Fullstack 面试复习笔记:Java 基础语法 / 核心特性体系化总结
上一篇笔记:Fullstack 面试复习笔记:操作系统 / 网络 / HTTP / 设计模式梳理
目前上来说,这个系列的笔记本质上来说,是对不理解的知识点进行的一个梳理,而不是是更细节的八股文备战。可以基于这个蓝图做延伸,去找对应的八股文,但是为了方便更快地过一遍面试准备——我基本上做好一周内要ready的打算,就不包含八股文了……
基础结构 & 语法机制
基础类型(primitive type)
这里简单的回顾一下primitive type的基础,java中有的primitive type有:
| 类型 | 字节数 | 默认值 | 范围 or 特性 |
|---|---|---|---|
| byte | 1 | 0 | -128 ~ 127 |
| short | 2 | 0 | -32,768 ~ 32,767 |
| int | 4 | 0 | -2^31 ~ 2^31-1(默认整数类型) |
| long | 8 | 0L | -2^63 ~ 2^63-1(必须加 L 后缀) |
| float | 4 | 0.0f | 单精度(精度约为 7 位) |
| double | 8 | 0.0d | 双精度(默认浮点数,约 15 位精度) |
| char | 2 | ‘\u0000’ | Unicode 字符编码(不是 ASCII) |
| boolean | 1 | false | true / false |
- 自动装箱 & 拆箱(autuboxing/unboxing)
-
Java会对
-128到127这个区间的数字进行缓存,如:Integer a = 127; Integer b = 127; System.out.println(a == b); // true Integer a = 128; Integer b = 128; System.out.println(a == b); // false除了
byte,boolean和float/double外的其他wrapper clas都适用 -
装箱对象的比较必须用
.equals(),不要用==
-
常用集合
-
HashMapvsHashtablevsConcurrentHashMap(线程安全机制)HashMap:非线程安全,性能好,适合单线程或通过Collections.synchronizedMap、ConcurrentHashMap实现安全Hashtable:线程安全,但通过方法加锁(synchronized),效率低,已过时ConcurrentHashMap: 线程安全, 最新实现,代替Hashtable
-
ArrayListvsLinkedList重点放在操作复杂度(时间复杂度)上
-
HashSet,TreeSet,TreeMap特性 HashSetTreeSetTreeMap类型 Set(不重复元素) Set(有序、不重复元素) Map(有序键值对) 底层结构 HashMapTreeMap(基于红黑树)红黑树(Red-Black Tree) 是否排序 ❌ 否(无序) ✅ 是(元素有序) ✅ 是(key 有序) 允许 null✅ 允许一个 null 元素 ✅ 默认支持一个 null 元素(但不可比较) ✅ key 允许 null(但排序会报错) 插入性能 🚀 快(O(1) 平均) 🐢 较慢(O(log n),因排序) 🐢 较慢(O(log n),因排序) 是否线程安全 ❌ 否 ❌ 否 ❌ 否 -
ComparablevsComparator方式 用法场景 说明 Comparable实现类内部排序(默认规则) 实现 compareTo()方法,修改类本身,例如:User implements Comparable<User>Comparator外部传入排序规则(灵活定制) 传入 TreeSet或TreeMap构造器,可避免修改类 -
BigDecimalBigDecimal bd = new BigDecimal("123.45"); // intVal = 12345 // scale = 2 // => intVal × 10^(-scale) = 123.45
对象机制
-
equals/hashCode 原则
若两个对象通过
equals()判断为相等,则它们的hashCode()也必须相等;否则会破坏集合类(如HashMap、HashSet)的查找一致性 -
Java 内存结构 + 对象引用类型(强/软/弱/虚)
类型 是否参与GC前回收 典型用途 特点说明 强引用 ❌ 不可回收 常规对象引用 默认引用类型,只有失去所有强引用才会GC 软引用 ✅ 内存不足时回收 缓存(如图片) 有可能在OOM前被GC,适合做内存敏感缓存 弱引用 ✅ 下一次GC就回收 ThreadLocal等 生命周期短,不影响GC回收 虚引用 ✅ 随时可回收 跟踪对象回收 无法通过它访问对象,需配合 ReferenceQueue
异常机制
-
checked vs unchecked
Checked 异常是受检异常,编译器要求你显式处理(try-catch 或 throws);而 Unchecked 异常是运行时异常,可以不处理,但最好处理
异常类型 是否强制捕获 继承体系 使用场景 示例 Checked ✅ 是 Exception(但非RuntimeException)受控环境、外部 IO、数据库等 IOException,SQLExceptionUnchecked ❌ 否 RuntimeException及其子类程序逻辑错误、空指针等 NullPointerException,IndexOutOfBoundsException -
try-with-resources
try-with-resources是 Java 7 引入的新语法,用于在try块中自动关闭资源(实现了AutoCloseable接口的对象),避免finally中手动close()的繁琐与遗漏try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) { String line = reader.readLine(); System.out.println(line); } catch (IOException e) { e.printStackTrace(); }
注解机制(Annotation)
-
基本注解:
@Override,@SuppressWarnings -
自定义注解
-
元注解(Retention Policy)
用于修饰注解本身,控制其生命周期、作用范围、能否继承等
元注解 含义(作用) @Retention注解保留到何时(编译时 / 运行时 / 类加载时) @Target注解可以放在哪些位置(类 / 方法 / 字段等) @Documented是否包含在 Javadoc 中 @Inherited是否允许子类继承注解 @Repeatable是否允许注解重复使用(Java 8+) 提供一个案例简单说明一下:
@Retention(RetentionPolicy.RUNTIME) // 注解可以在运行时通过反射读取 @Target(ElementType.METHOD) // 注解只能贴在方法上 public @interface MyCustomAnno { // 自定义注解本体 String value(); } -
常见使用场景:Spring 注解驱动
Java 8+ 核心特性
Lambda 表达式
是 函数式接口 的 实例 语法糖:简化匿名内部类
// comparator
List<String> names = Arrays.asList("Zhang", "Li", "Wang", "Zhao");
names.sort((a, b) -> a.compareTo(b));
names.sort((a, b) -> b.compareTo(a));
// runnable
Runnable task = () -> System.out.println("Hello from thread!");
Thread thread = new Thread(task);
thread.start();
// forEach
List<String> list = Arrays.asList("apple", "banana", "cherry");
list.forEach(item -> System.out.println("水果:" + item));
函数式接口(Functional Interface)
只包含一个抽象方法的接口,用于支持 Lambda 表达式,使方法行为可以像“函数”一样被传递
| 接口名 | 参数 | 返回 | 用途 | 示例说明 |
|---|---|---|---|---|
Runnable | 无 | 无 | 无参任务 | () -> System.out.println("Run") |
Supplier<T> | 无 | T | 提供一个对象 | () -> "Hello" |
Consumer<T> | T | 无 | 消费一个对象(只执行动作) | (x) -> System.out.println(x) |
Function<T,R> | T | R | 接收一个 T 返回一个 R | (x) -> x.length() |
Predicate<T> | T | 布尔 | 判断某个条件是否成立 | (x) -> x > 0 |
BiFunction<T,U,R> | T,U | R | 接收两个参数返回一个结果 | (a,b) -> a + b |
出了上面的 Runnable 的例子,这里再提供一个 Comparator 的例子:
@FunctionalInterface
public interface StudentComparator {
int compare(Student s1, Student s2);
default void log() {
System.out.println("Comparing students...");
}
static void staticHelper() {
System.out.println("Static helper inside interface");
}
}
public class Student {
String name;
int age;
double score;
public Student(String name, int age, double score) {
this.name = name;
this.age = age;
this.score = score;
}
// ...
}
List<Student> students = Arrays.asList(
new Student("Alice", 20, 85.5),
new Student("Bob", 22, 90.0),
new Student("Charlie", 19, 78.0)
);
// 使用 Lambda 表达式来定义比较规则(按年龄升序)
students.sort((s1, s2) -> s1.age - s2.age);
// 也可以封装成函数式接口
StudentComparator byScore = (s1, s2) -> Double.compare(s1.score, s2.score);
students.sort(byScore::compare);
// 对比传统开发,即不使用lambda和function interface的实现
// 方式一:匿名内部类(匿名实现 Comparator)
students.sort(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
return s1.age - s2.age;
}
});
// 方式二:单独定义一个类
students.sort(new StudentScoreComparator()); // 比分数
// 单独定义一个类:实现 Comparator<Student>
class StudentScoreComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
return Double.compare(s1.score, s2.score);
}
}
可以看到,通过lambda+functional interface的方式,代码实现变得更加的简洁可读。
推荐做法是添加 @FunctionalInterface 的注解,这样Java可以更好的做验证。如果不加的话,在interface中只有一个abstract method的情况下,Java也可以自动推导当前interface是 @FunctionalInterface
Stream API
依旧使用上面的 Student 作为案例:
List<Student> students = List.of(
new Student("Alice", 18, 90),
new Student("Bob", 20, 75),
new Student("Carol", 19, 90),
new Student("David", 20, 85)
);
-
中间操作:
map,filter,sorted,distinct// 转为名字列表 List<String> names = students.stream() .map(student -> student.name) .collect(Collectors.toList()); // 过滤出成绩 ≥ 85 的学生 List<Student> topStudents = students.stream() .filter(s -> s.score >= 85) .collect(Collectors.toList()); // 按年龄升序排序 List<Integer> distinctScores = students.stream() .map(s -> s.score) .distinct() .collect(Collectors.toList()); // 移除重复分数 List<Integer> distinctScores = students.stream() .map(s -> s.score) .distinct() .collect(Collectors.toList()); -
终端操作:
collect,reduce,count// 收集成列表 List<String> names = students.stream() .map(s -> s.name) .collect(Collectors.toList()); // 统计人数 long count = students.stream().count(); // 累加所有分数 int totalScore = students.stream() .map(s -> s.score) .reduce(0, Integer::sum); // or (a, b) -> a + b -
分组统计:
Collectors.groupingBy,partitioningBy虽然分组也是 collect 的一部分,但它使用了
Collectors.groupingBy,语义更复杂,因此单独列出// 按分数分组 Map<Integer, List<Student>> groupedByScore = students.stream() .collect(Collectors.groupingBy(s -> s.score)); // 按年龄分组,并统计每组人数 Map<Integer, Long> ageCountMap = students.stream() .collect(Collectors.groupingBy(s -> s.age, Collectors.counting())); // 按分数分组后,每组提取名字列表 Map<Integer, List<String>> scoreToNames = students.stream() .collect(Collectors.groupingBy( s -> s.score, Collectors.mapping(s -> s.name, Collectors.toList()) ));
总结一下输出结果
| 场景 | 代码片段 | 输出类型 |
|---|---|---|
| 转字段列表 | map(...).collect(toList()) | List<T> |
| 条件过滤 | filter(...).collect(toList()) | List<T> |
| 分组统计 | groupingBy(..., counting()) | Map<K, Long> |
| 分组后映射 | groupingBy(..., mapping(..., toList())) | Map<K, List<V>> |
| 规约求和 | reduce(0, Integer::sum) | int |
| 去重字段 | map(...).distinct() | Stream<T> |
Optional
Optional.of,Optional.empty,orElse,orElseGet,map- 避免 NPE、链式调用
举个例子:
public class User {
private Address address;
public Optional<Address> getAddress() {
return Optional.ofNullable(address);
}
}
public class Address {
private String city;
public Optional<String> getCity() {
return Optional.ofNullable(city);
}
}
// 传统写法
String city = null;
if (user != null && user.getAddress() != null && user.getAddress().getCity() != null) {
city = user.getAddress().getCity();
}
// 使用Optional
String city = user.getAddress()
.flatMap(Address::getCity) // 注意是 flatMap,因为返回值是 Optional
.orElse("Unknown");
补充一个常见的错误用法 vs 正确用法:
Optional<String> name = Optional.of("Tom");
if (name.isPresent()) {
System.out.println(name.get()); // 虽然可以,但违背了 Optional 的设计初衷
}
// 更推荐写成
name.ifPresent(System.out::println);
// 或者
String result = name.orElse("Default");
接口默认方法 & 静态方法
-
defaultmethod 用于向后兼容interface中可以使用
default添加新方法,继承原本的interface 的client端不需要实现新的default方法,需要使用对应方法的新用户也可以实现 overload -
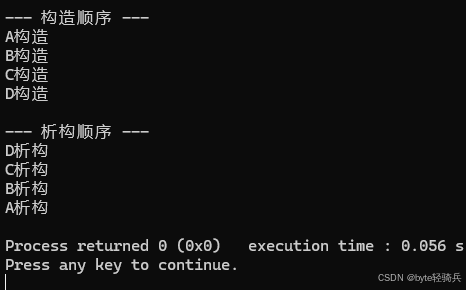
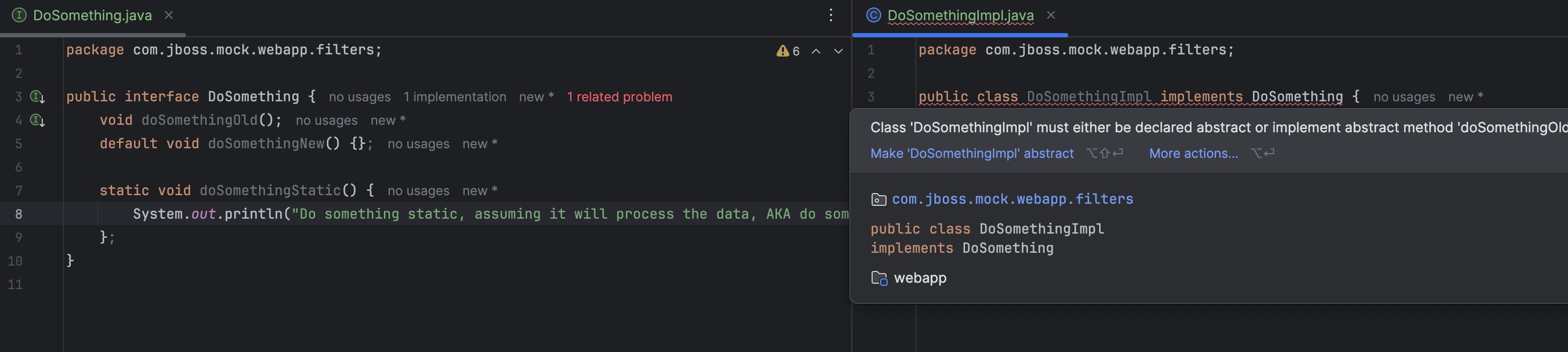
staticmethod in interfaces
这里用截图举个例子说明比较简单:

ConcurrentHashMap(Java 8 重构点)
-
Java 8 改成了分段锁 + CAS(Compare-And-Swap,一种乐观锁,比起之前的
ReentrantLock相比重试更快,也不会抢锁),取消了 Segment具体修改包括:
特性 Java 8 做了什么 ❌ 取消 Segment 不再有 Segment 数组,直接用 Node[] table ✅ 引入 CAS + synchronized 取代 ReentrantLock 的粒度控制 ✅ 链表转红黑树 当链表长度超过阈值(默认 8)转为红黑树,提高查询效率(O(n) → O(log n)) ✅ 支持 computeIfAbsent()、forEach()等并发友好新方法✅ 更轻量的锁机制 每个 bucket(table[i])单独加锁,或使用 CAS,无需全表锁定 -
computeIfAbsent是高频问点- 工作流程:
- 如果
key不存在,则执行 Lambda,生成新值(如new ArrayList<>()); - 用 CAS 或 synchronized(针对单个桶) 安全地插入;
- 避免了
putIfAbsent()+get()的双查找问题。
- 如果
- 高频面试陷阱:
- Lambda 表达式可能会被重复调用(并发争抢下),但只有一个结果会被真正放进去;
- 所以 Lambda 中逻辑要无副作用(side-effect-free);
- 工作流程:
-
与
synchronizedMap对比特性 ConcurrentHashMapCollections.synchronizedMap锁机制 分段+CAS+局部 synchronized 粗粒度同步(整个 Map 加锁) 性能 高并发读写表现优异 写操作竞争大,性能差 Null 支持 ❌ 不支持 key/value 为 null ✅ 支持 null Java 推荐 ✅ 推荐 🚫 已过时(在并发环境)
JUC
核心线程池类(基础构建块)
ExecutorService:线程池接口,支持任务提交、关闭、回收线程资源Future:用于获取异步任务的返回结果,支持取消任务Callable<T>:可返回结果并抛出异常的任务(对比Runnable)
并发工具类(线程同步控制)
CountDownLatch:等待多个线程完成,适合“倒计时”场景(如等待所有子任务执行完毕)CyclicBarrier:多个线程在屏障点等待,适合阶段性同步(如并行计算后统一合并)Semaphore:控制并发线程数(如数据库连接池限流)ReentrantLock:可重入锁,支持公平/非公平机制,可精细控制加锁与释放ThreadLocal:为每个线程维护独立变量副本,常用于用户上下文、连接隔离
Java 8+ 并发增强(异步编排)
CompletableFuture:链式异步任务编排工具,支持组合多个异步结果,替代传统FutureForkJoinPool:用于递归任务分割并行计算,Java 8 中parallelStream()默认使用parallelStream():简化并行流处理,使用ForkJoinPool.commonPool()背后实现
线程池实现与调优点
ThreadPoolExecutor:线程池核心实现类,支持核心线程数、最大线程数、队列容量、拒绝策略等参数配置ScheduledExecutorService:定时任务调度器,支持延迟/周期执行任务,替代老旧的Timer
Java 内存可见性与原子性关键词(高频知识点)
volatile:保证变量可见性,不保证原子性(常用于双重检查锁 DCL 中)synchronized:内置锁,保证原子性和可见性,支持对象级与类级加锁
反射 / 动态代理(Reflection & Dynamic Proxy)
基础 API(Class 对象)
Class<?> clazz = Class.forName("com.example.MyClass")clazz.getDeclaredFields() / getDeclaredMethods():反射读取字段和方法field.setAccessible(true):访问私有字段- 常用于通用框架 / 动态注册 / 对象转换等场景
动态代理(Proxy)
-
Proxy.newProxyInstance(classLoader, interfaces, handler):生成实现接口的代理对象 -
InvocationHandler接口用于定义方法增强逻辑public class MyHandler implements InvocationHandler { private final Object target; public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // before Object result = method.invoke(target, args); // 调用真实方法 // after return result; } } -
🌟 用于 AOP、RPC Stub 构造、权限校验、日志追踪等
-
只能代理 接口(类代理推荐用 CGLIB)
SPI 机制(Service Provider Interface)
- Java 原生插件机制,用于服务发现与自动加载
- 使用方式:
META-INF/services/com.example.InterfaceName文件中声明实现类- 加载方式:
ServiceLoader.load(InterfaceName.class)
- 示例:JDBC 驱动加载、Spring Boot Starter 自动注册、Netty Codec 插件
注解处理器 / 自定义注解
这部分和上面的有一点重复,算是稍微多加一点补充吧……
注解元注解(原注解)
-
@Target:注解可用于哪些位置(如 TYPE, METHOD, FIELD) -
@Retention:注解保留到哪个阶段(SOURCE、CLASS、RUNTIME)@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface LogExecutionTime {}
注解处理器(Annotation Processor)
- 编译期注解处理工具(APT),可用于代码生成
- 实现
javax.annotation.processing.Processor或使用AbstractProcessor - 常见场景:Lombok、MapStruct、Dagger、Spring Configuration Processor







![[论文阅读]PPT: Backdoor Attacks on Pre-trained Models via Poisoned Prompt Tuning](https://i-blog.csdnimg.cn/direct/de400cdd6d5e4854915497717db94854.png)