上课没听过报道。欢迎补充交流!
前言:老师画的重点其实可以完全不用看,我这里只是看了一眼书顺着书本敲一遍。
比较干货的部分,直接看学习通的内容就好。最重要的是把学习通的内容记好。
目录

老师划的重点:P50
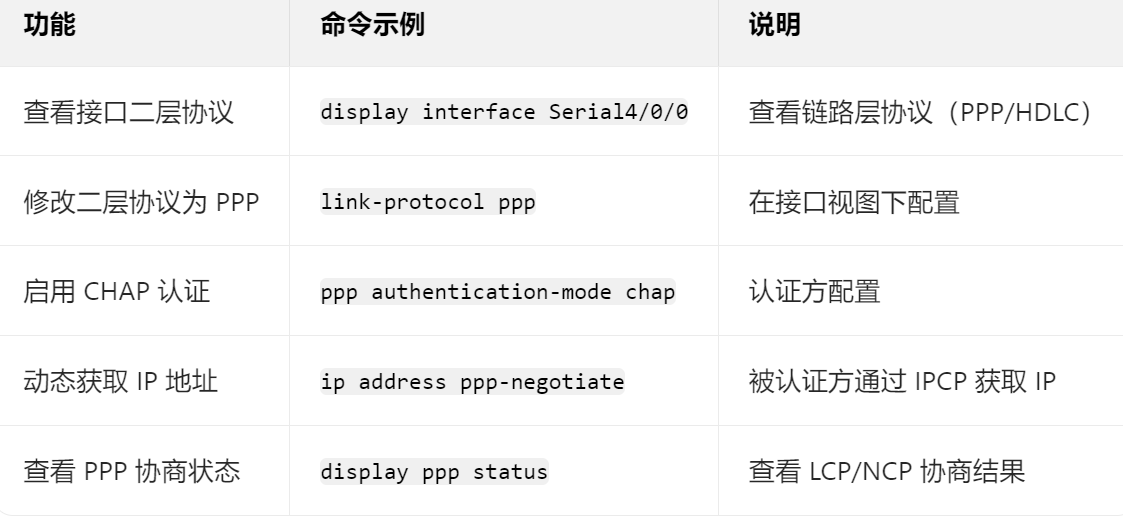
结构化记忆:from sklearn库 import 包名称
P51
P53
作业2 填空题
作业十五
我记得老师说有20个选择题,10道判断题,一共50分。 背学习通。
学习通上的有的选择判断书上也有,大家可以在学习通上做一遍之后,再在书上做一遍检查。
程序填空题20分,应用题包含计算题30分。
所以咱们得把学习通所有的填空题搞懂...毕竟20分,不能空着。
KD树划分、P106评价指标、最后一节课讲了P175的题反向传播算法也不知道考不考。
OK有了方向就可以开始学习:
1.学习通 占比50分
2.填空题 20分
3.几个计算题 30分
老师划的重点:P50
Scikit-learn概述:Scikit-Learn是基于python语言的机器学习工具。它是建立在Numpy、Scipy、Panda和Matplotlib之上。
Scikit-learn库的算法主要是四类:分类、回归、聚类、降维。
常用的回归:线性回归、决策树回归
常用的降维:K均值、层次聚类
常用的聚类:K均值
常用的降维:线性判别分析
导入工具包:从库中导入包 这里都是scikit-learn库 简写:sklearn。
基本建模的符号标记随便看一看理解。
结构化记忆:from sklearn库 import
from sklearn import 包名称
from sklearn .库名称 import 包名称
#导入数据集 数据预处理库
from sklearn import datasets,preprocessing
#从模型选择库导入数据切分包
from sklearn .model_selection import train_test_split
#从线性模型库导入线性回归包
from sklearn .linnner_model import LinearRegression
#从评价指标库导入R2评价指标
from sklearn .metrics import r2 score
P51
可以直接使用的自带数据集
顾名思义意思就是,给你补充的多的数据集可以直接用的

load_boston 波士顿房屋价格
load_digits 手写字
load_iris 鸢尾花
P53
咱们可以品一品书上的代码,因为python属于弱类型语言,不必声明变量的类型

关键点总结
- 数据结构:
iris.data是特征矩阵(二维数组),iris.target是标签向量(一维数组)。 - 用途:这种分离是机器学习的标准操作,便于后续进行模型训练和预测。
- 命名约定:
X和Y是通用符号,也常用features和labels等更具描述性的名称。
机器学习的数据集可以划分为测试集、验证集、训练集。
也可以划分为训练集、测试集。
P54
这里我把代码敲一敲,有个印象即可。。。
# 数据预处理
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,Y,random_state=12,stratify=y,test_size=0.3)
#将完整数据集70%作为训练集,30%作为数据集,并使得测试集和训练集中各类别数据的比例与原始数据集比例一致
from Flower_Classic import X_train
#自己总是会蹦上去这行
from sklearn.preprocessing import StandardScaler
# 数据变换操作
scaler =StandardScaler();
#拟合及转换
scaler.fit_transform(X_train)最大最小标准化:MinMaxScaler
缺失值填补:Imputer
监督学习算法——回归
线性回归是一种通过属性的线性组合来进行预测的线性模型,目的是找到一条直线或一个平面或更高维的超平面,使预测值与真实值之间的误差最小化。
库 大概要写成:from sklearn.linear_model import Ridge
线性回归:
岭回归:
LASSON回归:
ElasticNet回归:这里大家可以把这些英文单词背下来去对照我这里
决策树回归:tree.DecisionTreeRegressor
代码实现流程是,引入库包,构建模型,训练模型,做出预测
from sklearn.linear_model import LinearRegression
lr=LinearRegression(normalize=true)
lr.fit(x_train,y_train)
y_pred=lr.predict(X_test)监督学习-分类
要知道有逻辑回归、支持向量机、KNN、GBDT
聚类算法:K-means
评价指标:P58
反正我也搞不懂我想问真的会考吗?
P133 C4.5 :简称C4.5比ID3好,好在哪里!
ID3算法的核心思想就说以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。ID3算法有以下缺点:
1.ID3没有减枝策略,容易过拟合
2.信息增益准则对可取值数目较多的特征有所偏好。
3.只能用于处理离散分布的特征
4.没有考虑缺失值
C4.5算法概述:C4.5是对ID3算法的改进。
主要改进如下:
1.ID3选择属性用的是子树的信息增益,C4.5算法最大的特点是克服了ID3对特征数目的偏重这一缺点,引入了信息增益率来作为分类标准
2.在决策树构造过程中进行剪枝,引入悲观剪枝策略进行后剪枝。
3.对非离散数据也能处理。
4.能够对不完整数据进行处理。
学习通作业2 填空题
# (1) 字符串操作
str = 'the National Day'
print(str[4:10]) # 提取'nation'
# (2) 列表操作
lst = ['the', 'National', 'Day']
print(lst[1]) # 提取'national'
# (3) 元组操作(元组不可变,需修改内部可变对象)
tpl = (['10.1','is','the'],'National','Day')
tpl[0][0] = 'Today' # 修改列表元素
print(tpl)
# (4) 字典操作
Hotel = {'name':'J Hotel','count':35,'price':162}
Hotel['count'] = 36 # 修改值
print(Hotel)
# (5) 集合操作
Htls = {'A Hotel', 'B Hotel', 'C Hotel'}
result = 'E Hotel' in Htls # 检查存在性
print(result)
混淆矩阵
打开书本106 静下心多看一会儿书 很快就能学会 你会发现准确率就是对角线上的数除以所有的数,这是很容易学会的。也就是视频里面的薄荷绿颜色。
【小萌五分钟】机器学习 | 混淆矩阵 Confusion Matrix_哔哩哔哩_bilibili

假如有一个A类机器,能够识别是不是汉堡,我们要估算这个机器的准确率,用这样的图片表示显然不能直观看到评价指标,那么我们使用这样的混淆矩阵图就可以表示了
| 预测值 | |||
| 真实值 | 是汉堡 | 不是汉堡 | |
| 是汉堡 | 1 | 2 | |
| 不是汉堡 | 2 | 5 |
感觉就是挺奇妙的,一个小表居然把所有的情况都列出来了。而且所有数加起来就是样本数!
太久没有这样的逻辑思维,我认为这样的知识是十分奇妙的!我乐于学习这样神奇的知识!
而且,我们想知道机器预测的准不准,就只需要看他做得对不对!真实是汉堡,预测出来也是汉堡!真实不是汉堡,预测出来也不是汉堡!就是准的!所以一整个对角线上,1+5就是准确的情况。所以准确率就是60%。
我们再结合,结合书本106的公式。
作业十五
请以对手写数字体分类问题为背景出一个基于混淆矩阵计算分类精度的练习题目。 在手写数字识别任务中,我们训练了一个分类模型对测试集(共 100 个样本)进行预测。数据集包含数字 0~9 共 10 个类别。模型的预测结果由以下混淆矩阵表示(部分数据已省略,仅显示部分行和列): 真实 \ 预测 0 1 2 3 4 5 6 7 8 9 0 9 0 0 0 0 0 0 0 1 0 1 0 11 0 0 0 0 0 0 0 0 2 0 1 8 0 0 0 0 1 0 0 3 0 0 0 10 0 1 0 0 0 0 4 0 0 0 0 9 0 0 0 0 1 5 0 0 0 1 0 8 0 0 1 0 6 0 0 0 0 0 0 10 0 0 0 7 0 0 1 0 0 0 0 9 0 0 8 0 0 0 0 1 0 0 0 8 1 9 0 0 0 0 0 0 0 1 0 9 问题: 1). 计算模型的整体分类精度(Accuracy)。 2). 计算数字 3 和数字 8 的分类错误率(Misclassification Rate)。 3). 哪个数字的分类效果最好?哪个数字的分类效果最差?请说明原因。
我们基于以上的认识,就能很快做出第一问和第三问。
老师真是的,也不给咱们列个表格,不知道考试的时候是不是还得自己画,粗心画错咋办。


作业16
好我看了一眼完全都是程序填空题。芭比Q!烤肉。
永不起祈求平坦的路,而是拥有应对困难的力量.
写在本子上多记记吧。
KD树划分
这个知识,我二分查找树还是学得不错的。但是相比二分查找又有些出入。二分查找树是找左子树右子树中间值,偶数列的时候是取左边的值作为根节点。
但是KD树是二维的,而且偶数列的时候取的是中位数的值,也就是右边的值,首先给X轴排序,再以X轴,Y轴,X轴,Y轴来划分。咱们可以让豆包给出一组坐标然后我们画在本子上让豆包检查。