------B站《刘二大人》
1.Softmax Layer
- 在多分类问题中,输出的是每类的概率:
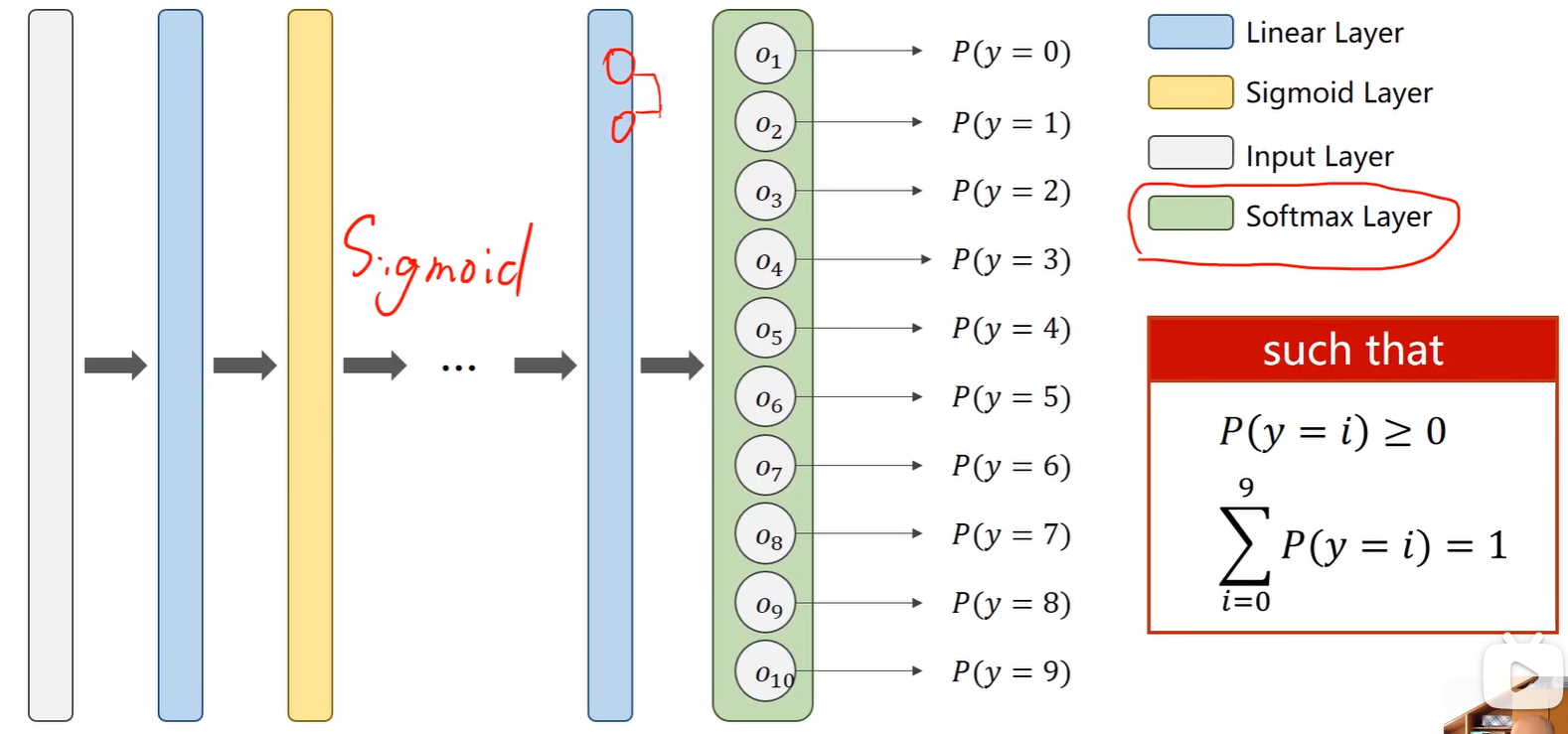
- 计算公式:保证了每类概率大于 0 ,又由保证了概率之和为 1;
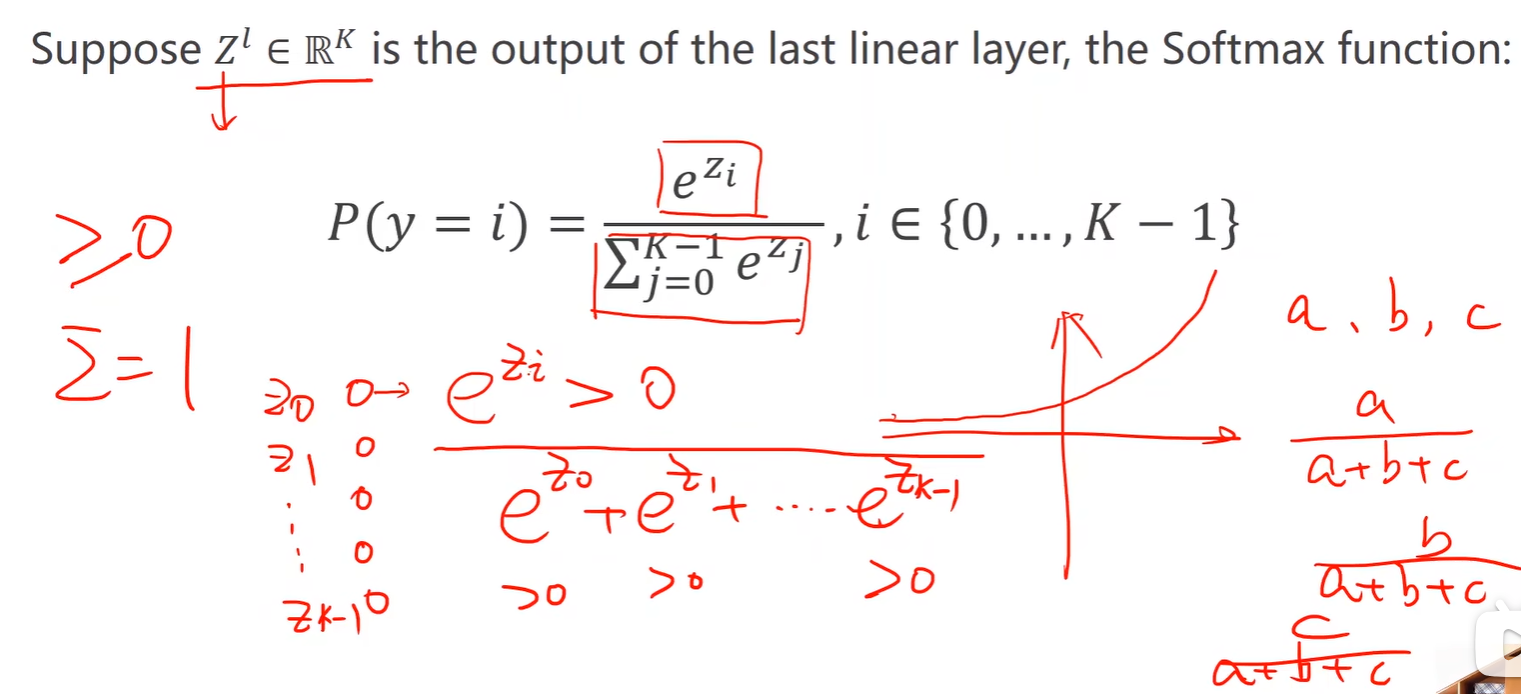
-
举例如下:
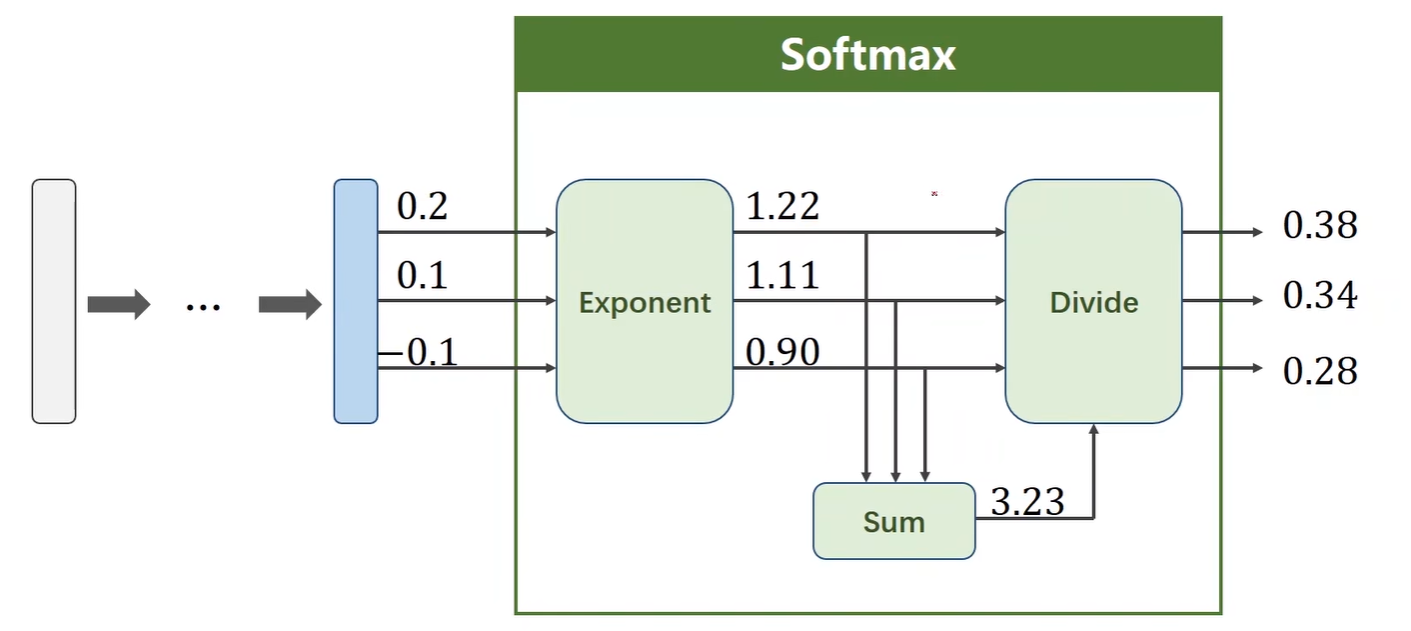
2.Cross Entropy
- 计算损失:
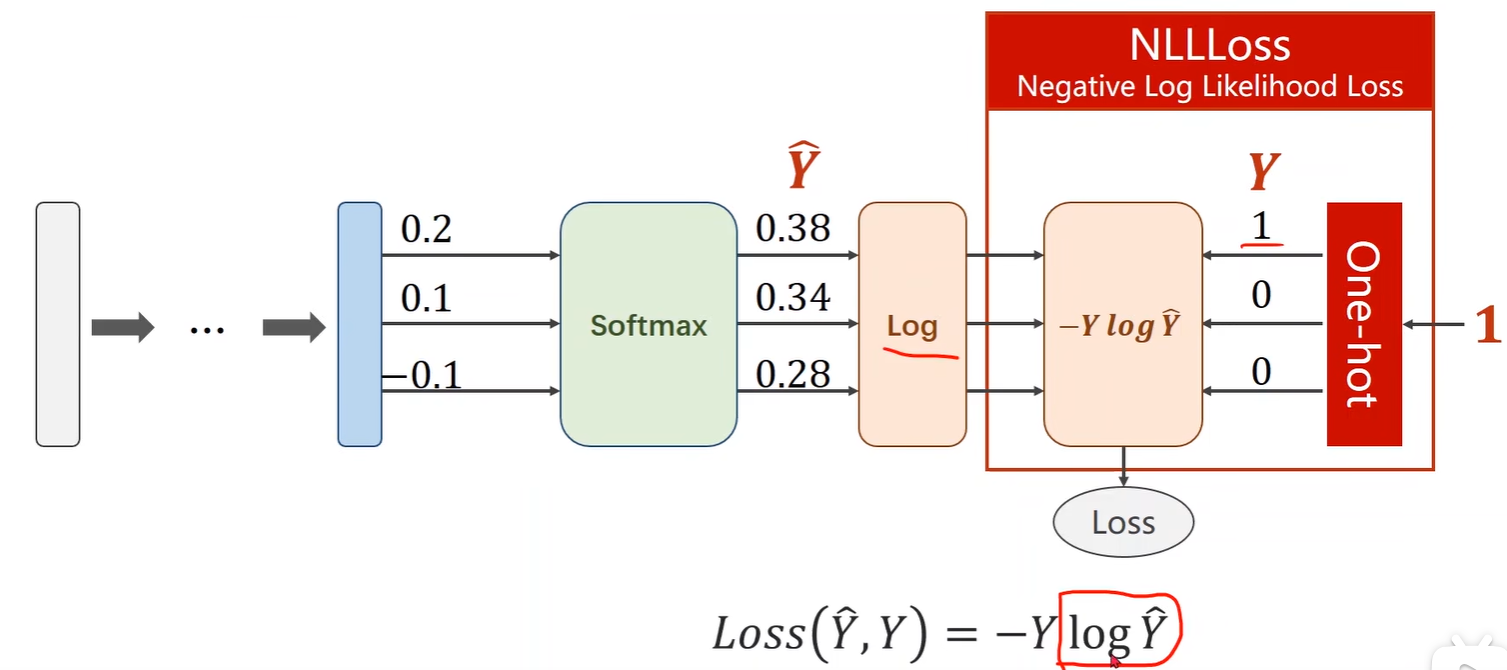
y = np.array([1, 0, 0]):是目标标签的 one-hot 编码。假设有 3 个类别,这里表示正确的类别是第一个类别;
import numpy as np
y = np.array([1, 0, 0])
z = np.array([0.2, 0.1, -0.1])
y_pred = np.exp(z) / np.exp(z).sum()
loss = (-y * np.log(y_pred)).sum()
print(loss) # 0.9729189131256584- 交叉熵损失函数:
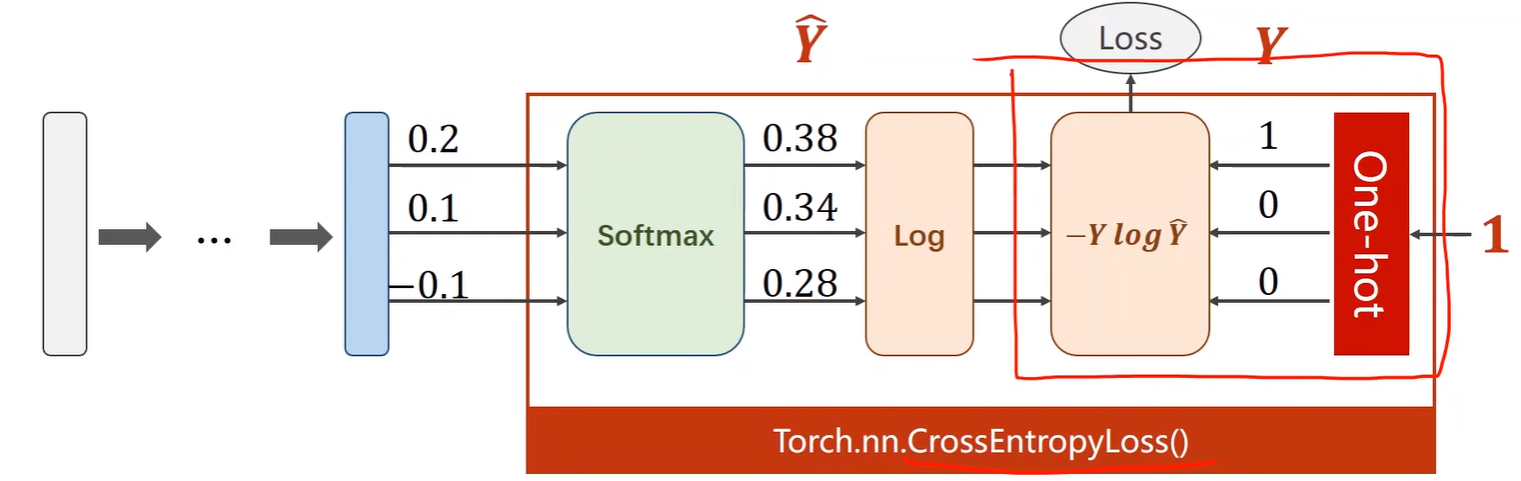
- y 是一个长度为 1 的长整型张量,是标签类别的 索引,
[0]表示正确的类别是类别 0;
import torch
y = torch.LongTensor([0])
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss) # tensor(0.9729)- Mini - Batch
import torch
criterion = torch.nn.CrossEntropyLoss()
Y = torch.LongTensor([2, 0, 1])
Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.1]])
Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3],
[0.2, 0.3, 0.5],
[0.2, 0.2, 0.5]])
loss1 = criterion(Y_pred1, Y) # Batch Loss1 = tensor(0.4966)
loss2 = criterion(Y_pred2, Y) # Batch Loss2 = tensor(1.2389)
print('Batch Loss1 = ', loss1.data, '\nBatch Loss2 = ', loss2.data)3.MNIST
- 导包
import torch
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim- 准备数据集
ToTensor():将图片转换为PyTorch的张量。Normalize(mean, std):使用指定的均值和标准差对图片进行标准化。

batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST('data/MNIST/', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = datasets.MNIST('data/MNIST/', train=False, transform=transform, download=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)- 构造模型
- 输入层:784个神经元(因为每张图片是28x28,展平后变成784维)。
- 隐藏层:4个全连接层,神经元数量分别为512、256、128和64。
- 输出层:10个神经元,分别对应数字0到9。
- 最后一层不做激活,因为后面调用 torch.nn.CrossEntropyLoss。
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(784, 512)
self.linear2 = torch.nn.Linear(512, 256)
self.linear3 = torch.nn.Linear(256, 128)
self.linear4 = torch.nn.Linear(128, 64)
self.linear5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.relu(self.linear3(x))
x = F.relu(self.linear4(x))
x = self.linear5(x) # 不用激活函数,因为 torch.nn.CrossEntropyLoss = softmax + nllloss
return x
model = Net()- 损失与优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)- 训练与测试
- torch.max:返回最大值和对应的下标。
- dim=1,说明是在行的维度。 0是列,1是行。
# training
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
# test
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' %(100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
if epoch % 10 == 0:
test()