昨天代码中注意力热图的部分顺移至今天
知识点回顾:
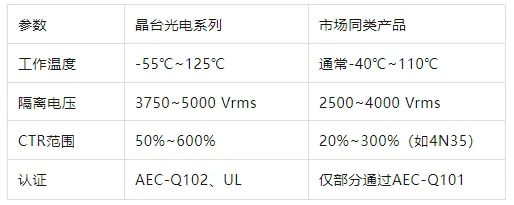
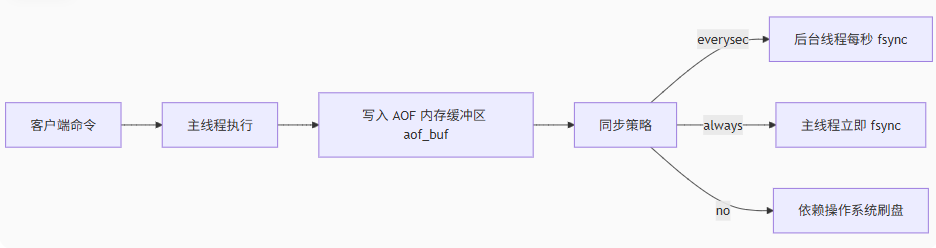
热力图
作业:对比不同卷积层热图可视化的结果
def visualize_attention_map(model, test_loader, device, class_names, num_samples=3):
"""可视化模型的注意力热力图,展示模型关注的图像区域
参数:
model: 训练好的PyTorch模型
test_loader: 测试数据加载器
device: 计算设备 (cuda/cpu)
class_names: 类别名称列表
num_samples: 要可视化的样本数量
"""
# 反标准化参数 (CIFAR10)
mean = torch.tensor([0.4914, 0.4822, 0.4465]).view(1, 3, 1, 1)
std = torch.tensor([0.2023, 0.1994, 0.2010]).view(1, 3, 1, 1)
model.eval() # 设置为评估模式
fig, axes = plt.subplots(num_samples, 4, figsize=(16, 4*num_samples))
if num_samples == 1:
axes = axes.reshape(1, -1) # 确保单样本时保持2D结构
with torch.no_grad():
for sample_idx, (images, labels) in enumerate(test_loader):
if sample_idx >= num_samples:
break
images, labels = images.to(device), labels.to(device)
# 创建钩子捕获特征图
activation = []
hook = model.conv3.register_forward_hook(
lambda module, input, output: activation.append(output.detach())
)
# 前向传播
outputs = model(images)
hook.remove() # 立即移除钩子
# 获取预测结果
_, preds = torch.max(outputs, 1)
# 反标准化图像
denorm_img = images.cpu() * std + mean
img_np = denorm_img[0].permute(1, 2, 0).numpy()
img_np = np.clip(img_np, 0, 1)
# 获取特征图
feat_map = activation[0][0].cpu() # 第一个样本
# 计算通道重要性 (全局平均池化)
channel_weights = torch.mean(feat_map, dim=(1, 2))
topk_indices = torch.topk(channel_weights, k=3).indices
# 显示原始图像
ax = axes[sample_idx, 0]
ax.imshow(img_np)
ax.set_title(f"Original\nTrue: {class_names[labels[0]]}\nPred: {class_names[preds[0]]}")
ax.axis('off')
# 显示前3个重要通道的热力图
for idx, channel_idx in enumerate(topk_indices, start=1):
# 处理单通道特征图
channel_heatmap = feat_map[channel_idx].numpy()
# 归一化并缩放到原图尺寸
channel_heatmap = (channel_heatmap - channel_heatmap.min()) / (channel_heatmap.max() - channel_heatmap.min() + 1e-8)
resized_heatmap = cv2.resize(channel_heatmap, img_np.shape[:2][::-1])
# 创建叠加可视化
ax = axes[sample_idx, idx]
ax.imshow(img_np)
ax.imshow(resized_heatmap, alpha=0.5, cmap='jet')
ax.set_title(f"Channel {channel_idx.item()} Attention")
ax.axis('off')
plt.tight_layout()
plt.show()
# 调用示例
visualize_attention_map(model, test_loader, device, class_names, num_samples=3)@浙大疏锦行