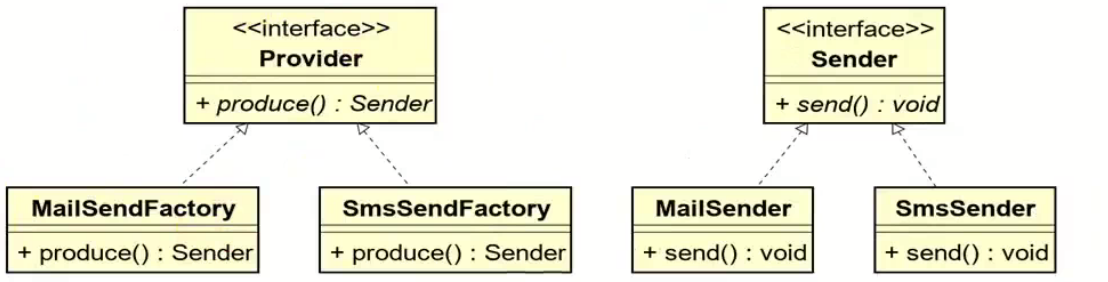
在C++中,string和wstring是两种用于处理不同字符编码的字符串类型,分别基于char和wchar_t字符类型。以下是它们的详细说明和对比:
1. 基础定义
-
string-
类型:
std::string -
字符类型:
char(通常为8位) -
编码:依赖于系统/编译器,通常是ASCII或UTF-8(但不保证)。
-
头文件:
<string> -
示例:
std::string s = "Hello, 世界"; // 非ASCII字符可能显示异常(取决于编码)
-
-
wstring-
类型:
std::wstring -
字符类型:
wchar_t(宽度由编译器决定,Windows为16位,Linux/macOS通常为32位) -
编码:Windows下常为UTF-16,其他平台可能为UTF-32。
-
头文件:
<string> -
示例:
std::wstring ws = L"Hello, 世界"; // 宽字符支持Unicode
-
2. 关键差异
| 特性 | string (char) | wstring (wchar_t) |
|---|---|---|
| 字符宽度 | 8位(可能因平台/编码变化) | 16位(Windows)或32位(其他) |
| Unicode支持 | 依赖UTF-8(需显式处理) | 直接支持(Windows UTF-16) |
| 字面量前缀 | 无(或u8前缀,C++11起) | L(如L"text") |
| 内存占用 | 紧凑(变长编码如UTF-8) | 固定宽度(可能更占内存) |
| 跨平台一致性 | 高(UTF-8通用) | 低(wchar_t大小依赖平台) |
3. Unicode处理
-
string+ UTF-8-
现代C++推荐使用
std::string存储UTF-8编码的Unicode文本。 -
需确保输入/输出流的编码正确处理(如控制台、文件)。
-
示例:
std::string utf8_str = u8"你好"; // C++11起支持u8前缀
-
-
wstring+ UTF-16/32-
在Windows API中常用(如
SetWindowTextW)。 -
其他平台可能不兼容(
wchar_t实现差异)。 -
示例:
std::wstring wide_str = L"こんにちは";
-
4. 转换与互操作
-
转换函数
需使用<locale>或<codecvt>(C++11起,但C++17弃用codecvt):#include <locale> #include <codecvt> // wstring → string (UTF-8) std::wstring_convert<std::codecvt_utf8<wchar_t>> converter; std::string utf8_str = converter.to_bytes(wide_str); // string → wstring std::wstring wide_str = converter.from_bytes(utf8_str); -
替代方案(C++17后)
推荐使用第三方库(如ICU、Boost.Locale)或系统API(如Windows的WideCharToMultiByte)。
5. 性能与适用场景
string更优场景:- 网络传输、文件存储(UTF-8兼容性好)。
- 内存敏感型应用(变长编码节省空间)。
wstring更优场景:- Windows原生API调用(如GUI编程)。
- 需要固定宽度字符处理(如某些文本算法)。
6. 现代C++的扩展
- 新字符类型(C++11)
char16_t(UTF-16):std::u16stringchar32_t(UTF-32):std::u32string- 更明确的Unicode支持,但需注意跨平台兼容性。
总结
- 优先使用
string:默认选择,尤其是需要跨平台或UTF-8编码时。 - 谨慎使用
wstring:仅在特定场景(如Windows API)或需要固定宽字符时使用。 - Unicode处理:明确编码约定,避免混用导致乱码。
正确选择取决于具体需求(平台、API、性能、编码)。