目录
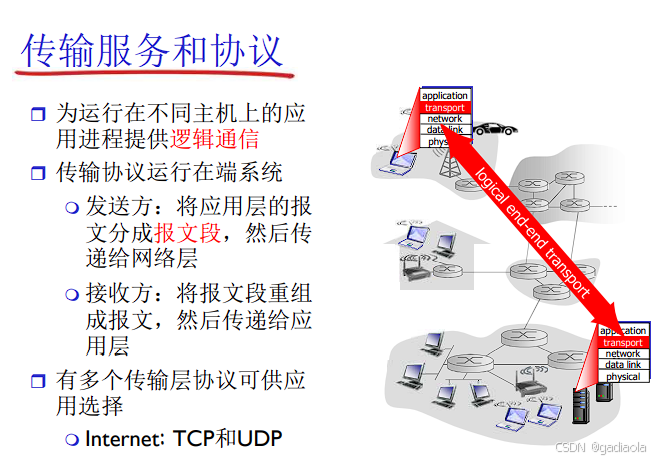
一、概述和传输层服务
二、多路复用与解复用
三、无连接传输:UDP
四、总结
(一)多路复用与解复用
(二)UDP
一、概述和传输层服务

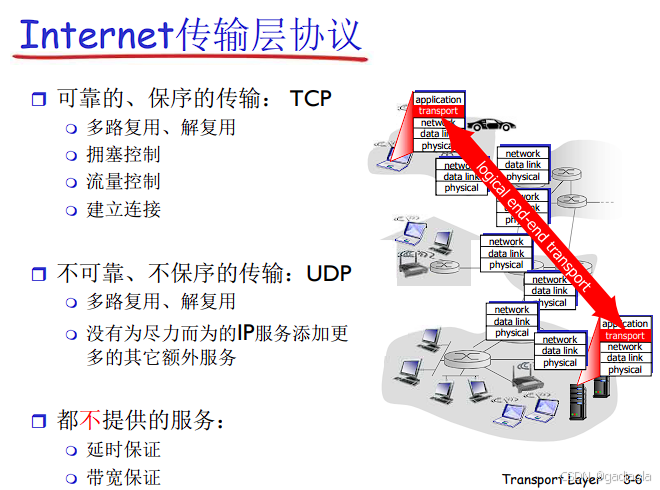
二、多路复用与解复用




三、无连接传输:UDP




四、总结
(一)多路复用与解复用
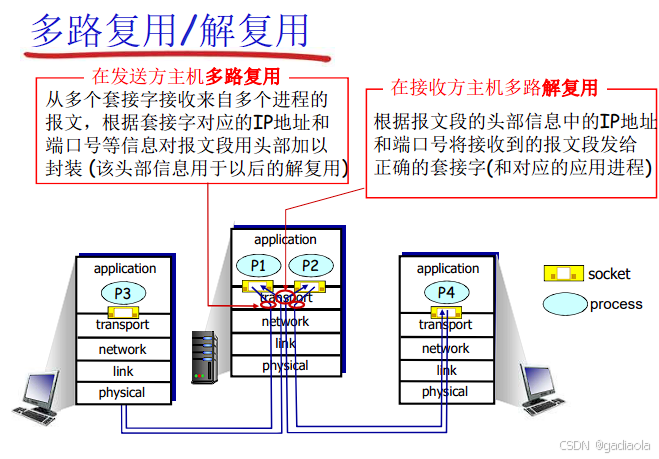
核心思想:
想象一条高速公路(网络信道)。多路复用允许来自不同源头(发送方应用进程)的车辆(数据)共享同一条主干道(同一个网络层协议,如IP),最终到达各自正确的目的地(接收方应用进程)。解复用则是在目的地根据车辆上的标识(地址)将它们分拣到各自正确的出口(接收方应用进程)。
1. 多路复用 (Multiplexing)
-
定义: 在发送端,将来自多个高层应用进程或数据流的数据,合并到同一个低层协议数据单元(通常是网络层数据包,如IP数据报)中,通过同一个底层传输信道(如一条物理链路、一个网络层连接)进行传输的过程。
-
目的:
-
提高资源利用率: 避免为每一个应用进程或短时数据流都建立独立的底层连接,极大地节省了网络带宽和端口资源。
-
简化网络管理: 网络层只需处理单一的IP数据报流,而不需要关心上层众多的应用流。
-
降低成本: 共享基础设施降低了传输成本。
-
-
关键要素 (在发送端):
-
源应用进程: 多个需要发送数据的应用程序(如浏览器标签、邮件客户端、文件传输)。
-
传输层协议: 主要是 TCP 和 UDP。
-
多路复用字段: 传输层在将应用数据封装成段(Segment)或数据报(Datagram)时,会添加关键的标识信息:
-
源端口号 (Source Port Number): 标识发送数据的本地应用进程。
-
目的端口号 (Destination Port Number): 标识数据要交付给远程主机上的哪个目标应用进程。
-
-
网络层封装: 传输层段(包含源/目的端口号和应用数据)被交给网络层(如IP)。网络层将其封装成IP数据报,添加源/目的IP地址。
-
-
过程描述 (发送端):
-
不同的应用进程(P1, P2, ...)通过各自的套接字(Socket) 调用传输层服务(如
send())。 -
传输层(TCP/UDP)接收来自不同套接字的数据块。
-
传输层为每个数据块添加传输层头部,其中最关键的是填写源端口号(标识发送进程)和目的端口号(标识目标进程)。
-
这些带有源/目的端口号的传输层段被传递给网络层(IP)。
-
网络层将传输层段封装成IP数据报(添加源/目的IP地址),并通过底层网络接口发送出去。来自不同应用进程(不同源端口)但去往同一目标主机(同一目的IP)的数据,就这样被“复用”到了同一个IP数据流中。
-
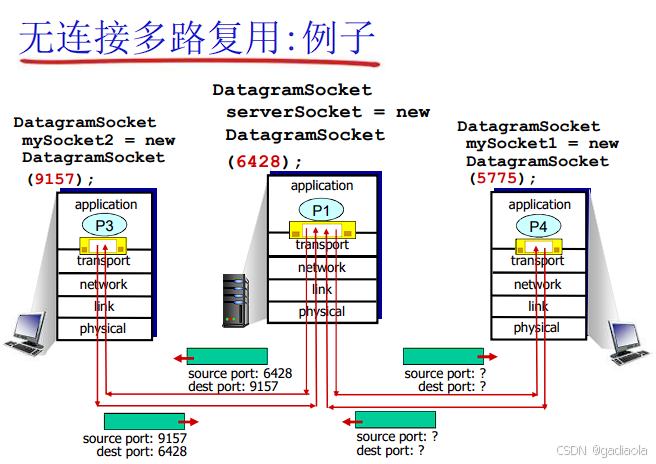
2. 解复用 (Demultiplexing)
-
定义: 在接收端,从同一个低层协议数据单元流(如接收到的IP数据报流)中,根据数据单元中的标识信息,分离出数据,并将其正确地交付给指定的高层应用进程的过程。它是多路复用的逆过程。
-
目的:
-
正确交付: 确保接收到的数据被准确地传递给目标主机上正确的目标应用进程。
-
重建数据流: 对于面向连接的协议(如TCP),解复用还涉及到将乱序到达的段按顺序重组,还原成原始的应用数据流。
-
-
关键要素 (在接收端):
-
传输层协议: TCP 或 UDP。
-
解复用字段: 接收端传输层从网络层交付的IP数据报中提取:
-
源IP地址 (Source IP Address): 标识发送数据的主机。
-
目的IP地址 (Destination IP Address): 标识接收数据的主机(本机)。
-
协议字段 (Protocol Field - IP头部): 指示封装的是TCP段(6)还是UDP数据报(17)。
-
源端口号 (Source Port Number): 标识发送数据的远程应用进程。
-
目的端口号 (Destination Port Number): 标识数据要交付给本机上的哪个目标应用进程。
-
-
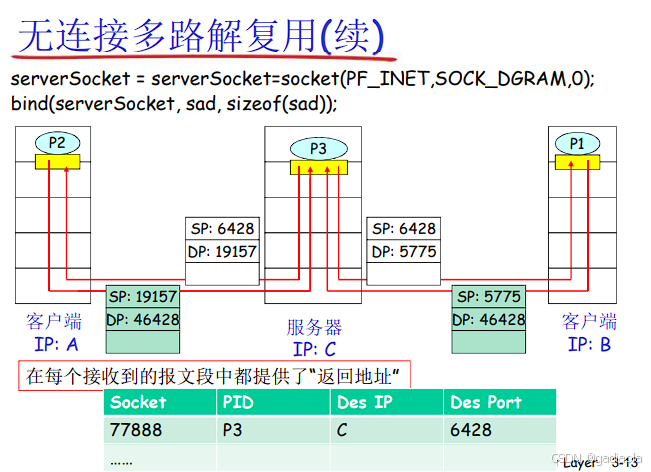
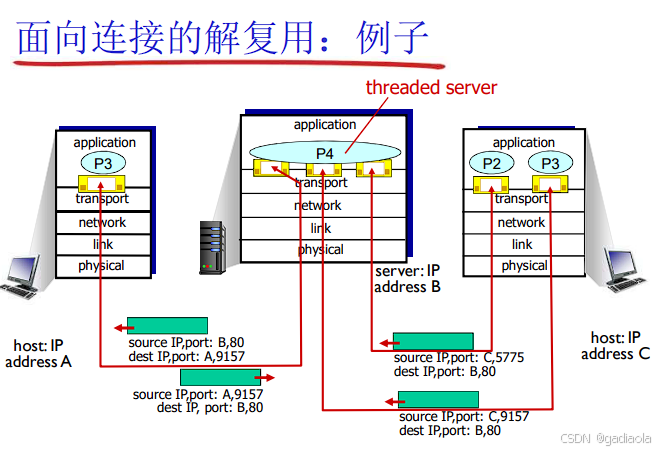
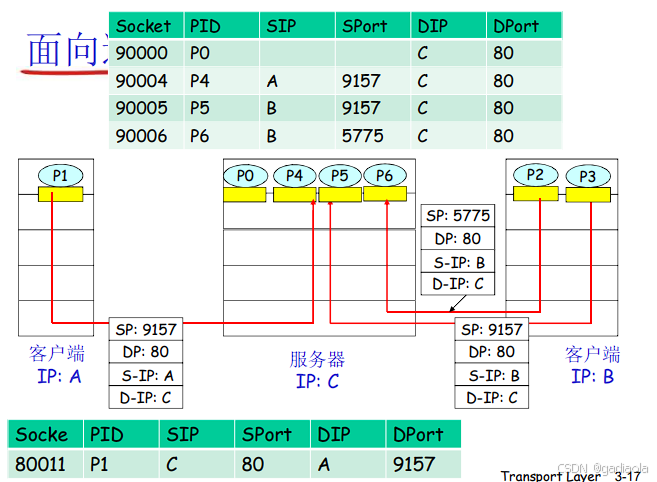
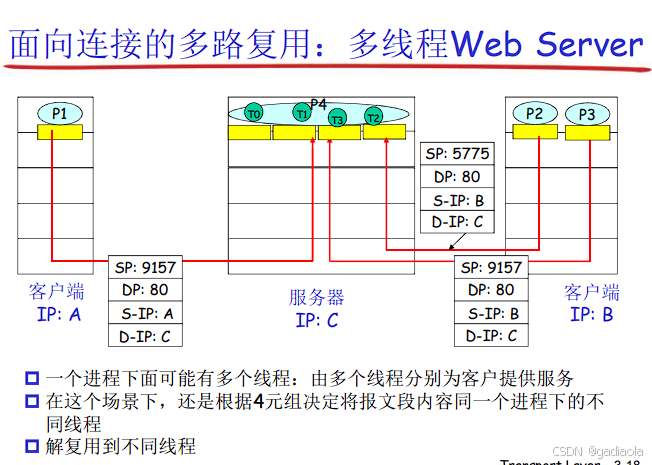
套接字 (Socket): 接收端操作系统为每个正在等待数据的应用进程维护一个“门户”。套接字由 <本地IP地址, 本地端口号, 协议(TCP/UDP)> 唯一标识。对于TCP,一个连接由 <源IP, 源端口, 目的IP, 目的端口> 四元组唯一标识。
-
-
过程描述 (接收端):
-
接收主机通过网络接口接收到IP数据报。
-
网络层(IP)检查目的IP地址是否匹配本机地址。匹配则剥去IP头部,根据IP头部的协议字段确定将数据报的有效载荷(传输层段)交给哪个传输层协议(TCP或UDP)。
-
传输层(TCP或UDP)接收数据段。
-
传输层检查段头部中的目的端口号。
-
传输层根据以下信息查找匹配的套接字:
-
UDP: 主要依赖 <目的IP地址, 目的端口号>。只要目的端口号匹配一个正在监听的UDP套接字,数据就被交付给该套接字对应的应用进程。源IP和源端口通常用于回复。
-
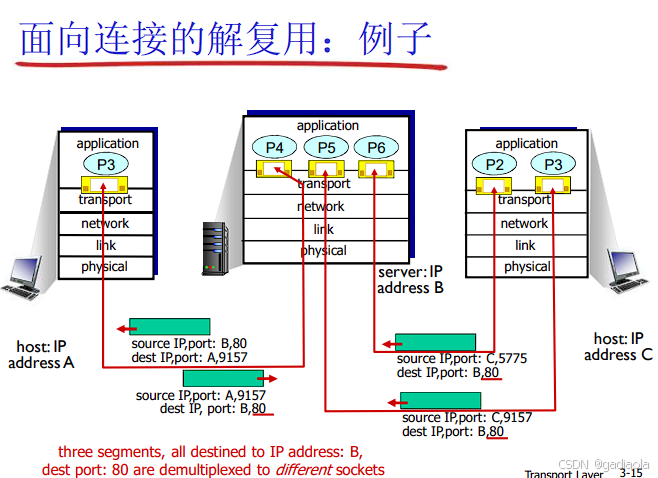
TCP: 依赖完整的 <源IP地址, 源端口号, 目的IP地址, 目的端口号> 四元组来唯一标识一个TCP连接。传输层查找具有匹配四元组的套接字,将数据交付给该套接字绑定的应用进程。TCP还负责段排序、确认、重传等。
-
-
数据被放入对应套接字的接收缓冲区。
-
目标应用进程通过其套接字读取接收缓冲区中的数据。
-
多路复用与解复用的核心依赖:端口号
-
端口号 (Port Number): 这是一个16位的整数(范围0-65535),是传输层实现多路复用和解复用的关键标识符。
-
源端口号: 由发送方主机(通常是操作系统)动态分配(客户端端口),用于标识发送数据的本地进程。
-
目的端口号: 通常由应用层协议约定(服务器端口),用于标识接收方主机上的目标服务进程(如HTTP:80, HTTPS:443, FTP:21, DNS:53)。客户端程序需要知道服务器的目的端口号才能发起连接或发送数据。
-
-
套接字地址 (Socket Address): 网络通信的端点由 IP地址 + 端口号 唯一标识。发送端的套接字地址是
<源IP, 源端口>,接收端的套接字地址是<目的IP, 目的端口>。TCP连接则由两端的套接字地址(四元组)唯一确定。
TCP 与 UDP 在复用/解复用上的关键区别
| 特性 | UDP (无连接) | TCP (面向连接) |
|---|---|---|
| 连接标识 | 无连接概念 | 每个连接由四元组 <源IP, 源端口, 目的IP, 目的端口> 唯一标识 |
| 解复用依据 | 仅依赖目的端口号 (匹配监听该端口的UDP套接字) | 依赖完整的四元组 (匹配特定的TCP连接套接字) |
| 数据交付 | 数据报独立交付,可能乱序、丢失。 | 字节流按序可靠交付。 |
| 套接字 | 一个UDP套接字可以接收所有发往其端口的数据报 (无论来源)。 | 每个TCP连接对应一个独立的套接字。 |
| 示例 | DNS查询、音视频流、广播/多播。 | Web浏览(HTTP/HTTPS)、文件传输(FTP)、电子邮件(SMTP/POP/IMAP)、远程登录(SSH)。 |
应用层的多路复用
这个概念不仅限于传输层。在更高层也存在复用:
-
HTTP/1.1 Pipelining: 允许在同一个TCP连接上发送多个HTTP请求(复用),但响应必须按序返回(容易队头阻塞)。
-
HTTP/2: 引入了流(Stream)的概念,在同一个TCP连接上实现了真正的多路复用。多个HTTP请求/响应对(流)可以交错传输,互不阻塞。每个流有唯一的ID标识。这极大地提高了Web页面的加载效率。
-
HTTP/3 (基于QUIC): QUIC协议在UDP之上实现了自己的可靠传输和连接管理。它在QUIC层也使用了流ID来实现多路复用,并且解决了TCP层的队头阻塞问题。
总结
-
多路复用: 发送端将多个应用数据流汇聚到一个底层传输信道(通过添加端口号/IP地址标识)。
-
解复用: 接收端根据端口号/IP地址标识将汇聚的数据流分离并正确交付给目标应用进程。
-
核心机制: 依赖于传输层端口号(结合网络层IP地址)来唯一标识通信端点(套接字)。
-
TCP vs UDP: TCP使用四元组进行精确解复用到特定连接;UDP仅使用目的端口号解复用到监听套接字。
-
价值: 实现了网络资源的极大共享,简化了网络结构,是互联网能够高效承载海量应用的基础。
(二)UDP
UDP 的核心定位与设计哲学
-
“尽力而为”的传输层协议: UDP位于TCP/IP模型的传输层(第4层),在网络层IP服务(提供主机到主机的逻辑通信)之上,为应用进程提供进程到进程的逻辑通信。
-
极简主义: UDP协议本身非常简单。它在IP提供的基础服务之上,只添加了非常少的功能:
-
多路复用/解复用: 通过端口号区分同一主机上的不同应用进程。
-
轻量级的错误检测: 提供可选的校验和,用于检测传输过程中UDP头部和数据部分是否出错。
-
-
无连接 (Connectionless):
-
发送数据前不需要像TCP那样建立连接(三次握手)。
-
每个UDP数据报都是独立的实体,彼此之间没有关联。
-
通信双方没有长期维护的连接状态(如序号、确认号、窗口大小、RTT估计等)。
-
-
不可靠 (Unreliable):
-
不保证交付: 发送的UDP数据报可能丢失,且协议本身不会重传。
-
不保证顺序: 即使发送方按顺序发送多个数据报,接收方收到的顺序也可能不同。
-
不保证完整性: 虽然有校验和,但如果检测到错误,UDP通常只是静默丢弃该数据报,不会通知发送方或接收方上层应用(有些实现可能会将错误信息上传给应用层)。
-
不提供拥塞控制: UDP本身没有内置机制来感知或响应网络拥塞。发送方可以以任何速率发送数据报,不管网络是否拥塞。
-
UDP 报文段 (Segment) 结构 - 极其精简
UDP数据报由头部 (Header) 和数据 (Data) 两部分组成。头部固定为 8 字节,包含4个字段,每个字段2字节:
0 16 31
+---------------+---------------+---------------+
| 源端口号 | 目的端口号 | |
| (Source Port) | (Destination Port)| |
+---------------+---------------+---------------+
| 长度 | 校验和 | |
| (Length) | (Checksum) | |
+---------------+---------------+---------------+
| |
| 数据... |
| |
+-----------------------------------------------+-
源端口号 (Source Port, 16 bits): 标识发送数据的应用进程。可选字段,如果发送方应用不需要回复,可以设为0。主要用于接收方回复时知道发给谁。
-
目的端口号 (Destination Port, 16 bits): 必需字段。标识接收主机上目标应用进程(如DNS服务监听53端口)。
-
长度 (Length, 16 bits): 整个UDP数据报的长度(包括8字节头部 + 数据部分),以字节为单位。最小值是8(只有头部,没有数据)。
-
校验和 (Checksum, 16 bits): 可选字段(但实际实现中几乎总是启用),用于检测UDP头部和数据在传输过程中是否出错。
-
计算范围: 不仅计算UDP头部和数据,还包含一个伪头部(Pseudo-Header)。伪头部包含源IP、目的IP、协议号(UDP=17)、UDP长度。引入伪头部的目的是为了验证数据报确实到达了正确的目的主机和正确的传输层协议。
-
工作原理: 发送方计算校验和并填入该字段。接收方重新计算校验和,如果与收到的值不匹配,则静默丢弃该数据报(通常不会产生错误消息)。如果校验和字段为0,表示发送方没有计算校验和(不推荐)。
-
UDP 的关键特性总结
-
无连接: 减少建立/维护连接的开销和延迟。
-
不可靠: 不保证交付、顺序或完整性。
-
无拥塞控制: 发送速率由应用决定,可能加剧网络拥塞。
-
面向报文: 应用层交给UDP多长的报文,UDP就发送多长的报文(一次发送一个完整的报文)。UDP不会对应用层报文进行拆分或合并(IP层可能会分片,但那是IP层的行为)。接收方UDP一次交付一个完整的报文给应用层。应用层需要自己处理报文边界。
-
轻量级:
-
头部开销极小(仅8字节),相比TCP至少20字节的头部更高效。
-
发送方和接收方无需维护复杂的连接状态信息。
-
协议处理逻辑简单,速度快,延迟低。
-
-
支持一对一、一对多、多对一、多对多通信: 利用IP层的单播、广播、多播功能,UDP可以轻松实现多种通信模式。
UDP 的优势 (为什么选择它?)
UDP的“缺点”(不可靠、无连接)在特定场景下恰恰是其优势所在:
-
极低的延迟和抖动:
-
无连接建立开销(三次握手),数据立即可发。
-
无确认、重传机制,数据持续流动。
-
应用场景: 实时音视频通话(VoIP如Skype, Zoom)、在线游戏、实时流媒体(直播)、视频会议。少量丢包导致的短暂卡顿或杂音比TCP重传导致的严重延迟或缓冲更容易被用户接受。
-
-
简单高效,开销小:
-
协议处理简单,CPU和内存资源占用少。
-
头部开销小,有效载荷占比高。
-
应用场景: 简单查询-响应协议(DNS - 通常第一个查询用UDP)、SNMP(网络管理)、DHCP(动态主机配置)、TFTP(简单文件传输,常用于网络设备固件更新)。
-
-
细粒度的应用层控制:
-
应用开发者可以在应用层根据需要实现自己所需的可靠性机制、流量控制、拥塞控制或顺序保证,更加灵活定制化。例如:
-
音视频应用:选择性重传关键帧,忽略不重要的中间帧。
-
金融行情推送:只发送最新数据,丢弃旧数据。
-
在线游戏:实现自定义的、对延迟敏感的状态同步和预测机制。
-
-
-
支持广播和多播:
-
UDP天然支持向多个接收者发送数据(广播:同一子网所有主机;多播:订阅了特定组的主机)。
-
应用场景: 服务发现(如mDNS/Bonjour)、路由协议更新(如RIP)、多媒体分发(IPTV)、实时数据分发(股票行情)。
-
UDP 的缺点与挑战
-
不可靠性: 数据可能丢失、乱序、重复。应用层必须自行处理这些问题(如果需要可靠性)。
-
缺乏拥塞控制: 如果应用设计不当,大量发送UDP流量可能淹没网络,导致严重拥塞,影响自身和其他协议(如TCP)的性能。这是使用UDP最大的风险和责任。 现代应用(如QUIC)在UDP之上实现了自己的拥塞控制来解决这个问题。
-
报文大小限制: UDP数据报最大长度为65535字节(包括8字节头部)。但实际受限于下层协议:
-
IPv4: 受限于MTU(通常是1500字节以太网MTU)。如果UDP数据报长度(IP层载荷)超过路径MTU,IP层会进行分片。分片会降低效率,增加丢失风险(一个分片丢失,整个IP数据报失效)。
-
IPv6: 不支持中间路由器分片。如果UDP数据报长度超过路径MTU,且发送方没有使用路径MTU发现(PMTUD),数据报会被丢弃,并可能产生ICMPv6 “Packet Too Big” 错误。
-
-
无连接状态: 防火墙和NAT设备更难跟踪和管理UDP“流”,可能带来安全或穿越问题(需要应用层保活或辅助协议如STUN/TURN/ICE)。
典型使用 UDP 的应用层协议
-
DNS (Domain Name System): 域名解析查询(通常优先使用UDP,响应太大或需要TCP时切TCP)。
-
DHCP (Dynamic Host Configuration Protocol): 动态获取IP地址。
-
SNMP (Simple Network Management Protocol): 网络设备监控和管理。
-
TFTP (Trivial File Transfer Protocol): 简单文件传输(如无盘启动)。
-
RTP (Real-time Transport Protocol): 承载实时音视频数据流(通常运行在UDP之上)。
-
QUIC (Quick UDP Internet Connections): 新一代传输协议,在UDP之上实现可靠、安全、低延迟的传输,用于HTTP/3。
-
在线游戏协议: 大量实时多人在线游戏使用UDP或其变种进行状态同步。
-
VoIP (Voice over IP): 如SIP信令(有时用TCP/UDP)和RTP媒体流(主要用UDP)。
-
自定义协议: 许多对延迟敏感或有特殊需求的应用会基于UDP开发自己的协议。
总结:UDP 的本质
UDP是传输层协议中的“轻骑兵”。它放弃了TCP的可靠性、顺序保证、流量控制和拥塞控制等复杂机制,换取了极致的简单、高效和低延迟。这种设计哲学使得UDP在以下场景中成为首选:
-
对延迟和抖动极其敏感的应用(实时音视频、游戏)。
-
简单高效的查询-响应模型(DNS, SNMP)。
-
需要广播或多播的应用。
-
应用层自身需要实现定制化传输逻辑的场景。
-
能容忍一定程度数据丢失的场景。