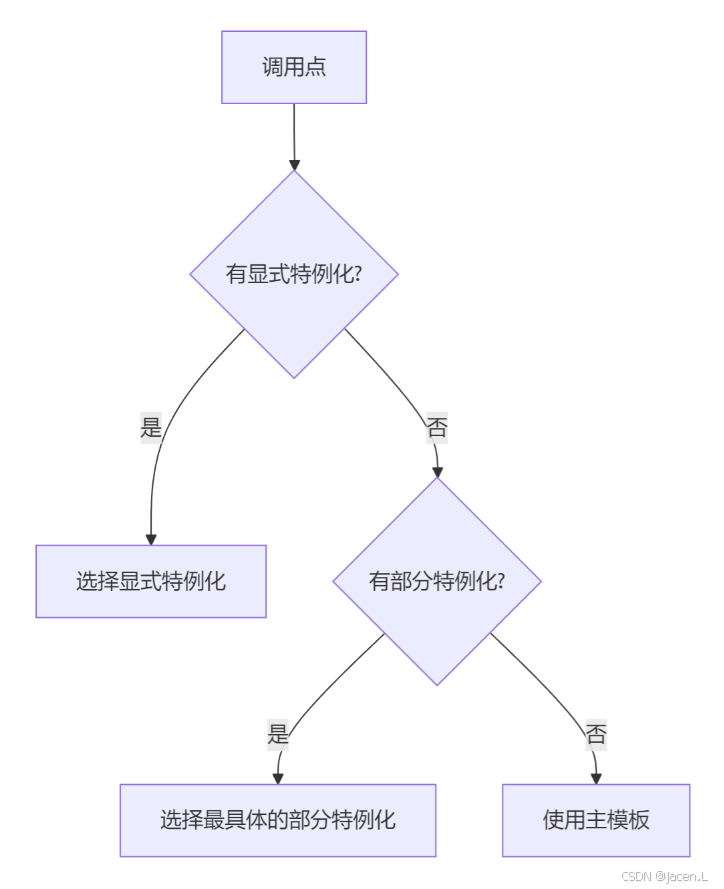
磁盘使用的最后一层抽象:文件系统
今天我们讲第31讲,这一讲将完成磁盘对磁盘使用的最后一层抽象。对此板使用最后一层抽象,抽象出来的是什么呢?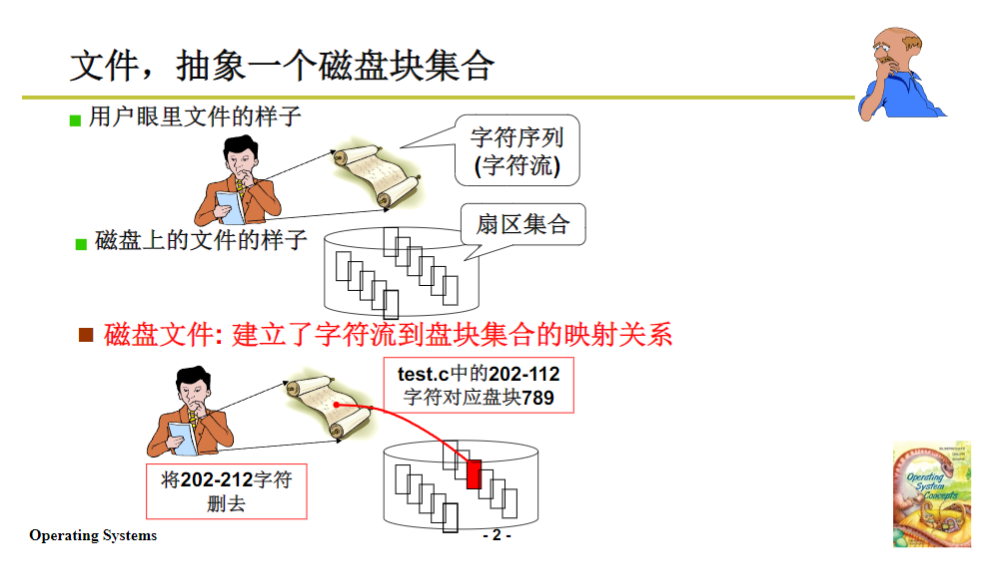
实际上我们使用过磁盘,大家应该有这样的认识,最后不管这个磁盘是在windows上,在linux上还是在什么系统下面,也不管它里面是什么样的格式,最后给用户的感觉就是一个目录树。
这个目录从根目录开始,比如说底下可能有windows目录、system目录等等。也就是说,不管什么样的磁盘、在哪里,最后给用户展现出来的就是这样一棵目录树。既然是一棵目录树,那么这个目录树放在linux上应该好使,能形成一棵这样的树;放在windows上,也应该形成这样的树。所以,磁盘最后就形成了一个文件系统,它是一个子系统,可以独立工作。
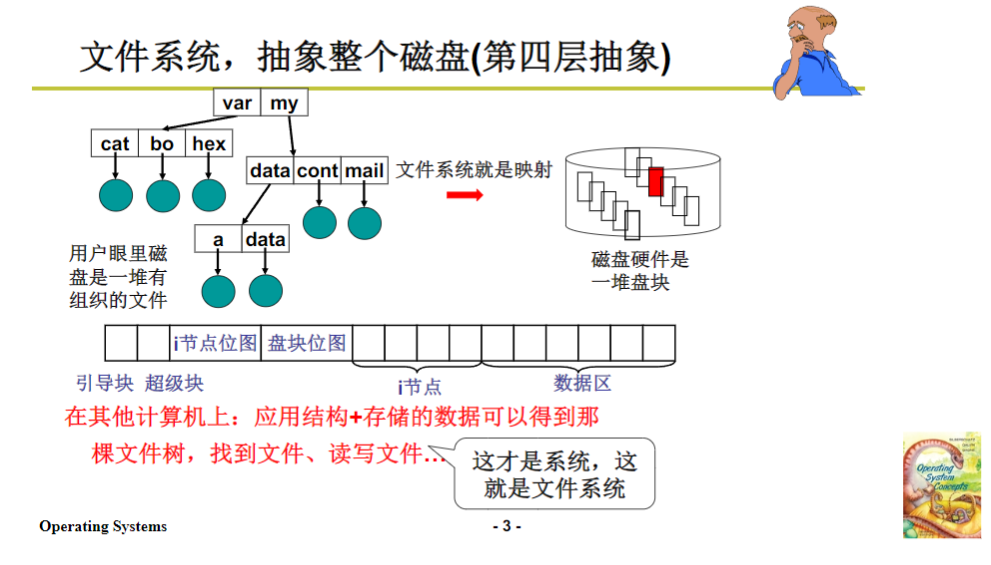
这个磁盘上面一旦抽象为这样的系统以后,在windows上的这个文件系统可以把硬盘拔下来放在linux上面,在linux上面能把这个目录数展开,并且在这个目录书中去相应地找到相应的文件来进行读写。这就是操作系统上对磁盘使用的最后一层抽象,整个磁盘变成一颗目录树。
这一棵目录树里面放的是一堆文件,目录树是用来组织一堆文件的,这和前面我们讲的课程正好呼应。前面我们讲的是一个文件怎么找到那些盘块来读写,一个文件对应的是一个盘块集合,操作系统将文件这个字符流映射成一堆盘块。而今天要讲的文件系统,不是一个文件到一堆盘块的集合,因为整个磁盘上存放的是一堆文件,最终形成的是一堆文件以树状结构的组织方式。
这种组织方式是给用户的一种感觉,实际上磁盘里面就是一堆盘块,它要完成将整个磁盘的所有盘块进行抽象组织,所谓抽象就是用数据结构进行组织。之前讲文件的时候用innode进行组织这些盘块形成一个字符序列,这里就是将整个磁盘按照一定的方式存放一定的信息,最后形成给用户的这样一种抽象的结构。
对于文件系统来说,就是将整个磁盘抽象成这个样子,在整个磁盘上要存放一些信息,比如位图等。在磁盘块上,磁盘操作系统在一堆盘块上存放各种各样的信息,这些信息经过操作系统读、维护以后,就形成了这样一个样子。反过来,用户给出使用方式,操作系统负责将这个方式根据在磁盘块维护的数据结构和抽象关系,把用户抽象的使用最后落实为盘块的读写。因为整个磁盘的使用,最后必须是扇区的使用,用out发出c h s才好使。
从下往上说,文件系统就是形成将整个磁盘的盘块存储上面存储映射关系,维护结构,使得在用户眼里形成基于树状的目录树和文件组织结构;从上往下说,就是用户按照这种结构去存取、访问、管理文件,操作系统把用户的读写通过映射关系转化成对扇区的读写,最后落实到磁盘上。底层的结构是对上层的一种实现,而上层就是对底层这种抽象,用户眼里看到的就是这个目录树,这个目录树可以放在不同机器、不同操作系统上展开。
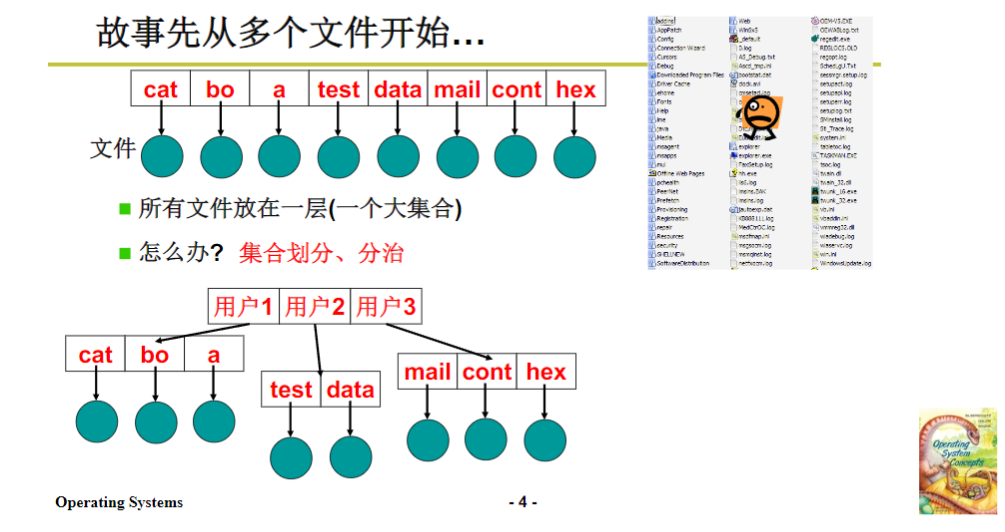
由此可以看出来,今天要讲的就是操作系统如何完成这个映射,完成从一堆文件到整个磁盘的映射,核心就是多个文件怎么处理。为什么我们总是说树状结构呢?在操作系统发展史上,它有一个演变的过程。最开始操作系统的一堆文件就放在一层,没有目录概念,这样在一个系统中有成千上万文件时,查找非常困难,不方便用户使用。后来尝试一个用户一个,但每个用户的文件垒在一起数量还是很多,也不好用。所以才引出了目录树的结构,目录树是典型的分层,这种结构清晰、可扩展性好,方便用户使用。
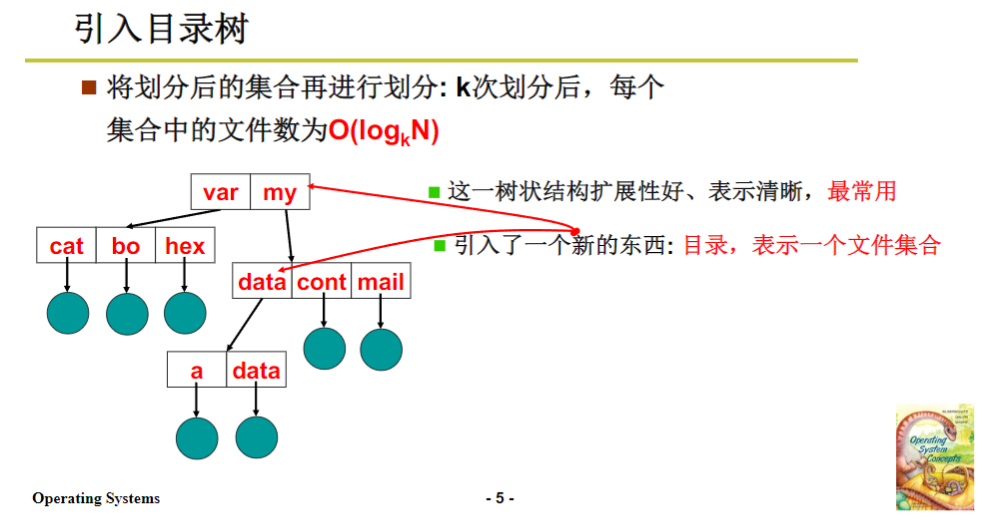
目录树结构中产生了目录这个概念,通过目录形成树状结构,实现这个结构就是对多个文件的组织结构。而实现这个结构的核心就在于目录的实现,将目录实现了,树状结构就有了,多个文件就能放到磁盘上。所以,目录实现成为关键,首先要明白目录怎么用。
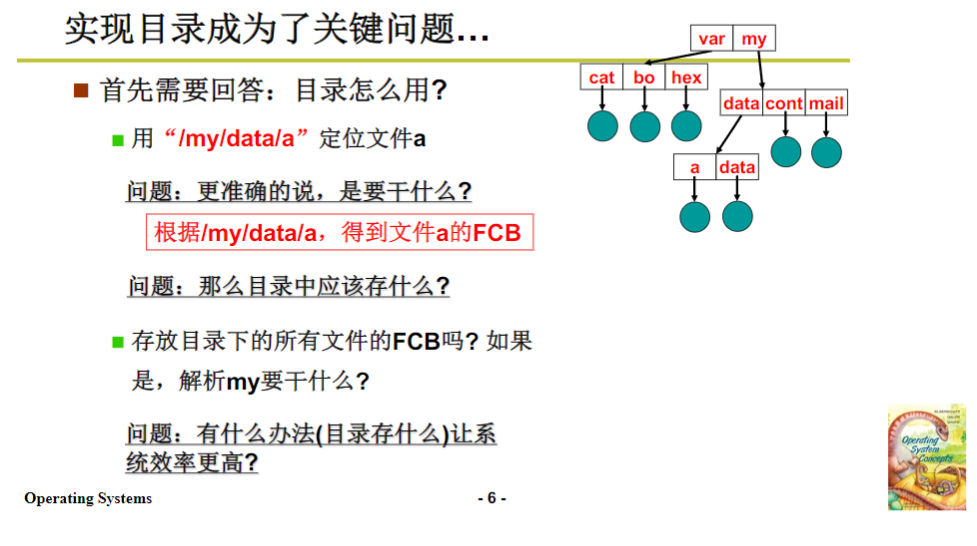
用户使用目录形成这样一种结构对应的是程序,我们要解析用户在程序中使用目录的方式。用户从上面发下来的是一个路径名,open这个路径名时,这个路径名实际上就是从树根到某个节点的一条路,形成了树状结构。我们要做到的核心事情是根据这个路径名找到文件对应的fcb,上次讲已知文件的innode就能读写文件,现在是给一个路径,找到文件的innode,再和前面的知识衔接,就可以访问整个目录树。
所以,最关键的就是给一个路径名,根据树状结构产生的路径名,得到文件的fcb,完成路径名到fcb的映射,再通过fcb映射到盘块,最后落实到磁盘扇区的映射。完成这样的映射,操作系统就能实现出一颗目录树,用户就能在目录树上按照一定方式使用。
如何根据路径名找到fcb
拉回话题,我们讲最关键的问题,怎么根据路径名找到fcb呢?关键就在于目录中存放的到底是什么,目录是怎么实现的,核心就是磁盘块上应该存放什么信息来实现目录。
我们来看,目录中应该有什么呢?比如my目录下有data目录、count文件等三个文件,目录也是一个文件。那么目录中应该存放什么才能根据my找到里面的文件呢?直观想法是,my目录下能不能存放里面所有文件的fcb信息,把所有文件的fcb放在一起存在my目录下,找到my后把这些fcb全读出来挨个匹配,的确是一种方案,但这种方案比较慢。
my目录要找到里面文件,需要匹配文件名这个字符串,根据字符串找到对应的fcb。如果把目录下所有文件的fcb全部存放起来,在解析时,因为不知道要找的文件在哪,需要把所有目录项(文件名和fcb)全部读到内存里挨个匹配,很多fcb信息读进来是没有用的,浪费磁盘读取,因为磁盘很慢,所以需要优化。
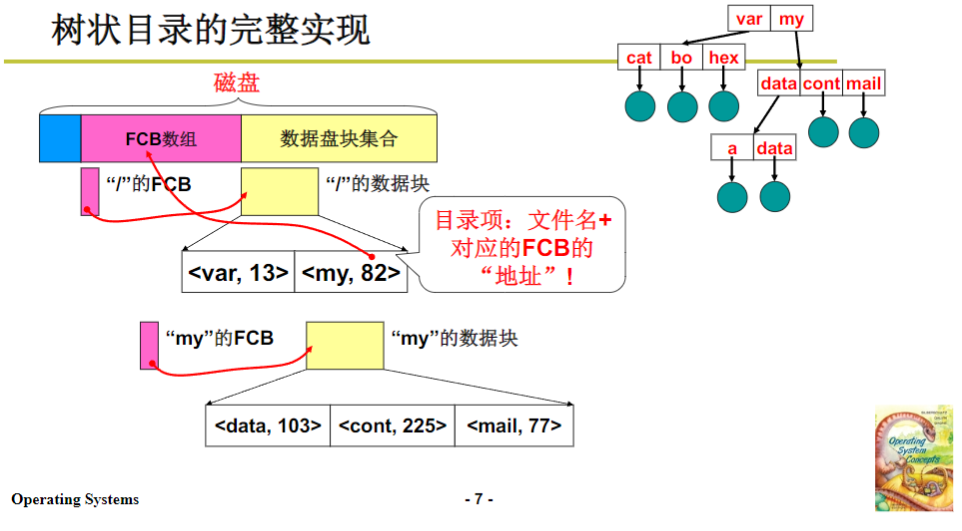
那目录下到底应该存放什么呢?字符串必须有用于匹配,但fcb太大不能存放,还要能通过匹配找到fcb,所以可以存放一个编号。可以把fcb形成一个数组,编号就是数组中的第几项,知道编号和每个fcb的固定长度,就能算出在数组中的位置,进而知道盘块号,发出盘块号的读写就能读出对应的fcb。
这样,一个目录项中存放的是一个字符串加编号,相比存放完整fcb信息短很多,读进来解析快,浪费少。找到目标后,根据编号通过换算能找到对应的盘块和fcb,逐层向下类推,就能找到路径中终点的fcb,这就是目录的完整实现。
目录实现与磁盘格式化
从根目录开始,根目录没有其他信息告知其位置,所以根目录必须固定,一般放在固定位置,比如fcb数组中的第一项(编号为0)。但根目录不能在磁盘第一块,因为前面还要放一些信息,如磁盘大小、能存放文件数量等。

磁盘格式化时,需要记录根目录位置,记录的信息可以放在磁盘固定位置。这样,磁盘从一个机器插到另一个机器上,读取磁盘信息就能找到根目录。一旦找到根目录,它是个文件,根据根目录fcb中存放的信息就能找到其数据块,数据块里就是根目录存放的内容,即根目录下各个文件的位置信息(文件名和对应的fcb编号),再根据这些信息继续查找,就能找到其他文件。
要想整个文件系统能独立工作,磁盘插到不同机器上都能正常使用,还需要一些信息。关键在于根目录信息,所以整个磁盘要被格式化成特定样子,才能完成目录树解析,根据路径名从根目录开始找到目标文件的fcb。
磁盘格式化后,前面要放一个超级块,还可能有引导块(引导扇区固定大小)。超级块从磁盘0开始,引导块之后就是超级块,根据超级块里面的信息读出来,能获得一些关键信息,如不同区域长度等。通过这些信息就能算出根目录位置,一旦知道根目录位置,后面的目录树内容就能读进来,目录树就有了。
磁盘格式化后的工作与文件读写流程
一个磁盘格式化成这样以后,插到任何地方,通过读固定位置的超级块,解析里面的内容,就可以找到根目录,并且还可以读写文件、修改维护数据结构、申请新的空闲块、申请和释放innode等。
这样,我们就完成了一堆文件在磁盘上目录树结构的实现,核心是目录的实现和解析。为了找到根目录,需要将整个磁盘格式化成特定样子,有超级块、innode位图、空闲板块位图,在超级块里放一些信息来找到根目录。
到这里,理论部分全部结束,完成了全部映射。在这个映射下,磁盘是怎么使用的呢?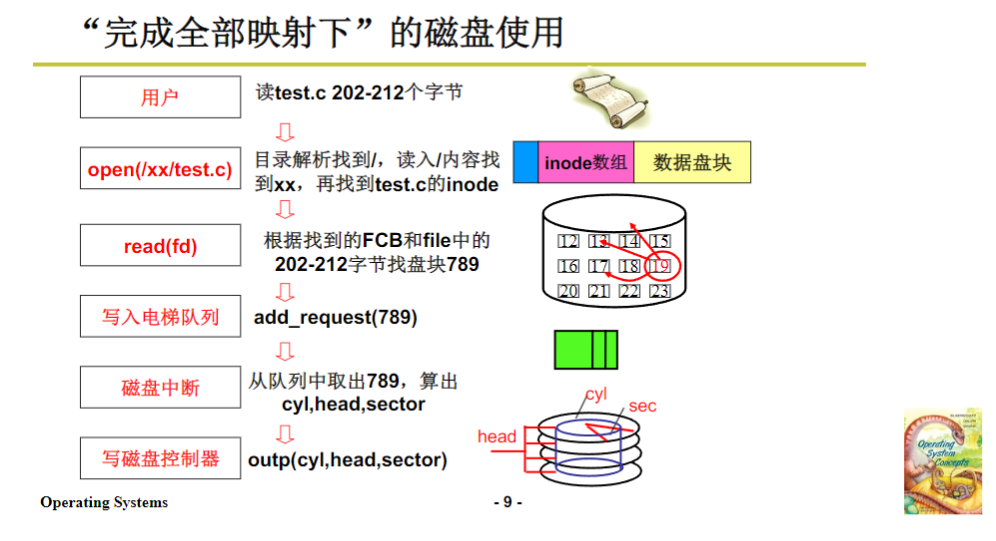
比如用户要读文件的某段字节,我们做的工作首先是open这个文件,从根目录开始,根据磁盘格式化的样子,从super block里面找到根目录,再找到各级目录,最后找到目标文件的fcb。
然后是read操作,根据innode和要读取的位置信息,找到对应的盘块,比如通过索引、链表或数组等结构找到盘块号。找到盘块号后,用内层抽象的电梯算法将盘块放在电梯队列中。在磁盘中断的时候,把盘块取出来,根据硬件参数(在bios中已获得,实验一时也让大家得到过这些参数)算出c h s关键数字,通过alt发给磁盘控制器,磁盘控制器驱动马达去读盘块,找到读写位置,将信息读到内存里。
到此为止,磁盘驱动的全部故事结束了,下次课我们讲目录这一部分的代码实现,把代码实现完整起来,就能编写一个小的文件系统。大家回去可以做相关实验,虽然这次实验不是文件系统,是一种特殊问题p l o c文件,但我们曾说过有八个实验加四个大型实验,其中一个大型实验就是做一个小型文件系统,大家感兴趣可以去做。