参考
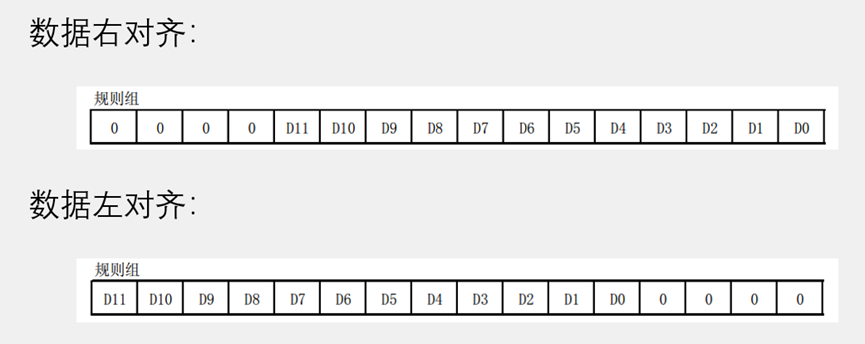
- 包括窗口函数在内的执行顺序
from & join --确定数据源
where --行级过滤
group by --分组
having --组级过滤
窗口函数 --计算窗口函数结果
select --选择列
distinct --去重
order by --最终排序(可对窗口函数结果进行排序)
limit/offset --分页
- 将多行数据按照规则聚集为一行,称为聚集函数,如sum()、avg()、max()等;
- 既要显示聚集前的数据,又要显示聚集后的数据,即为窗口函数,兼具分组和排序功能。
- sum()、avg()、min()、max()函数和窗口函数结合使用:
--c1,分组内从起点到当前行的c累积
select
a,b,c,
sum(c) over(partition by a order by b) as c1
from bigdata_t1
--c2,同c1
select
a,b,c,
sum(c) over(partition by a order by b rows between unbounded preceding and current row) as c2
from bigdata_t1
--c3,分组内所有的c累积
select
a,b,c,
sum(c) over(partition by a) as c3
from bigdata_t1
--c4,分组内当前行+往前3行
select
a,b,c,
sum(c) over(partition by a order by b rows between 3 preceding and current row) as c4
from bigdata_t1
--c5,分组内当前行+往前3行+往后1行
select
a,b,c,
sum(c) over(partition by a order by b rows between 3 preceding and 1 following) as c5
from bigdata_t1
--c6,分组内当前行+往后所有行
select
a,b,c,
sum(c) over(partition by a order by b rows between current row and unbounded following) as c6
from bigdata_t1
- 如果不指定rows between(又称为window子句),默认为从起点到当前行;
- 如果不指定order by,则将分组内所有值累加。
- row_number()、rank()、dense_rank()、ntile函数
- 排序函数row_number()、rank()、dense_rank(),从1开始,按照顺序,生成分组内记录的序列。
select
a,b,c,
row_number() over(partition by a order by b desc) as rn1,--按顺序分配唯一行号,相同值也分配不同序号
rank() over(partition by a order by b desc) as rn2,--相同值排名相同,后续排名跳号
dense_rank() over(partition by a order by b desc) as rn3--相同值排名相同,后续排名不跳号
from
bigdata_t1
- ntile函数
select
a,b,c,
ntile(2) over(partition by a order by b) as rn1,--分为2桶
ntile(3) over(partition by a order by b) as rn2,--分为3桶
ntile(4) over(order by b) as rn3--分为4桶
from
bigdate_t1
ntile可以看成是:
- 把有序的数据集合平均分配到指定数量个桶中,将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1.
- 然后可以根据桶号,选取前或后n分之几的数据,数据会完整展示出来,只是给相应的数据打标签;具体要取几分之几的数据,需要再嵌套一层根据标签取出。
- 其他一些窗口函数:lag,lead,first_value,last_value函数
- lag(col,n,default)用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行,第三个参数为默认值(当往上第n行为null时,取默认值,如不指定,则为null)。
select
a,b,c,
lag(b,1,'1970-01-01 00:00:0') over(partition by a order by b) as last_1_b,
lag(b,2) over(partition by a order by b) as last_2_b
from
bigdata_t4
- lead(col,n,default)用于统计窗口内往下第n行值。
select
a,b,c
lead(b,1,'1970-01-01 00:00:00') over(partition by a order by b) as next_1_b,
lead(b,2) over(partition by a order by b) as next_2_b
from bigdata_t4
- first_value(col)取分组内排序后,截止到当前行,第一个值
select
a,b,c,
first_val(c) over(partition by a order by b) as first_c
from
bigdata_t4
- last_value(col)取分组内排序后,截止到当前行,最后一个值
select
a,b,c,
last_value(c) over(partition by a order by b) as last_b
from
bigdata_t4
上述俩函数如果用desc倒序排序,则first_value取的是最后一个值,last_value取的是第一个值。
5. 序列分析函数,不支持window子句
- cume_dist(),小于等于当前值的行数/分组内总行数(小于等于当前行所占比例);order默认顺序为升序
select
a,b,c,
cume_dist() over(order by c) rn1,--所有小于等于当前行的c所占比例
cume_dist() over(partition by a order by c) as rn2--所有a分组中小于等于当前行c所占比例
from
bigdata_t3
- percent_rank(),分组内当前行的rank值-1/分组内总行数-1
select
a,b,c,
percent_rank() over(order by c) as rn1,
rank() over(order by c) as rn11,--分组内rank值
sum(1) over(partition by null) as rn12,--分组内总行数
percent_rank() over(partition by a order by c) as rn2
from
bigdata_t3
--rn1 = (rn11 - 1)/(rn12 - 1),因为未设置分组,故为总的百分比
--rn2:按a的分组将上述公式的rn11和rn12都替换为分组内
- grouping sets,grouping_id,cube,rollup函数,通常用于OLAP中,不可累加
- grouping sets是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同维度的group by结果集合进行union all
select
col1,col2,sum(col3)
from
bigdata_t3
group by grouping sets(
(col1,col2), --组合1
(col1), --组合2
(col2), --组合3
() --总计行
)
- cube,生成所有可能的分组组合(幂集),是grouping sets的快捷方式。
select
col1,col2,sum(col3)
from
bigdata_t3
group by cube(col1,col2)
--等价于
group by grouping sets(
(col1,col2), --组合1
(col1), --组合2
(col2), --组合3
() --总计行
)
- rollup,生成层次化的分组组合(从最详细到最汇总),适用于有层次结构的数据。
select col1,col2,sum(col3)
from
bigdata_t3
group by rollup(col1,col2)
--等价于
group by grouping sets(
(col1,col2), --层次1
(col1), --层次2
() --总计行
)
- grouping(col1)和grouping_id(col1,col2,…):标识结果行是由哪个分组集生成的。区分真实null和聚合产生的null。如果col1在分组组合内则返回0,如果不在分组组合内则返回1.