AlexNet模型详解:结构、算法与PyTorch实现
一、AlexNet模型结构
AlexNet是2012年ImageNet竞赛冠军模型,由Alex Krizhevsky等人提出,标志着深度学习在计算机视觉领域的突破。
网络结构(5卷积层 + 3全连接层):
graph LR
A[输入图像 227×227×3] --> B[Conv1]
B --> C[ReLU]
C --> D[MaxPool]
D --> E[Norm1]
E --> F[Conv2]
F --> G[ReLU]
G --> H[MaxPool]
H --> I[Norm2]
I --> J[Conv3]
J --> K[ReLU]
K --> L[Conv4]
L --> M[ReLU]
M --> N[Conv5]
N --> O[ReLU]
O --> P[MaxPool]
P --> Q[FC6]
Q --> R[ReLU]
R --> S[Dropout]
S --> T[FC7]
T --> U[ReLU]
U --> V[Dropout]
V --> W[FC8]
W --> X[Softmax]
各层参数详情:
| 层类型 | 参数配置 | 输出尺寸 | 激活函数 | 特殊操作 |
|---|---|---|---|---|
| 输入层 | - | 227×227×3 | - | - |
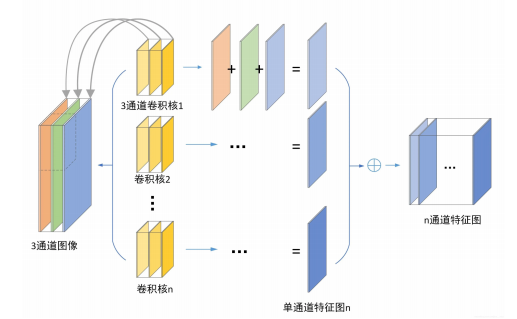
| 卷积层1 | 96@11×11, stride=4, pad=0 | 55×55×96 | ReLU | - |
| 最大池化 | 3×3, stride=2 | 27×27×96 | - | - |
| LRN | - | 27×27×96 | - | 局部响应归一化 |
| 卷积层2 | 256@5×5, stride=1, pad=2 | 27×27×256 | ReLU | - |
| 最大池化 | 3×3, stride=2 | 13×13×256 | - | - |
| LRN | - | 13×13×256 | - | 局部响应归一化 |
| 卷积层3 | 384@3×3, stride=1, pad=1 | 13×13×384 | ReLU | - |
| 卷积层4 | 384@3×3, stride=1, pad=1 | 13×13×384 | ReLU | - |
| 卷积层5 | 256@3×3, stride=1, pad=1 | 13×13×256 | ReLU | - |
| 最大池化 | 3×3, stride=2 | 6×6×256 | - | - |
| 全连接6 | 4096神经元 | 4096 | ReLU | Dropout(0.5) |
| 全连接7 | 4096神经元 | 4096 | ReLU | Dropout(0.5) |
| 全连接8 | 1000神经元 | 1000 | - | - |
| 输出层 | Softmax | 1000 | - | - |
二、核心算法创新
-
ReLU激活函数
- 替代传统的tanh/sigmoid函数
- 优点:计算简单,缓解梯度消失问题
- 公式: f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
-
局部响应归一化(LRN)
- 模拟生物神经系统的侧抑制机制
- 增强大响应值,抑制小响应值
- 公式:
b x , y i = a x , y i / ( k + α ∑ j = max ( 0 , i − n / 2 ) min ( N − 1 , i + n / 2 ) ( a x , y j ) 2 ) β b_{x,y}^i = a_{x,y}^i / \left(k + \alpha \sum_{j=\max(0,i-n/2)}^{\min(N-1,i+n/2)} (a_{x,y}^j)^2 \right)^\beta bx,yi=ax,yi/ k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yj)2 β - 其中: N N N为通道总数, n n n为局部邻域大小, k , α , β k,\alpha,\beta k,α,β为超参数
-
重叠池化(Overlapping Pooling)
- 使用步长(stride)小于池化窗口尺寸
- 3×3池化窗口,stride=2
- 提升特征丰富性,减少过拟合
-
Dropout正则化
- 训练时随机丢弃50%神经元
- 防止过拟合,增强模型泛化能力
- 相当于模型集成效果
-
数据增强
- 随机裁剪、水平翻转、颜色变换
- 大幅增加训练数据多样性
三、PyTorch底层实现分析
完整AlexNet实现代码(PyTorch风格)
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# Conv1
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# Conv2
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# Conv3
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# Conv4
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# Conv5
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
关键实现细节分析
-
卷积层实现
nn.Conv2d参数解析:nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)- 第一层卷积计算示例:
# 输入: (227, 227, 3) # 计算: (227 - 11 + 2*0)/4 + 1 = 55 → 输出: (55, 55, 96)
-
LRN的现代替代
- 原始AlexNet使用LRN
- PyTorch实现省略了LRN层(现代网络通常用BatchNorm替代)
- 如需实现LRN:
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2)
-
自适应平均池化
nn.AdaptiveAvgPool2d((6, 6))确保不同尺寸输入统一为6×6- 替代原始固定尺寸计算,增强灵活性
-
Dropout实现
- 全连接层前添加
nn.Dropout(p=0.5) - 仅训练时激活,测试时自动关闭
- 全连接层前添加
-
参数初始化
- 最佳实践:使用Xavier初始化
for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0)
四、PyTorch调用方法
1. 使用预训练模型
import torchvision.models as models
# 加载预训练模型
alexnet = models.alexnet(weights='AlexNet_Weights.IMAGENET1K_V1')
# 设置为评估模式
alexnet.eval()
2. 自定义训练
from torchvision import datasets, transforms
import torch.optim as optim
# 数据预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=64,
shuffle=True)
# 初始化模型
model = AlexNet(num_classes=10) # 修改为CIFAR-10的10分类
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练循环
for epoch in range(10):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
3. 模型预测示例
from PIL import Image
# 预处理图像
img = Image.open("test_image.jpg")
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
input_tensor = preprocess(img)
input_batch = input_tensor.unsqueeze(0) # 增加batch维度
# 预测
with torch.no_grad():
output = alexnet(input_batch)
# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"Predicted class index: {predicted_idx.item()}")
五、现代改进建议
- LRN替代方案:使用Batch Normalization替代LRN
- 全连接层优化:减少全连接层参数(原始占模型参数90%+)
- 小尺寸适配:对于小尺寸图像(如CIFAR),修改第一层:
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) # 替代11×11卷积 - 学习率调整:使用学习率衰减策略(如StepLR)
- 正则化增强:添加权重衰减(L2正则化)
AlexNet作为深度学习里程碑模型,其设计思想(ReLU、Dropout、数据增强等)深刻影响了后续CNN架构发展。虽然现代网络性能已超越AlexNet,但其核心创新仍是深度学习课程的重要学习内容。