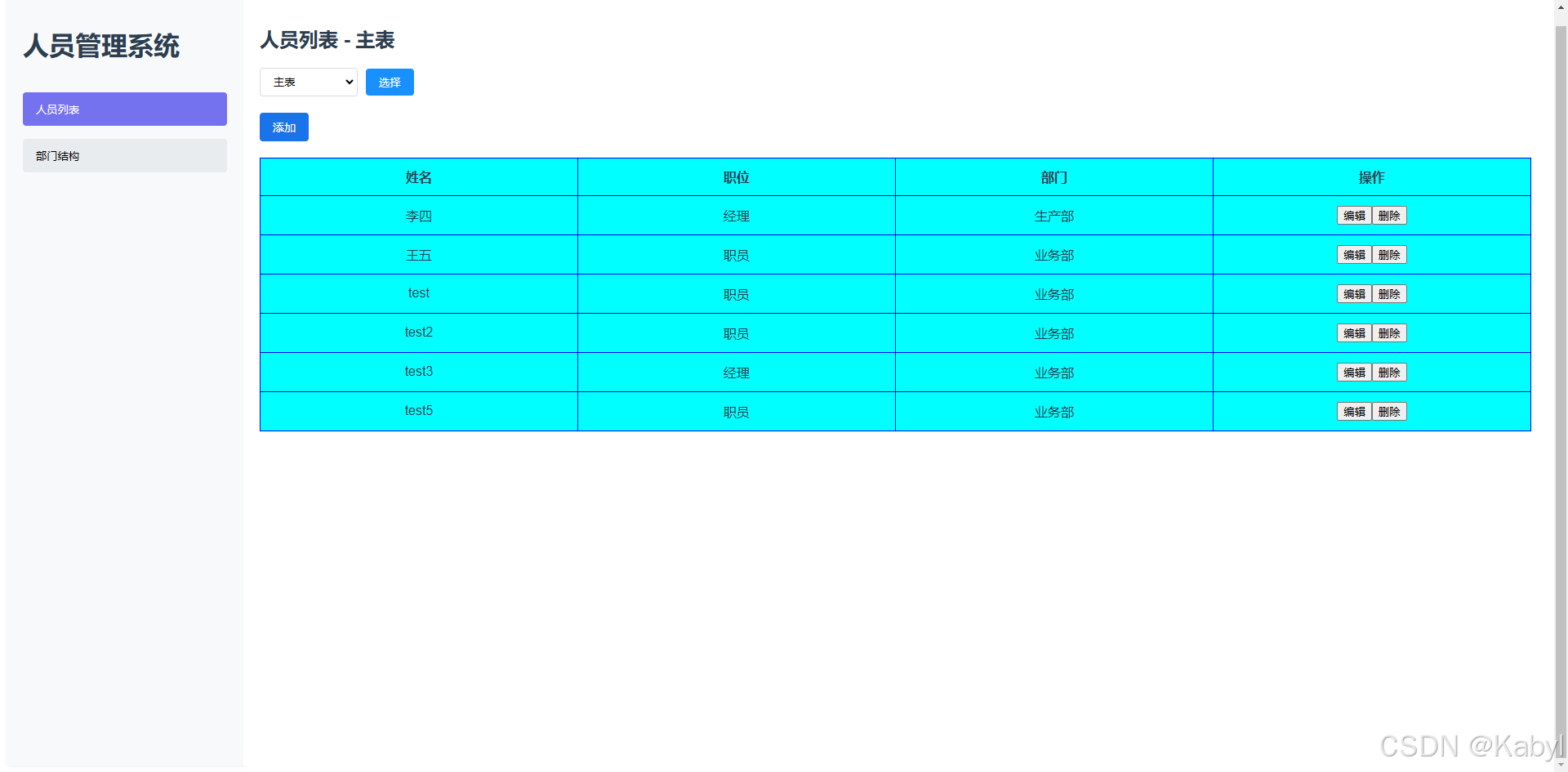
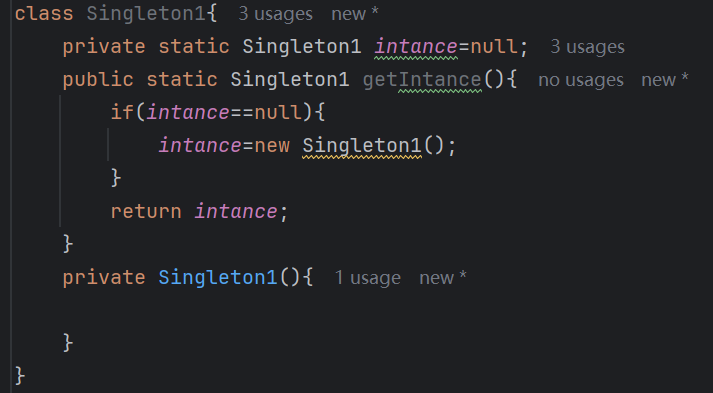
关于 Reflection(反射) 这个概念,总结一下:
Reflection(反射)是什么?
- 反射是对类型的自我检查能力(Introspection)
可以查看类的成员变量、成员函数等信息。 - 反射允许枚举类的成员
比如你可以遍历一个类的字段列表。 - 不等同于基于谓词的检查
比如简单地判断一个类是否有某个成员函数,不是完整的反射。 - 用来表达数据结构为 C++ 类
反射帮助实现从数据到类的映射,比如序列化和反序列化。 - C++ 中没有内建反射机制
C++ 标准目前没有提供像 Java 或 C# 那样的运行时反射。 - C++ 的反射数据可以存储在编译期
通过模板元编程、宏或者外部工具,反射信息往往在编译阶段生成或存储。 - C++ 反射提案正在研究中
标准化组织(ISO C++)中有小组在推动反射机制的标准化。
总结
C++ 目前没有“真正的”反射,但可以通过编译期技术模拟;而运行时反射是其他语言的常见特性。反射的目标是让程序可以动态查询和操作类型信息,方便泛型编程、序列化、调试工具等场景。
关于 消息序列化到 JSON 和 XML,关键点是:
- 字段名(field names)被当作
- 在 JSON 中作为 对象的键(key)
- 在 XML 中作为 标签名(tag name)
这意味着:
- 数据结构的每个字段都映射成了对应的 JSON 键或 XML 标签
- 序列化后的格式保留字段名信息,方便反序列化或人读
简单举例:
假设有一个结构体:
struct Person {
std::string name;
int age;
};
- 序列化成 JSON 可能是:
{
"name": "Alice",
"age": 30
}
- 序列化成 XML 可能是:
<Person>
<name>Alice</name>
<age>30</age>
</Person>
关于 对象关系映射(ORM, Object-Relational Mapping)到数据库:
- 需要用注解(Attributes)标注字段,告诉ORM框架:
- 哪些字段对应数据库的列(columns)
- 哪些字段是主键(primary key)
- 字段的数据类型、约束、索引等信息
- 通过注解,ORM能自动:
- 把对象属性映射到数据库表的字段
- 自动生成SQL语句,实现增删改查操作
- 维护对象和数据库记录之间的同步
比如在C#中:
public class User
{
[Key] // 主键
public int Id { get; set; }
[Column("user_name")] // 映射到数据库列 user_name
public string Name { get; set; }
}
ORM框架就知道怎么把 User 类对应到数据库表的结构上。
“General data-driven development”(通用数据驱动开发)理解如下:
- 数据驱动开发是一种开发范式,核心思想是应用程序的行为、流程和逻辑主要由数据(配置、模型、规则等)来驱动,而不是硬编码在代码里。
- 代码结构围绕数据的定义和流动设计,实现高度的灵活性和可扩展性。
- 这可以减少对代码改动的需求,通过修改数据就能调整系统行为,适应业务需求变化。
- 在工业物联网(IIoT)、流处理、DDS和Rx的背景下,数据驱动开发强调“数据即中心”,各种模块通过数据流(比如DDS Topic)连接,实现异步、响应式、可扩展的系统架构。
总结:
数据驱动开发是用数据定义和控制程序行为的开发方法,使系统更灵活、可维护和响应实时变化。
这段代码演示了如何使用**std::tuple(C++11标准库中的元组)来存储不同类型的多个值,并通过at_c**(通常是Boost库中的元组访问函数,或用std::get代替)访问它们。
代码解析
auto stuff = std::make_tuple(1, 'x', "howdy");
- 创建一个元组,包含3个不同类型的元素:
int1char‘x’- 字符串字面量
"howdy"(会被推断成const char*)
int i = at_c<0>(stuff);
- 取元组中索引为0的元素,即整数1,赋值给
i
char ch = at_c<1>(stuff);
- 取索引为1的元素,即字符
'x',赋值给ch
std::string s = at_c<2>(stuff);
- 取索引为2的元素,即字符串
"howdy",并构造成std::string赋给s
说明
std::tuple允许你把多个不同类型的值组合在一起。- 访问元素时,C++标准库用的是
std::get<index>(tuple),比如:int i = std::get<0>(stuff); - 你这里的
at_c是类似功能的函数,通常来自Boost库boost::tuple或boost::hana。
总结
- 元组是一种将多个异类型值聚合到一起的容器。
- 用
at_c或std::get按索引访问对应元素。 - 这种结构常用于函数返回多个值,或者临时存储不同类型数据。
这段代码尝试实现一个模板函数 print_xml,用于打印一个集合 t 中的每个元素为 XML 格式:
template<class T>
void print_xml(const T& t)
{
for_each(t, [](const auto& x)
{
std::cout
<< '<' << typeid(x).name() << '>'
<< x
<< "</" << typeid(x).name() << '>';
});
}
代码解析:
template<class T>表明这是一个模板函数,接受任意类型的t。for_each(t, [](const auto& x) { ... }):对t中的每个元素调用 lambda 函数打印。typeid(x).name()打印元素的类型名字(类型名未必直观,依赖编译器实现)。- 输出类似:
这里<i>1</i><c>x</c><PKc>howdy</PKc>i是int,c是char,PKc是const char*类型名字(根据编译器可能不同)。
关键点
- for_each 需要支持迭代的容器
for_each需要t是可迭代的容器或者类型,例如std::vector、std::list。
但std::tuple不是可迭代的,因此for_each(stuff, ...)不会直接编译。 - 如果
t是 tuple,需要专门写针对 tuple 的遍历
std::tuple要遍历一般用递归模板或者std::apply,而不是普通for_each。 typeid(x).name()输出是编译器特定的缩写,不适合用作XML标签
如果想要清晰标签,通常手动写字符串,或用反射技术。x需要能直接用operator<<输出
只有支持流输出运算符的类型,才能这样打印。
改进建议
如果你的 stuff 是 std::tuple,可以用下面示例打印每个元素的值:
#include <iostream>
#include <tuple>
// 递归遍历tuple的辅助模板
template<std::size_t I = 0, typename TupleType>
typename std::enable_if<I == std::tuple_size<TupleType>::value>::type
print_xml(const TupleType& t)
{
// 递归结束,无操作
}
template<std::size_t I = 0, typename TupleType>
typename std::enable_if<I < std::tuple_size<TupleType>::value>::type
print_xml(const TupleType& t)
{
auto& x = std::get<I>(t);
std::cout << "<item>" << x << "</item>\n";
print_xml<I + 1>(t);
}
int main()
{
auto stuff = std::make_tuple(1, 'x', "howdy");
print_xml(stuff);
}
输出:
<item>1</item>
<item>x</item>
<item>howdy</item>
总结
- 你的代码思想是好的:打印成 XML 标签的形式。
- 但
for_each不支持 tuple,需要用递归模板或std::apply遍历 tuple。 typeid(x).name()打印的标签名不友好,实际用时一般写固定标签名。- 输出内容需要支持
operator<<。
这段代码用到了 Boost.Fusion 库的一个宏 BOOST_FUSION_ADAPT_STRUCT,它的作用是:
作用
将普通的 C++ struct 适配成 Boost.Fusion 可识别的“序列”(Sequence)类型。
具体解释
struct person
{
std::string name;
int age;
};
BOOST_FUSION_ADAPT_STRUCT(person,
(std::string, name)
(int, age)
);
struct person是一个普通的结构体,包含两个字段:name(字符串类型)和age(整数类型)。BOOST_FUSION_ADAPT_STRUCT宏告诉 Boost.Fusion 库,person是一个“结构体序列”,由两个成员组成:- 类型为
std::string,名字为name - 类型为
int,名字为age
- 类型为
这样做的好处:
- 让
person这个结构体可以被 Boost.Fusion 库的算法和函数当作“序列”来处理,比如:- 迭代访问成员
- 应用元编程算法(如
for_each、transform) - 支持序列相关的算法和特性
- 支持自动序列化、比较、打印等功能(结合其他 Boost 库使用时)
举例
适配后,你可以这样写:
person p{"Alice", 30};
// 使用 Boost.Fusion 的for_each来访问成员
boost::fusion::for_each(p, [](auto& field){
std::cout << field << "\n";
});
输出:
Alice
30
总结
BOOST_FUSION_ADAPT_STRUCT 是 Boost.Fusion 用来“桥接”普通 struct 和 Fusion 序列的工具,方便在模板元编程和反射式操作中使用 struct 的成员。
这段代码是用 Boost.Fusion 库的宏 BOOST_FUSION_DEFINE_STRUCT 来定义一个结构体 person,它和普通的 struct 定义结合了 Boost.Fusion 的序列特性。
代码解读
BOOST_FUSION_DEFINE_STRUCT((), person,
(std::string, name)
(int, age)
);
- 宏
BOOST_FUSION_DEFINE_STRUCT直接定义了一个结构体,并且同时把它适配成 Boost.Fusion 的序列。 ()表示命名空间,这里空代表在全局命名空间定义。person是结构体名字。- 后面括号里的每一项
(类型, 名字)表示结构体的成员。
效果
- 等价于写:
struct person
{
std::string name;
int age;
};
BOOST_FUSION_ADAPT_STRUCT(person,
(std::string, name)
(int, age)
);
- 但它一步到位,既定义了结构体,也完成了 Fusion 适配。
好处
- 少写代码,结构体和适配同时完成
- 方便在 Boost.Fusion 中使用这个结构体作为序列,比如用于序列操作、序列遍历、元编程等
小结
BOOST_FUSION_DEFINE_STRUCT是 Boost.Fusion 提供的宏,用于定义结构体并自动适配 Fusion 序列接口。- 适合想快速定义可用于 Boost.Fusion 的结构体,避免写两遍代码(定义 + 适配)。
这段代码结合了Boost.Fusion适配的结构体和tuple风格的访问,具体解释如下:
代码分析
person p = { "Tom", 52 };
std::string name = at_c<0>(p);
int age = at_c<1>(p);
print_xml(p);
person p = { "Tom", 52 };
这是直接初始化一个person结构体实例,成员name是"Tom",age是52。std::string name = at_c<0>(p);
这里at_c<0>(p)利用Boost.Fusion提供的接口访问person结构体的第0个成员,也就是name,并赋值给name变量。int age = at_c<1>(p);
同理,访问第1个成员age。print_xml(p);
这是你之前写的print_xml函数,遍历结构体成员,打印成XML格式,比如:
<std::string>Tom</std::string><int>52</int>
总结
at_c<N>可以像操作tuple一样,访问被Boost.Fusion适配过的结构体成员。- 你可以用它避免写
p.name和p.age,实现更泛化的访问。 print_xml函数配合Boost.Fusion,能够自动遍历结构体成员并打印。
这段代码展示了如何在编译时或运行时获取结构体成员的名字,对应于第0和第1个成员:
解释
std::string name = struct_member_name<person, 0>::call();
std::string age = struct_member_name<person, 1>::call();
struct_member_name<person, 0>::call()表示获取person结构体第0个成员的名称字符串(比如"name")。struct_member_name<person, 1>::call()表示获取第1个成员的名称字符串(比如"age")。
背景
C++ 本身不支持直接反射(获取成员名),这通常是借助:
- Boost.Fusion 或 Boost.Hana 等库,通过宏定义或模板元编程实现的成员名映射。
- 自定义模板或宏,结合结构体适配宏,将成员名存储为字符串字面量,从而能通过模板索引访问。
总结
这两句代码用来:
- 动态获取结构体成员的名称(字符串),方便做序列化、打印、映射等操作。
- 和
at_c获取成员值配合使用,可以实现成员名和值的对应处理。
“将结构体成员的名字和对应的值配对,形成一个类似于tuple的结构”,比如:
std::make_tuple(
std::make_tuple(name, "name"),
std::make_tuple(age, "age")
)
这表示:
- 第一项是
(name的值, "name") - 第二项是
(age的值, "age")
理解
这个操作的目的是让数据和字段名关联起来,方便做比如:
- JSON/XML序列化(键值对)
- 打印时显示字段名和对应值
- 数据库映射
结合你的例子
person p = { "Tom", 52 };
auto zipped = std::make_tuple(
std::make_tuple(p.name, "name"),
std::make_tuple(p.age, "age")
);
这样 zipped 就是一个包含成员值和成员名的元组集合。
扩展
用Boost.Fusion或模板元编程可以自动实现“字段名和字段值配对”的功能,不用手动写每个字段名。
这个 with_names 模板函数的目的是:
- 给定一个结构体实例
s, - 返回一个将结构体成员值和成员名配对的“zip”结构。
代码逐步分析:
template<class Struct>
auto with_names(const Struct& s)
{
// 定义一个整数范围,从0到结构体成员数
using range = range_c<int, 0, (result_of::size<Struct>())>;
// names 是成员名组成的列表(用 transform 从索引转换到名字)
static auto names = transform(range(), [](auto i) -> std::string
{
return struct_member_name<Struct, i>::call();
});
// 返回成员值和成员名的 zip 结果
return zip(s, names);
}
range_c<int, 0, (result_of::size<Struct>())>:生成从0到成员数的整数序列。transform(range(), lambda):用索引i映射到成员名字符串。static auto names:静态存储成员名数组。zip(s, names):把结构体的成员值和对应名字按顺序配对起来。
作用
这个函数让你不用手动写字段名,通过模板元编程自动生成“字段名和字段值”的组合,方便打印、序列化等操作。
如果你有 person p = {"Tom", 52};
auto zipped = with_names(p);
zipped 里就存了:
( ("Tom", "name"), (52, "age") )
这两段模板函数的意思是:
template<class T>
auto get_value(const T& x)
{
return at_c<0>(x);
}
template<class T>
std::string get_name(const T& x)
{
return at_c<1>(x);
}
解释:
- 这里假设
T是一个二元组(tuple-like),例如(value, name)。 get_value:取这个二元组的第0个元素,返回它的值(成员的值)。get_name:取这个二元组的第1个元素,返回它的名字(成员名字符串)。
举例:
如果有
auto x = std::make_tuple(52, std::string("age"));
auto val = get_value(x); // val == 52
auto name = get_name(x); // name == "age"
这在结合你之前那个 with_names 函数时特别有用——with_names 生成的每个元素就是 (value, name) 这样的tuple,你用 get_value 和 get_name 可以方便地访问它们。
这段代码展示了 关联元组(Associative Tuples) 的用法,利用了 Boost Fusion 的 map 类型实现用类型做键来访问结构化数据。
代码详解:
namespace fields
{
struct name {}; // 定义一个空类型作为键
struct age {}; // 另一个空类型作为键
}
// 定义一个 person 类型,它是一个 Boost Fusion map,
// 用 fields::name 类型映射到 std::string,fields::age 映射到 int
typedef boost::fusion::map<
boost::fusion::pair<fields::name, std::string>,
boost::fusion::pair<fields::age, int>
> person;
// 创建一个 person 实例,传入键对应的值
person a_person = boost::fusion::make_map<fields::name, fields::age>("Tom", 52);
// 通过键访问对应的值
std::string person_name = boost::fusion::at_key<fields::name>(a_person); // "Tom"
int person_age = boost::fusion::at_key<fields::age>(a_person); // 52
核心理解:
- 类型做键:
fields::name和fields::age是空结构体,只用作类型标签(key)。 boost::fusion::map:可以把一组类型和对应的值绑定起来,形成一个类似于字典/映射的结构,但键是类型,不是运行时的字符串。- 通过
at_key<Type>(obj)访问值:根据类型键获取对应的值。 - 类型安全,且编译时检查键是否存在。
应用场景:
- 比较适合元编程风格的数据访问,避免字符串键带来的错误。
- 代替传统结构体,也可以方便做模板元编程和反射。
- 在需要键值对集合且键是类型安全时非常有用。
这段代码是用 Boost Fusion 提供的宏 BOOST_FUSION_DEFINE_ASSOC_STRUCT 来定义一个关联序列结构体(Associative Sequence Struct)。
代码解释:
BOOST_FUSION_DEFINE_ASSOC_STRUCT((), person,
(std::string, name, fields::name)
(int, age, fields::age)
);
- 这是定义一个名为
person的结构体,包含两个成员:name,类型是std::string,关联键是fields::nameage,类型是int,关联键是fields::age
- 关联键(association key) 是用来标识成员的类型标签,类似于前面提到的
fields::name和fields::age。 - 这样定义后,
person结构体的成员不仅可以通过成员名访问,也可以通过 Boost Fusion 的关联容器接口,用类型键访问:
person p{"Tom", 52};
// 通过成员名访问
std::string n1 = p.name;
int a1 = p.age;
// 通过 Boost Fusion 关联键访问
std::string n2 = boost::fusion::at_key<fields::name>(p);
int a2 = boost::fusion::at_key<fields::age>(p);
核心作用:
- 融合了结构体和关联容器的特性,即带有成员变量,又可以通过类型键访问。
- 让结构体同时支持面向对象的访问方式和元编程的关联式访问方式。
- 便于用 Boost Fusion 的算法处理结构体数据。
你可以把它理解为:
既有传统的结构体字段访问,也有类似关联容器的按“类型键”访问的能力。
C++ 模板元编程 + 类型系统技巧 的一个小例子,用来检查某个类型是否带有某种“属性”(以继承的方式实现“属性”标记)。它常用于模拟类似于 C# 或 Java 注解(Attributes / Annotations)在 C++ 中的行为。
目标
判断 Key 类型是否“具有”某个属性 Attribute —— 实际上是:Key 类型是否继承自 Attribute 类型。
逐句解释
1. 模板函数定义
template<class Attribute, class Key>
constexpr auto has_attribute(const Key&)
{
return std::is_base_of<Attribute, Key>();
}
- 这是一个
constexpr(编译期常量)函数模板。 - 参数:
Attribute: 你想要检查的属性类型(如primary_key)。Key: 实际的成员标签类型(如fields::name)。
- 实现:
- 使用
std::is_base_of<Attribute, Key>():这个标准库模板会在编译期返回一个true_type或false_type,表示 Key 是否继承自 Attribute。
- 使用
2. 模拟定义一些属性
namespace fields
{
struct name : primary_key, max_length<250> {};
struct age {};
}
fields::name继承了两个类型:primary_key和max_length<250>。fields::age没有继承任何东西。
这些结构就像是给字段打上的“标签”,类似于 C# 的[PrimaryKey]、[MaxLength(250)]。
3. 使用 has_attribute
bool with_primary_key = has_attribute<primary_key>(fields::name());
bool without_primary_key = has_attribute<primary_key>(fields::age());
with_primary_key会是true:因为fields::name继承了primary_key。without_primary_key会是false:因为fields::age没有继承primary_key。
总结
| 作用 | 实现方式 |
|---|---|
| 给类型加属性 | 通过继承“标记类型” |
| 检查是否有属性 | 使用 std::is_base_of |
| 编译期检查 | 用 constexpr 实现 |
这有什么用?
- 元编程结构体元数据标注:模拟 ORM 框架、序列化器、验证器等机制。
- 编译期校验规则:避免运行时错误,提高类型安全。
- 配合 Boost.Fusion 或其他反射机制:构建智能数据处理框架。
这段代码展示了如何使用 SFINAE(Substitution Failure Is Not An Error)和 enable_if 来根据类型是否具有某个属性来选择不同的函数实现。这是一个典型的 C++11 模板技巧,属于 编译期条件分发(也叫作“类型特化”或“约束式函数重载”)。
一句话总结
你定义了两个重载的 get_max_length 函数:
- 如果
Key拥有max_length_base属性 ➜ 返回其静态成员值。 - 如果
Key没有该属性 ➜ 返回-1。
分步理解
1. REQUIRES 宏定义
#define REQUIRES(...) typename std::enable_if<(__VA_ARGS__), int>::type = 0
这个宏等价于:
template<
class Key,
typename std::enable_if<条件表达式为 true, int>::type = 0
>
它用于函数模板中,作为默认模板参数来控制启用/禁用某个重载。
2. 第一个版本:类型有 max_length_base 属性时启用
template<class Key, REQUIRES(has_attribute<max_length_base>(Key()))>
int get_max_length(const Key&)
{
return Key::max_length_value;
}
has_attribute<max_length_base>(Key())会检查Key是否继承自max_length_base。- 如果是,就启用此函数。
Key::max_length_value是一个你要求所有有max_length_base属性的类型都要定义的静态成员。
3. 第二个版本:没有属性时启用
template<class Key, REQUIRES(!has_attribute<max_length_base>(Key()))>
int get_max_length(const Key&)
{
return -1;
}
- 条件相反:如果没有
max_length_base属性,就启用此重载。 - 返回一个默认值
-1。
应用示例
假设你有两个字段类型定义如下:
struct max_length_base {};
template<int N>
struct max_length : max_length_base {
static constexpr int max_length_value = N;
};
struct fields {
struct name : max_length<255> {};
struct age {};
};
现在调用:
int name_len = get_max_length(fields::name{}); // 返回 255
int age_len = get_max_length(fields::age{}); // 返回 -1
总结
| 技术点 | 说明 |
|---|---|
std::enable_if | 用于 SFINAE,启用/禁用模板重载 |
has_attribute<T>(Key()) | 编译期属性判断 |
REQUIRES(...) | 简化 enable_if 写法 |
| 静态成员访问 | Key::max_length_value 假设类型有此静态常量 |
如果你熟悉 C++20 的 Concepts,这种写法可以更优雅地替换为 requires 表达式。 |
这段代码的功能是:根据一个结构体对象自动生成 SQL 中的 CREATE TABLE 语句,结合 C++ 模板元编程和 Boost.Fusion 的结构反射功能,完成了“数据结构 ➜ SQL 表结构”的自动转换。
一句话总结
该函数将结构体 x 的字段(名字、类型、属性)映射成 SQL 列定义,并输出完整的 CREATE TABLE 语句。
逐行理解
template<class T>
std::string create_table(const T& x, const std::string& table_name)
- 模板函数:泛型支持任意结构体
T。 x: 一个类型为T的对象。table_name: 生成 SQL 表的名字。- 返回:完整的 SQL
CREATE TABLE字符串。
创建 SQL 开头
std::stringstream ss;
ss << "create table " << table_name;
- 构建 SQL 语句开头:
create table table_name
遍历字段并生成列定义
char delim = '(';
for_each(with_names_and_keys(x), [&](const auto& field)
{
ss << delim << create_column(field);
delim = ',';
});
解释:
with_names_and_keys(x):返回一个zip结构,包含字段值、字段名字、字段“键”类型(如fields::name)。for_each(...):对所有字段应用 lambda。- 第一次用
(,之后用,,来拼接 SQL 列定义。 create_column(field)是你需要自己实现的一个函数,用来根据字段类型生成列定义,例如:name VARCHAR(250) age INTEGER
结尾与返回
ss << ')';
return ss.str();
- 补上右括号
),结束表定义。 - 返回 SQL 字符串。
示例输入 + 输出
假设结构体:
struct fields {
struct name : primary_key, max_length<250> {};
struct age {};
};
BOOST_FUSION_DEFINE_ASSOC_STRUCT((), person,
(std::string, name, fields::name)
(int, age, fields::age)
);
调用:
person p = { "Tom", 52 };
std::string sql = create_table(p, "person");
输出可能是:
create table person(name VARCHAR(250) PRIMARY KEY,age INTEGER)
(依赖于 create_column(...) 如何实现)
衍生话题:create_column(...) 可能如何写?
template<typename Field>
std::string create_column(const Field& field) {
std::stringstream ss;
auto value = get_value(field);
auto name = get_name(field);
auto key = get_key(field); // 假设你还有 get_key()
ss << name << " ";
// 推断类型
if (std::is_same<decltype(value), std::string>::value)
ss << "VARCHAR(" << get_max_length(key) << ")";
else if (std::is_same<decltype(value), int>::value)
ss << "INTEGER";
// 属性
if (has_attribute<primary_key>(key))
ss << " PRIMARY KEY";
return ss.str();
}
总结
| 项目 | 内容 |
|---|---|
| 功能 | 自动生成 SQL 的 CREATE TABLE 语句 |
| 技术 | 模板编程 + Boost.Fusion + 类型反射 |
| 亮点 | 字段名、字段值、字段属性打包处理并拼接为 SQL |
| 应用场景 | 自动 ORM、配置导出、元编程实践 |