在自然语言处理领域,预训练语言模型(如BERT、GPT、T5)已成为基础设施。但如何让这些“通才”模型蜕变为特定任务的“专家”?微调策略正是关键所在。本文将深入剖析七种核心微调技术及其演进逻辑。
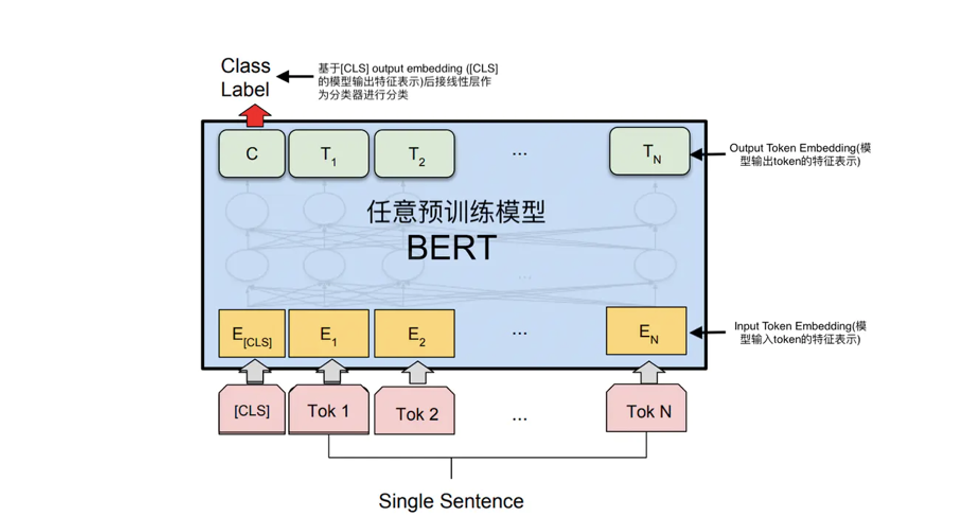
一、基础概念:为什么需要微调?
预训练模型在海量语料上学习了通用语言表征(词义、语法、浅层语义),但其知识是领域无关的。例如:
-
医学文本中的“阳性”与日常用语含义不同
-
金融领域的“多头”非指动物头部
-
法律文本的特殊句式结构
微调的本质:在预训练知识基础上,通过特定领域数据调整模型参数,使其适应下游任务,如文本分类、实体识别、问答系统等。
二、经典策略:全参数微调(Full Fine-tuning)
工作原理:解冻整个模型,在任务数据上更新所有权重
# PyTorch典型实现
model = B