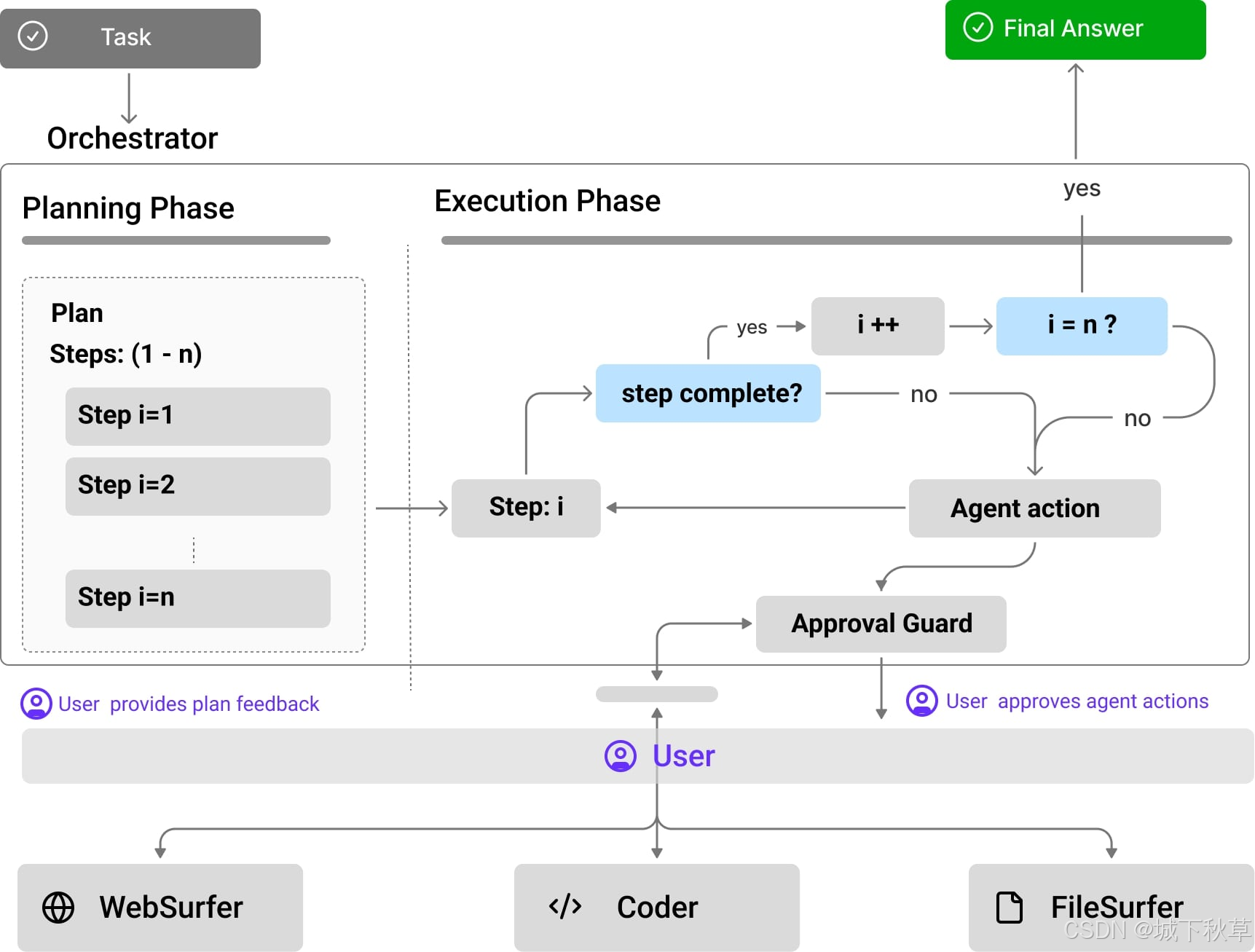
映射:fielddata 详解
- 1.fielddata 是什么
- 2.fielddata 的工作原理
- 3.主要用法
- 3.1 启用 fielddata(通常在 text 字段上)
- 3.2 监控 fielddata 使用情况
- 3.3 清除 fielddata 缓存
- 4.使用场景示例
- 示例 1:对 text 字段进行聚合
- 示例 2:对 text 字段进行排序
- 5.fielddata 与 doc_values 的区别
- 6.注意事项
- 7.最佳实践
1.fielddata 是什么
fielddata 是 Elasticsearch 中一种数据结构,用于在内存中缓存字段数据,主要服务于以下场景:
- 聚合操作(Aggregations)
- 排序(Sorting)
- 脚本计算(Scripting)
- 某些类型的查询(如
field字段上的term查询)
当需要对 text 字段或其他非 doc_values 支持的字段执行上述操作时,Elasticsearch 需要将这些字段的值加载到内存中,这就是 fielddata 的作用。
2.fielddata 的工作原理
- 按需加载:当第一次需要对某个字段执行聚合 / 排序等操作时,Elasticsearch 会从磁盘读取该字段的所有值并构建内存中的数据结构。
- 存储在 JVM 堆内存:
fielddata会占用 JVM 堆内存空间。 - 字段级启用:默认情况下,
text字段禁用fielddata,keyword字段使用doc_values而非fielddata。
3.主要用法
3.1 启用 fielddata(通常在 text 字段上)
PUT my_index/_mapping
{
"properties": {
"my_text_field": {
"type": "text",
"fielddata": true
}
}
}
3.2 监控 fielddata 使用情况
GET _nodes/stats/indices/fielddata?fields=*
3.3 清除 fielddata 缓存
POST my_index/_cache/clear?fielddata=true
4.使用场景示例
示例 1:对 text 字段进行聚合
GET my_index/_search
{
"size": 0,
"aggs": {
"my_terms": {
"terms": {
"field": "my_text_field" // 需要该字段启用 fielddata
}
}
}
}
示例 2:对 text 字段进行排序
GET my_index/_search
{
"sort": [
{
"my_text_field": {
"order": "asc"
}
}
]
}
5.fielddata 与 doc_values 的区别
| 特性 | fielddata | doc_values |
|---|---|---|
| 构建时机 | 查询时按需构建 | 索引时预先构建 |
| 存储位置 | JVM 堆内存 | 磁盘(操作系统缓存) |
| 内存占用 | 高 | 低 |
| 适用字段类型 | 主要为 text 字段 | 主要为 keyword / numeric / date 等字段 |
| 默认启用 | text 字段默认禁用 | 支持的字段默认启用 |
6.注意事项
- 内存消耗:
fielddata会显著增加内存使用,特别是高基数(大量唯一值)字段。 - 性能影响:首次加载
fielddata可能导致查询延迟。 - 替代方案:对于
keyword/numeric/date等字段,优先使用doc_values。 - 熔断机制:Elasticsearch 有
fielddata熔断器防止内存耗尽。
7.最佳实践
-
尽量避免在
text字段上启用fielddata。 -
如需对文本进行聚合/排序,考虑使用多字段(
multi-field)映射:"my_field": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }然后对
my_field.keyword进行操作。 -
监控
fielddata内存使用,设置合理的熔断阈值。