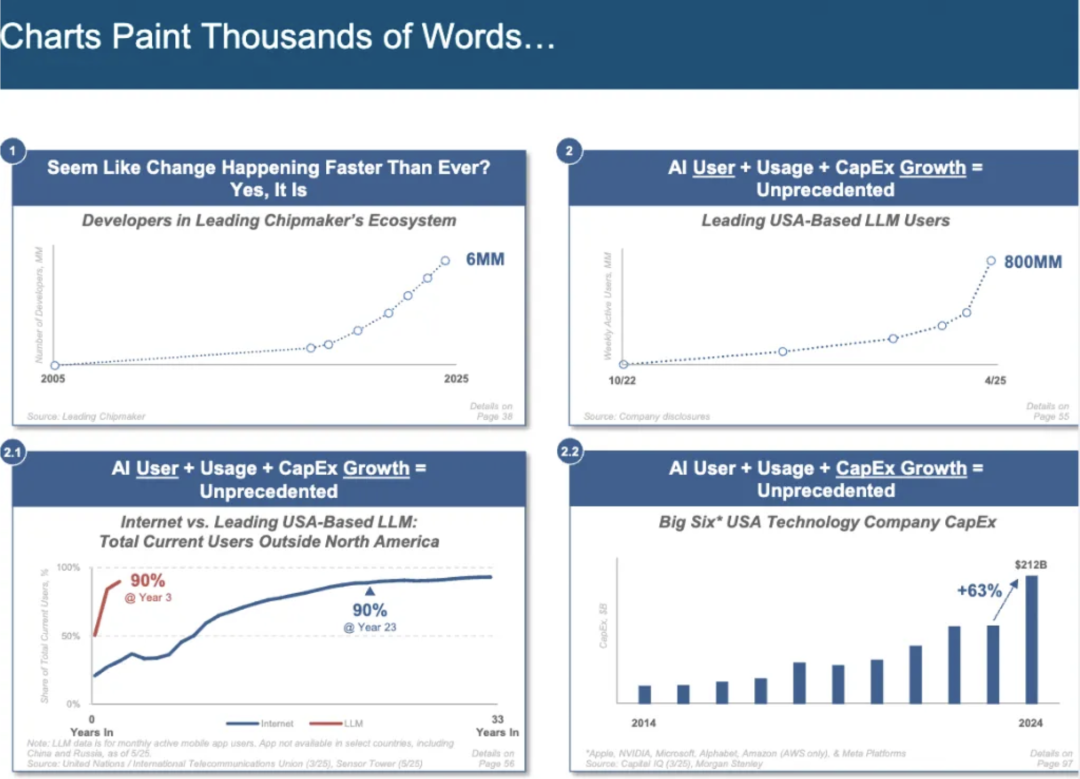
📘 强化学习基础概念图文版笔记
1️⃣ 基本框架:Agent 与 Environment
🧠 核心角色:
- Agent(智能体):做出决策的“大脑”,根据当前状态选择动作。
- Environment(环境):Agent 所处的世界,接收动作并返回下一个状态和奖励。
🔄 工作流程:
Agent 观察 → 环境反馈状态 (state)
Agent 决策 → 选择动作 (action)
环境响应 → 返回奖励 (reward) 和新状态
Agent 更新策略
📌 图形示意:
[Agent] —— action ——> [Environment]
<—— reward/state ——
2️⃣ 状态(State) vs 观测(Observation)
| 概念 | 描述 |
|---|---|
| State(状态) | 环境的完整信息,通常 Agent 不一定能直接观察到 |
| Observation(观测) | Agent 实际看到的信息,可能是 state 的一部分或噪声版本 |
✅ 在 RLHF 中,prompt 可以视为一种 observation
3️⃣ 动作空间(Action Space)
🧩 定义:
Agent 可以采取的所有动作的集合。
✅ 类型:
- 离散动作空间:比如上下左右(游戏控制)
- 连续动作空间:比如力度、角度(机器人控制)
🔍 示例:
- 在 LLM 中,一个动作可以是一个 token 输出
- 整个回答就是一系列动作组成的序列
4️⃣ 奖励函数(Reward Function)
🎯 定义:
环境对 Agent 动作的即时反馈,表示这个动作是否“好”。
🧮 示例:
- 正确回答问题:+1
- 回答有害内容:-1
- 长度过长:-0.1
⚠️ 注意:
- 奖励设计直接影响训练效果
- 在 RLHF 中,Reward Model 提供打分信号
5️⃣ 策略(Policy)
🧠 定义:
策略是 Agent 的行为规则,即给定状态,输出动作的概率分布。
π ( a ∣ s ) = P ( a t = a ∣ s t = s ) \pi(a|s) = P(a_t = a \mid s_t = s) π(a∣s)=P(at=a∣st=s)
📌 举例:
- 在 prompt “量子计算是什么?” 下,模型可能生成多个回答,策略决定了每个回答被选中的概率
6️⃣ 价值函数(Value Function)
📈 定义:
价值函数衡量某个状态的好坏,代表从该状态出发未来能获得的期望回报。
V π ( s ) = E π [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s ] V^\pi(s) = \mathbb{E}_\pi \left[ \sum_{t=0}^\infty \gamma^t r_t \mid s_0 = s \right] Vπ(s)=Eπ[t=0∑∞γtrt∣s0=s]
其中 γ \gamma γ 是折扣因子(0 ≤ γ ≤ 1),用于权衡当前奖励和未来奖励。
7️⃣ Q 函数(Action-Value Function)
📈 定义:
Q 函数衡量在某个状态下采取某个动作的价值。
Q π ( s , a ) = E π [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s , a 0 = a ] Q^\pi(s, a) = \mathbb{E}_\pi \left[ \sum_{t=0}^\infty \gamma^t r_t \mid s_0 = s, a_0 = a \right] Qπ(s,a)=Eπ[t=0∑∞γtrt∣s0=s,a0=a]
8️⃣ Advantage 函数(优势函数)
🧠 定义:
Advantage 表示某个动作相对于当前状态平均表现的优势。
A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)
📌 含义:
- $ A > 0 $:该动作优于平均水平,应增强其概率
- $ A < 0 $:该动作不如平均水平,应降低其概率
9️⃣ 策略梯度方法(Policy Gradient)
🧮 基本思想:
通过梯度上升优化策略参数 θ \theta θ,使期望回报最大化:
J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T γ t r t ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T \gamma^t r_t \right] J(θ)=Eτ∼πθ[t=0∑Tγtrt]
梯度更新公式为:
∇ θ J ( θ ) ≈ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) ⋅ A ( s t , a t ) \nabla_\theta J(\theta) \approx \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot A(s_t, a_t) ∇θJ(θ)≈t=0∑T∇θlogπθ(at∣st)⋅A(st,at)
🔟 PPO 中的 Advantage 使用方式
📐 Clip 操作的作用:
为了避免策略更新过大导致不稳定,PPO 对 ratio 做裁剪处理:
r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st)
最终损失函数为:
L PPO ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{\text{PPO}}(\theta) = \mathbb{E}_t\left[\min \left( r_t(\theta) \hat{A}_t,\ \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_t \right)\right] LPPO(θ)=Et[min(rt(θ)A^t, clip(rt(θ),1−ϵ,1+ϵ)A^t)]
🔟 什么是 GAE(Generalized Advantage Estimation)?
📌 目标:
GAE 是一种更稳定地估计 Advantage 的方法,通过引入参数 λ \lambda λ 来平衡偏差与方差。
🧮 公式(简化理解):
A ^ t GAE ( γ , λ ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l \hat{A}_t^{\text{GAE}(\gamma, \lambda)} = \sum_{l=0}^\infty (\gamma \lambda)^l \delta_{t+l} A^tGAE(γ,λ)=l=0∑∞(γλ)lδt+l
其中:
- δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st) 是 TD 误差
🔟 策略优化方法对比表
| 方法 | 是否需要 RM | 是否需要 RL | 是否使用 preference pair | 是否支持 SFT | 特点 |
|---|---|---|---|---|---|
| PPO | ✅ 需要 | ✅ 需要 | ❌ 否 | ❌ 否 | 经典强化学习方法 |
| DPO | ❌ 不需要 | ❌ 不需要 | ✅ 是 | ❌ 否 | 偏好优化主流方法 |
| KTO | ❌ 不需要 | ❌ 不需要 | ✅ 是 | ❌ 否 | 结合拒绝采样思想 |
| ORPO | ❌ 不需要 | ❌ 不需要 | ✅ 是 | ✅ 是 | 统一 SFT + Preference |
| GRPO | ❌ 不需要 | ✅ 是(简化版) | ✅ 是 | ✅ 是 | 加入引导机制 |
📌 附录:RLHF 三阶段流程图
1. SFT(Supervised Fine-Tuning)
└── 使用人工标注数据进行有监督微调
2. RM(Reward Model 训练)
└── 使用 preference pair 数据训练 Reward Model
3. PPO / DPO / GRPO / ORPO
└── 利用 Reward Model 或 preference pair 进行策略优化
📄 总结一句话:
强化学习的核心在于通过奖励信号不断调整策略,使得 Agent 能够学会如何在复杂环境中做出最优决策。