引言
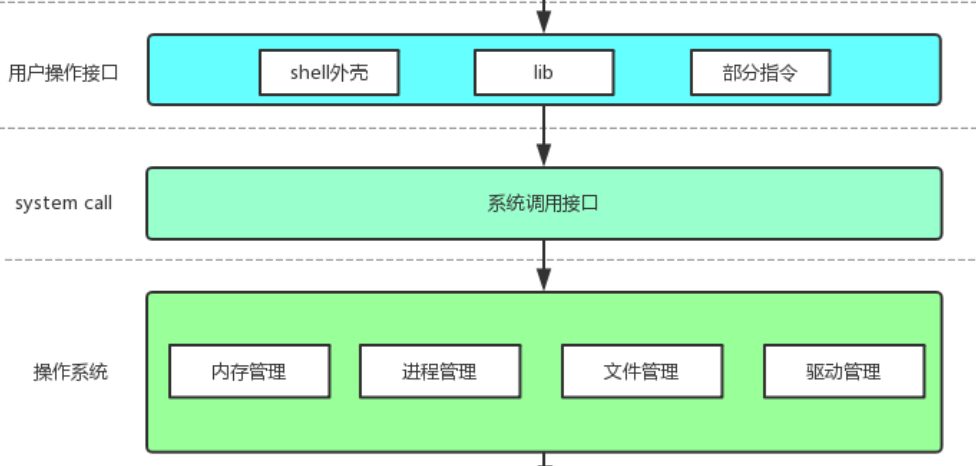
语音助手(如小爱同学、Siri)通过语音识别、自然语言处理(NLP)和语音合成技术,为用户提供直观、高效的交互体验。随着人工智能的普及,Python开发者可以利用开源库和AI模型,快速构建自定义语音助手。本文由浅入深,详细介绍如何使用Python开发AI语音助手,涵盖基础功能、外部API集成和大语言模型(LLM)应用,适合初学者到高级开发者,文章提供清晰的代码示例、实现步骤及思考题,有助于更深入掌握技术细节。
1. 核心组件
AI语音助手包含以下核心模块:
-
语音转文本(STT):将用户语音转换为文本。
-
自然语言处理(NLP):解析文本,理解意图,生成回复,可能结合AI模型。
-
文本转语音(TTS):将文本回复转为语音输出。
这些模块依赖Python生态中的库,如speechrecognition(STT)、pyttsx3(TTS)和transformers或langchain(NLP)。工作流程为:捕获音频、处理文本、生成语音,可扩展至调用外部API(如天气查询)或物联网控制。
2. 环境配置
准备工作
-
安装Python 3.8+。
-
安装依赖库:
pip install speechrecognition pyttsx3 transformers requests -
确保麦克风和扬声器可用。
-
(可选)获取API密钥,如OpenWeatherMap(天气,https://openweathermap.org/)或Claude AI API(https://Claude.ai/api)。
注意事项
-
pyttsx3需要系统语音引擎支持(如Windows的中文语音包)。
-
Google Speech API需联网,建议测试网络稳定性。
-
测试前确认麦克风权限已开启。
3. 简易---基础语音助手
先从一个简单语音助手开始,支持语音输入、处理基本命令(如查询时间)并语音回复。
代码示例
import speech_recognition as sr
import pyttsx3
import datetime
# 初始化语音识别和文本转语音
recognizer = sr.Recognizer()
tts_engine = pyttsx3.init()
tts_engine.setProperty("rate", 150) # 语速
tts_engine.setProperty("volume", 0.9) # 音量
def speak(text):
"""将文本转为语音并播放"""
try:
tts_engine.say(text)
tts_engine.runAndWait()
except Exception as e:
print(f"TTS错误: {e}")
def get_audio():
"""捕获麦克风输入并转换为文本"""
with sr.Microphone() as source:
print("正在监听...")
recognizer.adjust_for_ambient_noise(source, duration=1) # 调整环境噪音
try:
audio = recognizer.listen(source, timeout=5, phrase_time_limit=5)
text = recognizer.recognize_google(audio, language="zh-CN")
print(f"