目录
一、CBAM 模块简介
二、CBAM 模块的实现
(一)通道注意力模块
(二)空间注意力模块
(三)CBAM 模块的组合
三、CBAM 模块的特性
四、CBAM 模块在 CNN 中的应用
一、CBAM 模块简介
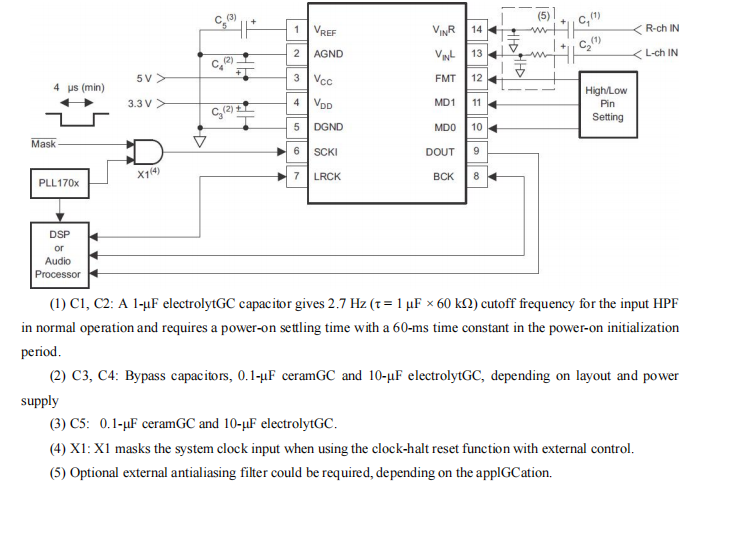
在之前的探索中,我们已经了解了 SE(Squeeze-and-Excitation)通道注意力模块,它通过关注特征图的通道维度,提升了模型对重要特征的感知能力。然而,SE 模块仅关注“哪些通道重要”,而忽略了“重要信息在空间中的位置”。这就好比我们只看到了一幅画的整体色调,却没注意到画中最吸引人的细节所在。
而 CBAM 模块正是为了解决这一局限而生。它是一种可以无缝集成到任何卷积神经网络架构中的注意力模块,核心目标是通过学习的方式,自动获取特征图在通道和空间维度上的重要性,并对特征图进行自适应调整。简单来说,它就像是给模型装上了一副“智能眼镜”,让模型能够更精准地聚焦于图像中关键的部分,从而提升模型的特征表达能力和性能。
CBAM 由两个主要部分组成:通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module)。这两个模块顺序连接,共同作用于输入的特征图。通道注意力模块负责分析“哪些通道的特征更关键”,例如图像中的颜色、纹理通道等;空间注意力模块则定位“关键特征在图像中的具体位置”,比如物体所在区域。二者的结合,让模型同时学会“关注什么”和“关注哪里”,极大地提升了特征表达能力。
二、CBAM 模块的实现
(一)通道注意力模块
通道注意力模块的实现思路是通过全局池化操作(包括全局平均池化和全局最大池化)分别提取特征图的全局平均信息和全局最大信息,然后将这两种信息分别送入共享的全连接层网络中进行学习,最后将两个分支的结果相加并通过 Sigmoid 函数得到通道权重,再将权重与原始特征图相乘,实现对重要通道的增强和不重要通道的抑制。
以下是通道注意力模块的代码实现:
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
"""
通道注意力机制初始化
参数:
in_channels: 输入特征图的通道数
ratio: 降维比例,用于减少参数量,默认为16
"""
super().__init__()
# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享全连接层,用于学习通道间的关系
# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层
nn.ReLU(), # 非线性激活函数
nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层
)
# Sigmoid函数将输出映射到0-1之间,作为各通道的权重
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
前向传播函数
参数:
x: 输入特征图,形状为 [batch_size, channels, height, width]
返回:
调整后的特征图,通道权重已应用
"""
# 获取输入特征图的维度信息,这是一种元组的解包写法
b, c, h, w = x.shape
# 对平均池化结果进行处理:展平后通过全连接网络
avg_out = self.fc(self.avg_pool(x).view(b, c))
# 对最大池化结果进行处理:展平后通过全连接网络
max_out = self.fc(self.max_pool(x).view(b, c))
# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重
attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道
return x * attention # 这个运算是pytorch的广播机制(二)空间注意力模块
空间注意力模块的核心思想是先对特征图进行通道维度的池化操作(包括平均池化和最大池化),得到两个描述特征图空间分布的特征图,然后将这两个特征图拼接在一起,通过一个卷积层进行特征提取,最后将得到的空间注意力权重与原始特征图相乘,实现对空间位置的加权。
以下是空间注意力模块的代码实现:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通道维度池化
avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)
max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)
pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)
attention = self.conv(pool_out) # 卷积提取空间特征
return x * self.sigmoid(attention) # 特征与空间权重相乘(三)CBAM 模块的组合
CBAM 模块就是将通道注意力模块和空间注意力模块按照顺序连接起来,先进行通道注意力的调整,再进行空间注意力的调整。这种串行的结构使得特征图先在通道维度上被优化,然后再在空间维度上被优化,从而实现对特征图的全面增强。
以下是 CBAM 模块的代码实现:
class CBAM(nn.Module):
def __init__(self, in_channels, ratio=16, kernel_size=7):
super().__init__()
self.channel_attn = ChannelAttention(in_channels, ratio)
self.spatial_attn = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attn(x)
x = self.spatial_attn(x)
return x三、CBAM 模块的特性
-
轻量级设计:CBAM 模块仅增加了少量的计算量,主要是全局池化和简单的卷积操作,因此它非常适合嵌入到各种 CNN 架构中,例如 ResNet、YOLO 等,不会对模型的性能产生过大的负担。
-
即插即用:CBAM 模块的设计非常灵活,无需修改原有模型的主体结构,可以直接作为模块插入到卷积层之间,方便我们对现有的模型进行升级和优化。
-
双重优化:CBAM 模块同时对通道和空间维度的特征进行优化,能够提升模型在复杂场景下的性能,例如小目标检测、语义分割等任务。通过增强重要特征和抑制不重要特征,模型能够更好地捕捉到图像中的关键信息,从而提高特征表达能力。
四、CBAM 模块在 CNN 中的应用
为了验证 CBAM 模块的效果,我将其应用到了一个简单的 CNN 模型中,并使用 CIFAR-10 数据集进行了训练和测试。以下是带有 CBAM 模块的 CNN 模型的代码实现:
class CBAM_CNN(nn.Module):
def __init__(self):
super(CBAM_CNN, self).__init__()
# ---------------------- 第一个卷积块(带CBAM) ----------------------
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32) # 批归一化
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2)
self.cbam1 = CBAM(in_channels=32) # 在第一个卷积块后添加CBAM
# ---------------------- 第二个卷积块(带CBAM) ----------------------
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.cbam2 = CBAM(in_channels=64) # 在第二个卷积块后添加CBAM
# ---------------------- 第三个卷积块(带CBAM) ----------------------
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.pool3 = nn.MaxPool2d(kernel_size=2)
self.cbam3 = CBAM(in_channels=128) # 在第三个卷积块后添加CBAM
# ---------------------- 全连接层 ----------------------
self.fc1 = nn.Linear(128 * 4 * 4, 512)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
# 第一个卷积块
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.cbam1(x) # 应用CBAM
# 第二个卷积块
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.pool2(x)
x = self.cbam2(x) # 应用CBAM
# 第三个卷积块
x = self.conv3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.pool3(x)
x = self.cbam3(x) # 应用CBAM
# 全连接层
x = x.view(-1, 128 * 4 * 4)
x = self.fc1(x)
x = self.relu3(x)
x = self.dropout(x)
x = self.fc2(x)
return x在训练过程中,我设置了 50 个 epoch,并使用了 Adam 优化器和学习率调度器。以下是训练过程中的部分输出信息:
Epoch: 1/50 | Batch: 100/782 | 单Batch损失: 1.8068 | 累计平均损失: 1.9504
Epoch: 1/50 | Batch: 200/782 | 单Batch损失: 1.6703 | 累计平均损失: 1.8310
……
Epoch 1/50 完成 | 训练准确率: 42.49% | 测试准确率: 58.60%
Epoch 2/50 完成 | 训练准确率: 56.67% | 测试准确率: 67.22%
……最终,经过 50 个 epoch 的训练,模型的测试准确率达到了 85.98%。通过观察训练过程中的损失值和准确率变化,可以看到模型在训练过程中逐渐收敛,准确率稳步提升。
@浙大疏锦行