大家读完觉得有帮助记得关注和点赞!!!
抽象
视频生成的最新进展需要越来越高效的训练配方,以减轻不断上升的计算成本。在本报告中,我们介绍了 ContentV,这是一种 8B 参数文本到视频模型,在 256 上训练后实现了最先进的性能(VBench 上的 85.14 分)×64 GB 神经处理单元 (NPU),仅需 4 周。ContentV 通过文本提示生成多种分辨率和持续时间的多样化高质量视频,这得益于三项关键创新: (1) 一种极简架构,可最大限度地重用预先训练的图像生成模型进行视频生成; (2) 利用流程匹配提高效率的系统多阶段训练策略;和 (3) 具有人工反馈框架的具有成本效益的强化学习,无需额外的人工注释即可提高生成质量。 所有代码和模型都可以在以下网址获得: https://contentv.github.io.

图 1:视频生成示例。ContentV 可以根据文本提示生成多样化、有创意和高质量的多分辨率视频。
1介绍
长期以来,视频生成一直被认为是一项极具挑战性的任务,主要是因为难以对复杂的时间动态和空间细节进行建模。随着 Sora 的发布[6]通过 OpenAI,基于扩散变压器 (DiT) 架构的潜在扩散模型在该领域显示出巨大的潜力,激发了一系列开源工作,例如 Open-Sora-Plan[26]、CogVideoX[52], HunyuanVideo[21]、Step-Video-T2V[29]和 Wan2.1[46].
但是,当前的视频生成模型通常需要大量的计算资源进行训练。此外,视频的长序列特性导致 GPU 内存需求异常高,必须使用高级 GPU,这严重阻碍了该领域的进步。例如,MovieGen[36]使用 6144 个 H100 GPU 训练 30B 模型𝒪(100 M) 视频和𝒪(1 B) 图像。此外,我们观察到现有方法主要采用 “图像优先,视频后 ”的两阶段训练范式。这就提出了一个关键问题:我们能否直接利用开源社区中成熟的图像生成模型(例如 Stable Diffusion 3[12]通量[24])并调整它们以快速获得视频生成能力?
为了解决这个问题和相关挑战,本技术报告介绍了 ContentV,这是第一个基于 Stable Diffusion 3.5 Large (SD3.5L) 的开源视频生成模型,它完全在 NPU 上进行训练。我们系统地共享我们的数据管理管道、模型架构适应、训练基础设施,以及大规模的训练前和训练后配方。我们的研究结果表明,潜在扩散模型对变分自动编码器 (VAE) 替换表现出显着的适应性。具体来说,只需将SD3.5L中的VAE替换为3D-VAE,并结合3D位置编码,即可在原始图像模型上快速获得视频生成能力。 通过多种分辨率和持续时间的大规模预训练,该模型学习生成以提示为条件的多样化和创造性的视频。通过监督微调 (SFT) 和人工反馈强化学习 (RLHF) 的进一步增强显著提高了其指令跟随能力和视觉质量。
对于训练基础设施,我们设计了一个利用 64GB 内存 NPU (AI 加速器作为 GPU 替代品)的分布式训练框架。通过将特征提取和模型训练解耦到单独的集群中,并将异步数据管道与 3D 并行策略集成,我们实现了 480P 分辨率、24 FPS、5 秒视频的高效训练。经过 256 个 NPU 的一个月培训后,ContentV 在 VBench 上得分为 85.14[19],优于 CogVideoX-5B[52]和 HunyuanVideo-13B[21],同时也保持了对 Wan2.1-14B 的略微优势[46]在人类评估中。这项工作为资源有限环境中的视频生成研究建立了一条新的技术途径。
2相关工作
在过去几年中,扩散模型[17,11]在图像生成方面表现出卓越的能力[41,39,33,12,24].随着这些图像生成技术的快速发展和广泛采用,人们的注意力越来越多地转向将图像扩展到时间域:由多个连续帧组成的视频。
早期的文本到视频生成模型[44,18,14,15,5,48]主要专注于通过整合可学习的时间层来调整预训练的文本到图像架构以生成视频。这些方法通常采用分层级联管道,包括关键帧生成、时间上采样和空间上采样的不同阶段。然而,一些限制阻碍了它们的有效性。一些方法[44,18]直接在像素空间中执行视频生成,事实证明,这计算成本高昂且难以优化。此外,即使利用变分自动编码器将像素空间中的视频映射到潜在空间,这些方法也往往无法利用视频数据中固有的时间冗余,从而导致优化效率低下和性能欠佳。此外,级联结构需要复杂的生成工作流程,并排除了端到端优化。
空的首次亮相[7]2024 年初代表了该领域的关键进步。利用具有全注意力机制的 3D-VAE 架构[32],Sora 演示了扩展计算资源和训练数据如何产生实质性改进。具体来说,Sora 实现了出色的时空一致性,生成了具有连贯叙事的扩展视频序列,并促进了无缝视频连续。此外,Sora 模拟物理交互的能力表明它作为能够编码物理动力学的世界模型的潜力,从而促进了对高保真视频合成方法的研究兴趣。
Sora 令人印象深刻的表现和巨大的潜力引发了学术界的研究热潮,并促使工业界增加了资源投资,推动了该领域的快速发展。Open-Sora 等开源模型[57]、Open-Sora-Plan[26]、麻糬-1[45]、CogVideoX[52], HunyuanVideo[21]和 Wan2.1[46]为学术研究提供了坚实的基础,而像 Kling 这样的商业闭源模型[23], 海罗[30]、 活力[43]、PixelVerse[35]、跑道 Gen-3[40]鼠兔[34]和 Veo[13]建立了更易用的介面,促进了视频生成技术在公众中的广泛采用和传播。
3数据管理管道
在现代模型训练中,数据质量和多样性优先于数量。特别是对于生成任务,低质量的数据会使模型的生成结果恶化。在本节中,我们将介绍用于大规模高质量数据收集和处理的管道,以及用于数据筛选的各种处理器和标准。
3.1处理和筛选
我们从各种来源收集了原始数据,包括公开可用的学术数据集[42,9,49]以及 CC0 许可的在线网站,例如 Mixkit 和 Pexels。这些数据集涵盖了广泛的场景、动作和视觉风格,这对于训练具有强大泛化能力的视频生成模型至关重要。
鉴于我们的原始数据来源多种多样,很大一部分视频质量较低,这大大降低了视频生成的性能。为了解决这个问题,我们使用了一个全面的内容感知数据过滤管道,该管道对内部视频维度进行作,以提高数据集的整体质量。
视频分段
原始视频的时长从几秒到几小时不等。训练需要将长视频拆分为二级视频剪辑。同时,为了避免视频剪辑中的场景变化,我们使用 PySceneDetect[1]为了区分场景变化,可以将长视频剪辑成连续镜头,然后根据时长拆分成 3 到 6 秒不等的短视频片段。为了确保清晰的时间边界,我们使用时间模式分析进一步去除场景逐渐变化的过渡。
视频去重
我们提出了一种分层重复数据删除方法来解决视频数据集中的数据冗余和不平衡问题。具体来说,我们使用内部嵌入模型进行视频特征提取。 对于原始长视频,我们执行 k-means 聚类以对语义相似的内容进行分组,并应用自适应阈值,其中密度较高的集群使用更严格的相似性阈值进行更积极的重复数据删除。从同一源视频派生的视频剪辑通常显示大量内容和场景重叠。为了减少冗余,我们计算成对特征相似性并丢弃高度相似的剪辑。
字幕和水印检测
我们使用 PaddleOCR[2]查找和裁剪字幕,以及删除包含过多文本的视频剪辑。此外,我们还使用内部检测模型来检测和删除敏感信息,例如水印、徽标和黑色边框。
模糊检测
我们通过计算 Laplacian 算子的方差来检测模糊[31],用作帧清晰度的定量度量。方差值越低,模糊度越高,通常是由于摄像机运动或对焦不准确造成的。
运动动力学
视频中主要物体的动态主要来自两个方面:一是物体本身的运动,二是摄像机镜头的运动带来的前景和背景的同步运动。我们将前景和背景的平均动态分数作为整体动态分数。具体来说,密集的光流是使用 GMFlow 获得的[51].通过拟合透视变换得到近似的背景光流,然后对前景光流进行整流。从而将前景和背景分开,分别计算动态分数。
美学评分
我们使用了基于在 LAION 上训练的 CLIP 模型的改进的审美分数预测器[42]预测每个剪辑中关键帧的美学分数并计算其平均值。
如图 2 所示,使用我们的数据管理管道,我们构建了一个规模为𝒪(100 M) 图像,以及𝒪(10 M) 视频剪辑,时长范围为 2 到 8 秒。
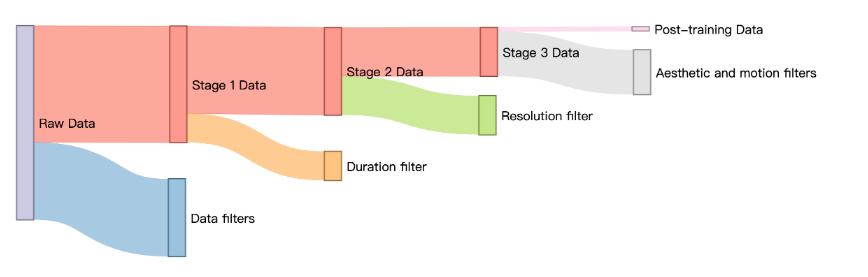
图 2:数据筛选管道的整体。对于筛选后的训练前数据,将根据持续时间和分辨率筛选出来自不同训练阶段的数据。
3.2训练后数据选择
经过数据过滤管道后,过滤掉原始数据中的大量低质量、重复视频,通过视频切片构建了数千万个视频片段的预训练数据集。然而,由于预训练视频数据量大,预训练数据质量的变化范围非常大。此外,我们对预训练数据应用了更严格的过滤标准,获得了 100 万的高质量子集。我们特别强调以下精细的选择标准:
- •
审美分数。在 laion 上训练的审美模型主要针对图像,对高色彩对比度有很强的偏好。与单个图像不同,由于需要时间连续性,从视频中提取的帧将具有帧间平滑效果。我们基于 VideoCLIP 训练了一个视频的美学模型[47],可以同时考虑图片的视觉质量和视频中的文本对齐程度。
- •
运动动力学。在这个阶段,我们更加强调视频主体的运动动态。我们分别以类似于 pre-training 阶段的 foreground 和 background 的方式计算 dynamic 分数。但是,我们给前景动态分数赋予更高的权重,并将前景和背景的加权动态分数作为总动态分数。
对于预训练数据,我们使用这两个更严格的标准对剪辑进行评分和排名,并选择在这两个标准中排名前 10% 的剪辑。总共获得了 100 万个剪辑。
3.3字幕
正如 DALL-E 3 所证明的那样[4],字幕的精度和全面性对于增强生成模型的提示跟随能力和输出质量至关重要。 我们以 1 fps 的速度提取视频帧,并使用 Qwen 2.5 VL 生成密集的字幕[3]多模态模型。我们发现,较大的模型会产生更准确的字幕,同时减轻幻觉效果。但是,使用最大的 72B 模型为数千万个视频生成密集字幕会产生高得令人望而却步的计算成本。因此,我们采用 7B 模型来提供预训练数据,将 72B 模型专门用于后训练中使用的更高质量的子集。
4建筑
在本节中,我们将介绍 ContentV 的架构。与以前的方法不同[52,46,21,37,29]优先考虑新颖的结构设计,我们的方法强调开源文本到图像模型的有效适应,通过最少的架构修改来实现视频生成能力。
4.1概述
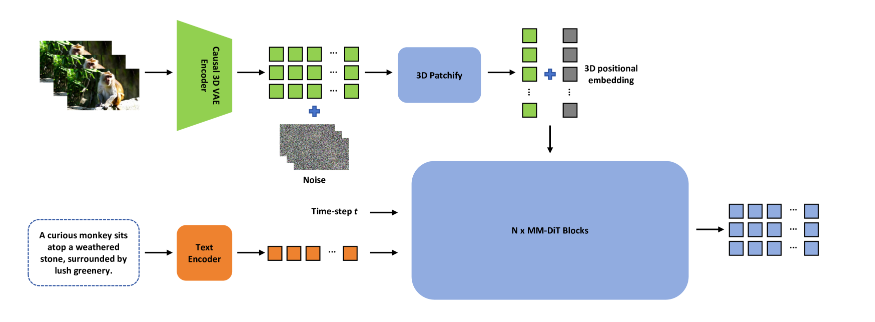
图 3:ContentV 的架构。只需将 SD3.5L 中的 VAE 替换为因果 3D-VAE,并结合 3D 位置嵌入,即可解锁模型的视频生成功能。
如图 3 所示,基于 SD3.5L 的文本到视频扩散模型[12]架构还包括三个组件:变分自动编码器、文本编码器和 DiT。最显著的架构变化发生在变分自动编码器中,其中 3D-VAE 在图像生成中取代了 2D-VAE。此修改使模型能够通过将图像和视频压缩为统一的潜在表示来处理图像和视频。3D-VAE首先压缩输入的视觉数据,然后通过3D修补作进行处理。随后,这些修补的特征被扁平化为一维序列,使 DiT 模型能够同时处理图像和视频生成任务。如图 1 所示,ContentV 的注意力层数和维度与 SD3.5L 一致。
表 1:ContentV 的架构配置。
| 补丁大小 | #Layers | Attention Heads | 头部尺寸 | FFN 维度 |
| 1x2x2 | 38 | 38 | 64 | 9728 |
4.23D 变分自动编码器

4.33D 扩散变压器
SD3.5L 的 DiT 专为图像输入而设计,需要修改以适应视频输入。由于潜在特征将被扁平化为一维序列,因此需要通过位置嵌入来区分位置信息。此外,对于视频输入,序列长度明显变长 (~116k),QK-Norm 在稳定训练中起着重要作用。
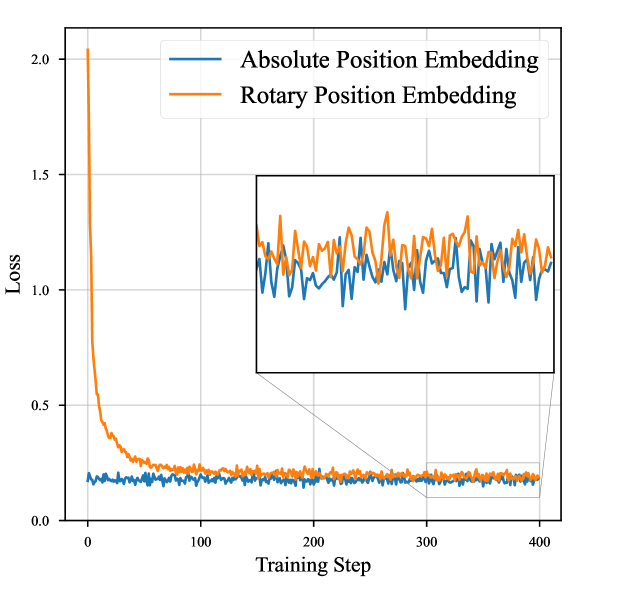
图 4:RoPE 诉 APE
3D 位置嵌入
在 SD3.5L 中[12]中,绝对位置嵌入 (APE) 用于捕获空间关系。当 SD3.5L 的 DiT 从图像输入扩展到视频输入时,我们添加了额外的时间位置嵌入以适当地表示顺序时间信息。近年来,旋转位置嵌入 (RoPE) 使用旋转矩阵进行位置编码,能够很好地学习不同位置标记之间的相对位置信息,提高了模型对长上下文的适应性,已成为大型语言模型和文本转视频扩散模型的主流方法。 我们还尝试用 RoPE 替换 SD3.5L 中的 APE。损失曲线如图 4 所示。该模型只需要用少量步骤 (~500) 进行训练,即可快速适应新的位置编码。经过更长时间的训练,与 APE 相比,RoPE 在 VBench 上的得分没有显着提高。考虑到 RoPE 和 APE 之间的边际差距,我们仍然在文本到视频设置中保留了 APE。
Q-K 归一化
在大型语言模型中,训练大规模 transformer 偶尔会导致损失峰值,这可能会导致模型损坏。 在长序列上训练 DiT 也面临相同的挑战,尤其是在以混合精度进行训练时。半精度会导致长序列中的梯度爆炸,而 grad norm 的增长会导致损失不收敛。使用 float32 的单精度训练可以避免这个问题,但训练时间会显著增加。查询键规范化[10]用于 SD3.5L 可以避免这个问题。具体来说,我们应用 RMSNorm[54]到注意力计算之前的每个 query-key 特征,确保更流畅、更可靠的训练动态。
5训练策略
5.1流匹配
培训目标
ContentV 使用 Flow Matching 进行训练[27],一种支持在连续时间内通过直线概率路径进行高效采样的算法。 给定配对数据样本𝒙1∼p数据和杂色样本𝒙0∼𝒩(0,我),我们在t∈[0,1]如𝒙t=(1−t)𝒙0+t𝒙1.该模型经过训练以预测速度v目标=d𝒙t/dt=𝒙1−𝒙0,它引导𝒙t对𝒙1.通过最小化预测速度之间的均方误差来优化模型参数𝒗θ和真值速度𝒗目标,表示为 loss 函数:
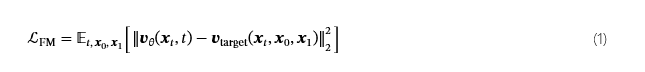
在采样过程中,高斯噪声𝒙0∼𝒩(0,我)将首先绘制。一阶欧拉常微分方程求解器用于计算𝒙1通过速度预测。此过程最终生成最终样本𝒙1.
流量偏移
这t在等式 (1) 中,最初是从均匀分布中采样的。然而Esser 等人 [12]证明从低分辨率图像生成到高分辨率图像生成直接应用相同的噪声计划会导致噪声添加不足和图像降级不充分。他们建议使用 logit-normal 和 Flow Shift 来替换均匀分布。如图 5 所示,在训练过程中,这种时间步采样方法相当于对时间步长使用不同的权重,而在推理过程中,这种采样方法是一种自适应步长调整,即在高噪声阶段使用步长较多的小步更新,在低噪声阶段使用大步更新较少的小步更新。在实验中,我们发现在训练过程中使用较大的 flow shift 可以带来更快的收敛速度,但对模型的生成能力影响较小。在采样中使用较大的流移可以增强生成效果。如图 6 所示,当流量偏移为 1 时,几乎不可能生成可区分的结果。当流移增加时,图像质量会显著提高。因此,我们在训练期间使用了 1 的流量偏移,在采样期间使用了 17 的流量偏移。
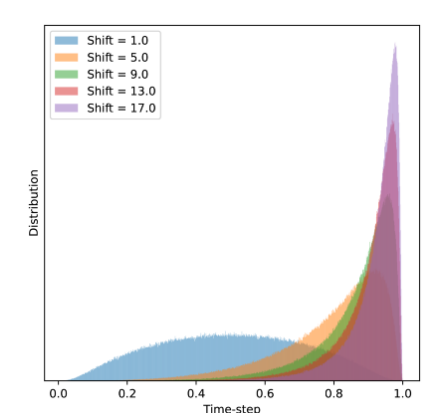
(一)具有不同偏移的时间步长分布。
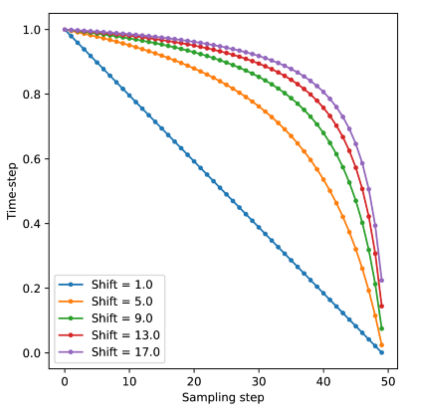
(二)变化偏移下的采样时间步长。
图 5:流动偏移图示。 图 6:在不同无分类器指导量表和流量偏移下的采样结果。

5.2视频 VAE 适配


图 7:3D-VAE 驯化过程中生成的图像。图像生成能力的快速恢复表明,SD3.5L 的 DiT 可以快速适应新的 3D-VAE。
为了将 SD3.5L 的 DiT 从图像生成扩展到视频生成,关键的第一步是将原来的 2D-VAE(仅基于图像训练)替换为能够同时处理图像和视频的 3D-VAE。 适应过程首先在图像上重新训练 DiT 模型,以重新建立其基本的图像生成能力。如图 7 所示,向 3D VAE 的过渡只需要 800 个训练步骤,DiT 就可以成功适应新的潜在空间表示,同时保持其图像合成性能。
我们通过 Fréchet Inception Distance (FID) 定量评估了这种适应过程[16]10K 生成图像的测量结果。SD3.5L 的分辨率为 512 时的 FID 为 12.8。当我们直接替换 VAE 时,所有生成的图像都毫无意义,FID 为 294.3,非常大。然而,仅经过 200 步训练后,FID 迅速下降到 27.8,并且能够生成可区分的图像。训练了 1600 步后,FID 进一步下降到 13.05,基本接近切换 VAE 前的生成能力。这些定量结果与所生成样本的定性观察完全一致,证实了我们适应方法的有效性和效率。
5.3DiT 预培训
形象 视频 联合训练
我们的训练配方以受控比例整合图像,以实现联合视频图像优化。该策略有两个主要目的:(1) 通过利用静态图像中丰富的视觉知识来缓解高质量视频数据集的稀缺性,以及 (2) 尽管视频和图像分布之间存在域转移,但仍保持模型的图像理解能力。与传统方法相反,我们的分析揭示了一个微妙的权衡:虽然图像数据通过改进空间理解来提高生成质量,但它同时也损害了时间动力学。这种现象源于学习空间语义(对图像至关重要)和时间相干性(对视频至关重要)之间的根本紧张关系。为了解决此冲突,我们实施了分阶段训练配方。初始阶段只关注视频数据,以建立健壮的时态表示。随后,我们引入了一个联合训练期,其中两种模式都以平衡的比例处理。这种分阶段的方法实现了有效的跨模态知识转移,同时最大限度地降低了对任一领域的表示偏向风险。
多个纵横比和持续时间 Bucketization
在数据筛选过程之后,视频具有不同的纵横比和持续时间。为了有效地利用数据,我们根据持续时间和纵横比将训练数据分类到各个桶中。具体来说,我们预设了 7 个常见的视频纵横比存储桶:{16:9,3:2,4:3,1:1,3:4,2:3,9:16}.通过以 1 秒为间隔的统一分区来离散化时间持续时间,从而创建一组全面的持续时间存储桶。 为了解决跨存储桶的可变序列长度所施加的内存限制,我们实现了动态批量调整机制。每个存储桶都分配了一个根据经验确定的最大批处理大小,以优化内存利用率,同时防止内存不足的情况。所有数据都分配给最近的存储桶并截断以形成一个批处理。在训练期间,每个排名都会从存储桶中随机预取批量数据。这种随机选择可确保模型在每个步骤中都针对不同的数据大小进行训练,这有助于通过避免在单个大小上训练的限制来保持模型泛化。组合分桶化方法有效地平衡了训练过程中的计算效率和表示多样性。
渐进式视频训练
直接在高分辨率、长时间的视频序列上进行训练通常会导致模型收敛困难和次优结果。因此,渐进式课程学习已成为训练文本到视频模型的广泛采用策略。在 ContentV 中,我们设计了一种渐进式训练策略,从文本到图像的权重开始,遵循先增加持续时间,再增加分辨率的训练方法
- •
Stage1:低分辨率、短持续时间tage.该模型在文本和视觉内容之间建立了基本映射,确保了短期作的一致性和连贯性。
- •
Stage2:低分辨率、长持续时间阶段。该模型学习更复杂的时间动态和场景变化,从而确保在较长时间内的时间和空间一致性。
- •
Stage3:高分辨率、长时间的训练。该模型提高了视频分辨率和细节质量,同时保持了时间一致性并管理复杂的时间动态。
表 2 中显示了详细的训练配置和超参数规范。我们发现,该模型主要在训练过程的第 2 阶段获取动态视觉表示。因此,我们将大部分计算资源分配给了这个关键阶段,优化了训练效率和模型性能。
表 2:跨不同阶段的训练配置。
| 阶段 | 最大形状 | 总批量大小 | 学习速率 | 训练步骤 | |
| 图像 | 视频 | ||||
| VAE 适配 | 1×288×288 | 4096 | - | 1×e−4 | 5 千米 |
| 第一阶段 | 29×288×288 | 4096 | 2048 | 1×e−4 | 40 千米 |
| 第 2 阶段 | 125×288×288 | 4096 | 512 | 1×e−4 | 60 千米 |
| 第 3 阶段 | 125×432×768 | 2048 | 256 | 5×e−4 | 30 千米 |
| SFT | 125×432×768 | - | 256 | 1×e−5 | 5 千米 |
6培训后
在对大规模数据进行预训练后,扩散模型展示了生成多样化和创意视频的能力。然而,生成的视频仍然存在几个关键挑战,包括文本-视频错位、偏离人类审美偏好。为了提高生成视频的视觉保真度和运动动力学,我们在预训练模型上采用了后训练。具体来说,我们对预训练数据的高质量子集进行 SFT,然后进行 RLHF 以进一步优化视觉质量。
6.1监督微调
对于预训练阶段的数据,我们使用了松散的过滤阈值,这使我们能够保留大量的训练数据,但会降低预训练阶段的数据质量。另一方面,由于需要多时长的训练,视频的时长会被截断,导致实际的训练视频与字幕不一致。这些问题导致预训练模型生成的视频质量低下,并且与提示的对齐性差。因此,在 SFT 阶段,我们使用预训练数据的高质量子集和更一致的字幕来提高模型的性能。
数据
如第 3.2 节所述,我们在美学质量和运动动力学两个维度上使用了更严格的过滤标准,从预训练数据中过滤出 100 万的高质量子集。此外,我们会对视频进行预裁剪和截断,以确保培训视频与字幕完全一致。同时,每个视频都标有简短和详细的字幕,并且在 SFT 期间会随机选择一个字幕。
实现细节
SFT 阶段使用较小的学习率(训练前学习率的 10%)和梯度裁剪,以避免灾难性的遗忘。为了保持生成多样性,我们对原始预训练模型的输出进行 KL 发散惩罚,从而规范训练。这个有监督的微调阶段通常只需要预训练计算成本的 5%,同时显著提高视频质量。
6.2从人类反馈中强化学习
用于扩散模型的 RLHF 旨在优化条件分布pθ(x0∣c)这样,奖励模型r(c,x0)在它上面定义,同时正则化与参考模型的 KL 背离p裁判.更具体地说,RLHF 优化了模型pθ最大化以下目标:
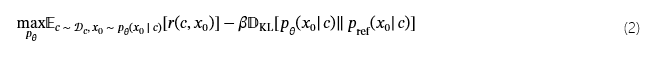
其中,超参数β控制 KL 正则化强度。灵感来源Wu 等人 [50]监督扩散模型的最终输出,并通过迭代采样过程反向传播到输入噪声。我们不是以相等的间隔进行训练,而是随机抽样k从 infer 的时间步长中携带梯度的步长。考虑到视频生成的模型大、序列长,而AI加速器的内存不大,为了计算效率,我们忽略了KL约束。
数据
对于 RLHF 训练,我们通过严格的多阶段流程构建了一组高质量的提示。首先,我们从 SFT 数据集中随机选择了 80,000 个提示,确保不同内容类别和提示样式的均衡覆盖。SFT 数据集本身是从各种来源精心策划的,包括:(1) 专业创建的内容描述,(2) 来自创意平台的用户生成的提示,以及 (3) 由语言模型生成的人工验证合成提示。
奖励模型
最初,我们采用 VideoAlign[28],这是一种基于视觉语言模型 (VLM) 的奖励模型,用于从三个关键维度评估生成的视频:视觉质量 (VQ)、运动质量 (MQ) 和文本对齐 (TA)。在训练过程中,我们观察到,虽然奖励分数稳步提高,但生成的视频的定性性能没有显示出显着的提高。进一步的分析表明,基于 VLM 的奖励模型引入了一个意想不到的偏差:该模型没有全面优化视频质量,而是不成比例地优先考虑文字提示遵守,导致次优生成。我们选择 MPS[55],作为我们的视觉质量奖励模型。它可以有效提高视频的视觉质量。
实现细节
生成初始视频的过程x1事实证明,FROM NOISE THROUGH DIFFUSION 模型需要大量计算,特别是对于扩展视频序列。一个完整的迭代生成周期通常需要数十分钟来执行,而随后从潜在空间到像素空间的解码需要大量的视频内存资源。为了解决 RLHF 阶段的这些效率挑战,我们实施了两个关键优化:(1) 将生成的视频长度从 125 帧减少到 29 帧,从而大大缩短了生成时间;(2) 采用利用 VAE 架构因果特性的选择性解码策略。具体来说,我们只解码第一帧,并利用 MPS 来提高生成图像的感知质量,同时保持计算效率。这些修改共同提高了训练管道的吞吐量,而不会影响输出质量。
7基础设施
本节介绍旨在实现文本到视频模型的高效和可扩展训练的基础设施。我们的训练基于一个由 256 个 NPU 组成的集群。 为了满足大规模视频生成的大量内存和计算需求,我们实施了一系列优化策略。其中包括:(1) 功能编码器和训练模块之间的架构分离,以减少内存开销;(2) 先进的内存优化技术,以最大限度地提高硬件利用率;(3) 结合数据、参数和序列并行的 3D 并行策略。通过这些方法的协同应用,我们在 64 GB 内存约束内实现了 80 亿个参数的视频生成模型的稳定训练。
7.1硬件
我们的训练设置采用一个由 32 个节点组成的集群,每个节点配备 8 个 NPU 和 torch_npu 2.1.0 深度学习框架。为了优化分布式训练性能,我们利用了集体通信库 (HCCL),这是一个高性能通信库,可实现高带宽和低延迟的高效多节点同步。互连架构提供卓越的带宽能力:每个节点支持 56 GB/s 的一对一通信带宽和 392 GB/s 的一对多聚合带宽。NPU 具有每卡 64 GB 的高带宽内存 (HBM),在使用 BF16/FP16 混合精度运行时可提供 320 TFLOPS 的计算吞吐量。这种硬件配置为大规模分布式训练工作负载提供了必要的计算密度和通信带宽。
7.2异步编码服务器
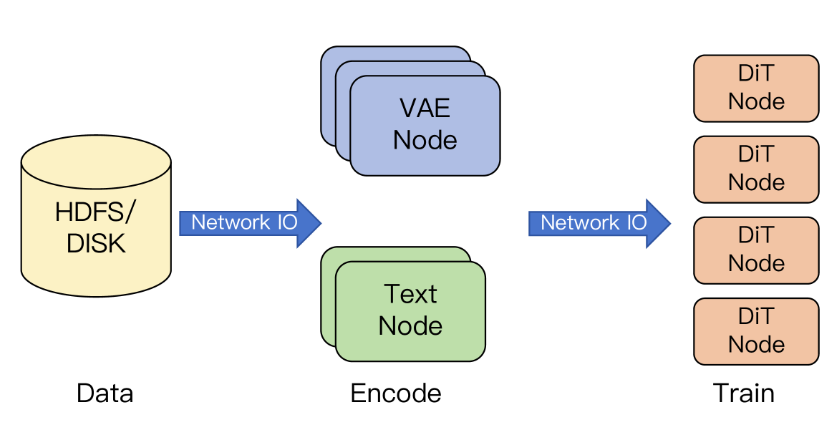
图 8:异步编码服务器。模型的训练和特征提取放置在不同的节点上,数据和特征的传输通过异步网络请求完成。
由于文本到视频扩散模型在潜在空间中执行去噪,因此它需要 VAE 和文本编码器分别提取潜在特征和文本嵌入。虽然这个推理阶段不涉及梯度计算,但 T5-XXL[38]文本编码器和 VAE 编码器仍然需要大量的内存资源。在 SD3.5L 中[12],特征提取是离线进行的,这不可避免地会占用大量的存储空间。为了解决这些资源限制,我们提出了一种解耦架构,将用于推理和训练的计算资源分开。具体来说,VAE 和文本编码器在专用推理集群上运行,持续生成处理后的输入数据(包括图像/视频潜在特征和相应的文本嵌入)用于 DiT 训练。然后,训练集群通过网络传输检索这些预先计算的特征,并专注于训练过程。
批处理缓冲区
对于每个等级,我们采用专用流程来管理数据缓冲区。在初始阶段,当缓冲区尚未达到其全部容量时,该过程会以迭代方式从服务器获取新的批处理数据并将其存储在本地。此设计使训练节点能够直接从其本地存储访问所需的功能,无需在训练期间频繁地远程检索数据。为了确保所有等级之间的同步,我们使用训练步骤计数作为统一标识符,从而保证数据加载和模型训练过程之间的一致协调。
7.3内存优化
注意力优化
随着序列长度的增长,注意力的计算开销成为训练中的主要瓶颈。我们利用 npu_fusion_attention 来加速注意力计算,从而显著提高计算效率。此外,这种优化还大大降低了内存消耗,从而能够在有限的硬件资源中训练更长的序列。
梯度检查点
梯度检查点是一种内存优化技术,它以计算开销为代价来降低内存需求。该方法包括三个关键步骤:(1) 选择性地指定特定层或块进行重新计算,(2) 在正向传递期间释放中间激活,以及 (3) 在向后传递期间根据需要重新计算这些激活。这种方法显著降低了训练期间的内存消耗,从而能够在有限的内存限制内处理更大的模型或批量大小。
7.4并行策略
庞大的模型大小和超长的序列长度(最长序列超过 116K 个标记)需要实施高级并行策略,以确保计算效率高的训练。为了应对这一挑战,我们采用了 3D 并行性,这是一种结合了数据并行性、张量(参数)并行性和序列并行性的可扩展方法。此策略支持在所有三个关键维度(包括数据批处理、模型参数和长序列)上高效分配计算工作负载,从而优化内存使用和计算吞吐量。
序列并行度 (SP)
序列并行是一种沿序列维度对输入张量进行分区的技术,支持对 LayerNorm 等层进行独立处理,以消除冗余计算并减少内存开销[22,25,20].这种方法还支持对不合规的 inputs 进行动态填充,从而有助于高效处理可变长度序列。我们的实施利用了 Ulysses[20],该框架在训练循环开始时跨序列并行组对输入样本进行分片。在注意力计算期间,Ulysses 采用多对多通信来分发查询、键和值张量,以便每个工作线程处理完整的序列长度,但只处理注意力头的子集。在并行计算之后,第二个 all-to-all作重新组合输出,重建 attention heads和原始序列分片。为了确保稳健性,我们的实现包括对本身不满足 SP 要求的输入序列的工程优化,例如自动填充以保持计算效率。
完全分片的数据并行性
Zhao et al. [56]引入了全分片数据并行 (FSDP),这是一种节省内存的分布式训练方法,可在数据并行排名之间对模型参数、梯度和优化器状态进行分区。与依赖 all-reduce 进行同步的分布式数据并行 (DDP) 不同,FSDP 使用 all-gather 进行参数检索,使用 reduce-scatter 进行梯度聚合。这些作在战略上与前向和后向计算重叠,从而减少了通信开销并提高了训练效率。在我们的实施中,我们利用了 HYBRID_SHARD 策略,该策略将组内参数分片 (FULL_SHARD) 与组间参数复制相结合。这种混合方法有效地实现了分层数据并行性:虽然 FULL_SHARD 优化了每个分片组中的内存使用,但跨组复制提高了计算吞吐量。通过在分片组中本地化 all-gather 和 reduce-scatter作,与全局同步方案相比,此方法显著降低了 rank 间通信成本。
CogVideoX-5B 系列

浑源视频-13B

广域2.1-14B

MINIMAX 海罗

维杜

克陵 1.6

济盟 PixelDance 2.0 专业版

内容V -8B

图 9:ContentV 与其他 T2V 模型之间的定性比较。提示:一群活泼的朋友,外表和风格各异,聚集在一个舒适、温暖的客厅里,充满了欢笑和友情。他们坐在一张毛绒的彩色地毯上,周围是柔软的靠垫和一张装饰着小吃和饮料的低矮木桌。每位朋友都穿着休闲、充满活力的服装,通过热情的手势表示同意,例如竖起大拇指、击掌和碰拳。他们的脸上洋溢着真诚的微笑和点头,反映了共同的理解和相互支持。房间的氛围,柔和的灯光和不拘一格的装饰,增强了温暖和友谊的感觉。
8性能
8.1定性可视化
为了进行直观比较,我们进行定性评估并在图 9 中呈现采样结果。评估包括开源模型 CogVideoX-5B[52], HunyuanVideo-13B[21]、Wan-14B[46]以及闭源产品,包括 MINIMAX 海罗[30]、 活力[43]、克林1.6[23]和极盟 PixelDance 2.0[8].图 9 显示,与其他开源模型相比,ContentV 可以实现更好的视觉质量,与一些闭源模型相当。这是因为 RLHF 符合人类偏好,显着提高了视频的视觉质量。我们在图 10 中分别展示了 Pre-train、SFT 和 RLHF 阶段的可视化结果。SFT 阶段增强了视频和提示之间的语义对齐,而 RLHF 提高了视觉质量和细节,尤其是在人类偏好方面。更多视频示例显示在项目页面上。

(一)一个宁静的人,身着飘逸的白色礼服,优雅地坐在阳光明媚的房间里,房间里装饰着郁郁葱葱的绿色植物和柔软的飘逸窗帘。他们的手指轻轻拨动金色竖琴的琴弦,产生空灵的旋律,弥漫在空气中。相机捕捉到手部的特写镜头,展示了复杂的动作和竖琴的华丽细节。阳光透过窗户,在安详的脸上投下温暖的光芒,闭上眼睛,全神贯注。场景过渡到更广阔的镜头,展现出房间的宁静氛围,窗帘的轻轻摇曳和树叶的轻柔沙沙声增强了宁静的气氛。

(二)一只顽皮的熊猫自信地站在冲浪板上,在令人叹为观止的日落中乘风破浪。天空被橙色、粉红色和紫色的色调所绽放,在水面上投下温暖的光芒。这只熊猫黑白相间的皮毛在金光下闪闪发光,毫不费力地保持平衡,兴奋地睁大了眼睛。冲浪板涂有鲜艳的色彩,划过波光粼粼的海浪,留下一串闪闪发光的水滴。在背景中,太阳落到地平线以下,营造出宁静而神奇的氛围,熊猫在宁静的大海中享受着独特的冒险。

(三)一名西装革履的宇航员,靴子上沾满了火星的红尘,在第四颗行星粉红色的天空下,伸出手与外星人握手,他们的皮肤闪耀着蓝色的光芒。在背景中,一枚光滑的银色火箭高高耸立,发动机熄灭,来自不同世界的两位代表在火星景观的荒凉美景中交换历史性的问候。
图 10:ContentV 在不同阶段的定性比较。
8.2定量分析
对于定量分析,我们在 VBench 上将 ContentV 与 SOTA 文本到视频模型进行了评估[19],从 16 个维度全面评估视频生成质量的基准。Vbench 提供了两种类型的提示音:一种是简短的提示音,平均 7.6 个字。另一种是 chatGPT 增强的长而详细的提示,平均 100.5 个字。我们同时评估这两种类型的提示,以全面衡量 ContentV 的功能。
如表 3 所示,ContentV 在多个评估维度上表现出出色的表现,在总分上优于众多开源和商业模式。在所有开源模型中,ContentV 仅逊色于 Wan2.1[46].然而,与具有 14B 参数的 Wan2.1 相比,ContentV 仅使用 8B (~57% 的 14B) 参数实现了相当的性能。 值得注意的是,ContentV 在长提示中取得了更高的 VBench 总分,主要是因为详细提示带来了 3.51 分的语义分数的显着提升。这表明 ContentV 具有理解复杂提示并增强文本视频对齐的能力。
表 3:与 VBench 上领先的 T2V 模型比较[19]按总分降序排列。† 表示具有非公开可用权重的模型。其他模型的结果来自官方 VBench 排行榜。
| 模型 | 整体 | 质量得分 | 语义得分 | 人行动 | 现场 | 动态度 | 倍数对象 | 出现。风格 |
| 维杜-Q1† | 87.41 | 87.28 | 87.94 | 99.60 | 67.41 | 91.85 | 93.89 | 22.37 |
| 广域2.1-14B | 86.22 | 86.67 | 84.44 | 99.20 | 61.24 | 94.26 | 86.59 | 21.59 |
| ContentV(长) | 85.14 | 86.64 | 79.12 | 96.80 | 57.38 | 83.05 | 71.41 | 23.02 |
| 悟空† | 84.85 | 85.60 | 81.87 | 97.60 | 57.08 | 76.11 | 79.48 | 23.08 |
| Open-Sora 2.0 | 84.34 | 85.40 | 80.12 | 95.40 | 52.71 | 71.39 | 77.72 | 22.98 |
| 空† | 84.28 | 85.51 | 79.35 | 98.20 | 56.95 | 79.91 | 70.85 | 24.76 |
| 因果维德† | 84.27 | 85.65 | 78.75 | 99.80 | 56.58 | 92.69 | 72.15 | 24.27 |
| ContentV(短) | 84.11 | 86.23 | 75.61 | 89.60 | 44.02 | 79.26 | 74.58 | 21.21 |
| 鲁马† | 83.61 | 83.47 | 84.17 | 96.40 | 58.98 | 44.26 | 82.63 | 24.66 |
| EasyAnimate 5.1 版 | 83.42 | 85.03 | 77.01 | 95.60 | 54.31 | 57.15 | 66.85 | 23.06 |
| 海罗视频-01† | 83.41 | 84.85 | 77.65 | 92.40 | 50.68 | 64.91 | 76.04 | 20.06 |
| Kling 1.6† | 83.40 | 85.00 | 76.99 | 96.20 | 55.57 | 62.22 | 63.99 | 20.75 |
| 浑源视频 | 83.24 | 85.09 | 75.82 | 94.40 | 53.88 | 70.83 | 68.55 | 19.80 |
| 第 3 代† | 82.32 | 84.11 | 75.17 | 96.40 | 54.57 | 60.14 | 53.64 | 24.31 |
| CogVideoX-5B 系列 | 81.61 | 82.75 | 77.04 | 99.40 | 53.20 | 70.97 | 62.11 | 24.91 |
| 皮卡-1.0† | 80.69 | 82.92 | 71.77 | 86.20 | 49.83 | 47.50 | 43.08 | 22.26 |
| 视频工匠 2.0 | 80.44 | 82.20 | 73.42 | 95.00 | 55.29 | 42.50 | 40.66 | 25.13 |
| AnimateDiff-V2 (动画差异-V2) | 80.27 | 82.90 | 69.75 | 92.60 | 50.19 | 40.83 | 36.88 | 22.42 |
| OpenSora 1.2 版本 | 79.23 | 80.71 | 73.30 | 85.80 | 42.47 | 47.22 | 58.41 | 23.89 |
| 显示 1 | 78.93 | 80.42 | 72.98 | 95.60 | 47.03 | 44.44 | 45.47 | 23.06 |
| 米拉 | 71.87 | 78.78 | 44.21 | 63.80 | 16.34 | 60.33 | 12.52 | 21.89 |
此外,为了确保稳健的评估,我们使用了基于端到端视觉语言模型的评估器 VideoAlign[28]以补充 VBench 评估标准。VideoAlign 提供对视频生成的三个维度的精细分析:视觉质量 (VQ) 量化帧级清晰度和结构保真度;运动质量 (MQ) 评估运动的时间连贯性和物理合理性;文本对齐 (TA) 衡量生成的视频与其文本提示之间的语义一致性。我们使用 Vbench[19]和 VideoAlign[28]来衡量 Pre-train、SFT、RLHF 阶段对生成的视频的影响。
表 4:实验模型跨阶段 ContentV 的改进。蓝色表示针对预训练模型的胜率。
| 阶段 | Vbench 系列[19] | 视频对齐[28] | |||||
| 质量 | 语义 | 整体 | VQ 预约 | MQ | TA | 整体 | |
| 预训练 | 85.11 | 78.29 | 83.74 | -0.2160 | 0.2494 | 0.8737 | 0.9071 |
| SFT | 85.24 | 79.73 | 84.13 | -0.208050.26% | 0.244346.40% | 1.014561.31% | 1.050856.77% |
| RLHF | 85.85 | 80.02 | 84.68 | 0.303489.38% | 0.433965.96% | 1.159976.48% | 1.897285.62% |
表 4 中的结果表明,在连续的训练阶段中,性能逐步提高,每个阶段都为不同的评估指标做出了不同的增强。 在 SFT 阶段,该模型显示 TA 性能有显著改善,从 0.8737 到 1.0145 实现了 61.31% 的胜率。这种改进归因于利用了来自预训练数据集的过滤视频样本,并附有更精确和全面的字幕。值得注意的是,虽然 TA 显示出显著的提升,但 VQ 和 MQ 指标保持稳定,保持与基线相当的性能水平。这一观察表明,SFT 过程主要通过提高字幕质量来优化文本-视频对齐,而不是影响视觉质量。 RLHF 阶段在所有评估维度上产生更全面的改进。最值得注意的是,这个阶段的 VQ 胜率提高了 89.38%(从 -0.2160 到 0.3034),总分胜率提高了 85.62%(从 0.9071 到 1.8972)。这些实质性的收益可归因于 RLHF 对整个扩散过程的优化,它系统地对齐了去噪x1通过迭代反馈机制以人类偏好模式输出。
8.3用户研究
尽管在 Vbench 和 VideoAlign 中使用了多维评估方案,但基于模型的评估和人工评估之间仍然存在差距。 因此,我们对 ContentV 和其他三种主流开源模型 CogvideoX-5B 进行了用户研究[52], HunyuanVideo-13B[21]和 WanX2.1-14B[46]. 具体来说,我们的评估考察了视频生成质量的四个关键维度:
- •
感知质量:评估基本视频特性,包括时间一致性、帧到帧稳定性、运动流畅性和整体美学连贯性。
- •
说明遵循:匹配元素、数量和特征的文本提示的准确性
- •
物理模拟:运动、照明和物理交互的真实感
- •
视觉质量:量化生产级质量指标,包括分辨率保真度、色彩准确度、噪点水平和伪影存在。
评估指标
我们使用 Good-Same-Bad (GSB) 比率来定量表示评估模型(即 ContentV)和比较模型之间人类偏好的差异。给定评价模型和对比模型分别生成的提示和视频,人工注释者需要根据个人喜好做出选择:评价模型更好(”Good“),两者大致相同 (”Same“),并且比较模型更好 (”B广告”)。GSB 比率的计算公式为:

比率大于 1 表示评估模型的性能优越,而比率低于 1 表示比较基线的性能更好。例如,当评估 10 个样本视频,结果为 7 个较好、2 个等效和 1 个较差时,得到的 7:2:1 比率得出的 GSB 值为 3.0,清楚地表明性能优越。
我们邀请了 5 位人工注释者综合考虑并选择首选视频。GSB 的比较结果如图 11 所示。与基于模型的评估一致,ContentV 在整体评估维度上表现出优于 CogVideoX 和 HunyuanVideo 的性能。从基于指标的评估和人工评估之间的比较中得出一个有趣的观察结果:虽然 ContentV 在 VBench 上的得分低于 Wan2.1,但它获得了更好的人类偏好评级。这种差异表明,与人类感知相比,VBench 评估标准可能强调视频质量的不同方面。我们假设人类评估者更加强调整体因素,例如自然运动、时间连贯性和审美质量,这些因素可能无法被自动度量系统完全捕获。
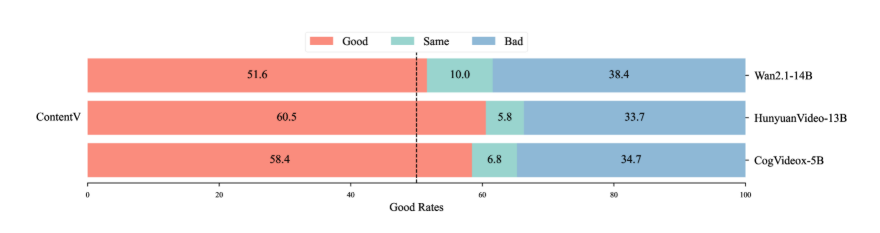
图 11:ContentV 与开源 SOTA T2V 模型的用户研究。相较于 CogVideoX、HunyuanVideo 和 Wan2.1,ContentV 的 GSB 比率分别为 1.57、1.68 和 1.30。
9结论
我们提出了 ContentV,这是第一个在 NPU 上完全训练的视频生成模型,在 VBench 和用户研究中都实现了 SOTA 性能。通过以最小的架构更改从 Stable Diffuison 3.5 Large 初始化,实施新颖的分阶段联合渐进式训练策略以同步优化图像视频,以及用于视频生成的 RLHF 调整,我们的框架可以在短短一个月内生成不同分辨率和持续时间的高质量、多样化的视频,同时收敛。值得注意的是,ContentV 的性能与当前领先的开源模型的性能相匹配,只需一半的参数,就展示了前所未有的训练效率,而不会影响输出保真度。这项工作不仅推进了可扩展视频合成的前沿,还为在替代硬件架构上进行大规模生成模型训练建立了新的范式。