verl 是现在非常火的 rl 框架,而且已经支持了多个 rl 算法(ppo、grpo 等等)。
过去对 rl 的理解很粗浅(只知道有好多个角色,有的更新权重,有的不更新),也曾硬着头皮看了一些论文和知乎,依然有很多细节不理解,现在准备跟着 verl 的代码梳理一遍两个著名的 rl 算法,毕竟代码不会隐藏任何细节!
虽然 GRPO 算法是基于 PPO 算法改进来的,但是毕竟更简单,所以我先从 GRPO 的流程开始学习,然后再看 PPO。
GRPO 论文中的展示的总体流程:
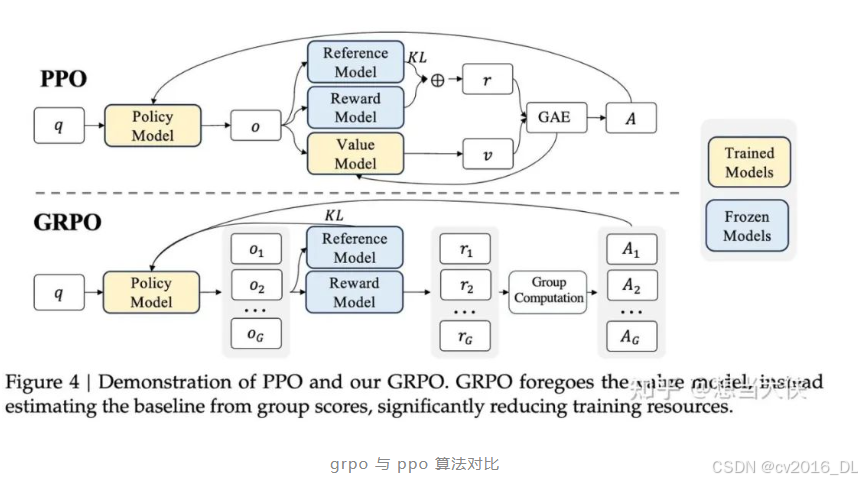
论文中这张图主要展示了 GRPO 和 PPO 的区别,隐藏了其他的细节。
图中只能注意到以下几个关键点:
-
没有 Value Model 和输出 v(value)
-
同一个 q 得出了一组的 o(从 1 到 G)
-
计算 A(Advantage) 的算法从 GAE 变成了 Group Computation
-
KL 散度计算不作用于 Reward Model,而是直接作用于 Policy Model
其他细节看不懂,结合论文也依然比较抽象,因为我完全没有 RL 的知识基础,下文中我们结合代码会再一次尝试理解。
下面是我根据 verl 代码自己 DIY 的流程图(帮助理解):
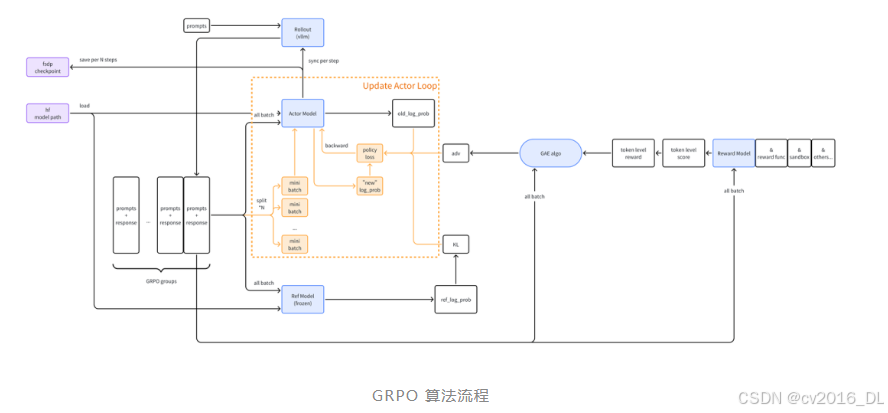
01 第一步:Rollout
第一步是 rollout,rollout 是一个强化学习专用词汇,指的是从一个特定的状态按照某个策略进行一些列动作和状态转移。
在 LLM 语境下,“某个策略”就是 actor model 的初始状态,“进行一些列动作”指的就是推理,即输入 prompt 输出 response 的过程。
verl/trainer/ppo/ray_trainer.py:
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)其背后的实现一般就是是 vllm 或 sglang 这些常见推理框架的离线推理功能,这部分功能相对独立我们先不展开。
权重同步
一个值得注意的细节是代码里面的 rollout_sharding_manager 实现,它负责每一个大 step 结束后把刚刚训练好的 actor model 参数更新到 vllm 或 sglang。
这样下一个大 step 的 rollout 采用的就是最新的模型权重(最新的策略)了。
这是每一个大 step 里面真正要做的第一件事,在真正执行 rollout 之前。
verl/workers/fsdp_workers.py:
class ActorRolloutRefWorker(Worker):
# ...
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(self, prompts: DataProto):
# ...
with self.rollout_sharding_manager:
# ...
prompts = self.rollout_sharding_manager.preprocess_data(prompts)
output = self.rollout.generate_sequences(prompts=prompts)
output = self.rollout_sharding_manager.postprocess_data(output)rollout_sharding_manager 的基类是 BaseShardingManager。
verl/workers/sharding_manager/base.py:
class BaseShardingManager:
def __enter__(self):
pass
def __exit__(self, exc_type, exc_value, traceback):
pass
def preprocess_data(self, data: DataProto) -> DataProto:
return data
def postprocess_data(self, data: DataProto) -> DataProto:
return data BaseShardingManager 的派生类在各自的 __enter__ 方法中实现了把 Actor Model 的权重 Sync 到 Rollout 实例的逻辑,以保证被 with self.rollout_sharding_manager 包裹的预处理和推理逻辑都是用的最新 Actor Model 权重。
推理 N 次
此外,GRPO 算法要求对每一个 prompt 都生成多个 response,后续才能根据组间对比得出相对于平均的优势(Advantage)。
verl/trainer/config/ppo_trainer.yaml:
actor_rollout_ref:
rollout:
# number of responses (i.e. num sample times)
n: 1 # > 1 for grpo 在 _build_rollout 的时候 actor_rollout_ref.rollout.n 被传给了 vLLMRollout 或其他的 Rollout 实现中,从而推理出 n 组 response。
verl/workers/fsdp_workers.py:
class ActorRolloutRefWorker(Worker):
def _build_rollout(self, trust_remote_code=False):
# ...
elif rollout_name == "vllm":
# ...
if vllm_mode == "customized":
rollout = vLLMRollout(
actor_module=self.actor_module_fsdp, config=self.config.rollout,
tokenizer=self.tokenizer,
model_hf_config=self.actor_model_config,
)02 第二步:计算 log prob
log 是 logit,prob 是 probability,合起来就是对数概率,举一个简单的例子来说明什么是 log prob:
词表仅有 5 个词:
<pad> (ID 0)
你好 (ID 1)
世界 (ID 2)
! (ID 3)
吗 (ID 4)
prompt:你好
prompt tokens: [1]
response:世界!
response tokens: [2,3]
模型前向传播得到完整的 logits 张量:
[ [-1.0, 0.5, 2.0, -0.5, -1.5], // 表示 “你好” 后接 “世界” 概率最高,数值为 2.0 [-2.0, -1.0, 0.1, 3.0, 0.2] // 表示 “你好世界” 后接 “!” 概率最高,数值为 3.0]
对每个 logit 计算 softmax 得到:
[ [-3.65, -2.15, -0.64, -3.15, -4.08], [-4.34, -3.32, -2.20, -0.20, -2.10]]
提取实际 response 对应的数值:得到 log_probs:
[-0.64, -0.20]总结下来:
-
首先计算 prompt + response(来自 rollout)的完整 logits,即每一个 token 的概率分布
-
截取 response 部分的 logits
-
对每一个 logits 计算 log_sofmax(先 softmax,然后取对数),取出最终预测的 token 对应的 log_sofmax
-
最终输出 old_log_probs, size = [batchsize, seq_len]
此处你可能会有一个疑惑:在上一步 Rollout 的时候我们不是已经进行过完整 batch 的推理了么?
为什么现在还要重复进行一次 forward 来计算 log_prob,而不是在 generate 的过程中就把 log_prob 保存下来?
答:因为 generate_sequences 阶段为了高效推理,不会保存每一个 token 的 log_prob,相反只关注整个序列的 log_prob。因此需要重新算一遍。
答:另外,vllm 官方 Q&A 中提到了 vllm 框架并不保证 log_probs 的稳定性。因为 pytorch 的 numerical instability 与 vllm 的并发批处理策略导致每一个 token 的 logits/log_probs 结果会略有不同,假如某一个 token 位采样了不同 token id,那么这个误差在后续还会被继续累加。我们在训练过程需要保证 log_probs 的稳定性,因此需要根据已经确定的 token id(即 response)再次 forward 一遍。
old log prob
verl/workers/fsdp_workers.py:
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)指 Actor Model 对整个 batch 的数据(prompt + response)进行 forward 得到的 log_prob
此处的 “old” 是相对于后续的 actor update 阶段,因为现在 actor model 还没有更新,所以依然采用的是旧策略 (ps:当前 step 的“旧策略”也是上一个大 step 的“新策略”)
ref log prob
verl/trainer/ppo/ray_trainer.py:
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)指 Ref Model 对整个 batch 的数据(prompt + response)进行 forward 得到的 log_prob。
通常 Ref Model 就是整个强化学习开始之前 Actor Model 最初的模样,换句话说第一个大 step 开始的时候 Actor Model == Ref Model,且 old_log_prob == ref_log_prob。
Ref Model 的作用是在后续计算 policy loss 之前,计算 KL 散度并作用于 policy loss,目的是让 actor model 不要和最初的 ref model 相差太远。
03第三步:advantage
advantage 是对一个策略的好坏最直接的评价,其背后就是 Reward Model,甚至也许不是一个 Model,而是一个粗暴的 function,甚至一个 sandbox 把 prompt+response 执行后得出的结果。
在 verl 中允许使用上述多种 Reward 方案中的一种或多种,并把得出的 score 做合。
verl/trainer/ppo/ray_trainer.py:
# compute reward model score
if self.use_rm:
reward_tensor = self.rm_wg.compute_rm_score(batch)
batch = batch.union(reward_tensor)
if self.config.reward_model.launch_reward_fn_async:
future_reward = compute_reward_async.remote(batch, self.config, self.tokenizer)
else:
reward_tensor, reward_extra_infos_dict = compute_reward(batch, self.reward_fn)然后用这个 score 计算最终的 advantage。
verl/trainer/ppo/ray_trainer.py:
# compute advantages, executed on the driver process
norm_adv_by_std_in_grpo = self.config.algorithm.get( "norm_adv_by_std_in_grpo", True)
# GRPO adv normalization factor
batch = compute_advantage( batch,
adv_estimator=self.config.algorithm.adv_estimator,
gamma=self.config.algorithm.gamma,
lam=self.config.algorithm.lam,
num_repeat=self.config.actor_rollout_ref.rollout.n, norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,)04第四步:actor update(小循环)
在 PPOTrainer 中简单地一行调用,背后可是整个 GRPO 算法中最关键的步骤:
actor_output = self.actor_rollout_wg.update_actor(batch) 在这里,会把上面提到的整个 batch 的数据再根据 actor_rollout_ref.actor.ppo_mini_batch_size 配置的值拆分成很多个 mini batch。
然后对每一个 mini batch 数据进行一轮 forward + backward + optimize step,也就是小 step。
new log prob
每一个小 step 中首先会对 mini batch 的数据计算(new)log_prob,第一个小 step 得到的值还是和 old_log_prob 一模一样的。
pg_loss
然后通过输入所有 Group 的 Advantage 以新旧策略的概率比例(old_log_prob 和 log_prob),得出 pg_loss(Policy Gradient),这是最终用于 backward 的 policy loss 的基础部分。
再次描述一下 pg_loss 的意义,即衡量当前策略(log_prob)相比于旧策略(old_log_prob),在当前优势函数(advantage)指导下的改进程度。
verl/workers/actor/dp_actor.py:
pg_loss, pg_clipfrac, ppo_kl, pg_clipfrac_lower = compute_policy_loss( old_log_prob=old_log_prob,
log_prob=log_prob,
advantages=advantages,
response_mask=response_mask,
cliprange=clip_ratio,
cliprange_low=clip_ratio_low,
cliprange_high=clip_ratio_high,
clip_ratio_c=clip_ratio_c,
loss_agg_mode=loss_agg_mode,)entropy loss
entropy 指策略分布的熵 (Entropy):策略对选择下一个动作(在这里是下一个 token)的不确定性程度。
熵越高,表示策略输出的概率分布越均匀,选择各个动作的概率越接近,策略的探索性越强;熵越低,表示策略越倾向于选择少数几个高概率的动作,确定性越强。
entropy_loss 指 entropy 的 平均值,是一个标量,表示探索性高低。
verl/workers/actor/dp_actor.py:
if entropy_coeff != 0:
entropy_loss = agg_loss(loss_mat=entropy, loss_mask=response_mask, loss_agg_mode=loss_agg_mode)
# compute policy loss
policy_loss = pg_loss - entropy_loss * entropy_coeff
else:
policy_loss = pg_loss计算 KL 散度
这里用到了前面 Ref Model 推出的 ref_log_prob,用这个来计算 KL 并作用于最后的 policy_loss,保证模型距离 Ref Model(初始的模型)偏差不会太大。
verl/workers/actor/dp_actor.py:
if self.config.use_kl_loss:
ref_log_prob = data["ref_log_prob"]
# compute kl loss
kld = kl_penalty(logprob=log_prob, ref_logprob=ref_log_prob, kl_penalty=self.config.kl_loss_type )
kl_loss = agg_loss(loss_mat=kld, loss_mask=response_mask, loss_agg_mode=self.config.loss_agg_mode )
policy_loss = policy_loss + kl_loss * self.config.kl_loss_coef
metrics["actor/kl_loss"] = kl_loss.detach().item()
metrics["actor/kl_coef"] = self.config.kl_loss_coef反向计算
verl/workers/actor/dp_actor.py:
loss.backward()持续循环小 step,直到遍历完所有的 mini batch,Actor Model 就完成了本轮的训练,会在下一个大 step 前把权重 sync 到 Rollout实例当中,准备处理下一个大 batch 数据。