映射:Join 类型、Flattened 类型、多表关联设计
- 1.Join 类型
- 1.1 主要应用场景
- 1.1.1 一对多关系建模
- 1.1.2 多层级关系建模
- 1.1.3 需要独立更新子文档的场景
- 1.1.4 文档分离但需要关联查询
- 1.2 使用注意事项
- 1.3 与 Nested 类型的区别
- 2.Flattened 类型
- 2.1 实际运用场景和案例
- 2.1.1 日志数据处理
- 2.1.2 用户自定义属性
- 2.1.3 API 请求/响应存储
- 2.1.4 第三方数据集成
- 2.2 不足之处
- 2.3 与 Nested / Object 类型的对比
- 3.多表关联设计方案
- 3.1 嵌套对象(Nested Objects)
- 3.2 父子文档(Parent-Child Relationship)
1.Join 类型
在 Elasticsearch 中,Join 类型是一种特殊的数据类型,用于在文档之间建立 父子关系 或 嵌套关系。它允许你在索引中创建类似于关系型数据库中的表连接(join)效果。
Join 类型主要通过以下两个字段实现:
join_field:定义关系的字段。relations:指定父子关系的映射。
1.1 主要应用场景
1.1.1 一对多关系建模
当需要表示一个父文档对应多个子文档时,例如:
- 博客文章(父)、评论(子)
- 订单(父)、订单项(子)
PUT my_index
{
"mappings": {
"properties": {
"join_field": {
"type": "join",
"relations": {
"post": "comment"
}
}
}
}
}
1.1.2 多层级关系建模
需要表示多层级的树形结构,例如:
- 组织架构(公司 → 部门 → 员工)
- 产品分类(大类 → 中类 → 小类)
PUT my_index
{
"mappings": {
"properties": {
"join_field": {
"type": "join",
"relations": {
"company": ["department", "employee"],
"department": "employee"
}
}
}
}
}
1.1.3 需要独立更新子文档的场景
- 场景:当子文档需要频繁独立更新,而父文档相对稳定时。
- 优势:可以单独更新子文档,而不影响父文档。
1.1.4 文档分离但需要关联查询
- 场景:文档逻辑上属于不同实体但需要联合查询。
- 示例:
- 用户基本信息(父)、用户行为日志(子)。
- 产品信息(父)、产品价格历史(子)。
1.2 使用注意事项
- 性能考虑:Join 查询通常比普通查询更耗资源。
- 分片限制:父子文档必须存储在同一个分片上。
- 替代方案:对于简单关系,考虑使用
nested类型或应用层处理。 - 适用版本:Elasticsearch
5.x及以上版本支持。
1.3 与 Nested 类型的区别
| 特性 | Join 类型 | Nested 类型 |
|---|---|---|
| 存储方式 | 独立文档 | 同一文档内嵌 |
| 更新灵活性 | 可单独更新子文档 | 需要更新整个文档 |
| 查询性能 | 相对较慢 | 相对较快 |
| 适用场景 | 大量子文档、频繁更新 | 少量子文档、不常更新 |
Join 类型为 Elasticsearch 提供了处理复杂关系的灵活性,但应根据具体场景权衡使用,因为它在查询性能和资源消耗上会有一定代价。
2.Flattened 类型
Flattened 类型是 Elasticsearch 7.3 版本引入的一种特殊数据类型,主要用于解决以下核心问题:
- 动态字段爆炸问题:当索引包含大量不可预知的动态字段时,会导致映射膨胀,影响集群性能。
- 非结构化数据处理:处理 JSON 文档中未知或高度动态的结构时,避免为每个字段创建独立映射。
- 降低存储开销:减少为大量稀疏字段维护倒排索引的开销。
2.1 实际运用场景和案例
2.1.1 日志数据处理
- 场景:处理不同来源、格式各异的日志数据。
- 案例:集中收集不同应用的日志,各应用日志字段结构不同,且可能随时变化。
PUT logs_index
{
"mappings": {
"properties": {
"log_data": {
"type": "flattened"
}
}
}
}
2.1.2 用户自定义属性
- 场景:电商平台中商品的扩展属性。
- 案例:不同类别的商品有完全不同的属性集,且卖家可自定义添加属性。
PUT products
{
"mappings": {
"properties": {
"custom_attrs": {
"type": "flattened"
}
}
}
}
2.1.3 API 请求/响应存储
- 场景:记录微服务间通信的请求和响应。
- 案例:不同服务的 API 结构差异大,且版本迭代会导致结构变化。
PUT api_monitor
{
"mappings": {
"properties": {
"request": {
"type": "flattened"
},
"response": {
"type": "flattened"
}
}
}
}
2.1.4 第三方数据集成
- 场景:集成来自多个第三方来源的数据。
- 案例:从不同社交平台获取用户数据,各平台数据结构迥异。
2.2 不足之处
- 查询功能限制
- 不支持精确的
term查询,只能使用prefix、wildcard等有限查询方式。 - 无法对
flattened字段中的单个子字段进行独立聚合。
- 不支持精确的
- 搜索性能影响
- 相比常规字段,
flattened字段的查询性能较低。 - 不支持相关性评分(
scoring),所有匹配文档得分相同。
- 相比常规字段,
- 存储效率问题
- 虽然减少了映射膨胀,但存储空间可能比精心设计的映射更大。
- 所有子字段值被索引为关键字,不进行文本分析。
- 功能缺失
- 不支持多字段(
multi-fields)特性。 - 不能指定不同的分析器或分词器。
- 不支持多字段(
- 排序限制
- 不能直接对
flattened字段进行排序操作。
- 不能直接对
2.3 与 Nested / Object 类型的对比
| 特性 | Flattened 类型 | Nested 类型 | Object 类型 |
|---|---|---|---|
| 字段映射膨胀 | 完全避免 | 可能发生 | 可能发生 |
| 查询灵活性 | 有限 | 完全支持 | 完全支持 |
| 存储效率 | 中等 | 较低(重复元数据) | 较高 |
| 适合场景 | 未知 / 动态字段 | 固定结构的数组对象 | 固定结构的嵌套对象 |
| 支持子字段独立查询 / 聚合 | 不支持 | 支持 | 支持 |
Flattened 类型是 Elasticsearch 为特定场景提供的折中方案,它在灵活性和功能完整性之间做了平衡。当面对高度动态、不可预测的数据结构时,它提供了可行的解决方案,但需要清楚其局限性。
3.多表关联设计方案
在 Elasticsearch 中,由于它是面向文档的 NoSQL 数据库,不像关系型数据库那样原生支持 JOIN 操作,因此需要采用特殊的设计方案来实现多表关联。以下是常见的两种方案:
3.1 嵌套对象(Nested Objects)
- 场景:适用于一对多关系,子对象数量较少且不经常独立查询的场景。
- 案例:博客文章与评论。
PUT /blog_index
{
"mappings": {
"properties": {
"title": { "type": "text" },
"author": { "type": "keyword" },
"comments": {
"type": "nested",
"properties": {
"username": { "type": "keyword" },
"content": { "type": "text" },
"timestamp": { "type": "date" }
}
}
}
}
}
查询嵌套对象:
GET /blog_index/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{ "match": { "comments.content": "Elasticsearch" }},
{ "match": { "comments.username": "john" }}
]
}
}
}
}
}
3.2 父子文档(Parent-Child Relationship)
- 场景:适用于一对多关系,子对象数量大或需要独立查询的场景。
- 案例:订单与订单项。
PUT /order_index
{
"mappings": {
"properties": {
"order_id": { "type": "keyword" },
"order_date": { "type": "date" },
"customer_id": { "type": "keyword" },
"relation_type": {
"type": "join",
"relations": {
"order": "item"
}
}
}
}
}
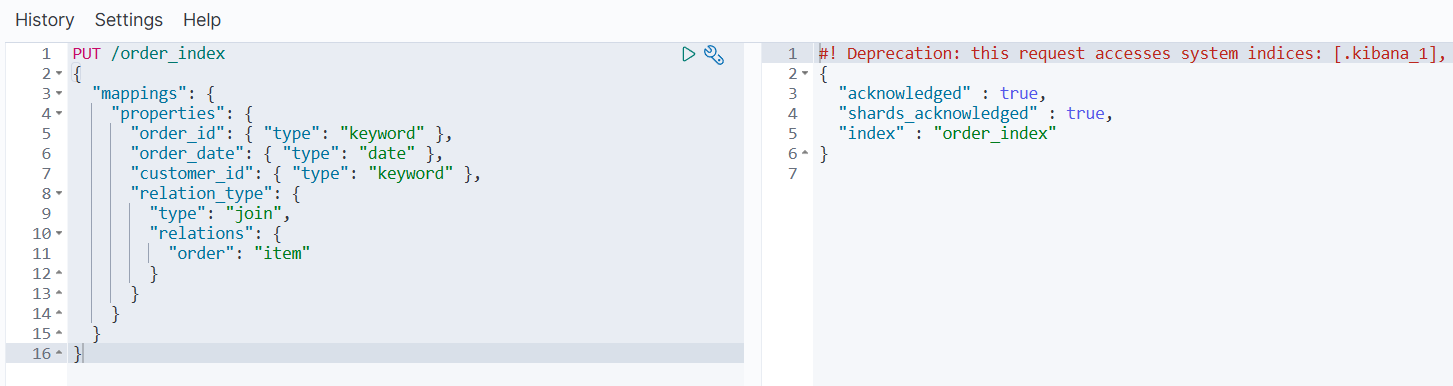
添加父文档(订单):
PUT /order_index/_doc/1
{
"order_id": "ORD001",
"order_date": "2023-01-01",
"customer_id": "CUST123",
"relation_type": {
"name": "order"
}
}
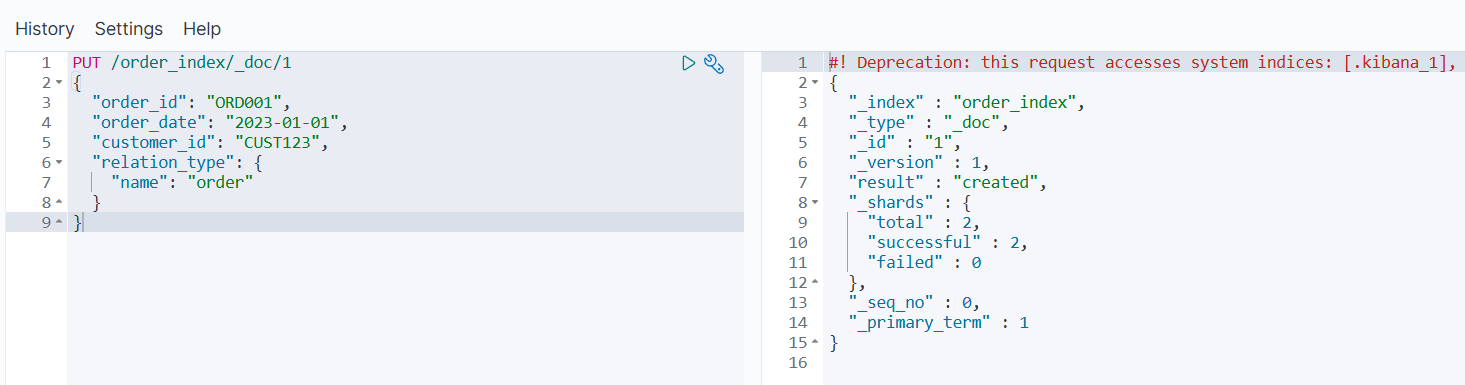
添加子文档(订单项):
PUT /order_index/_doc/2?routing=1
{
"product_id": "PROD456",
"quantity": 2,
"price": 19.99,
"relation_type": {
"name": "item",
"parent": "1"
}
}
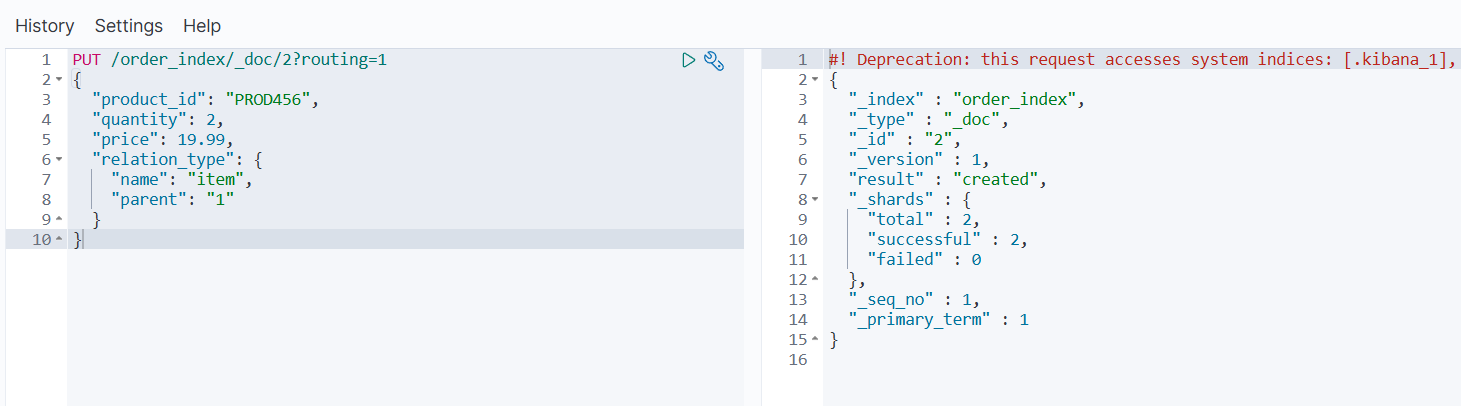
查询子文档:
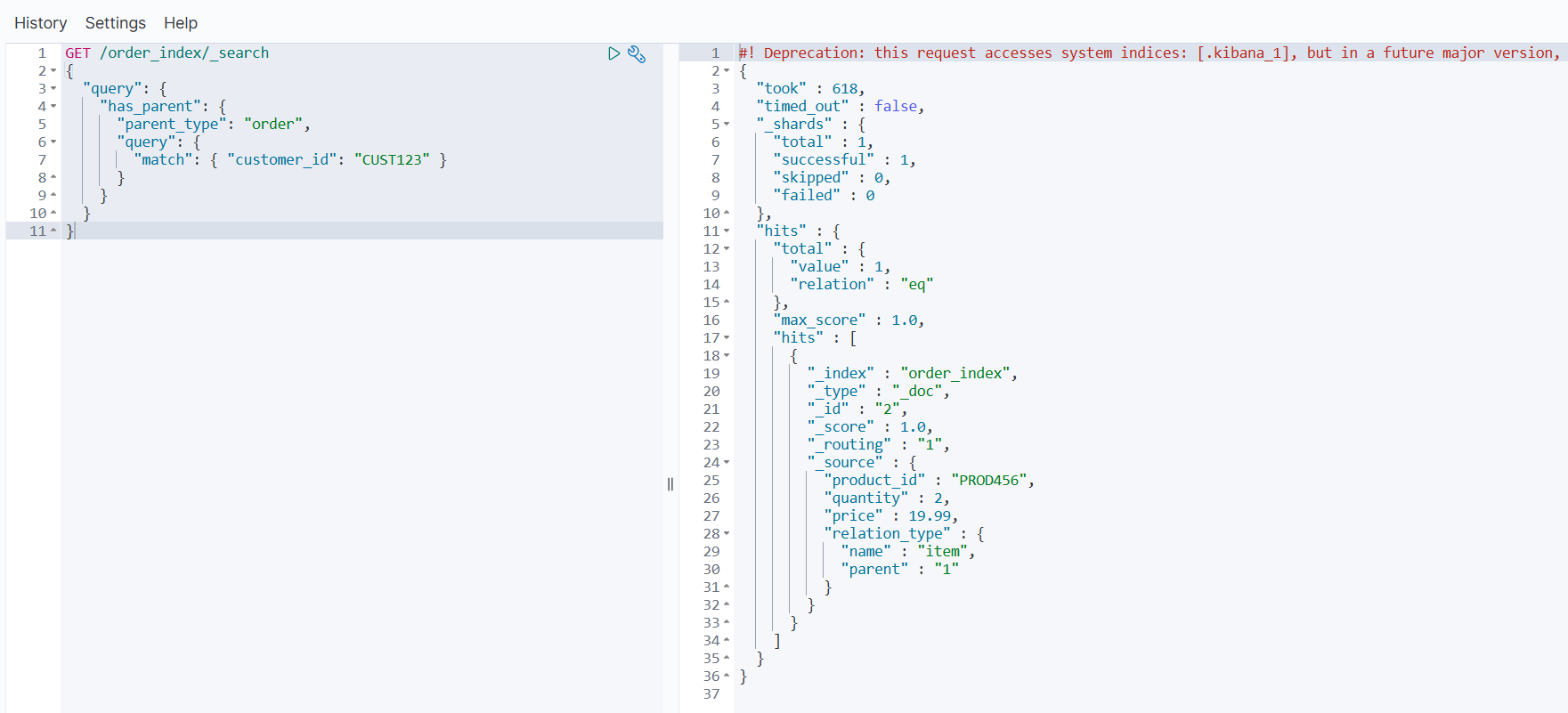
GET /order_index/_search
{
"query": {
"has_parent": {
"parent_type": "order",
"query": {
"match": { "customer_id": "CUST123" }
}
}
}
}
其他方案还包括:
- 应用层关联:先查询一个索引,再根据结果查询另一个索引。
- 数据冗余:将关联数据冗余存储在主文档中。
- 宽表模式:在索引时预先关联好数据。
选择哪种方案取决于查询模式、数据更新频率和性能要求。