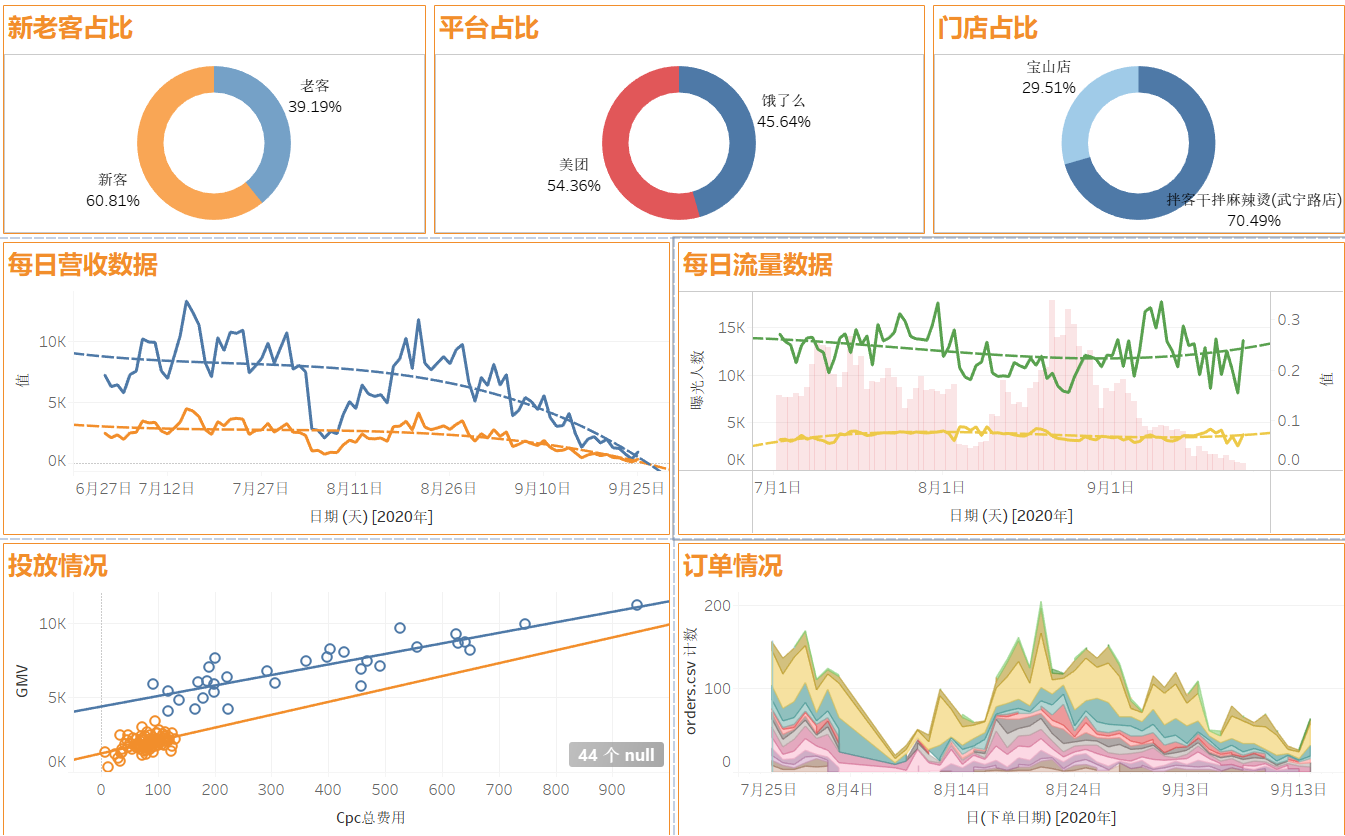
RAG技术解析:实现高精度大语言模型知识增强
RAG概述
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索系统和生成模型的技术架构,旨在提高大语言模型回答问题的准确性和相关性。当遇到如"如何退款"这类问题时,若没有提供标准答案,模型可能会产生"幻觉"(生成看似合理但实际不准确的信息)。而通过RAG提供标准答案参考,模型就能够输出准确且符合要求的回应。
RAG特别适用于企业私有化定制场景,处理那些不适合对外公开、需要模型学习的专有数据。其核心优势在于:不需要重新训练模型,而是通过检索相关信息来增强现有模型的输出。
RAG与模型微调的区别
| RAG(检索增强生成) | 模型微调 | |
|---|---|---|
| 本质区别 | “训练"模型的"四肢” | 训练模型的"大脑" |
| 成本 | 相对较低 | 极高(算力、费用) |
| 实现难度 | 中等 | 高 |
| 适用场景 | 需要参考特定知识库回答问题 | 需要模型从根本上学习新能力 |
| 可扩展性 | 高(知识库可动态更新) | 低(需重新训练) |
| 技术要求 | 向量检索、提示工程 | 深度学习、大规模算力 |
简单来说,微调是直接改变模型权重的过程,需要大量计算资源,一般企业难以承担。而RAG则是在不改变模型本身的情况下,通过检索相关信息来增强模型的回答能力,成本相对较小,更适合企业级应用。
RAG的两个核心阶段
1. 索引阶段(Indexing)
索引阶段主要完成以下工作:
- 读取文件内容:加载各种格式的文档(PDF、TXT、Word等)
- 文本分割:将长文本分割成适当大小的段落
- 向量化与存储:生成文本段落的向量表示并保存到向量数据库中
# 索引阶段示例代码
loader = TextLoader("documents.txt", encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
segments = text_splitter.split_documents(documents)
vector_store = RedisVectorStore(embedding_model, config=redis_config)
vector_store.add_documents(segments)
2. 检索增强阶段(Retrieval-Augmentation)
检索增强阶段执行以下流程:
- 读取用户查询并向量化
- 在向量库中检索相关文本段落
- 将检索结果作为上下文与用户问题一起提供给大模型
- 生成最终回答
# 检索增强阶段示例代码
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
relevant_docs = retriever.invoke(user_query)
prompt = prompt_template.format(context=relevant_docs, question=user_query)
response = llm_model.invoke(prompt)
RAG效果评测
为了系统评估RAG系统的性能,通常需要构建自动化评测工具,结合RAGAs(RAG评估框架)进行全面评测。主要评测指标包括:
- 准确率(Accuracy):回答的正确程度
- 召回率(Recall):能够找回的相关信息比例
- 精确率(Precision):返回结果中相关信息的比例
- F1值:精确率和召回率的调和平均
- 回答时间:系统生成回答所需的时间
- 相关性(Relevance):回答与问题的相关程度
- 完整性(Completeness):回答包含所有必要信息的程度
RAG性能优化策略
要提升RAG系统的效能,可以从以下几个方面入手:
-
优化原始数据质量
- 确保文档内容准确、相关
- 预处理文本,去除噪音和冗余信息
- 结构化重要知识点
-
改进向量化方法
- 使用更先进的嵌入模型(如text-embedding-3等)
- 调整嵌入参数以适应特定领域
-
增强检索策略
- 实现混合检索(关键词+向量搜索)
- 调整检索参数(k值、相似度阈值等)
-
重排序机制
- 使用如通义千问的重排序模型对检索结果进行二次排序
- 基于相关性和信息丰富度重新评分
-
优化提示工程
- 设计更精确的提示模板
- 使用少样本示例引导模型输出
RAG应用场景
RAG技术在多种场景下表现出色:
-
问答系统
- 企业知识库问答
- 技术支持系统
- 产品常见问题解答
-
文档摘要与处理
- 长文档自动摘要
- 报告分析与重点提取
- 研究论文信息提取
-
客户服务
- 智能客服助手
- 工单自动分类与回复
- 个性化服务推荐
-
教育培训
- 智能教学助手
- 个性化学习内容推荐
- 自适应题目生成
-
决策支持
- 数据分析报告生成
- 市场趋势分析
- 风险评估与建议
结语
RAG技术为大语言模型注入了"外部记忆"能力,使其能够基于最新和专有知识提供准确回答,有效克服了大模型"幻觉"问题。相比传统的微调方法,RAG具有实现成本低、部署简单、知识可实时更新等优势,特别适合企业级应用场景。
随着向量数据库、嵌入模型和提示工程技术的不断进步,RAG系统的性能还将持续提升,为各领域的智能问答和知识服务带来更大价值。