目录
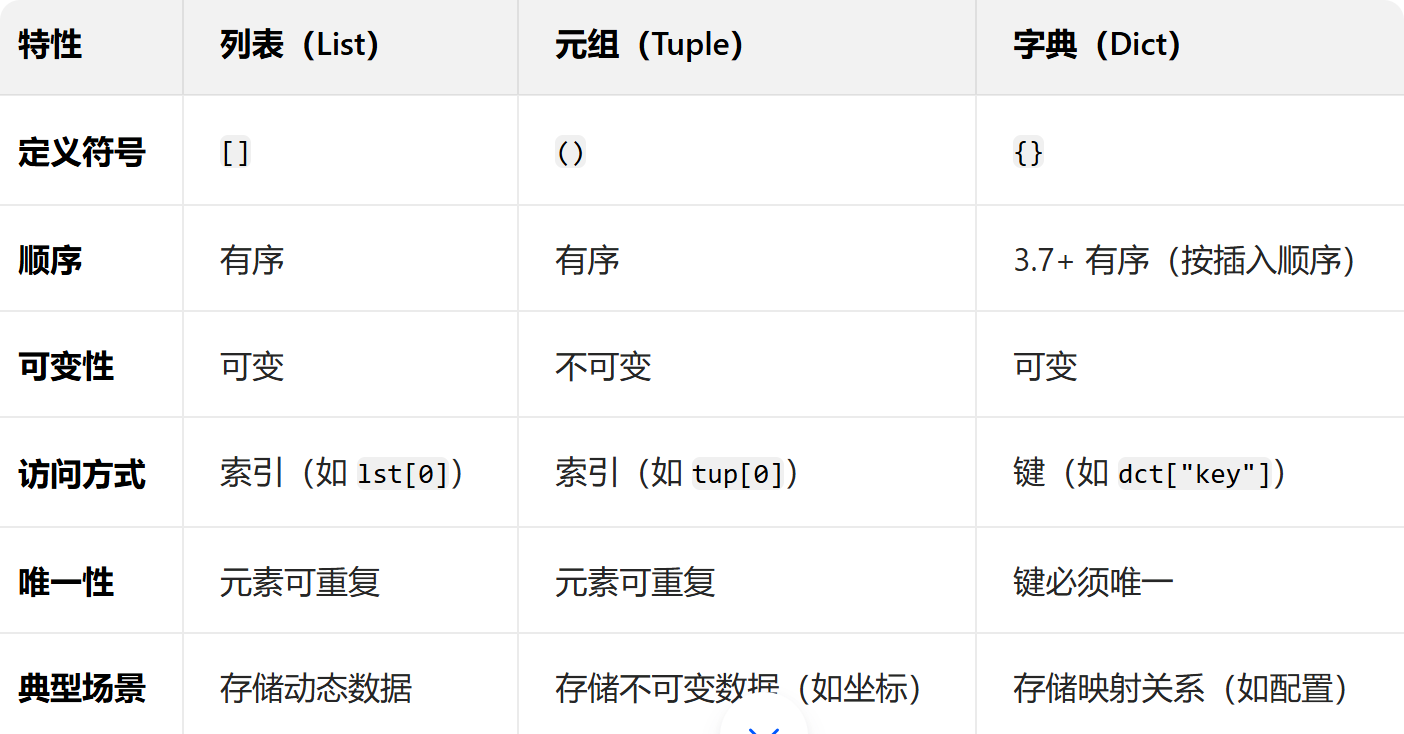
列表、元组、字典的区别
nvicat连接出现问题如何排查
mysql性能调优
python连接mysql数据库方法
参数化 @pytest.mark.parametrize 装饰器
list1 = [1,7,4,5,5,6] for i in range(len(list1): assert list1[i] < list1[i+1] 这段程序有问题嘛?
pytest.int 是干什么的
前端问题后端问题怎么辨别?
性能测试的指标如何获取?
批量接口的参数怎么验证?
给你一个水杯,怎么测(结合功能,性能,安全性,易用性,外观)
测试流程
对于postman和JMeter工具,a接口需要b接口传入数据怎么办
常用的测试方法
测试用例怎么写才能不遗漏测试点?
sql完整的增删改查命令
如果误执行了DELETE FROM orders怎么办?
如果开发人员不认可你提出的缺陷,你会如何处理
Bug 严重等级划分标准
测试人员发现 Bug 后要怎么处理
接口测试用例的设计思路一般是从哪些方面去考虑的?
什么是冒烟测试?其目的和意义是什么?
谈谈你对敏捷测试的理解与实践?
介绍一下po模型
什么项目适合做自动化测试
对于频繁更新的页面元素,如何在自动化测试中进行有效定位和维护
软件测试工作可能会面临项目紧急、任务繁重以及来自开发团队和上级的压力,你会如何应对?
列表、元组、字典的区别
nvicat连接出现问题如何排查
检查连接参数:主机名,端口号,用户名,密码,数据库名
ping 服务器:检查服务器是否可达。
telnet 测试端口:确认端口开放。
确认 MySQL 服务运行状态:
- Windows:在服务管理器中检查 MySQL 服务是否启动。
- Linux:systemctl status mysql
检查服务器防火墙:Windows 防火墙--》在防火墙中添加 MySQL 允许规则。
检查 MySQL 配置文件my.ini中
bind-address是否配置正确验证用户权限:
-- 查看用户权限 SHOW GRANTS FOR 'username'@'%'; -- 授予远程访问权限(示例) GRANT ALL PRIVILEGES ON *.* TO 'username'@'%' IDENTIFIED BY 'password'; FLUSH PRIVILEGES;
mysql性能调优
MySQL 性能调优是提升数据库应用响应速度和吞吐量的关键工作。
方法:
使用最小的数据类型存储数据(如
TINYINT代替INT)索引优化
避免全表扫描
多表关联时用小表驱动大表
python连接mysql数据库方法
使用 mysql-connector-python(官方驱动)
##安装库 pip install mysql-connector-python ##连接数据库 import mysql.connector # 建立连接 try: conn = mysql.connector.connect( host="localhost", # 主机名 user="your_username", # 用户名 password="your_password", # 密码 database="your_database", # 数据库名(可选) port=3306 # 端口(默认3306) ) if conn.is_connected(): print("数据库连接成功!") # 创建游标对象 cursor = conn.cursor() # 执行SQL查询 cursor.execute("SELECT VERSION()") version = cursor.fetchone() print(f"MySQL版本: {version[0]}") # 关闭游标和连接 cursor.close() conn.close() print("数据库连接已关闭") except mysql.connector.Error as err: print(f"连接错误: {err}")使用 pymysql(纯 Python 实现)
##安装库 pip install pymysql #操作步骤 #导包 import pymysql #创建连接 conn=pymysql.connnect(host="211.103.136.224",port="3306",user="student",password="123",database="test",charset="utf8") #创建游标 my_cursor=conn.cursor() # 执行 select sq] my_cursor.execute("select version;") #提取结果,打印查看 res = my_cursor.fetchone( print("查询结果为:",res) print("查询结果为:",res[0]) # 关闭游标 my_cursor.close( #关闭连接 conn.close()
参数化 @pytest.mark.parametrize 装饰器
它能让单个测试函数执行多组参数
#语法: #@pytest.mark.parametrize("测试函数的参数名(多个参数用逗号隔开)", 可迭代对象) 示例:简单 import pytest def add(a, b): return a + b @pytest.mark.parametrize("a, b, expected", [ (1, 2, 3), # 测试用例1:1+2=3 (0, 0, 0), # 测试用例2:0+0=0 (-1, 1, 0), # 测试用例3:-1+1=0 (1.5, 2.5, 4.0), # 测试用例4:1.5+2.5=4.0 ]) def test_add(a, b, expected): assert add(a, b) == expected 示例:参数组合测试 import pytest @pytest.mark.parametrize("x", [1, 2]) @pytest.mark.parametrize("y", [3, 4]) def test_combination(x, y): print(f"测试组合: x={x}, y={y}") #1,3 1,4 2,3 2,4 示例:从数据文件读取参数 @pytest.mark.parametrize("a, b, expected", load_test_data()) def test_add_from_csv(a, b, expected): assert add(a, b) == expected
list1 = [1,7,4,5,5,6] for i in range(len(list1): assert list1[i] < list1[i+1] 这段程序有问题嘛?
- 当
i=0:检查 list1[0] < list1[1] → 1 < 7,True,没问题。- 当
i=1:检查 list1[1] < list1[2] → 7 < 4,False,这会触发 AssertionError,但首先我们得处理索引问题。- 当
i=2:list1[2] < list1[3] → 4 < 5,True。- 当
i=3:list1[3] < list1[4] → 5 < 5?False,因为 5 不小于 5。--》逻辑错误- 当
i=4:list1[4] < list1[5] → 5 < 6,True。- 当
i=5:list1[5] < list1[6],但 list1[6] 不存在,所以 IndexError。--》索引越界错误
pytest.int 是干什么的
pytest.ini是 Pytest 测试框架的核心全局配置文件。通常位于项目根目录下,Pytest 运行时会自动加载其配置。#设置默认命令行参数 (addopts) [pytest] addopts = -v -s --html=report.html --maxfail=2 -v:显示详细测试结果(输出每个用例名称) -s:输出测试中的打印信息(如 print() 语句)。 --html=report.html:自动生成 HTML 测试报告(需安装 pytest-html)。 --maxfail=2:当失败用例达到 2 个时停止测试。 #定义测试用例的识别规则 [pytest] python_files = test_*.py # 识别以 "test_" 开头的文件 python_classes = Test* # 识别以 "Test" 开头的类 python_functions = test_* # 识别以 "test_" 开头的方法/函数
前端问题后端问题怎么辨别?
主要是想探你有没有基础的服务端测试经验。web端F12抓接口看传参,app抓包工具抓接口,传参没异常排除前端,响应异常的话服务端看日志有没有具体的报错信息这是后端异常,定位到具体代码行数可以看看代码实现。
性能测试的指标如何获取?
指标要结合测试场景制定,大概分为两种,一种对方没有明确的指标要求只是想知道系统瓶颈,那就从小往大增压;对方有明确的指标要求比如QPS、并发人数等等那就按目标递增。
批量接口的参数怎么验证?
想探你接口自动化经验,不管是自己搭脚手架还是用开源工具,批量验证响应结果的话基本都是靠断言。
给你一个水杯,怎么测(结合功能,性能,安全性,易用性,外观)
1. 功能测试
1.1 基本功能
- 容量测试:
- 用标准量杯注入精确体积的水(如 500ml),检查水杯是否能正常容纳且无溢出。
- 测试最大容量标记是否准确(误差应小于 ±5%)。
- 密封性测试:
- 装满水后盖上杯盖,水平放置 1 小时,检查是否漏水。
- 模拟颠簸(如放入背包走动 10 分钟),观察是否渗水。
1.2 特殊功能
- 保温性测试:
- 注入 100℃热水,盖上杯盖,2 小时后测量水温(保温杯应保持在 60℃以上)。
- 记录水温从 100℃降至 50℃的时间,评估保温效率。
- 便携功能:
- 测试挂绳、提手的承重能力(悬挂 1kg 重物 30 分钟无断裂)。
- 检查杯套、防滑设计是否有效。
2. 性能测试
2.1 耐用性
- 抗摔测试:
- 从 1 米高度自由落体到水泥地面,重复 5 次,检查是否破裂或变形。
- 塑料杯需测试耐老化性能(如紫外线照射 100 小时后是否变脆)。
- 抗压测试:
- 对杯身施加逐渐增加的压力,记录破裂时的压力值(普通水杯应承受 50N 以上)。
2.2 材料稳定性
- 冷热循环测试:
- 交替注入 100℃热水和 0℃冰水,重复 10 次,检查是否开裂或漏水。
- 化学稳定性:
- 用醋、果汁等酸性液体浸泡 24 小时,检测是否有有害物质析出(如重金属)。
3. 安全性测试
3.1 材料安全
- 食品接触安全性:
- 检查是否通过 FDA、LFGB 等认证,确认材料符合食品级标准。
- 测试塑料杯是否含 BPA(双酚 A)等有害物质。
- 耐高温性:
- 对塑料杯进行高温测试(如 95℃热水浸泡 30 分钟),检查是否释放异味或变形。
3.2 使用安全
- 防烫设计:
- 注入 80℃热水,触摸杯身外部,温度应低于 40℃(避免烫伤)。
- 防漏设计:
- 测试杯盖锁止功能是否可靠(误触打开的概率应小于 1%)。
4. 易用性测试
4.1 操作便捷性
- 开合测试:
- 测试杯盖开启和关闭的力度(建议在 5-15N 之间,避免过紧或过松)。
- 单手操作测试:评估单手打开 / 关闭杯盖的难易程度。
- 饮水体验:
- 测试吸嘴、直饮口的出水速度(每秒 10-20ml 为宜)。
- 检查是否有呛水、漏水问题。
4.2 清洁难度
- 内部结构评估:
- 检查杯口直径是否足够大(≥6cm),便于清洁工具进入。
- 测试带滤网、茶隔的水杯,评估拆卸和清洗的便利性。
5. 外观测试
5.1 美学设计
- 视觉评价:
- 检查表面是否平整、无划痕、色泽均匀。
- 评估图案、logo 的印刷质量(耐磨测试:用酒精棉擦拭 50 次不褪色)。
- 人体工学:
- 测量杯身直径和握感(建议直径在 6-8cm,符合大多数人手掌尺寸)。
- 测试防滑纹理的有效性(湿手状态下滑落概率应小于 5%)。
5.2 环保性
- 材料可持续性:
- 检查是否使用可回收材料(如 PC、PP5 等)。
- 评估包装是否简约、可降解。
测试流程
需求分析,测试计划测试方案,设计用例及测试前的准备(环境搭建,数据初始化,脚本编写等),执行测试,缺陷管理,回归测试达到要求,测试报告
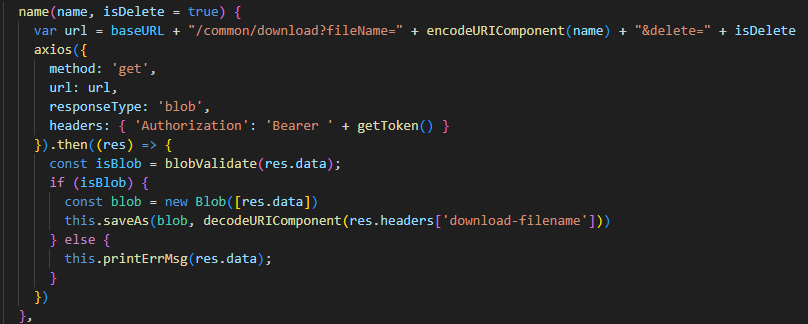
对于postman和JMeter工具,a接口需要b接口传入数据怎么办
思路:提取B接口的数据设为变量,再在A接口的请求中引用变量,最后保证B接口在A接口前执行。
postman
- 在 B 接口的响应中提取需要的数据(如 token、ID 等),并保存到环境变量或全局变量中,在
- A 接口的请求参数、Headers 或 Body 中使用保存的变量,
- 在 Collection Runner 中设置执行顺序,确保 B 接口先于 A 接口执行:
JMeter
- 在 B 接口的 HTTP 请求后添加后端处理器中 JSON 提取器,用于提取需要的数据,并设置为变量
- 在 A 接口的请求参数、Headers 或 Body 中使用提取的变量。
- 在 线程组 中确保 B 接口的 HTTP 请求位于 A 接口之前,JMeter 会按顺序执行。
常用的测试方法
等价类
边界值
判定表:分析输入条件的各种组合及其对应的输出结果。
场景法:基于用户实际使用场景设计测试用例,通常包含基本流和备选流。
因果图:分析输入条件(原因)与输出结果(效果)之间的逻辑关系。
错误推断法:基于经验预测可能的错误并设计测试用例。
测试用例怎么写才能不遗漏测试点?
系统化分析需求:从需求文档中提取所有功能点、业务规则和隐含要求。
- 将需求分解为最小可测试单元(如"登录页面"拆分为输入字段,验证规则,交互逻辑)
- 挖掘隐含需求:性能(响应时间)、兼容性(浏览器 / 设备适配)、安全性(密码加密),界面布局合理性、操作流畅性。
结构化设计用例:通过系统化方法覆盖不同维度的测试点,避免凭经验遗漏。同时保证用例步骤清晰,可复现
功能测试:基于黑盒测试对需求的正向 / 反向验证
流程测试:使用场景分析法和状态迁移法覆盖业务逻辑路径
非功能测试:按需求点进行测试
团队协作评审
- 团队评审:组织开发、产品、测试人员共同评审用例,从不同视角发现遗漏
- 动态补充:在测试执行中,记录未覆盖的场景(如偶然发现的异常流程),及时补充用例。
- 历史用例复用:参考类似项目的测试用例库,补充通用场景(如登录功能的验证码测试、忘记密码流程)。
sql完整的增删改查命令
#查询
SELECT 列1, 列2 FROM 表名
WHERE 条件
ORDER BY 排序列
LIMIT 行数;
#插入
INSERT INTO 表名 (列1, 列2)
VALUES (值1, 值2), (值3, 值4); -- 支持批量插入
#更新
UPDATE 表名
SET 列1=新值1, 列2=新值2
WHERE 条件; -- WHERE是安全关键!
#删除
DELETE FROM 表名
WHERE 条件; -- 无WHERE将清空全表,单保留表结构如果误执行了DELETE FROM orders怎么办?
- 立即停止数据库操作
- 联系DBA(数据管理员)尝试从binlog恢复
- 后续流程中增加SQL执行审核机制
如果开发人员不认可你提出的缺陷,你会如何处理
1)缺陷复现
再次严格按照测试用例复现问题,确保缺陷是稳定出现的(非偶发)。记录详细的复现步骤、环境信息(如浏览器版本、操作系统、数据配置)、截图 / 日志等证据。同时检查是否因测试环境不稳定、数据缓存或权限问题导致误判。
2)明确缺陷影响
从用户体验、功能完整性、合规性等角度说明问题的严重性。
3)与开发人员进行技术沟通
简单问题的话即可沟通;复杂问题可进行会议讨论。
4)僵持不下
若争议源于需求模糊或变更,可邀请产品经理确认。
引用同类问题的处理方式或行业规范。
使用数据或用户反馈佐证
Bug 严重等级划分标准
1. 致命级(Critical)
- 定义:导致系统无法正常运行、数据丢失或存在重大安全风险的 Bug。
- 典型场景:
- 程序崩溃、无法启动或频繁无响应。
- 核心功能完全不可用(如支付功能异常导致交易失败)。
- 敏感数据泄露(如用户密码明文存储、数据库连接信息暴露)。
- 多用户并发操作时数据严重不一致或系统瘫痪。
- 处理优先级:立即修复,需优先安排开发资源处理,避免影响线上用户或造成重大损失。
2. 严重级(High)
- 定义:影响主要功能使用或导致用户体验显著下降,但系统仍可部分运行的 Bug。
- 典型场景:
- 主要功能存在错误(如搜索结果不准确、订单状态显示异常)。
- 流程阻断(如注册流程中必填项验证失败但无提示)。
- 性能问题显著(如页面加载时间超过 5 秒、内存占用持续飙升)。
- 兼容性问题导致核心功能不可用(如某浏览器无法提交表单)。
- 处理优先级:高优先级,需在版本迭代周期内尽快修复,避免影响多数用户的核心操作。
3. 中级(Medium)
- 定义:影响次要功能或用户体验,但不影响系统核心流程的 Bug。
- 典型场景:
- 界面显示异常(如图片加载失败、按钮样式错位)。
- 交互逻辑不友好(如提示信息不明确、操作步骤冗余)。
- 非核心功能错误(如帮助文档链接失效、统计图表数据偏差较小)。
- 兼容性问题影响非核心功能(如某机型闹钟提醒声音异常)。
- 处理优先级:中优先级,可在后续版本中规划修复,或根据资源情况调整处理时间。
4. 轻微级(Low)
- 定义:对功能和体验影响极小,属于细节优化范畴的 Bug。
- 典型场景:
- 文案错别字、标点符号错误。
- 界面元素间距不一致、按钮颜色偏差。
- 非关键页面的加载动画卡顿。
- 低频率出现的边缘情况问题(如极端格式输入导致的显示异常)。
- 处理优先级:低优先级,可集中在迭代末期或专门的优化版本中处理,或根据产品策略决定是否修复。
除了影响程度,划分 Bug 等级时还需考虑以下因素:
- 用户影响范围:影响大量用户或高频操作的 Bug 等级更高。
- 重现概率:稳定重现的 Bug 比偶发问题更易定位和修复,等级可能更高。
- 行业规范与合规性:涉及安全合规(如 GDPR、金融监管)的 Bug 需提升等级。
- 业务场景:业务高峰期出现的 Bug 或影响关键业务流程的问题优先级更高。
测试人员发现 Bug 后要怎么处理
- 记录与描述:详细填写 Bug 标题、重现步骤、预期 / 实际结果、截图 / 日志等信息。
- 初步定级:根据标准初判等级,提交给开发团队评审。
- 开发评审:开发人员复现并评估 Bug,确认等级或调整(如偶发的致命 Bug 可能降级为严重)。
- 修复与验证:按优先级修复后,测试人员重新验证,关闭或重新激活 Bug(若未解决)。
- 总结复盘:定期分析高频或高等级 Bug,优化测试用例和开发流程,减少同类问题。
接口测试用例的设计思路一般是从哪些方面去考虑的?
1.功能测试是从业务流程和单功能方面进行测试的
- 业务流程用最少的 用例 覆盖最多的业务场景,只进行正向测试即可。
- 单功能对数值和参数进行正反测试。
2.性能测试主要测响应时间,吞吐量,并发数,资源使用率
3.安全测试主要测试敏感数据是否加密
什么是冒烟测试?其目的和意义是什么?
冒烟测试的定义
在版本发布或进入正式测试阶段前,对软件的核心功能和关键流程进行快速、轻量级的验证,确保软件的基本功能正常运行,没有 “致命性错误”,从而避免后续测试在不可用的版本上浪费时间。
目的
- 验证版本基本可用性
- 快速定位致命缺陷
- 减少无效测试投入
意义
对测试来说,可以过滤掉无效版本,明确测试的准入条件。
谈谈你对敏捷测试的理解与实践?
敏捷测试强调快速响应变化、持续交付价值、团队协作和以用户为中心。他要求测试应在需求分析阶段就开始,同时测试和开发并行迭代,优先使用自动化。
介绍一下po模型
PO 模型(Page Object Model,页面对象模型) 是一种自动化测试设计模式,用于分离测试逻辑与页面元素操作,通过将页面抽象为对象,降低测试代码的耦合度,提高可维护性和复用性。PO模型将页面分为三层,分别为对象层,操作层和业务层。它是 UI 自动化测试(如 Selenium、Appium)中最主流的设计模式之一。
什么项目适合做自动化测试
1)需求稳定、迭代周期长的项目:自动化脚本可长期复用,维护成本低。
2)高频次重复测试的项目:自动化脚本可快速执行数百 / 数千条用例,效率远超手动测试。
3)技术复杂度高或风险高的模块:通过自动化脚本精准验证逻辑正确性(如计算精度、接口响应时间)。提前暴露代码缺陷,降低生产环境故障风险。
4)跨平台 / 多环境兼容测试:自动化工具(如 Selenium、Appium)可批量执行跨平台测试,覆盖手动难以触及的组合(如 “Chrome + Windows 10 + 屏幕分辨率 1920x1080”)。
5)性能 / 负载测试需求明确的项目:借助工具(如 JMeter、LoadRunner)模拟真实负载,自动化生成性能报告(如响应时间、吞吐量、错误率)。
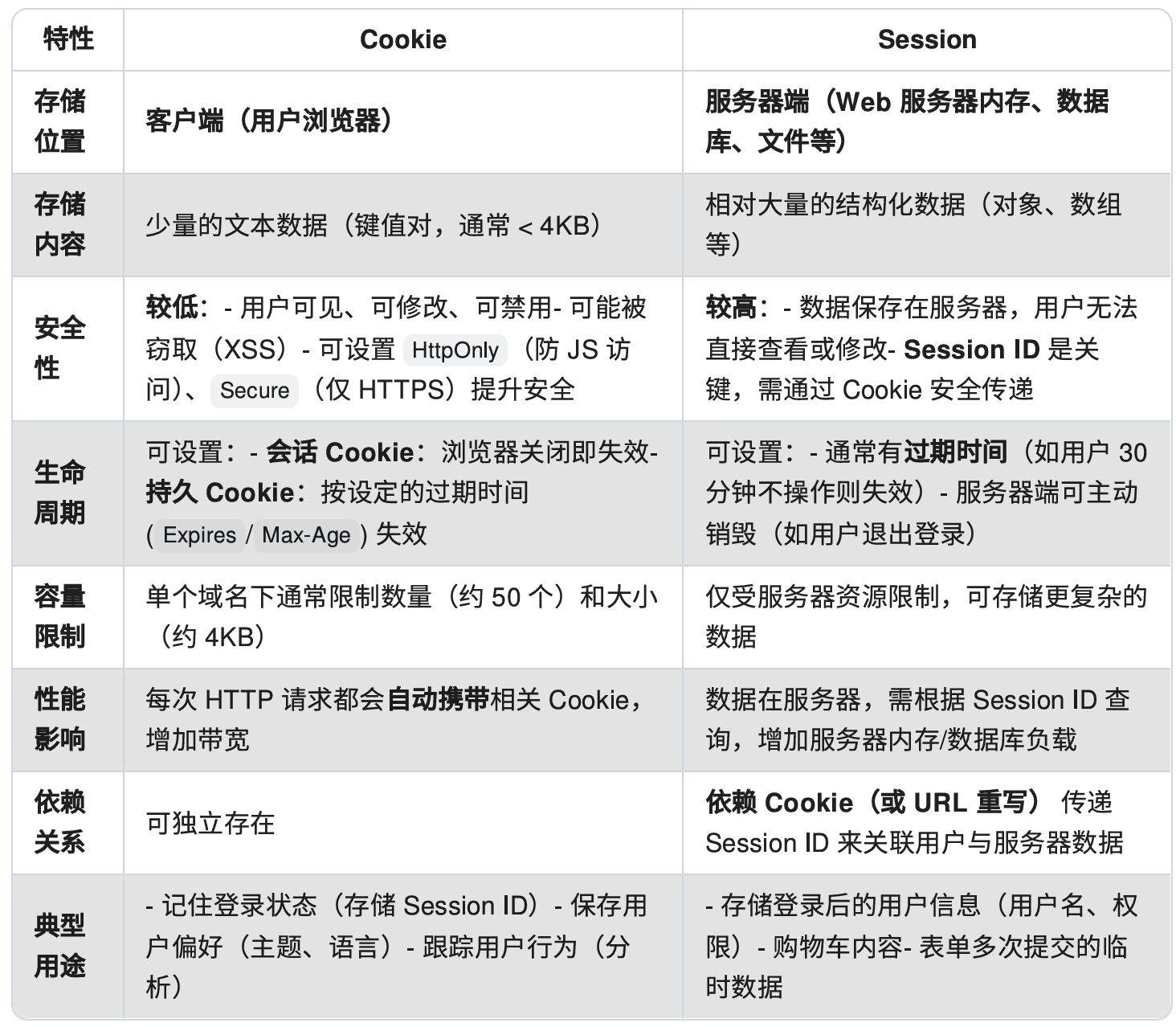
cookie 和 session 的区别是什么
对于频繁更新的页面元素,如何在自动化测试中进行有效定位和维护
可使用 PO 模型集中管理元素定位
软件测试工作可能会面临项目紧急、任务繁重以及来自开发团队和上级的压力,你会如何应对?
面对任务繁重和多方压力时,首先会更加任务的重要程度和截止时间进行优先级排序,制定好时间计划,保证任务的可视化。
所有面试题来源于自己面试问题以及红薯帖子里。答案不唯一,仅供参考。