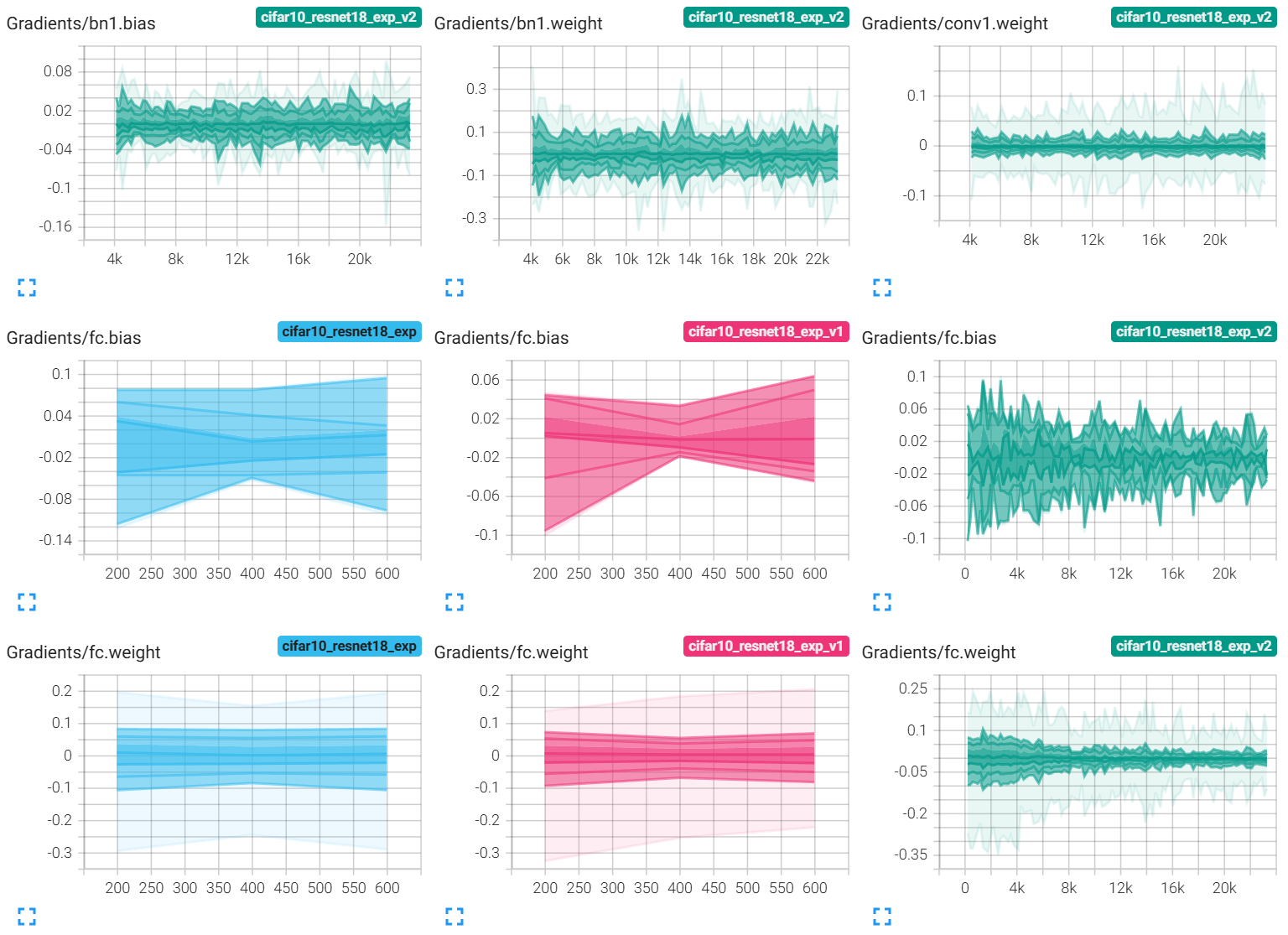
追踪计算机视觉领域的前沿热点是把握技术发展方向、推动创新落地的关键,分析这些热点,不仅能洞察技术趋势,更能为科研选题和工程实践提供重要参考。本文对计算机视觉顶刊《International Journal of Computer Vision》2025年5月前沿热点进行了可视化分析。欢迎阅读和转发。
本文作者为韩煦,审核为邓镝。
一、期刊介绍
《国际计算机视觉杂志》(International Journal of Computer Vision,简称IJCV)是计算机视觉领域的顶级期刊。该期刊现为月刊(每年出版12期),致力于发表高质量、原创性的学术论文,以推动计算机视觉科学与工程的蓬勃发展。期刊影响因子11.6(2023),5年期刊影响因子14.5(2023),提交首次决定(中位数)96天。表1展示了IJCV近5年发表文章的数量及期刊的影响因子(IF)的变化情况。
表 1 IJCV每年的文章数量和影响因子
| 年度 | 文章数/年 | IF |
| 2023 | 198 | 11.6 |
| 2022 | 187 | 19.5 |
| 2021 | 130 | 13.3 |
| 2020 | 187 | 7.4 |
| 2019 | 90 | 5.7 |
该期刊的讨论主题领域主要聚焦于计算机视觉领域,具体来说包括图像形成、处理、分析与解读、机器学习技术、统计方法;传感器技术;基于图像的渲染、计算机图形学、机器人技术、影像解译、图像检索、视频分析与标注、多媒体等;视觉计算模型及人脑视觉架构研究。
期刊网址:https://link.springer.com/journal/11263
二、热点分析
表2 论文标题中出现的高频主题词
| 高频主题 | 翻译 | 出现次数 | 核心方向 |
| Generation | 生成 | 8 | 故事 / 图像 / 视频生成 |
| Consistency | 一致性 | 6 | 多视图、跨模态、角色身份一致性 |
| Re-identification | 重识别 | 4 | 行人 / 视频重识别 |
| Semantic Segmentation | 语义分割 | 4 | 弱监督 / 跨模态 / 医学场景 |
| Diffusion Models | 扩散模型 | 3 | 动态跟踪、长视频生成 |
| 3D Reconstruction | 3D 重建 | 3 | 神经场景、形状表示 |
| Self-Supervised | 自监督学习 | 3 | 无监督 / 少监督复杂任务 |
| Multi-modal | 多模态 | 3 | 视觉 - 语言、跨模态蒸馏 |
| Medical Image | 医学影像 | 2 | 分割、肿瘤预测 |
| Adversarial Learning | 对抗学习 | 2 | 质量评估、攻击防御 |
| Multi-view | 多视图 | 2 | SLIDE(多视图一致性)、多视图立体网络(深度估计) |
| Unsupervised | 无监督 | 2 | 跨模态蒸馏语义分割 |
| Semi-supervised | 半监督 | 2 | 医学影像分割、联邦半监督学习 |
| DeepFake Detection | DeepFake 检测 | 2 | 鲁棒序列检测、双级适配器检测 |
| Cross-Modal | 跨模态 | 2 | 跨模态蒸馏 |

图 1 研究热点词云图
表2列出了在本次会议中,被录用的38篇论文标题中的15个高频主题词。图1展示了基于IJCV研究热点生成的词云图,涵盖语义分割、扩散模型、一致性等研究领域。表3总结了本期IJCV的已被接受的投稿论文。
表3 2025年5月IJCV发表论文的列表
| 题目 | 中文翻译 |
| AutoStory: Generating Diverse Storytelling Images with Minimal Human Efforts | AutoStory:以最小人力生成多样化故事图像 |
| SLIDE: A Unified Mesh and Texture Generation Framework with Enhanced Geometric Control and Multi-view Consistency | SLIDE:具有增强几何控制与多视角一致性的统一网格与纹理生成框架 |
| Exploring Homogeneous and Heterogeneous Consistent Label Associations for Unsupervised Visible-Infrared Person ReID | 探索同质与异质一致标签关联的无监督可见光–红外行人重识别 |
| AniClipart: Clipart Animation with Text-to-Video Priors | AniClipart:基于文本到视频先验的剪贴画动画 |
| Combating Label Noise with a General Surrogate Model for Sample Selection | 使用通用替代模型进行样本选择以对抗标签噪声 |
| CSFRNet: Integrating Clothing Status Awareness for Long-Term Person Re-identification | CSFRNet:融合服装状态感知的长时跨度行人重识别网络 |
| Pseudo-Plane Regularized Signed Distance Field for Neural Indoor Scene Reconstruction | 伪平面正则化签名距离场用于神经室内场景重建 |
| RepSNet: A Nucleus Instance Segmentation Model Based on Boundary Regression and Structural Re-Parameterization | RepSNet:基于边界回归与结构重参数化的细胞核实例分割模型 |
| Blind Image Quality Assessment: Exploring Content Fidelity Perceptibility via Quality Adversarial Learning | 盲图像质量评估:通过质量对抗学习探索内容保真性感知 |
| HUPE: Heuristic Underwater Perceptual Enhancement with Semantic Collaborative Learning | HUPE:基于语义协同学习的启发式水下感知增强 |
| Robust Sequential DeepFake Detection | 强健序列化 DeepFake 检测 |
| PICK: Predict and Mask for Semi-supervised Medical Image Segmentation | PICK:用于半监督医学图像分割的预测与掩码方法 |
| Relation-Guided Versatile Regularization for Federated Semi-Supervised Learning | 基于关系引导的联邦半监督学习通用正则化 |
| General Class-Balanced Multicentric Dynamic Prototype Pseudo-Labeling | 通用类平衡多中心动态原型伪标签 |
| Diving Deep into Simplicity Bias for Long-Tailed Image Recognition | 深入探讨长尾图像识别中的简单性偏差 |
| Context-Aware Multi-view Stereo Network for Efficient Edge-Preserving Depth Estimation | 面向高效边缘保留深度估计的上下文感知多视角立体网络 |
| LDTrack: Dynamic People Tracking by Service Robots Using Diffusion Models | LDTrack:服务机器人基于扩散模型的动态人群跟踪 |
| Learning Meshing from Delaunay Triangulation for 3D Shape Representation | 从 Delaunay 三角化学习网格以进行三维形状表示 |
| RIGID: Recurrent GAN Inversion and Editing of Real Face Videos and Beyond | RIGID:真实人脸视频的循环 GAN 反演与编辑 |
| UniCanvas: Affordance-Aware Unified Real Image Editing via Customized Text-to-Image Generation | UniCanvas:通过定制文本到图像生成功能感知的统一真实图像编辑 |
| Generalized Robot Vision-Language Model via Linguistic Foreground-Aware Contrast | 通过语言前景感知对比的通用机器人视觉-语言模型 |
| Rethinking Generalizability and Discriminability of Self-Supervised Learning from Evolutionary Game Theory Perspective | 从进化博弈论视角重新思考自监督学习的泛化性与判别性 |
| Pre-trained Trojan Attacks for Visual Recognition | 预训练木马攻击用于视觉识别 |
| GL-MCM: Global and Local Maximum Concept Matching for Zero-Shot Out-of-Distribution Detection | GL-MCM:用于零样本分布外检测的全局与局部最大概念匹配 |
| A Mutual Supervision Framework for Referring Expression Segmentation and Generation | 一种用于指代表达式分割与生成的互监督框架 |
| DeepFake-Adapter: Dual-Level Adapter for DeepFake Detection | DeepFake-Adapter:用于 DeepFake 检测的双层适配器 |
| MoonShot: Towards Controllable Video Generation and Editing with Motion-Aware Multimodal Conditions | MoonShot:面向可控视频生成与编辑的运动感知多模态条件 |
| SeaFormer++: Squeeze-Enhanced Axial Transformer for Mobile Visual Recognition | SeaFormer++:用于移动视觉识别的压缩增强轴向 Transformer |
| Dual-Space Video Person Re-identification | 双空间视频行人重识别 |
| Image Synthesis Under Limited Data: A Survey and Taxonomy | 有限数据条件下的图像合成:调查与分类 |
| Sample-Cohesive Pose-Aware Contrastive Facial Representation Learning | 基于样本内聚性与姿态感知的对比人脸表征学习 |
| Learning with Enriched Inductive Biases for Vision-Language Models | 面向视觉-语言模型的富归纳偏置学习 |
| Self-supervised Shutter Unrolling with Events | 基于事件的自监督快门反展开 |
| TryOn-Adapter: Efficient Fine-Grained Clothing Identity Adaptation for High-Fidelity Virtual Try-On | TryOn-Adapter:用于高保真虚拟试穿的高效细粒度服装身份适配 |
| Correction: CMAE-3D: Contrastive Masked AutoEncoders for Self-Supervised 3D Object Detection | 勘误:CMAE-3D:用于自监督三维目标检测的对比掩码自编码器 |
| Correction: Deep Attention Learning for Pre-operative Lymph Node Metastasis Prediction in Pancreatic Cancer via Multi-object Relationship Modeling | 勘误:基于多目标关系建模的胰腺癌术前淋巴结转移预测深度注意力学习 |
| Correction: Few Annotated Pixels and Point Cloud Based Weakly Supervised Semantic Segmentation of Driving Scenes | 勘误:基于少量标注像素与点云的驾驶场景弱监督语义分割 |
投稿的论文主题反映出本期研究热点集中在一下几个方向:
- 图像/视频生成与编辑:包括故事图像生成(AutoStory)、文本到视频/图像生成(AniClipart、UniCanvas、MoonShot)、Diffusion Models 驱动的生成与编辑(LDTrack、RIGID)等。这一方向兼顾“多模态条件下的内容创生”和“运动感知的可控编辑”两大主题。
- 一致性建模与行人重识别:涉及多视角一致性(SLIDE)、可见-红外一致标签关联(Unsupervised Visible-Infrared Person ReID)、长时序状态感知重识别(CSFRNet)等。关注场景中跨视角、跨模态的一致性约束与特征对齐技术。
- 语义分割与三维重构:包括神经签名距离场重建(Pseudo-Plane Regularized SDF)、Delaunay三角网格重建(Learning Meshing from Delaunay Triangulation)、核实例分割(RepSNet)、弱监督/半监督分割(PICK、Few Annotated Pixels)等。兼顾平面、体素、点云等多种三维表示与精细分割任务。