一、yolov11+双目测距基本流程
yolov11 + 双目测距的大致流程就是:
双目标定 --> 立体校正(含消除畸变) --> 立体匹配 --> 视差计算 --> 深度计算(3D坐标)计算 --> 目标检测 --> 目标距离计算及可视化
下面将分别阐述每一个步骤并使用python来实现。
二、双目测距
其中双目测距的原理及过程请查看我下面的博客
保姆级双目测距原理及代码-CSDN博客
三、目标检测
在本项目中,我们选用了轻量级且高效的目标检测模型 YOLOv11,并使用其 ONNX格式模型部署,结合OpenCV和ONNX Runtime完成前向推理,实现高性能目标识别。整个检测流程主要包括 模型转换、图像预处理、模型推理、后处理 四个步骤,以下是详细解析:
3.1 模型转换(PyTorch → ONNX)
为提升系统在不同平台的兼容性与环境,我们将 PyTorch 格式的 YOLOv11 模型转换为 ONNX 格式,供 onnxruntime 加载使用。
Ultralytics 框架提供了简洁的模型导出接口,支持直接将训练好的 .pt 权重导出为 ONNX 文件。转换代码如下:
from ultralytics import YOLO
# 加载YOLOv11模型
model = YOLO("./weight/yolo11s.pt")
# 转onnxsimplify
model.export(format="onnx", simplify=False, device="cpu", opset=15)其中参数说明如下:
-
format="onnx":指定导出格式为 ONNX。 -
simplify=False:是否使用onnxsim简化模型结构。此处设置为False,保持模型结构完整。 -
device="cpu":导出时使用 CPU 进行模型加载和转换。 -
opset=15:指定 ONNX 的算子集版本,确保在现代推理环境中兼容性良好。
导出成功后,系统会在当前目录生成名为 yolo11s.onnx 的模型文件。
该模型可直接通过 onnxruntime.InferenceSession 加载,用于后续图像目标检测与测距任务。
3.2 图像预处理(Preprocess)
输入图像在送入YOLOv11模型前,需要经过标准化与尺寸调整。预处理的关键操作包括:
-
颜色空间转换:BGR转RGB(符合模型训练时的格式要求);
-
等比例缩放:根据模型输入尺寸(如640x640)对图像缩放,同时添加灰色边框填充,确保图像比例不变;
-
归一化:将像素值归一到0,10, 10,1;
-
维度调整:转换为
NCHW格式,以匹配ONNX模型输入要求。
其中,图像预处理代码如下:
def preprocess_image(self, image):
# 调节颜色通道
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# rsize + padding
h, w, c = image.shape
# 求各自缩放到模型的缩放比例,找出最小比例
r_w = self.model_width / w
r_h = self.model_height / h
ratio = 0
if r_h > r_w:
tw = self.model_width
th = int(h * r_w)
ratio = r_w
# 填充尺寸
p_x1 = p_x2 = 0
p_y1 = int((self.model_height - th) / 2)
p_y2 = self.model_height - th - p_y1
else:
th = self.model_height
tw = int(w * r_h)
ratio = r_h
# 填充尺寸
p_y1 = p_y2 = 0
p_x1 = int((self.model_width - tw) / 2)
p_x2 = self.model_width - tw - p_x1
image = cv2.resize(image, (tw, th))
image = cv2.copyMakeBorder(image, p_y1, p_y2, p_x1, p_x2, cv2.BORDER_CONSTANT, (128, 128, 128))
image2 = image
# 转换为浮点型并归一化到 [0, 1]
image = image.astype(np.float32) / 255.0
# 转换为 NCHW 格式(批次、通道、高、宽)
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, axis=0)
return image, ratio, [p_x1, p_x2, p_y1, p_y2]3.2 ONNX模型推理
通过 onnxruntime.InferenceSession 加载YOLOv11的ONNX模型,并根据模型定义的输入输出节点,构建推理输入:
self.onnx_session = onnxruntime.InferenceSession(self.onnx_path)
input_feed = {self.input_name[0]: preprocessed_image}
pred_bbox = self.onnx_session.run(None, input_feed)[0]
3.3 后处理(Postprocess)
在目标检测模型完成前向推理后,其输出通常为大量未筛选的候选框(bounding boxes),每个候选框包含位置坐标、各类别置信度等信息。为了从中提取有效的目标信息,并在原始图像上可视化展示,需对模型输出进行后处理。后处理步骤如下:
-
维度变换与置信度筛选:
模型输出的张量pre_box通过np.einsum("bcn->bnc", pre_box)调整维度顺序,得到[num_boxes, num_channels]形式的数据。随后提取每个候选框的最大类别置信度,并只保留置信度高于设定阈值conf_thres的候选框。 -
提取目标框与类别索引:
对保留的候选框,提取其前四个位置坐标、最大置信度和类别索引。类别索引由np.argmax得到,即置信度最大的类别。 -
非极大值抑制(NMS):
通过 OpenCV 的cv2.dnn.NMSBoxes实现 NMS,去除重叠度(IoU)过高的冗余候选框,保留最优检测结果。 -
坐标解码与图像尺度还原:
检测框坐标从中心点形式cx, cy, w, h转换为边界框形式x1, y1, x2, y2,并根据预处理的 padding 和缩放比例ratio还原为原始图像坐标。边界值被限制在图像范围内,防止越界。
其中,后处理代码如下:
def postprocess_image(self, original_image, pre_box, points_3d, ratio, pad_size):
pre_box = np.einsum("bcn->bnc", pre_box)
# 获取每个预测框的最大置信度
conf_scores = np.amax(pre_box[..., 4:], axis=-1)
# 只保留置信度大于阈值的预测框
x = pre_box[conf_scores > self.conf_thres]
x = np.c_[x[..., :4], conf_scores[conf_scores > self.conf_thres], np.argmax(x[..., 4:], axis=-1)]
# NMS filtering
x = x[cv2.dnn.NMSBoxes(x[:, :4], x[:, 4], self.conf_thres, self.iou_thres)]
# Decode and return
if len(x) > 0:
# cxcywh -> xyxy
x[..., [0, 1]] -= x[..., [2, 3]] / 2
x[..., [2, 3]] += x[..., [0, 1]]
# 恢复成原图尺寸
x[..., :4] -= [pad_size[0], pad_size[2], pad_size[1], pad_size[3]]
x[..., :4] /= ratio
# 检查边界
x[..., [0, 2]] = x[:, [0, 2]].clip(0, original_image.shape[1])
x[..., [1, 3]] = x[:, [1, 3]].clip(0, original_image.shape[0])四、目标距离计算及可视化
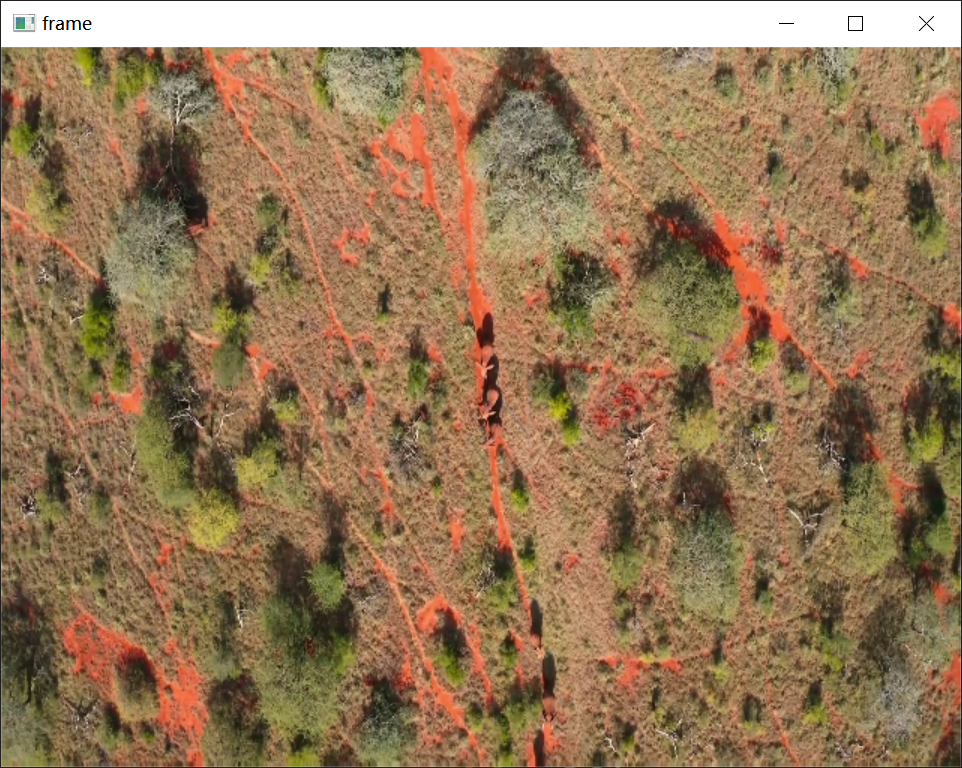
在完成目标检测的后处理阶段后,系统已经获得每个候选目标的二维图像坐标和置信度信息。为了进一步实现三维感知功能,本系统结合双目测距模块输出的 points_3d,实现目标距离的估算与图像可视化展示。
4.1 距离估算(3D中心点提取)
首先,对通过置信度筛选和 NMS 处理后的目标框,计算其中心点坐标:
随后,根据中心点的像素坐标,从稠密深度图中提取该位置对应的三维坐标:
其中,Z表示相机到目标的深度距离。
4.2 类别过滤与绘制逻辑
为提升系统的针对性与应用适应性,引入了可配置的 detection_name 白名单机制。仅当检测到的目标类别存在于该名单中时,才执行可视化绘制与距离估算操作。该策略可适用于特定场景(如仅关注“人”或“汽车”等对象)。
4.3 可视化结果展示
最终,为提升用户体验并实现直观展示,系统将检测结果绘制回原始图像中,具体包括:
-
目标框绘制:使用
cv2.rectangle绘制每个目标的边界框,不同类别采用不同颜色(由COLORS字典控制); -
距离信息叠加:在目标框上方添加该目标与相机之间的距离信息,格式为
"Distance: 1.52 m"; -
类别与置信度(可选):支持在框上叠加类别名称与预测置信度,用于辅助判断目标识别准确性。
yolov11双目测距图像
yolov11双目测距深度


五、整体代码介绍
本代码实现了基于双目立体视觉的目标检测与测距系统,涵盖了畸变矫正、立体校正、视差计算及深度计算和目标检测关键步骤。
测距模块从 stereoconfig 模块中加载相机标定参数,包括内外参和畸变系数,利用 OpenCV 的 cv2.stereoRectify() 对左右相机图像进行立体校正,保证图像对齐。随后,采用 SGBM(半全局匹配算法)计算视差图,并结合 WLS(加权最小二乘滤波)滤波器对视差图进行优化,提高视差的平滑性和准确性。接着,通过 cv2.reprojectImageTo3D() 将视差图转换成三维点云,得到每个像素的三维信息。检测模块基于ONNX格式的YOLO模型,结合后处理与非极大值抑制筛选检测框,并计算目标中心点的三维坐标实现距离估计。
系统支持两种运行模式:图片模式(image_mode)用于处理静态双目图像,摄像头模式(camera_mode)支持实时视频流处理,实现动态测距与目标检测。可根据自己需求进行相应选择。
本代码仅依赖 ONNX、NumPy 和 OpenCV 库,无需依赖 PyTorch 等深度学习框架,因而更适合部署在边缘设备上,具有较低的资源消耗和良好的跨平台兼容性。
关于该系统涉及到的完整源码、测试图片视频、说明、安装环境等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
yolov11+双目测距代码