1 引言
1.1 研究背景与意义
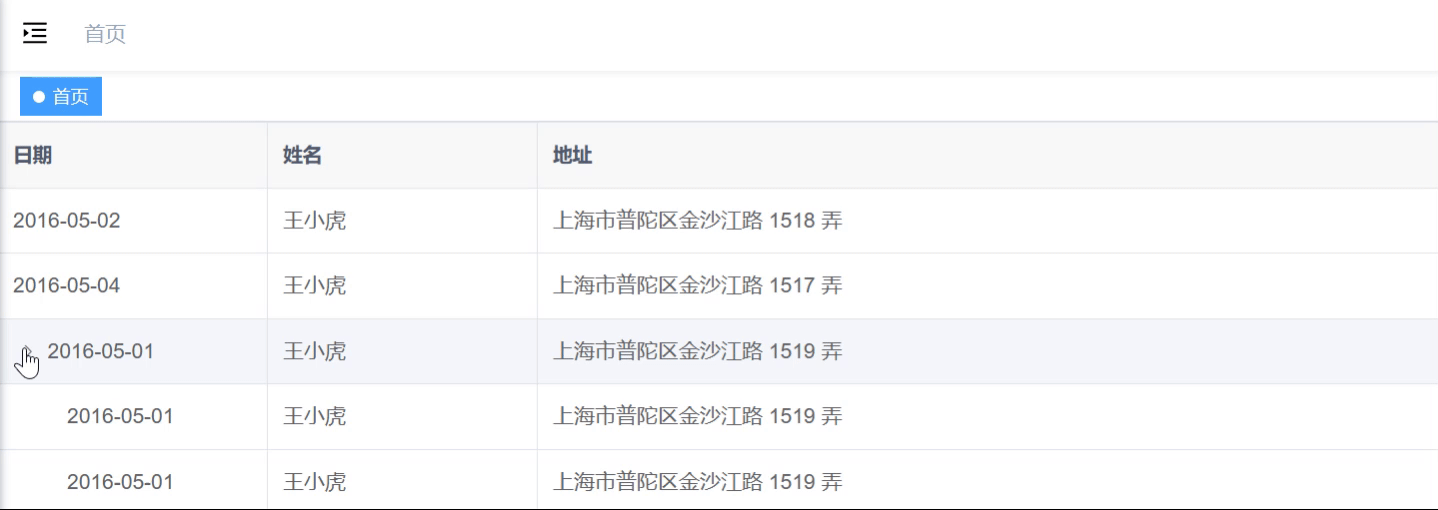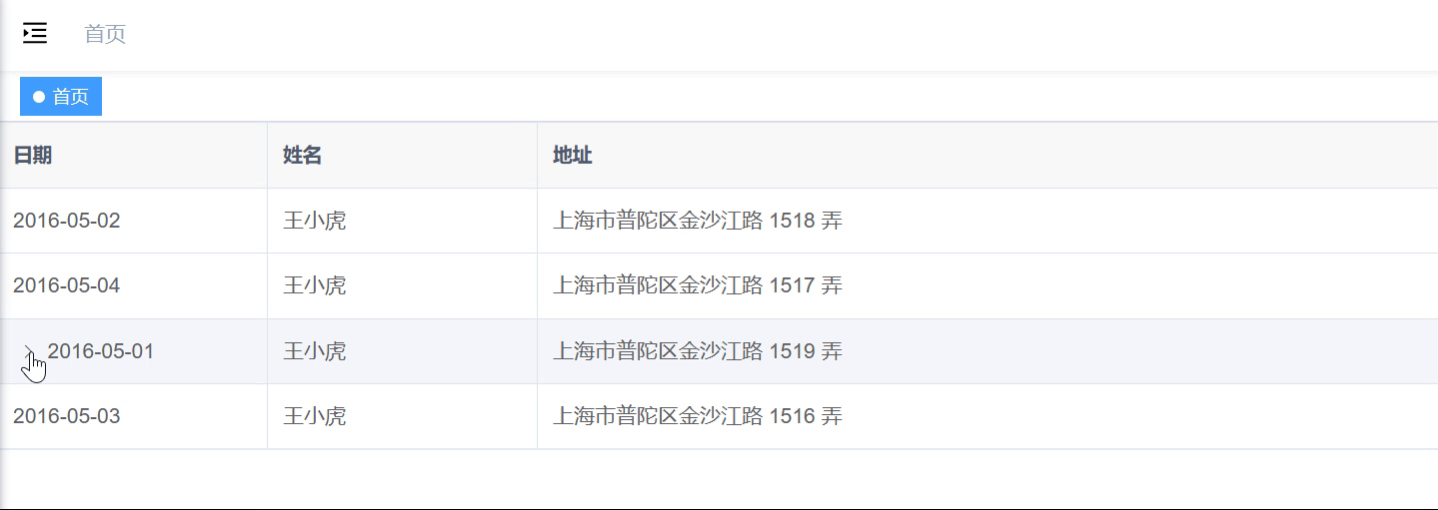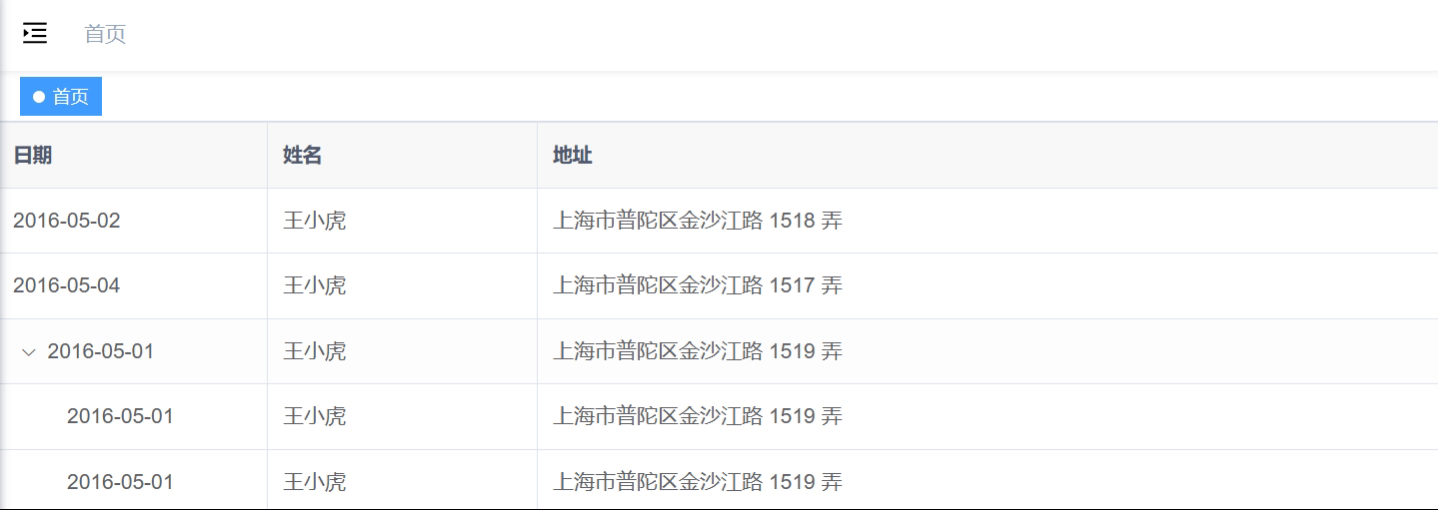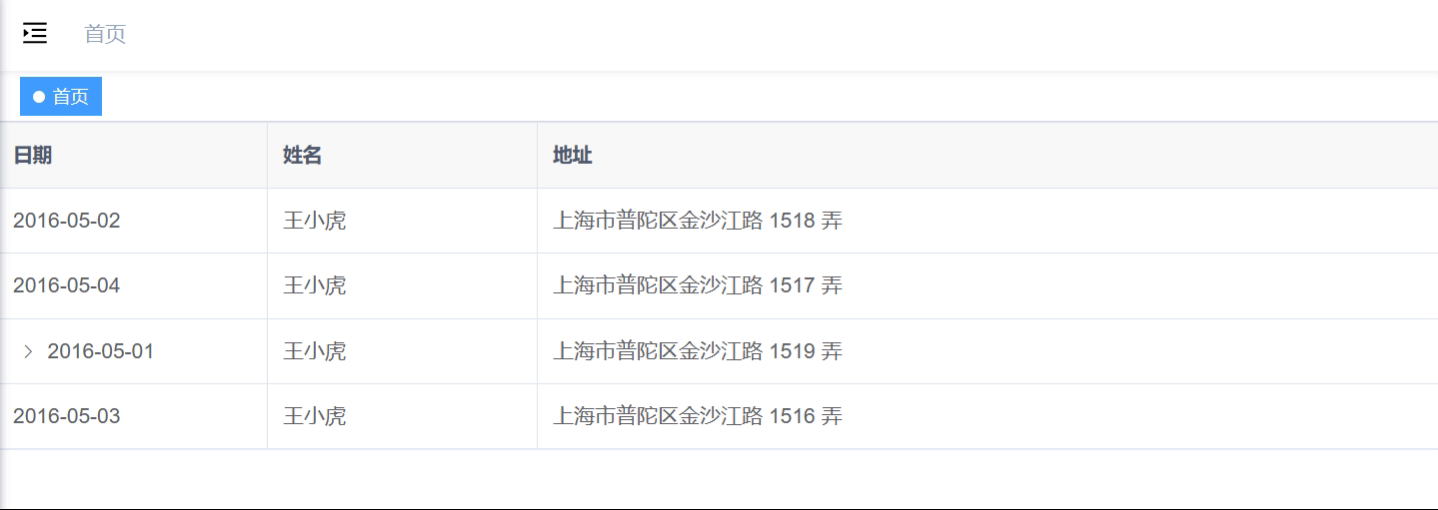
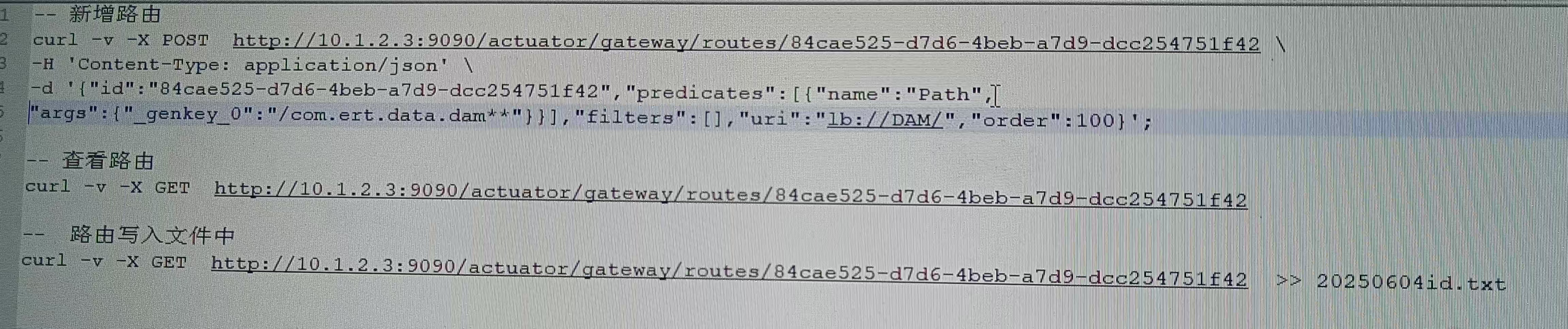
网络爬虫作为互联网数据采集的核心技术,在信息检索、舆情分析、数据挖掘等领域具有广泛应用。随着 Web 技术的发展,现代网站 URL 结构日益复杂,包含路径参数、查询参数、锚点等多种组件,且存在相对路径、URL 编码等问题,给爬虫开发带来了挑战。urllib.parse(Python 3.x 中为urllib.parse,Python 2.x 中为urlparse)作为 Python 标准库,提供了 URL 解析、合并、编码等一系列工具,是构建高效爬虫系统的基础组件。
本文通过开发一个完整的学术文献爬取系统,详细分析 urlparse 库在爬虫中的具体应用场景和实现方法,为相关领域的研究和开发提供参考。
1.2 国内外研究现状
国内外学者对网络爬虫技术进行了广泛研究。在 URL 处理方面,主要集中在以下几个方向: