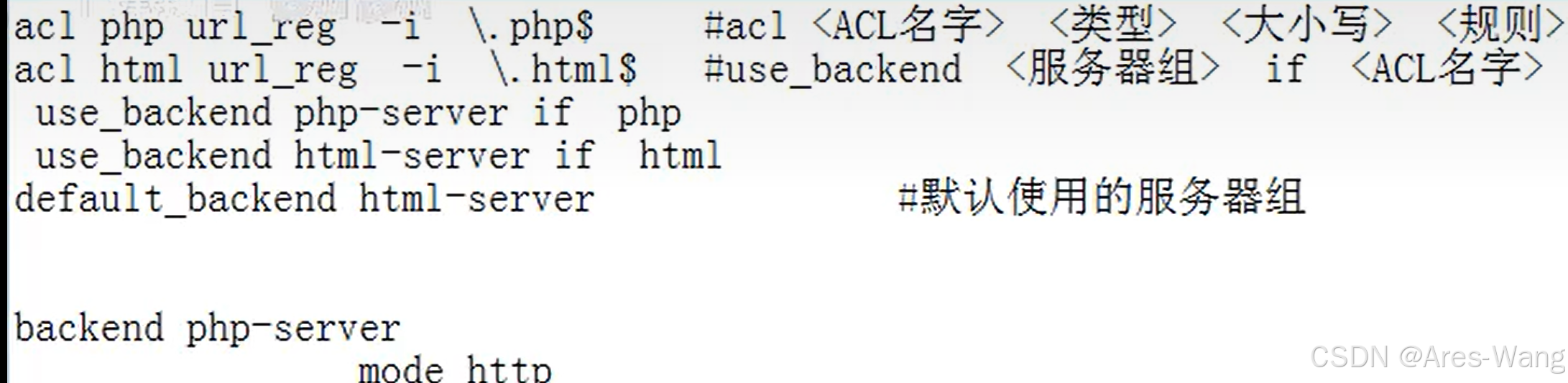
基于语言模型的知识图谱嵌入
原文链接:https://arxiv.org/abs/2301.10405
Comment: AAAI 2024.03
摘要
-
基于语言模型的KG嵌入通常部署为静态工件,这使得它们在部署后如果不重新训练就很难修改。在本文中提出了一个编辑基于语言模型的 KG 嵌入的新任务。
-
此任务旨在促进对 KG 嵌入进行快速、数据高效的更新,而不会影响其他方面的性能。
-
构建了四个新的数据集E-FB15k237、AFB15k237、E-WN18RR 和 A-WN18RR,并评估了几个知识编辑基线,这些基线表明以前的模型处理所提出的具有挑战性的任务的能力有限。我们进一步提出了一个简单而强大的基线,称为 KGEditor,它利用超网络(引入额外参数层)来编辑/添加事实。
引言
-
研究的背景与动机
-
KG的重要性:结构化知识的表示形式,广泛应用于信息检索、问答系统、推荐系统等任务,其质量直接影响下游应用的效果。
-
语言模型与KG嵌入的结合:近年来,预训练语言模型(BERT、GPT)被用于生成KG实体和关系的嵌入向量(KG embeddings),这类方法能够捕捉丰富的语义信息,优于传统基于规则或统计的方法。
-
静态模型的局限性:当前基于语言模型的KG嵌入通常是静态的(即训练后参数固定),无法动态适应KG的更新需求(如新增事实或修正错误)。这导致知识过时、模型与现实知识脱节等问题。
-
-
本文的核心任务与目标
-
提出新任务:定义“编辑KG嵌入”的任务,具体包括两种场景:
-
EDIT(编辑):修正KG中错误的事实(错误的实体关系)。
-
ADD(添加):向KG中新增知识(添加新的实体-关系对)。
-
-
目标:在不重新训练整个模型的前提下,通过局部调整实现对KG嵌入的高效编辑,同时保持其他知识的完整性。
-
-
方法和创新点
-
KGEditor 方法:提出一种基于超网络的轻量级编辑框架,通过引入额外参数层,仅修改与目标知识相关的嵌入,避免全局扰动。
-
数据集构建:为评估编辑效果,构建了四个新数据集(E-FB15k237、A-FB15k237、E-WN18RR、A-WN18RR),分别对应编辑和添加任务。
-
评价准则:
-
知识可靠性(Knowledge Correctness):编辑后的知识是否准确。
-
知识局部性(Knowledge Locality):编辑操作对其他知识的影响是否最小。
-
知识效率(Knowledge Efficiency):编辑过程是否资源友好(如计算和存储开销)。
-
-
-
主要贡献
-
任务定义与数据集:首次明确“编辑KG嵌入”的任务,并构建了标准化数据集,为后续研究提供基准。
-
KGEditor 方法:提出一种高效、灵活的编辑框架,能够快速更新KG嵌入,同时避免知识遗忘。
-
实证分析:通过对比实验验证了KGEditor在可靠性、局部性和效率上的优势,揭示了当前方法在编辑KG嵌入上的不足。
-
相关工作
传统的KG嵌入
-
基于结构的方法:
-
早期方法(TransE、TransR、DistMult、ComplEx)通过建模三元组(头实体-关系-尾实体)的几何关系,将实体和关系映射到低维向量空间。
-
优势:计算高效,适合大规模KG。
-
局限性:依赖KG的结构信息,难以捕捉语义信息(如实体描述、文本上下文)。
-
-
基于语义的方法:
-
方法(ConvE、R-GCN)结合图神经网络(GNN)或卷积操作,建模实体和关系的复杂交互。
-
优势:能捕捉更丰富的结构模式。
-
局限性:仍以结构信息为主,语义表示能力有限。
-
基于语言模型的KG嵌入
-
预训练语言模型的应用:
-
预训练语言模型(BERT、RoBERTa)用于生成KG嵌入,利用文本描述(如实体名称、属性值)增强语义表示。
-
典型方法:
-
K-BERT:结合KG结构和语言模型,通过掩码任务联合优化实体和关系的表示。
-
ERNIE:在文本中引入KG三元组作为额外监督信号,提升语义关联性。
-
-
优势:能捕捉实体的多义性和上下文依赖。
-
局限性:模型在训练后参数固定,无法动态更新嵌入(即“静态模型”问题)。
-
-
联合训练方法:
- 一些方法将KG结构与语言模型联合训练,但依然面临更新成本高、灵活性差的问题。
知识编辑与动态更新
-
KG的动态维护:
-
传统方法通过增量学习或迁移学习更新KG,但通常针对结构化数据(如三元组),难以直接应用于嵌入向量。
-
典型挑战:
-
知识冲突:新增或修改知识可能导致原有知识的“遗忘”。
-
局部性控制:如何仅修改目标知识而不影响其他部分。
-
-
-
基于嵌入的编辑方法:
-
参数微调:通过少量样本微调模型参数,但需重新训练整个模型,成本高。
-
向量覆盖:直接替换实体/关系的嵌入向量,但可能破坏语义一致性。
-
超网络:引入额外参数生成编辑后的嵌入,但早期方法缺乏系统性评估。
-
方法
任务定义
-
任务目标:在不重新训练整个语言模型的前提下,对基于语言模型生成的KG嵌入进行局部修改,以实现动态更新知识图谱中的实体或关系,同时保持其他知识的完整性。
-
任务分类
-
KG的知识定义(h,r,t)h头实体,r关系,t尾实体
-
EDIT
-
目标:修正知识图谱中已存在的错误事实
-
知识定义(h,r,y,a)或(y,r,t,a)其中y为错误/过时实体,a表示真确要替换y的实体
-
-
ADD
-
目标:向知识图谱中新增实体或关系。
-
同时需要维护模型的稳定性其中 x′ 和 y′ 分别表示模型中存储的事实知识的输入和标签
-
-
-
评估指标
-
知识可靠性(Knowledge Reliability)
-
编辑后的嵌入是否能正确预测目标事实
-
指标:Succ@k(Top-k的比例)
-
-
知识局部性(Knowledge Locality)
-
编辑KG嵌入后对原有知识的影响
-
其中 x′ 是从原始的预训练数据集中采样获取的, f(x′;W)≤k 代表的是由原始参数 W 的模型预测的rank值小于 k 的统计, W~ 表示的是更新后的参数。
-
其中 Redit 和 Rorigin 代表的模型编辑前后需要编辑数据集的平均rank值, Rs_edit 和 Rs_origin 表示的是模型编辑前后参考数据集的平均rank值。
-
-
知识效率(Knowledge Efficiency)
-
旨在评估编辑的效率
-
指标:编辑器的参数量和编辑时间
-
-
数据集构建
-
基础数据集
-
Freebase(FB15k237):一个大规模知识图谱,包含实体、关系和三元组,广泛用于KG嵌入研究。
-
WordNet(WN18RR):一个基于语义的词汇数据库,包含词与词之间的层次化关系。
-
-
衍生数据集
-
EDIT任务:E-FB15k237, E-WN18RR
-
ADD任务:A-FB15k237, A-WN18RR
-
-
关键构建步骤
-
排除简单样本(数据预处理)
-
问题:预训练语言模型(PLM)本身已包含大量事实知识,可能直接预测正确尾实体,干扰编辑效果评估。
-
解决方案:筛选 预测排名 > 2,500 的三元组作为候选集。将预测排名<2500的视为简单样本,剔除。
-
目的:数据过滤,为后续任务提供高质量评估集
-
-
EDIT 任务数据集构建
-
目标:训练和评估修正错误知识的能力
-
构造流程:
-
生成错误知识:从现有知识图谱中随机破坏三元组以生成损坏的数据集
-
训练需编辑的模型:用损坏数据集微调PLM,生成一个包含错误知识的待编辑模型。
-
过滤:
-
Edit Dataset:模型预测结果错误的三元组
-
参考集 (L-Test):模型依旧预测正确的(用于评估知识局部性)。
-
-
-
-
ADD任务数据集
-
目标:评估新增未见知识的能力
-
数据划分:
-
预训练集:原始训练集(不含新增三元组)。
-
新增集 (Train):完全独立的新三元组(从困难样本中选择)。
-
-
关键区别:
- 直接使用新增集作为测试集(因新增知识从未出现在预训练数据中)。
-
参考集 (L-Test):同EDIT任务,用于检验新增知识是否干扰原有知识。
-
-
基于语义模型的KGE
-
FT-KGE:微调方式
-
将三元组 (h, r, t) 转换为文本序列(例如:[CLS] + h描述 + [SEP] + r描述 + [SEP] + t描述)。
-
任务形式:二元分类(判断三元组是否有效):y∈{0,1} 表示三元组正确性。
-
-
PT-KGE:提示调优方式
-
将三元组转换为自然语言提示(例如:“h r [MASK]”),将链接预测转化为掩码预测任务。
-
实体扩展:将 KG 中所有实体视为语言模型的特殊 token,扩展词汇表。
-
任务形式:预测掩码位置的实体:
-
-
KGEditor 编辑框架独立于 KGE 构建方法,可同时应用于 FT-KGE 和 PT-KGE 生成的嵌入。
编辑KGE的基线模型
-
外部模型编辑器
-
利用超外部网络来获取参数的偏移并添加到原始模型参数中进行编辑(将原始实体 y 替换为实体 a)修改的保持全局的一致性
-
核心思想:通过外部超网络生成参数更新量(ΔW),间接修改原模型参数。
-
代表方法:
-
**KE:**使用双向LSTM作为超网络,学习参数更新量 ΔW。
-
MEND:用MLP预测微调梯度的低秩分解,生成轻量级参数更新。适用于大模型(如BART、GPT-3)的高效编辑。
-
-
优势:灵活性强,不直接改动原模型结构。
-
局限:需额外训练超网络,参数量较大。
-
-
附加参数编辑器
-
核心思想:在模型内部添加可训练参数层,调整输出分布以实现编辑。
-
代表方法:CALINET
-
假设FFN存储事实知识,通过添加带“校准记忆槽”的小型FFN层调整原FFN输出。
-
参数量小,但编辑能力有限。
-
-
优势:参数量少,计算高效。
-
局限:依赖FFN存储知识的假设,对复杂编辑任务效果不佳。
-
KGEditor
利用超外部网络来更新 FFN 中的知识(上:EDIT,下:ADD)。
-
KGEditor融合外部模型编辑器和附加参数编辑器的优势,提出一个简单健壮的基线模型。
-
使用双向LSTM构建超网络。对 ⟨x、y、a⟩ 进行编码,用特殊的分隔符将它们连接起来,给LSTM。然后双向 LSTM 的最后的输出送到 FNN 中,以生成用于知识编辑的单个向量H。
-
低秩梯度变换
评估
实验设置
-
数据集:使用构建的数据集E-FB15k237、AFB15k237、E-WN18RR 和 A-WN18RR
-
模型初始化:使用预训练数据集(EDIT任务用被破坏的训练集,ADD任务用原始训练集),基于BERT初始化KG Embedding
-
训练与评估:
-
编辑器(Editor)使用训练集训练,测试集评估
-
ADD任务直接使用训练集评估(因新知识未出现在预训练中)
-
-
微调方式:采用PT-KGE作文默认设置
主要结果
-
EDIT任务:
-
KGE_FT:直接微调所有参数;KGE_ZSL:不调整任何参数;K-Adapter:使用适配器微调参数。CALINET:扩展FNN;KE和MEND:使用外部编辑器
-
知识可靠性:KGEditor在
Succ@1和Succ@3上显著优于基线。 -
知识局部性:KGEditor的
RK@3最高,表明其最小化对原有知识的干扰。 -
效率:KGEditor参数量(38.9M)远低于KE(88.9M)和MEND(59.1M),且推理时间更短。
-
-
ADD任务:
-
可靠性:KGEditor在
Succ@1接近全参数微调(KGE_FT),且显著优于其他编辑器。 -
局部性:KGEditor的
RK@3最高,且RKroc(稳定性变化率)最低。
-
-
KG初始化方法对比:PT-KGE在知识可靠性(
ERroc)和局部性(RKroc)上均优于FT-KGE,表明Prompt更适合编辑任务。 -
编辑知识数量的影响:
-
单次编辑中修改的三元组数量
-
所有模型的
Succ@1下降,但KGEditor和KE的局部性(RK@3)更稳定,MEND则显著下降。
-
-
可视化案例:编辑后目标实体(如"Marc Shaiman")进入预测中心,其他实体位置基本不变,直观验证了知识可靠性和局部性。
结论
-
提出KGE模型的任务允许直接修改三元组以适应特定任务,从而提高编辑过程的效率和准确性。
-
与早期的预训练语言模型编辑任务相反,该方法依赖于KG事实来修改知识,而不使用预训练模型知识。
-
这些方法提高了性能,并为知识表示和推理的研究提供了重要的见解。
未来工作
-
编辑KGE模型会带来持续存在的问题,特别是处理复杂的知识和多对多关系。由此类关系产生的已编辑事实可能会使模型偏向于已编辑的实体,从而忽略其他有效实体。
-
实验KGE模型很小,都利用了标准 BERT。未来,目标是设计模型来编辑具有多对多关系的知识,并集成 LLM 编辑技术。