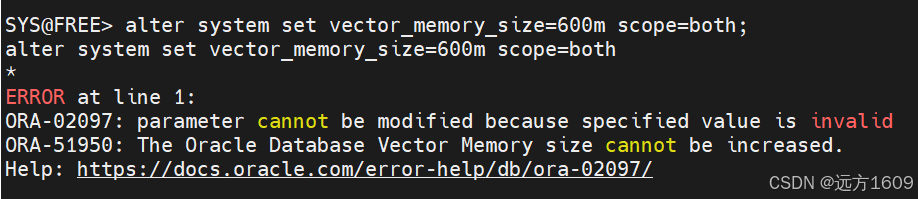
SYS@FREE> alter system set vector_memory_size=600m scope=both;
alter system set vector_memory_size=600m scope=both
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-51950: The Oracle Database Vector Memory size cannot be increased.
Help: https://docs.oracle.com/error-help/db/ora-02097/
SYS@FREE>
SYS@FREE> alter system set vector_memory_size=600M scope=spfile;
System altered.
SYS@FREE> shut immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SYS@FREE> startup
ORACLE instance started.
Total System Global Area 1603289656 bytes
Fixed Size 4923960 bytes
Variable Size 352321536 bytes
Database Buffers 603979776 bytes
Redo Buffers 4530176 bytes
Vector Memory Area 637534208 bytes
Database mounted.
Database opened.
SYS@FREE> show parameter vector_memory_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
vector_memory_size big integer 608M
SYS@FREE> show parameter sga_target;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_target big integer 1536M
SYS@FREE>3.4.1 PDB vector_memory_size大小设置,
默认FREEPDB1为CDB设置的size大小,可以动态调整,无需重启实例
SYS@FREE> show con_id;
CON_ID
------------------------------
1
SYS@FREE> alter seesion set container=FREEPDB1;
alter seesion set container=FREEPDB1
SYS@FREE> alter session set container=FREEPDB1;
Session altered.
SYS@FREE> SHOW PDBS;
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
3 FREEPDB1 READ WRITE NO
SYS@FREE> show parameter vector_memory_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
vector_memory_size big integer 608M
SYS@FREE> alter system set vector_memory_size=512m scope=both;
System altered.
SYS@FREE> show parameter vector_memory_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
vector_memory_size big integer 512M
SYS@FREE>3.5 vector_query_capture参数
VECTOR_QUERY_CAPTURE 参数用于控制查询向量的捕获功能,是23ai实现闭环AI优化的关键一环,通过自动捕获向量查询,为索引调优和模型训练提供数据支撑。
该参数默认值为 ON,启用后数据库会通过抽样机制捕获部分查询向量。
开发测试环境建议保持ON以积累优化依据;生产环境根据资源消耗情况动态调整
SYS@FREE> show parameter VECTOR_QUERY_CAPTURE;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
vector_query_capture string ON
SYS@FREE>

















