文章目录
- 使用ragas做评估
- 在自己的数据集上评估
- 完整代码
- 代码讲解
- 1. RAG系统构建
- 核心组件初始化
- 文档处理流程
- 2. 评估数据集构建
- 3. RAGAS评估实现
- 1. 评估数据集创建
- 2. 评估器配置
- 3. 执行评估
本系列阅读:
理论篇:RAG评估指标,检索指标与生成指标①
实践篇:利用ragas在自己RAG上实现LLM评估②
首先我们可以共识LLM的评估最好/最高效的方式就是再利用LLM的强大能力,而不是用传统指标。
假设我们不用LLM评估我们只有两条方式可实现:
- 传统指标,如Bleu。需输入标准答案(通常也是人工审核答案是不是标准的,或者是人工制造标准答案),缺点是效果有限,用了都知道效果惨不忍睹。
- 纯人工打分。缺点是耗时,带有主观性。
使用ragas做评估
推荐一个包ragas。但是它的教程文档确实写得不太好,可能是jupyter格式,直接在py中运行,总是会报少变量之类。我这边都改动了下,确保我们py文件可以运行。
ragas(Retrieval Augmented Generation Assessment)是社区最著名的评估方案,内置了我们常见的评估指标。
利用了LLM评估,因此不需要人工打标。其出名是因为封装了LLM做评估,简单易用(当然其实这些也是我们可以造轮子实现的~)。
代码链接https://github.com/blackinkkkxi/RAG_langchain/blob/main/learn/evaluation/RAGAS-langchian.ipynb
在自己的数据集上评估
完整可运行的代码见本文的完整代码小节,代码可运行。而1~3我们会拆开完整代码讲解,代码主要用于讲解完整代码,可能不能运行。
完整代码
在使用我的代码你只需要把deepseekapi换成你自己的即可。
import os
import re
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chat_models import init_chat_model
from ragas import evaluate
from ragas.llms import LangchainLLMWrapper
from ragas import EvaluationDataset
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectness
class RAG:
def __init__(self, api_key=None):
"""使用DeepSeek模型和BGE嵌入初始化RAG系统"""
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 初始化对话模型
self.llm = init_chat_model(
model="deepseek-chat",
api_key=api_key,
api_base="https://api.deepseek.com/",
temperature=0,
model_provider="deepseek",
)
# 初始化嵌入模型
self.embedding_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5"
)
# 初始化文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
# 初始化向量存储和检索器
self.vectorstore = None
self.retriever = None
self.qa_chain = None
# 设置提示模板
self.template = """
根据以下已知信息,简洁并专业地回答用户问题。
如果无法从中得到答案,请说"我无法从已知信息中找到答案"。
已知信息:
{context}
用户问题:{question}
回答:
"""
self.prompt = PromptTemplate(
template=self.template,
input_variables=["context", "question"]
)
def load_documents_from_url(self, url, persist_directory="./chroma_db"):
"""从网页URL加载文档并创建向量存储"""
# 从网页加载文档
loader = WebBaseLoader(url)
documents = loader.load()
# 将文档分割成块
chunks = self.text_splitter.split_documents(documents)
# 创建向量存储
self.vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embedding_model,
persist_directory=persist_directory
)
# 创建检索器
self.retriever = self.vectorstore.as_retriever()
# 创建问答链
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
chain_type_kwargs={"prompt": self.prompt}
)
print(f"成功从 {url} 加载并处理文档")
def ask(self, question):
"""便捷的提问方法"""
result = self.qa_chain.invoke({"query": question})
return result["result"]
def relevant_docs_with_scores(self, query, k=1):
"""计算相关文档及其相似度分数,返回处理后的文档信息"""
docs_with_scores = self.vectorstore.similarity_search_with_score(query, k=k)
# 处理文档内容
processed_docs = []
for i, (doc, score) in enumerate(docs_with_scores, 1):
# 清理文档内容
content = doc.page_content.strip()
# 去除回车符、换行符和多余的空白字符
content = content.replace('\n', ' ').replace('\r', ' ').replace('\t', ' ')
# 合并多个连续空格为单个空格
content = re.sub(r'\s+', ' ', content)
processed_docs.append({
'index': i,
'score': score,
'content': content
})
return processed_docs
# 使用示例
if __name__ == "__main__":
api_key = "X"
queries = [
"为什么Transformer需要位置编码?",
"QKV矩阵是怎么得到的?",
"注意力机制的本质是什么?",
"对于序列长度为n的输入,注意力机制的计算复杂度是多少?",
"在注意力分数计算中,为什么要除以√d?",
"多头注意力机制的主要作用是什么?",
"解码器中的掩码自注意力是为了什么?",
"编码器-解码器注意力中,Query来自哪里?",
"GPT系列模型使用的是哪种架构?",
"BERT模型适合哪类任务?"
]
# 初始化RAG
rag = RAG(api_key)
# 从URL加载文档
rag.load_documents_from_url("https://blog.csdn.net/ngadminq/article/details/147687050")
expected_responses = [
"Transformer的输入是并行处理的,不像RNN有天然的序列关系,因此需要位置编码来为模型提供词元在序列中的位置信息,确保模型能理解词的先后顺序。",
"QKV矩阵通过将输入向量分别与三个不同的权重矩阵W_q、W_k、W_v进行线性投影得到,这三个权重矩阵是模型的可学习参数,在训练过程中不断优化。",
"注意力机制的本质是为序列中的每个词找到重要的上下文信息,通过计算词与词之间的相关性分数,实现对重要信息的聚焦和整合。",
"注意力机制的计算复杂度是O(n²),因为序列中每个词都需要与所有其他词计算注意力分数,形成n×n的注意力矩阵。",
"除以√d是为了提升训练稳定性,防止注意力分数过大导致softmax函数进入饱和区,确保梯度能够有效传播。",
"多头注意力机制可以从多个角度捕捉不同类型的词间关联,比如语义关系、句法关系等,增强了模型的表达能力和理解能力。",
"解码器中的掩码自注意力是为了防止当前位置关注未来位置的信息,确保在自回归生成过程中每个位置只能看到当前及之前的信息。",
"在编码器-解码器注意力中,Query来自解码器的前一层输出,而Key和Value来自编码器的最终输出,这样解码器就能利用编码器处理的源序列信息。",
"GPT系列模型使用仅解码器架构,专门针对文本生成任务设计,通过掩码自注意力机制实现从左到右的序列生成。",
"BERT模型适合分类和理解类任务,如文本分类、命名实体识别、情感分析、问答等,因为它使用双向编码器可以同时关注上下文信息。"
]
dataset = []
for query, reference in zip(queries, expected_responses):
# 获取相关文档及分数并打印
relevant_docs = rag.relevant_docs_with_scores(query)
relevant_docs = relevant_docs[0]['content']
response = rag.ask(query)
dataset.append(
{
"user_input": query,
"retrieved_contexts": [relevant_docs],
"response": response,
"reference": reference
}
)
evaluation_dataset = EvaluationDataset.from_list(dataset)
llm = init_chat_model(
model="deepseek-chat",
api_key=api_key,
api_base="https://api.deepseek.com/",
temperature=0,
model_provider="deepseek",
)
evaluator_llm = LangchainLLMWrapper(llm)
result = evaluate(dataset=evaluation_dataset, metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],
llm=evaluator_llm)
print(result)
以下是运行的结果:
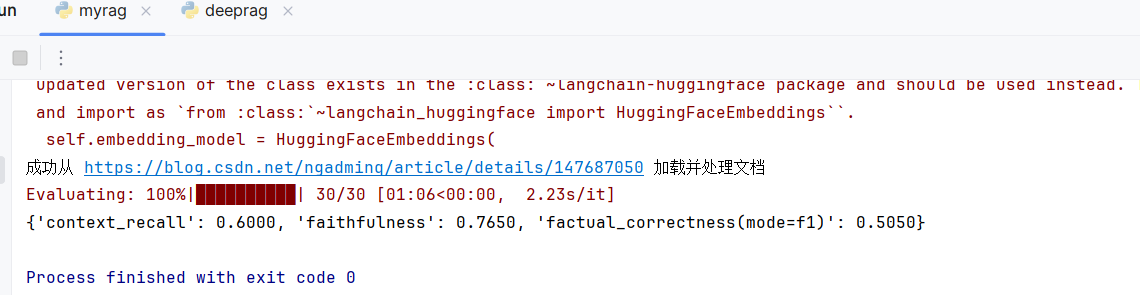
根据我们的结果指标可以针对指标有优化方向
代码讲解
1. RAG系统构建
核心组件初始化
class RAG:
def __init__(self, api_key=None):
# DeepSeek聊天模型
self.llm = init_chat_model(
model="deepseek-chat",
api_key=api_key,
api_base="https://api.deepseek.com/",
temperature=0,
model_provider="deepseek",
)
# BGE中文嵌入模型
self.embedding_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5"
)
# 文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
技术要点:
- 使用DeepSeek作为生成模型,temperature=0确保输出稳定性
- BGE-large-zh-v1.5是目前中文嵌入效果较好的开源模型
- 文本分块策略:500字符块大小,50字符重叠防止信息丢失
文档处理流程
def load_documents_from_url(self, url, persist_directory="./chroma_db"):
# 1. 网页内容加载
loader = WebBaseLoader(url)
documents = loader.load()
# 2. 文档分块
chunks = self.text_splitter.split_documents(documents)
# 3. 向量化存储
self.vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embedding_model,
persist_directory=persist_directory
)
# 4. 构建检索链
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
chain_type_kwargs={"prompt": self.prompt}
)
2. 评估数据集构建
数据集需要包含四个核心要求
dataset.append({
"user_input": str, # 用户查询,即我们备好的一系列问题
"retrieved_contexts": [str,str], # 检索到的上下文,list格式
"response": str, # 系统回答
"reference": str # 标准答案,人工制造,我这里使用cluade生成的
})
3. RAGAS评估实现
1. 评估数据集创建
from ragas import EvaluationDataset
evaluation_dataset = EvaluationDataset.from_list(dataset)
2. 评估器配置
from ragas.llms import LangchainLLMWrapper
evaluator_llm = LangchainLLMWrapper(llm)
关键点: RAGAS使用LLM作为评估器,需要将LangChain模型包装成RAGAS兼容格式
3. 执行评估
代码使用了三个核心评估指标:
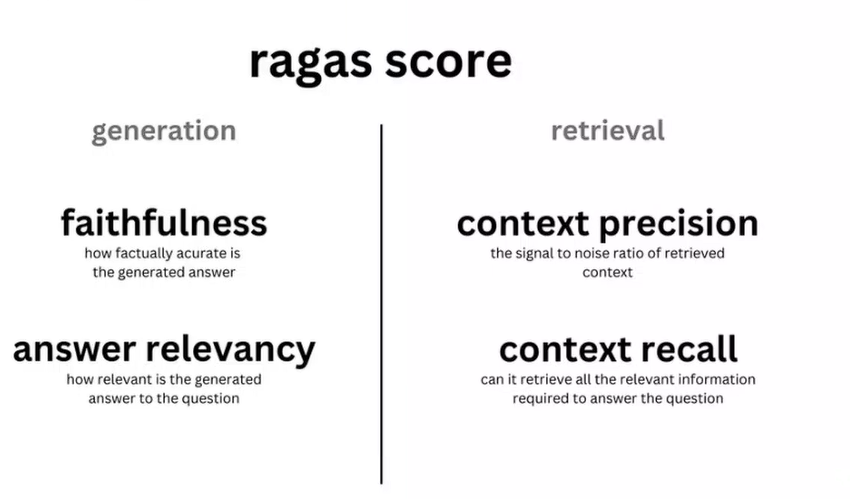
LLMContextRecall(上下文召回率)
- 作用: 评估检索到的上下文是否包含回答问题所需的信息
- 计算方式: 通过LLM判断标准答案中的信息有多少能在检索上下文中找到
- 公式: Context Recall = 可在上下文中找到的标准答案句子数 / 标准答案总句子数
Faithfulness(忠实度)
- 作用: 衡量生成回答与检索上下文的一致性,防止幻觉
- 计算方式: 检查回答中的每个声明是否能在提供的上下文中得到支持
- 公式: Faithfulness = 有上下文支持的声明数 / 总声明数
FactualCorrectness(事实正确性)
- 作用: 评估生成回答的事实准确性
- 计算方式: 将生成回答与标准答案进行事实层面的比较
- 评估维度: 包括事实的正确性、完整性和相关性
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectness
result = evaluate(
dataset=evaluation_dataset,
metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],
llm=evaluator_llm
)