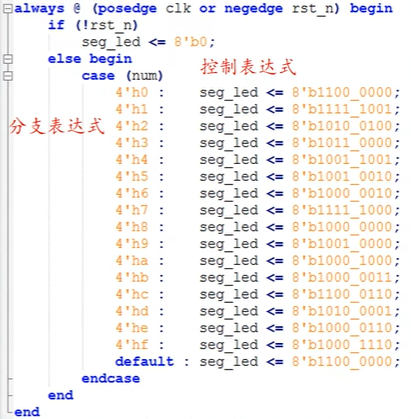
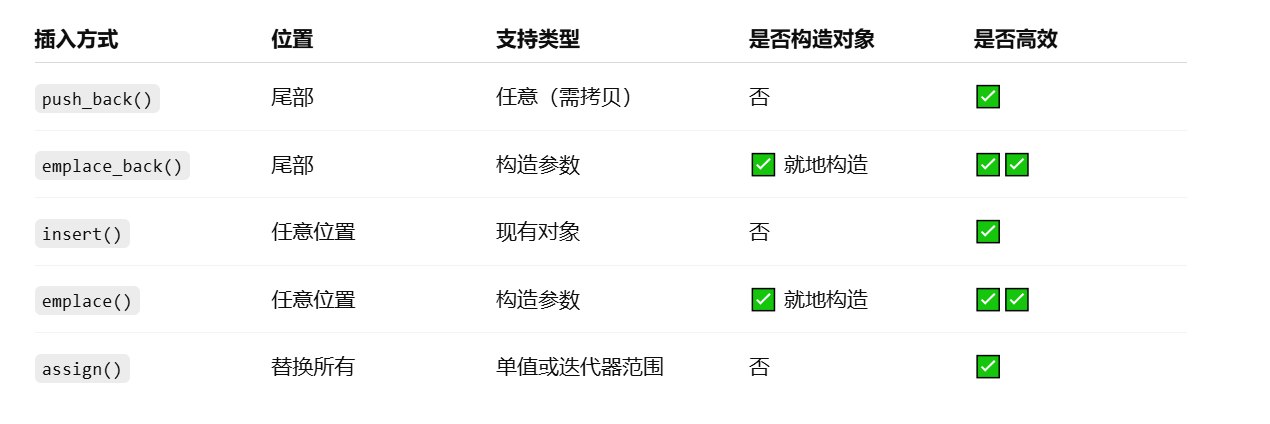
一、软件介绍
文末提供程序和源码下载
RushDB 改变了您处理图形数据的方式 — 不需要 Schema,不需要复杂的查询,只需推送数据即可。

二、Key Features ✨ 主要特点
- Instant Setup: Be productive in seconds, not days
即时设置 :在几秒钟内提高工作效率,而不是几天 - Push Any JSON: Nested objects are automatically normalized into a graph
推送任何 JSON: 嵌套对象自动规范化为图形 - Fractal API: Same query syntax everywhere - learn once, use everywhere
Fractal API:到处都是相同的查询语法 - 一次学习,到处使用 - Vector Search: Comprehensive similarity search for AI-powered applications
向量搜索 :AI 驱动的应用程序的全面相似性搜索 - Zero Schema Headaches: We handle the data structure so you can focus on building
零架构麻烦 :我们处理数据结构,因此您可以专注于构建
三、1.0 中的新增功能
- Vector Search: Comprehensive vector search with similarity aggregates and query builder support
矢量搜索 :具有相似性聚合和查询生成器支持的综合矢量搜索 - Member Management: Complete workspace membership system with invitations and access controls
成员管理 :完整的工作区会员系统,带有邀请和访问控制 - Remote Database: Connect to existing Neo4j/Aura databases
远程数据库 :连接到现有的 Neo4j/Aura 数据库 - Enhanced Auth: Google OAuth support and improved authorization flows
增强的身份验证 :Google OAuth 支持和改进的授权流程 - Documentation: Reworked docs with clear tutorials and guides
文档 :重新设计的文档,提供清晰的教程和指南
四、Quick Start 🚀 快速开始
1. Get RushDB 1. 获取 RushDB
Option A: Use RushDB Cloud (Free Tier Available)
选项 A:使用 RushDB Cloud(提供免费套餐)
# Sign up and get an API token at app.rushdb.com
# No installation required!
Option B: Self-Host with Docker
选项 B:使用 Docker 自托管
docker run -p 3000:3000 \
--name rushdb \
-e NEO4J_URL='neo4j+s://your-instance.neo4j.io' \
-e NEO4J_USERNAME='neo4j' \
-e NEO4J_PASSWORD='password' \
rushdb/platform
2. Start Building 2. 开始构建
Python 蟒
from rushdb import RushDB
db = RushDB("your-api-token")
# Push any nested JSON - RushDB normalizes it into a graph
db.records.create_many(
"COMPANY",
{
"name": "Google LLC",
"rating": 4.9,
"DEPARTMENT": [
{
"name": "Research & Development",
"PROJECT": [
{
"name": "Bard AI",
"budget": 1200000000,
"EMPLOYEE": [
{
"name": "Jeff Dean",
"position": "Head of AI Research",
}
],
}
],
}
],
},
)
# Traverse relationships with intuitive nested queries
employees = db.records.find({
"labels": ["EMPLOYEE"],
"where": {
"position": {"$contains": "AI"},
"PROJECT": {"DEPARTMENT": {"COMPANY": {"rating": {"$gte": 4}}}},
},
})
TypeScript/JavaScript
import RushDB from '@rushdb/javascript-sdk';
const db = new RushDB("your-api-token");
// Push data with automatic relationship creation
await db.records.createMany({
label: "COMPANY",
payload: {
name: 'Google LLC',
rating: 4.9,
DEPARTMENT: [{
name: 'Research & Development',
PROJECT: [{
name: 'Bard AI',
EMPLOYEE: [{
name: 'Jeff Dean',
position: 'Head of AI Research',
}]
}]
}]
}
});
// Simple queries that traverse complex relationships
const aiExperts = await db.records.find({
labels: ['EMPLOYEE'],
where: {
position: { $contains: 'AI' },
PROJECT: { DEPARTMENT: { COMPANY: { rating: { $gte: 4 } } } },
},
});
五、RushDB 的 Fractal API 的强大功能
RushDB uses a consistent query structure across all operations:
RushDB 在所有作中使用一致的查询结构:
interface SearchQuery {
labels?: string[]; // Filter by record labels
where?: WhereClause; // Filter by properties and relationships
limit?: number; // Maximum records to return
skip?: number; // Records to skip (pagination)
orderBy?: OrderByClause; // Sorting configuration
aggregate?: AggregateClause; // Data aggregation
}
This approach means: 这种方法意味着:
- Learn Once, Use Everywhere: The same pattern works across records, relationships, labels, and properties
一次学习,随处使用 :相同的模式适用于记录、关系、标签和属性 - Predictable API: No surprises as you build more complex features
可预测的 API:当您构建更复杂的功能时,不会有任何意外 - Self-Discovering Database: The graph knows its own structure and exposes it consistently
Self-Discovering Database:图形知道自己的结构并始终如一地公开它 - Perfect for AI & RAG: AI agents can explore and generate queries on-the-fly
非常适合 AI 和 RAG:AI 代理可以即时探索并生成查询
🛠️ Self-Hosting Options 🛠️ 自托管选项
Requirements 要求
- Neo4j: Version
5.25.1or higher
Neo4j:版本 5.25.1或更高版本 - APOC Plugin: Required and can be installed either via volume mount or auto-install
APOC 插件 :必需,可以通过卷挂载或自动安装进行安装 - Graph Data Science Plugin: Required for advanced features like vector search and aggregations
Graph Data Science Plugin:矢量搜索和聚合等高级功能需要
Docker Compose Setup Docker Compose 设置
version: '3.8'
services:
rushdb:
image: rushdb/platform
container_name: rushdb
ports:
- "3000:3000"
environment:
- NEO4J_URL=neo4j+s://your-instance.neo4j.io
- NEO4J_USERNAME=neo4j
- NEO4J_PASSWORD=password
- RUSHDB_LOGIN=admin
- RUSHDB_PASSWORD=secure-password
View all environment variables
查看所有环境变量
Development setup with local Neo4j
使用本地 Neo4j 进行开发设置
version: '3.8'
services:
rushdb:
image: rushdb/platform
container_name: rushdb
depends_on:
neo4j:
condition: service_healthy
ports:
- "3000:3000"
environment:
- NEO4J_URL=bolt://neo4j
- NEO4J_USERNAME=neo4j
- NEO4J_PASSWORD=password
neo4j:
image: neo4j:5.25.1
healthcheck:
test: [ "CMD-SHELL", "wget --no-verbose --tries=1 --spider localhost:7474 || exit 1" ]
interval: 5s
retries: 30
start_period: 10s
ports:
- "7474:7474"
- "7687:7687"
environment:
- NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
- NEO4J_AUTH=neo4j/password
- NEO4J_PLUGINS=["apoc", "graph-data-science"]
CLI Commands CLI 命令
View available CLI commands
查看可用的 CLI 命令
Create a New User
rushdb create-user admin@example.com securepassword123
Update User Password
rushdb update-password admin@example.com newsecurepassword456
六、软件下载
迅雷云盘
本文信息来源于GitHub作者地址:GitHub - rush-db/rushdb: RushDB is an Instant Database for Modern Apps & AI. Built on top of Neo4j.