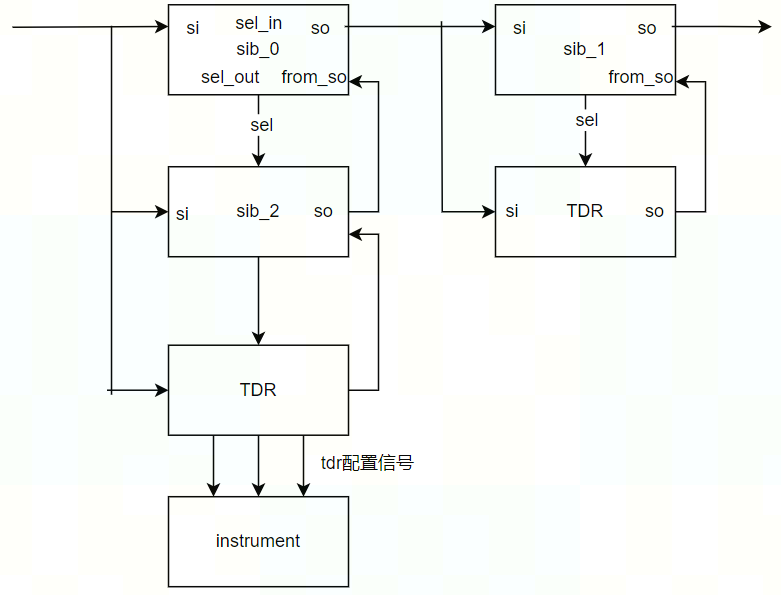
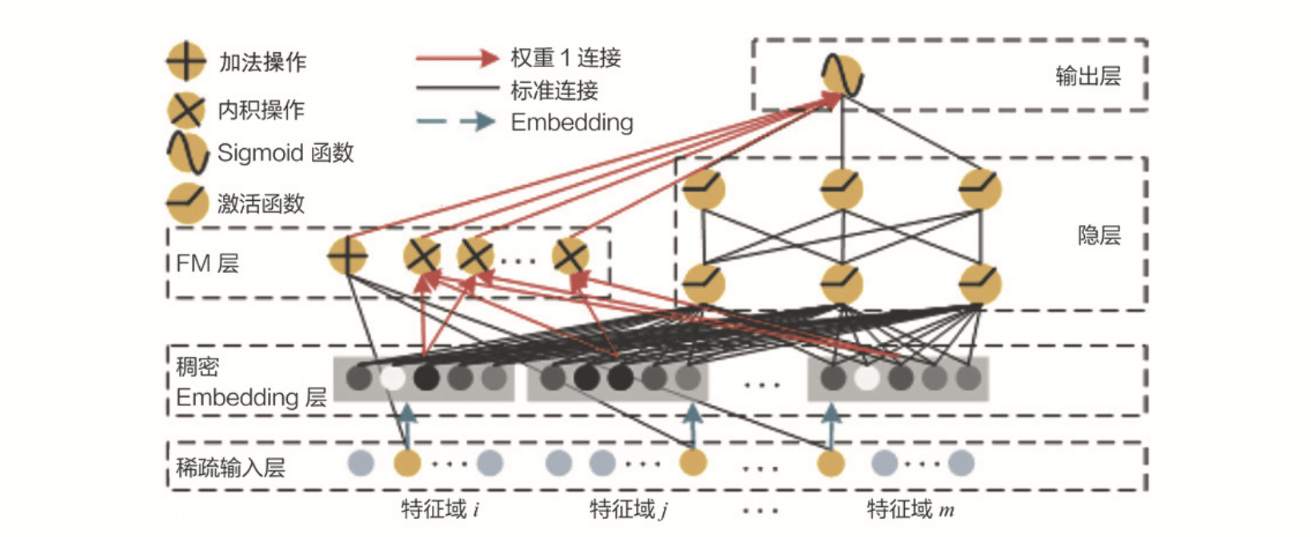
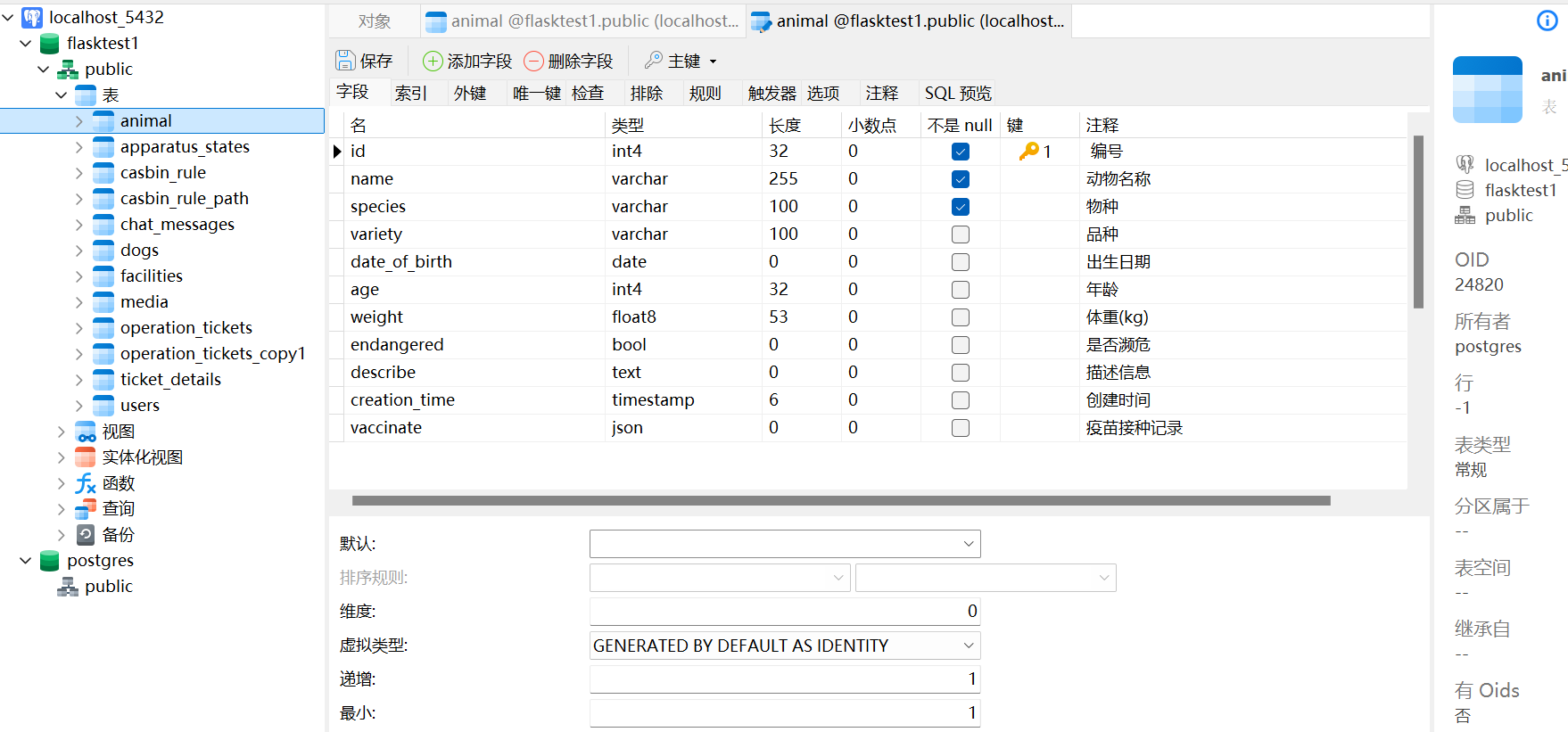
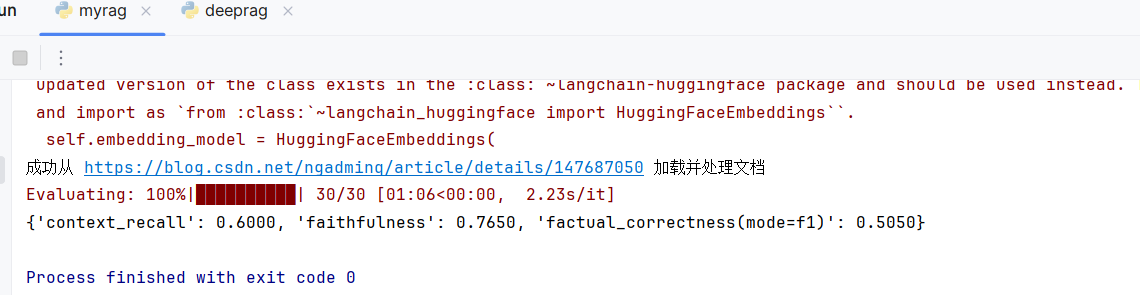
DAY 43 复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as F
# 设置随机种子确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([
# 新增:调整图像大小为统一尺寸
transforms.Resize((32, 32)), # 确保所有图像都是32x32像素
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
# 测试集:仅进行必要的标准化,保持数据原始特性
test_transform = transforms.Compose([
# 新增:调整图像大小为统一尺寸
transforms.Resize((32, 32)), # 确保所有图像都是32x32像素
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
# 定义数据集根目录
root = r'C:\Users\vijay\Desktop\1'
train_dataset = datasets.ImageFolder(
root=root + '/train', # 指向 train 子文件夹
transform=train_transform
)
test_dataset = datasets.ImageFolder(
root=root + '/test', # 指向 test 子文件夹
transform=test_transform
)
# 打印类别信息,确认数据加载正确
print(f"训练集类别: {train_dataset.classes}")
print(f"测试集类别: {test_dataset.classes}")
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)@浙大疏锦行