目录
前提条件
背景
概念及适用场景
UDF(User-Defined Function)
概念
适用场景
UDAF(User-Defined Aggregate Function)
概念
适用场景
UDTF(User-Defined Table-Generating Function)
概念
适用场景
案例
UDF案例
UDTF案例
UDAF案例
前提条件
- 安装好Hive,可参考:openEuler24.03 LTS下安装Hive3
- 具备Java开发环境:JDK8、Maven3、IDEA
背景
Hive 作为大数据领域常用的数据仓库工具,提供了丰富的内置函数,但在实际业务场景中,内置函数往往无法满足复杂的计算需求。这时,Hive 的自定义函数就显得尤为重要。Hive 支持三种类型的自定义函数:UDF、UDAF 和 UDTF,本文分别介绍它们的概念和适用场景,并给出典型案例。
概念及适用场景
UDF(User-Defined Function)
概念
UDF 是最基本的自定义函数类型,用于实现 "单行进,单行出" 的处理逻辑,即对每行数据中的一个或多个输入值进行计算,返回一个结果值。
适用场景
- 字符串处理(如格式转换、编码转换)
- 数学计算(如自定义计算公式)
- 日期处理(如自定义日期格式解析)
UDAF(User-Defined Aggregate Function)
概念
UDAF 即用户定义的聚合函数,用于实现 "多行进,一行出" 的处理逻辑,将一组数据经过计算后返回一个汇总结果,类似于 SQL 中的 SUM、COUNT 等内置聚合函数。
适用场景
- 自定义统计指标(如计算中位数、众数)
- 复杂数据聚合(如分组拼接字符串)
- 多阶段聚合计算
UDTF(User-Defined Table-Generating Function)
概念
UDTF 是用户定义的表生成函数,实现 "单行进,多行出" 的处理逻辑,将一行数据扩展为多行或多列数据。
适用场景
- 字符串拆分(如将逗号分隔的字符串拆分为多行)
- 数组或集合展开(如将 JSON 数组展开为多行记录)
- 复杂数据结构解析(如解析嵌套 JSON)
案例
UDF案例
需求:
自定义一个UDF实现计算给定基本数据类型的长度,效果如下:
hive(default)> select my_len("abcd");
41)使用IDEA创建一个Maven工程Hive,工程名称例如:udf
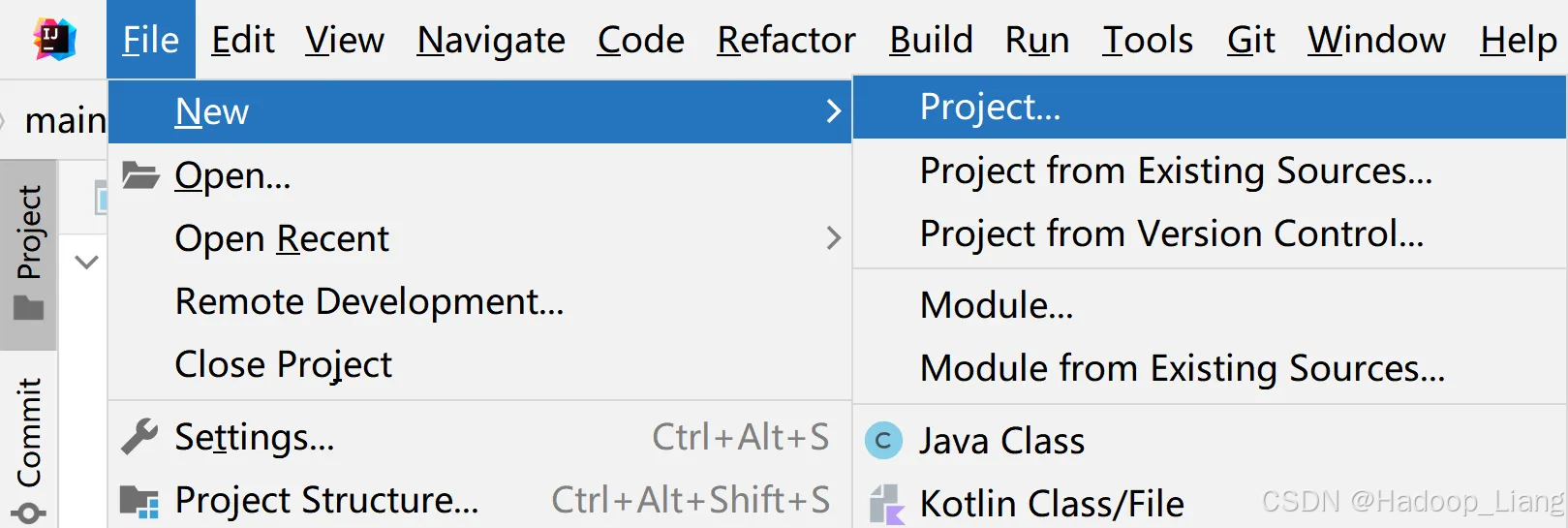
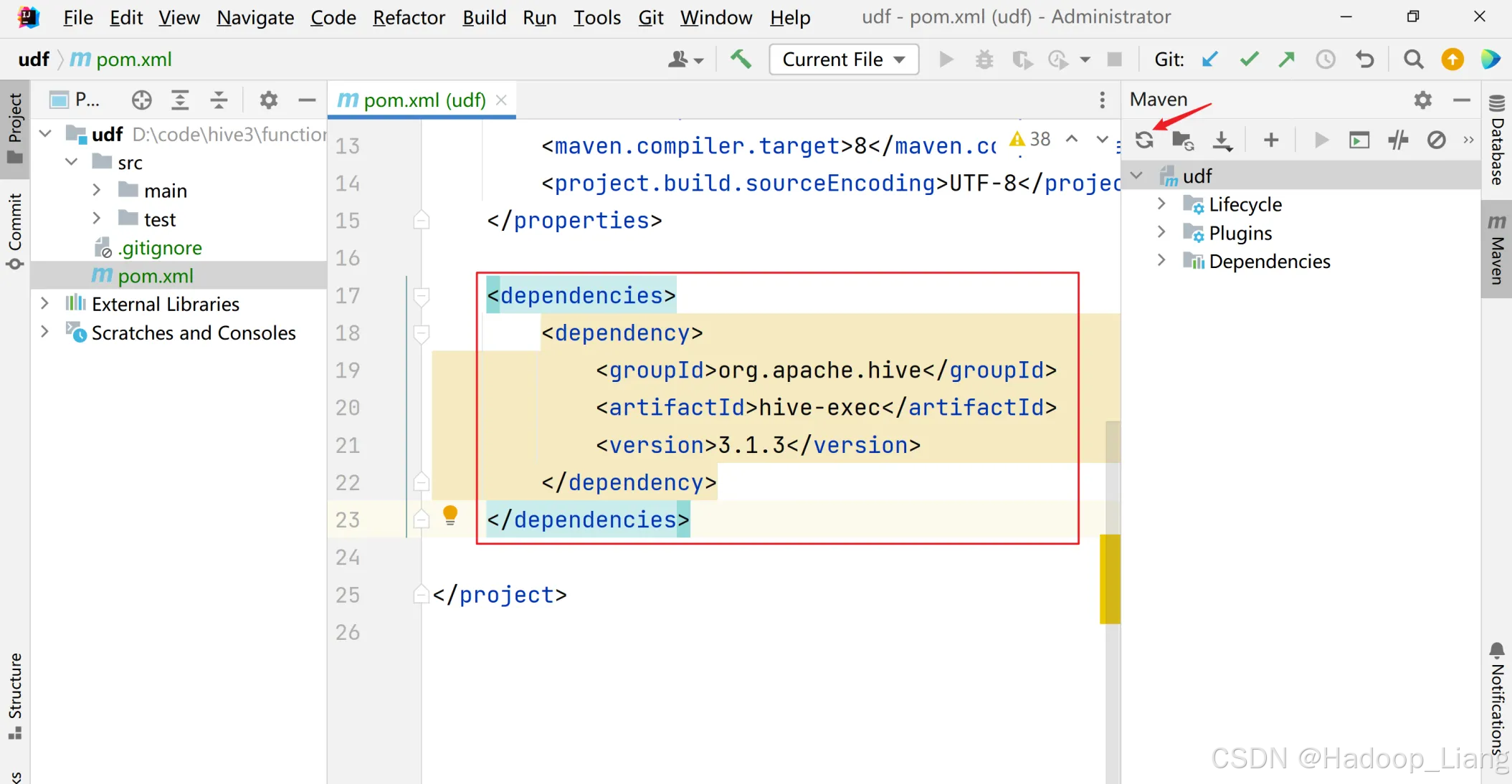
2)添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>添加依赖后,刷新依赖,如下
3)创建包、创建类
创建包:在src/main/java下创建org.exapmle.hive.udf包
创建类:MyUDF.java
package org.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* 我们需计算一个要给定基本数据类型的长度
*/
public class MyUDF extends GenericUDF {
/**
* 判断传进来的参数的类型和长度
* 约定返回的数据类型
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length !=1) {
throw new UDFArgumentLengthException("please give me only one arg");
}
if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(1, "i need primitive type arg");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 解决具体逻辑的
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
Object o = arguments[0].get();
if(o==null){
return 0;
}
return o.toString().length();
}
/**
* 用于获取解释的字符串
*/
@Override
public String getDisplayString(String[] children) {
return "";
}
}4)创建临时函数
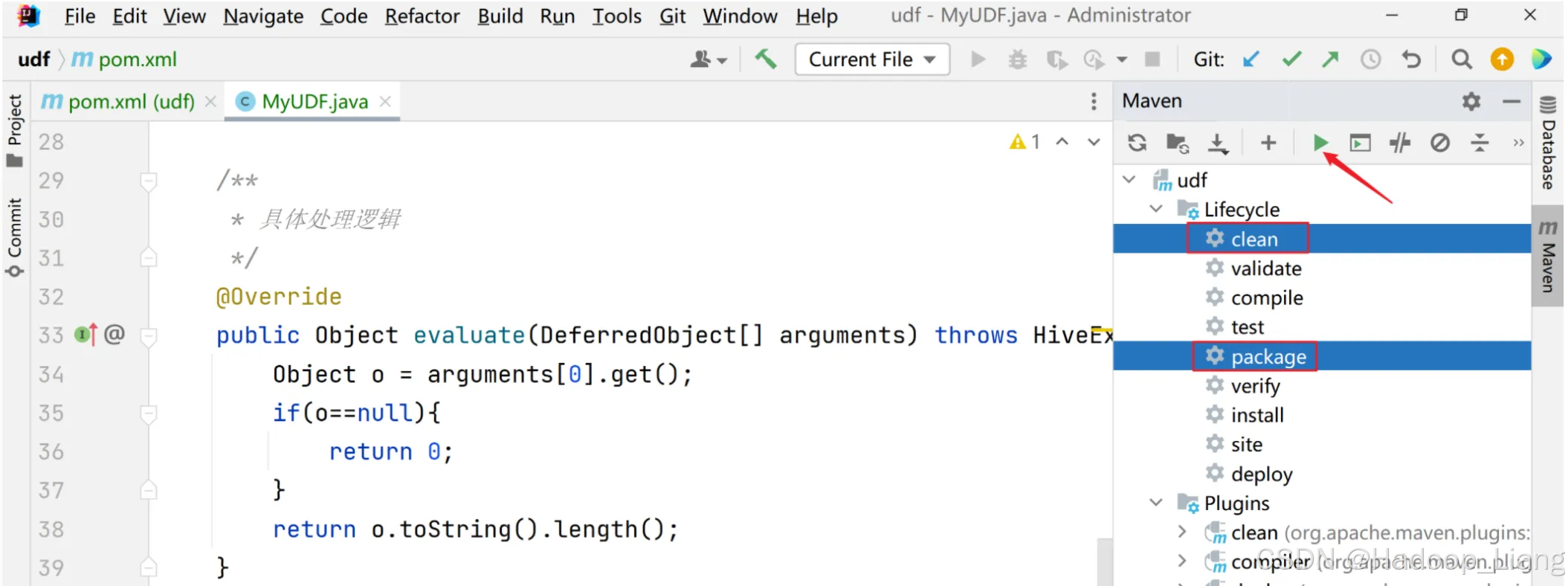
1)打成jar包上传到Linux /opt/module/hive/datas/myudf.jar
点击右侧的Maven,点开Lifecycle,按Ctrl键不放,同时选中clean和package,点击箭头指向的三角形图标运行
看到BUILD SUCCESS说明打包成功,同时看到jar包所在路径,如下
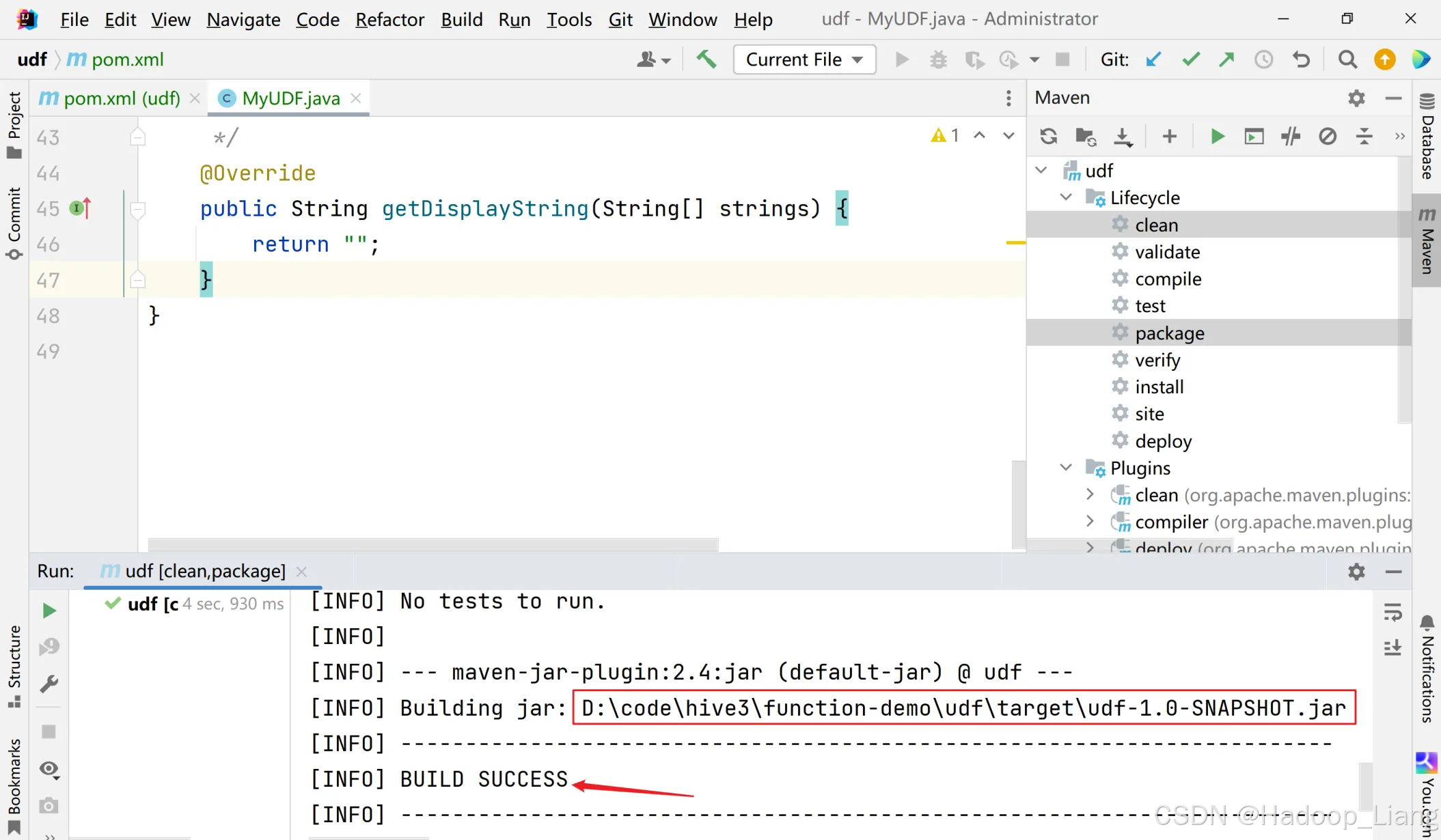
将jar包上传到Linux合适目录下,例如:/home/liang/testjar
[liang@node2 testjar]$ ls
udf-1.0-SNAPSHOT.jar(2)将jar包添加到hive的classpath,临时生效
hive (default)> add jar /home/liang/testjar/udf-1.0-SNAPSHOT.jar;(3)创建临时函数与开发好的java class关联
hive (default)> create temporary function my_len as "org.exapmle.hive.udf.MyUDF";注意:创建临时函数,此时只是在当前会话生效,关闭会话,临时函数被删除。如果需要能在其他会话能看到,且关闭会话后,不删除自定义函数,则需要创建永久函数。
(4)查询函数
hive (default)> show functions;
...
months_between
murmur_hash
my_len
named_struct
negative
...
Time taken: 0.024 seconds, Fetched: 291 row(s)看到my_len函数,说明可以使用自定义函数了。
(5)使用自定义的临时函数
hive (default)> select my_len("abcd");结果为
4(6)删除临时函数
使用如下语句或者关闭会话(退出Hive命令行)删除临时函数。
hive (default)> drop temporary function my_len;5)创建永久函数
(1)创建永久函数
把jar包上传到hdfs
[liang@node2 ~]$ hdfs dfs -put /home/liang/testjar/udf-1.0-SNAPSHOT.jar /创建永久函数
hive (default)>
create function my_len2 as "org.exapmle.hive.udf.MyUDF" using jar "hdfs://node2:8020/udf-1.0-SNAPSHOT.jar";操作过程
hive (default)> create function my_len2 as "org.exapmle.hive.udf.MyUDF" using jar "hdfs://node2:8020/udf-1.0-SNAPSHOT.jar";
Added [/tmp/944c050b-e360-48f1-b7b6-93f8fd7e2644_resources/udf-1.0-SNAPSHOT.jar] to class path
Added resources: [hdfs://node2:8020/udf-1.0-SNAPSHOT.jar]
OK
Time taken: 0.212 seconds查看函数
hive (default)> show functions;
...
dayofweek
decode
default.my_len2
degrees
dense_rank
...
Time taken: 0.019 seconds, Fetched: 291 row(s)看到永久函数名为库名.函数名。
注意:永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
退出hive命令行会话,重新进入hive命令行,再次查看函数,还可以看到default.my_len2
hive (default)> show functions;
...
dayofweek
decode
default.my_len2
degrees
dense_rank
...
Time taken: 0.019 seconds, Fetched: 291 row(s)使用永久函数
hive (default)> select my_len2("abcd");结果为
4(3)删除永久函数
hive (default)> drop function my_len2;注意:永久函数使用的时候,在其他库里面使用的话加上,库名.函数名。
UDTF案例
需求:
将字符串按分隔符分割为多行,例如:将a,b,c按照,进行分隔,得到三行
a
b
c代码
package org.exapmle.hive.udtf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableStringObjectInspector;
import org.apache.hadoop.io.Text;
import java.util.Arrays;
import java.util.List;
@Description(
name = "explode_string",
value = "将字符串按分隔符分割为多行",
extended = "SELECT explode_string('a,b,c', ',') FROM table_name;"
)
public class ExplodeWordsUDTF extends GenericUDTF {
private WritableStringObjectInspector inputOI;
private WritableStringObjectInspector separatorOI;
private final Object[] forwardObj = new Object[1];
private final Text outputText = new Text();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 获取输入参数的ObjectInspector
List<? extends StructField> inputFields = argOIs.getAllStructFieldRefs();
// 检查参数数量
if (inputFields.size() != 2) {
throw new UDFArgumentLengthException("explode_string需要两个参数: 字符串和分隔符");
}
// 检查参数类型
ObjectInspector firstOI = inputFields.get(0).getFieldObjectInspector();
ObjectInspector secondOI = inputFields.get(1).getFieldObjectInspector();
if (!(firstOI instanceof WritableStringObjectInspector) || !(secondOI instanceof WritableStringObjectInspector)) {
throw new UDFArgumentLengthException("参数必须是字符串类型");
}
inputOI = (WritableStringObjectInspector) firstOI;
separatorOI = (WritableStringObjectInspector) secondOI;
// 定义输出结构
List<String> fieldNames = Arrays.asList("element");
List<ObjectInspector> fieldOIs = Arrays.asList(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
if (args[0] == null) {
return;
}
Text input = inputOI.getPrimitiveWritableObject(args[0]);
Text sep = separatorOI.getPrimitiveWritableObject(args[1]);
String separator = sep != null ? sep.toString() : ",";
String inputStr = input.toString();
// 处理空字符串
if (inputStr.isEmpty()) {
outputText.set("");
forwardObj[0] = outputText;
forward(forwardObj);
return;
}
// 使用正则表达式分隔字符串
String[] elements = inputStr.split(separator, -1);
for (String element : elements) {
outputText.set(element);
forwardObj[0] = outputText;
forward(forwardObj);
}
}
@Override
public void close() throws HiveException {
}
}
打jar包,上传到Linux
注册与使用
hive (default)> ADD JAR /home/liang/testjar/udf-1.0-SNAPSHOT.jar;
Added [/home/liang/testjar/udf-1.0-SNAPSHOT.jar] to class path
Added resources: [/home/liang/testjar/udf-1.0-SNAPSHOT.jar]
hive (default)> CREATE TEMPORARY FUNCTION explode_string AS 'org.exapmle.hive.udtf.ExplodeStringUDTF';
OK
Time taken: 0.362 seconds
hive (default)> SELECT explode_string('a,b,c', ',');
OK
element
a
b
c
Time taken: 2.844 seconds, Fetched: 3 row(s)
hive (default)> SELECT explode_string('hello,world', ',');
OK
element
hello
world
Time taken: 0.209 seconds, Fetched: 2 row(s)UDAF案例
需求:
计算加权平均值,加权平均数=(Σ(数值×权重))/Σ权重
例如:
计算学生综合成绩时,若数学(学分4分,成绩90)和语文(学分3分,成绩80),其中数值为成绩,权重为学分,则加权平均成绩为 (4×90+3×80)/(4+3)≈85.71(4×90+3×80)/(4+3)≈85.71分。
代码
package org.exapmle.hive.udaf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Description(
name = "weighted_avg",
value = "计算加权平均值",
extended = "SELECT weighted_avg(score, credit) FROM grades GROUP BY student_id;"
)
public class WeightedAverageUDAF extends UDAF {
public static class WeightedAverageEvaluator implements UDAFEvaluator {
// 存储中间结果
private double sumWeightedValues;
private double sumWeights;
private boolean empty;
@Override
public void init() {
sumWeightedValues = 0;
sumWeights = 0;
empty = true;
}
// 处理输入行
public boolean iterate(DoubleWritable value, DoubleWritable weight) {
if (value == null || weight == null || weight.get() <= 0) {
return true;
}
sumWeightedValues += value.get() * weight.get();
sumWeights += weight.get();
empty = false;
return true;
}
// 存储部分结果的类
public static class PartialResult implements Writable {
double sumWeightedValues;
double sumWeights;
@Override
public void write(DataOutput out) throws IOException {
out.writeDouble(sumWeightedValues);
out.writeDouble(sumWeights);
}
@Override
public void readFields(DataInput in) throws IOException {
sumWeightedValues = in.readDouble();
sumWeights = in.readDouble();
}
}
// 返回部分结果
public PartialResult terminatePartial() {
if (empty) {
return null;
}
PartialResult result = new PartialResult();
result.sumWeightedValues = sumWeightedValues;
result.sumWeights = sumWeights;
return result;
}
// 合并部分结果
public boolean merge(PartialResult other) {
if (other == null) {
return true;
}
sumWeightedValues += other.sumWeightedValues;
sumWeights += other.sumWeights;
empty = false;
return true;
}
// 返回最终结果
public DoubleWritable terminate() {
if (empty || sumWeights <= 0) {
return null;
}
return new DoubleWritable(sumWeightedValues / sumWeights);
}
}
}打jar包,上传到Linux
注册
hive (default)> ADD JAR /home/liang/testjar/udf-1.0-SNAPSHOT.jar;
Added [/home/liang/testjar/udf-1.0-SNAPSHOT.jar] to class path
Added resources: [/home/liang/testjar/udf-1.0-SNAPSHOT.jar]
hive (default)> CREATE TEMPORARY FUNCTION weighted_avg AS 'org.exapmle.hive.udaf.WeightedAverageUDAF';
OK
Time taken: 0.043 seconds使用
WITH grades AS (
SELECT 1 AS student_id, 'Math' AS course, 90 AS score, 4 AS credit
UNION ALL
SELECT 1, 'English', 85, 3
UNION ALL
SELECT 2, 'Math', 88, 4
UNION ALL
SELECT 2, 'English', 92, 3
)
SELECT
student_id,
weighted_avg(score, credit) AS gpa
FROM grades
GROUP BY student_id;操作过程
hive (default)> WITH grades AS (
> SELECT 1 AS student_id, 'Math' AS course, 90 AS score, 4 AS credit
> UNION ALL
> SELECT 1, 'English', 85, 3
> UNION ALL
> SELECT 2, 'Math', 88, 4
> UNION ALL
> SELECT 2, 'English', 92, 3
> )
> SELECT
> student_id,
> weighted_avg(score, credit) AS gpa
> FROM grades
> GROUP BY student_id;
Query ID = liang_20250521165046_6335eb21-2d92-4ae1-b30c-511bcb9a98ab
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1747808931389_0001, Tracking URL = http://node3:8088/proxy/application_1747808931389_0001/
Kill Command = /opt/module/hadoop-3.3.4/bin/mapred job -kill job_1747808931389_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2025-05-21 16:51:04,388 Stage-1 map = 0%, reduce = 0%
2025-05-21 16:51:12,756 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.89 sec
2025-05-21 16:51:28,486 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.36 sec
MapReduce Total cumulative CPU time: 11 seconds 360 msec
Ended Job = job_1747808931389_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 11.36 sec HDFS Read: 12918 HDFS Write: 151 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 360 msec
OK
student_id gpa
1 87.85714285714286
2 89.71428571428571
Time taken: 43.272 seconds, Fetched: 2 row(s)更多Hive自定义函数用法,请参考:Hive官方文档
完成!enjoy it!