问题概述
最近我的测试服务器借给客户用作临时中转,仅更改了ESXi的管理IP,设备拿回来改回原来IP,vCenter开启后重新接收证书,主机和所有VM管理运行正常,跑着跑着发现主机和vCenter会频繁断开连接后又马上自动恢复,间隔恰好为一分钟
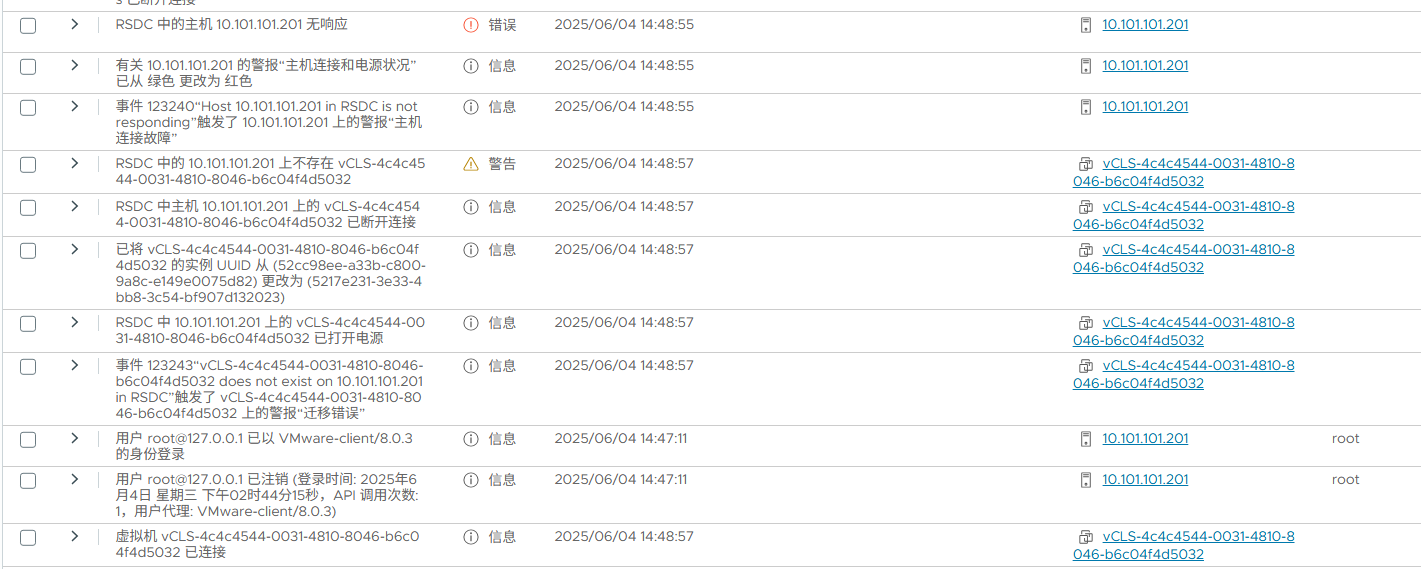
经过初步排查掉网络原因,集群配置原因等(包括重启,重新添加主机)过后,把问题基本先定位在vCenter和ESXi之间的存活检测上,并开始逐步排查修复
排查流程
问题分析:
当vCenter Server与ESXi主机之间的检测信号(Heartbeat)数据包因被丢弃、阻止或传输失败而丢失时,会导致主机从vCenter清单中断开连接
检测机制如下:
- 默认情况下,ESXi主机通过UDP 902端口以固定间隔向vCenter Server发送检测信号数据包(频率为每10秒1次)
- vCenter Server需持续接收这些数据包以确认主机在线状态。若连续丢失6个检测信号包(即60秒未收到响应),vCenter会判定主机离线,并将其从清单中移除,直至通信恢复
本身vCenter和ESXi管理地址都在同一网段,VCSA的VM与ESXi的管理Kernal也都在同一物理网卡上,同时外部ping两边都正常,所以先通过主机和VC之间探测UDP 902的包是否能正常通信,发现确实无法正常通信
[root@RS-ESXi01:~] tcpdump-uw dst host 10.101.101.200 and udp port 902
tcpdump-uw: verbose output suppressed, use -v[v]... for full protocol decode
listening on vmk0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
0 packets captured
0 packets received by filter
0 packets dropped by kernel
查看vCenter的IP正常
root@rsvc [ ~ ]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:0c:29:a2:5f:2b
inet addr:10.101.101.200 Bcast:10.101.101.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1527 errors:0 dropped:0 overruns:0 frame:0
TX packets:658 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:361918 (361.9 KB) TX bytes:1096029 (1.0 MB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:195097 errors:0 dropped:0 overruns:0 frame:0
TX packets:195097 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:235667102 (235.6 MB) TX bytes:235667102 (235.6 MB)
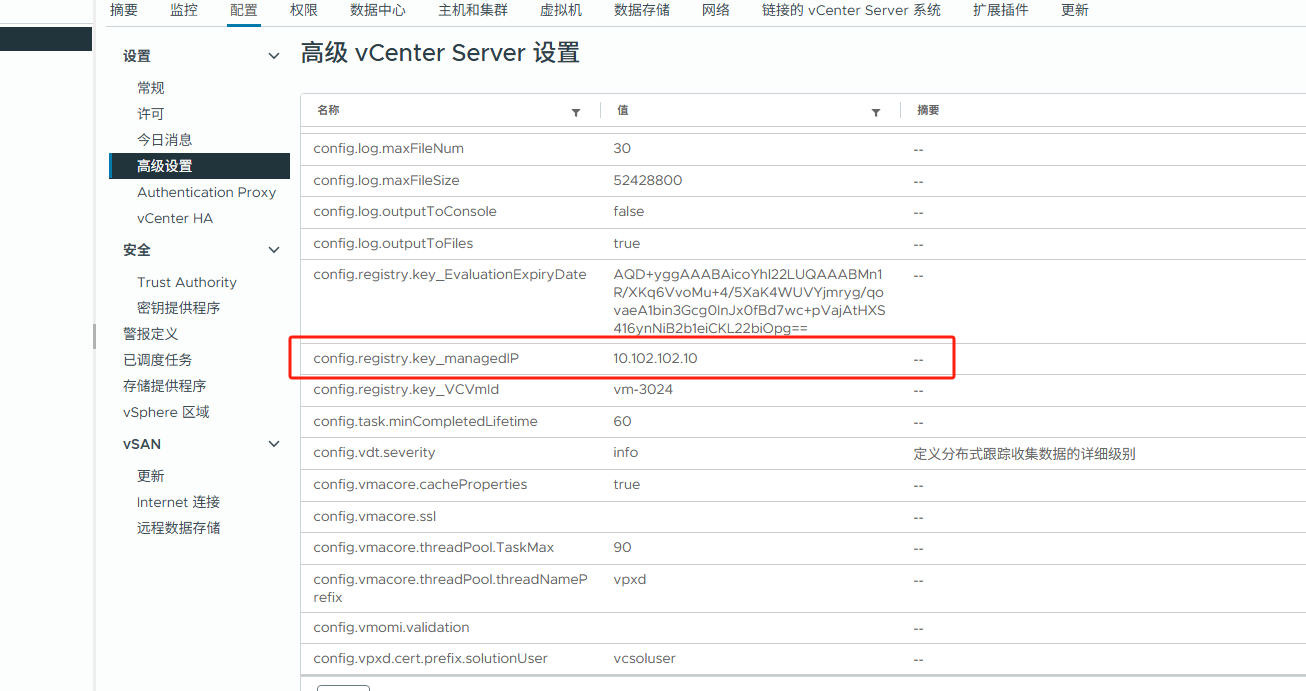
此时进入vCenter的高级设置中,发现manageIP一项的参数内的IP与vCenter的真实IP不一致!此IP为另一网段的一台跳板机IP,知道最后也无法理解为何会出现在这边,唯一能稍微有点联系的是一周前曾测试了vCenter的防火墙策略,把这个IP作为除ESXi管理IP之外的一个白名单IP,后续也已全部删除o(╥﹏╥)o
那不管怎样,这边既然不正常了那先改回真实的vCenter IP
完成等SSH登录主机,通过以下命令看到主机指向的Server_IP确实也不正确
#确认当前主机Server_IP
[root@RS-ESXi01:~] configstorecli config current get -c esx -g services -k vpxa_solution_user_config |grep -i server_ip
"server_ip": "10.102.102.10",
通过命令修改
#手动更改ESXi的Server_IP为实际的vCenter IP
[root@RS-ESXi01:~] configstorecli config current set -c esx -g services -k vpxa_solution_user_config --path /server_ip --value "10.101.101.200"
Set: completed successfully
#确认更改正常
[root@RS-ESXi01:~] configstorecli config current get -c esx -g services -k vpxa_solution_user_config |grep -i server_ip
"server_ip": "10.101.101.200",
#重启服务
[root@RS-ESXi01:~] /etc/init.d/vpxa restart
vpxa stopped.
vpxa started.
完成后发现问题仍然存在,回到主机查看server_ip又自动改回之前的错误IP
继续查找高级设,其中AutoManagedIPV4一项仍为错误IP,会继续使用这个错误IP与ESXi发送检测信号,并且此处在高级设置内为灰色,无法直接进行修改
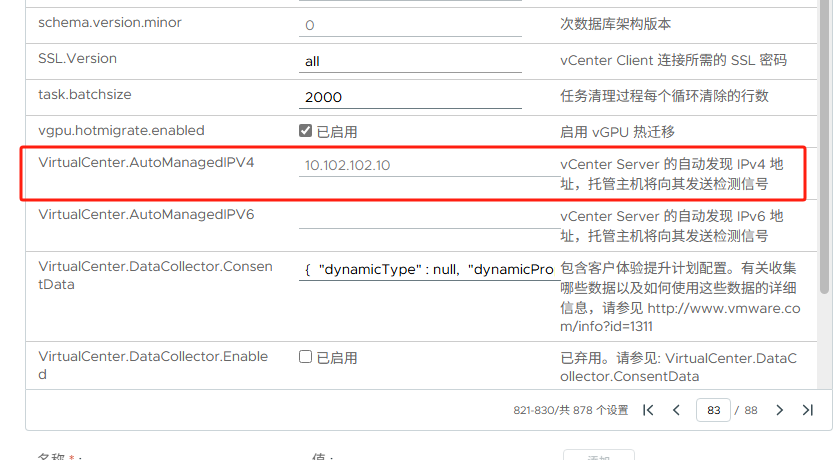
在vCenter的常规设置,运行时(RunTime)设置内,可编辑更改该IP
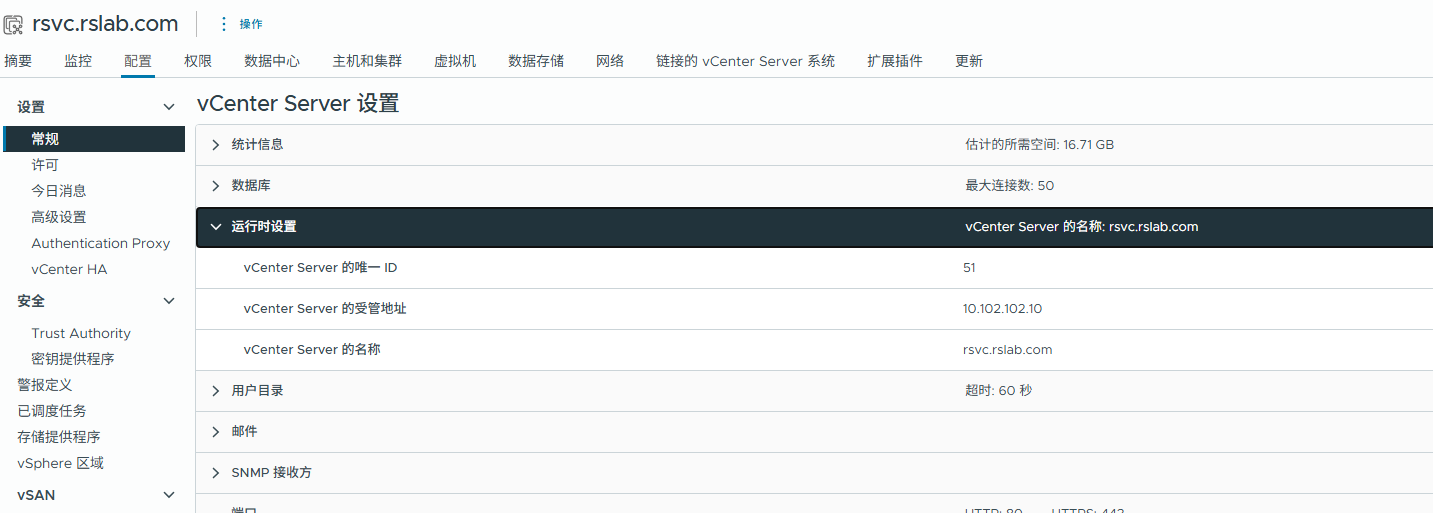
完成更改后保存并重启vCenter
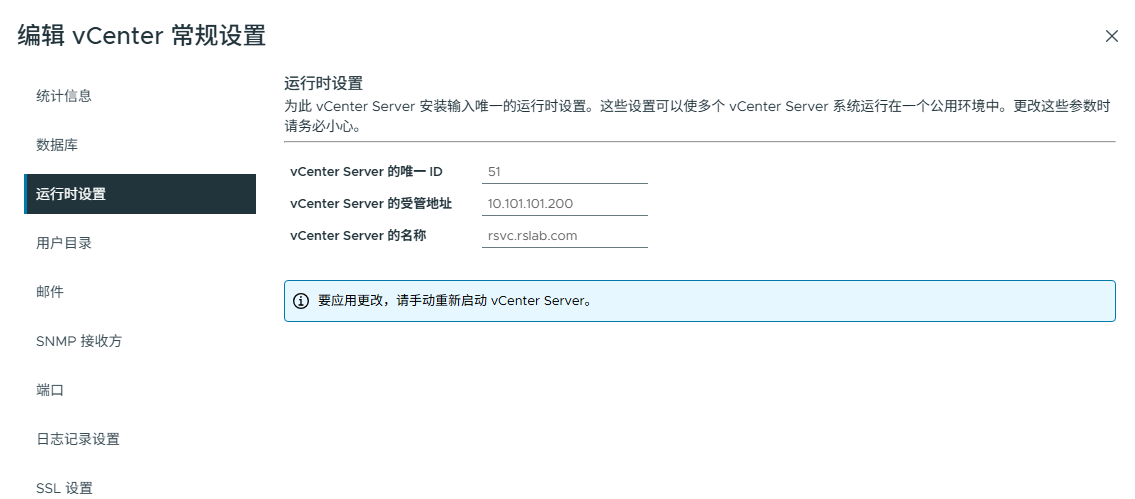
最后问题解决,UDP 902的包也测试正常
[root@RS-ESXi01:~] tcpdump-uw dst host 10.101.101.200 and udp port 902
tcpdump-uw: verbose output suppressed, use -v[v]... for full protocol decode
listening on vmk0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
09:25:21.937771 IP RS-ESXi01.47969 > 10.101.101.200.902: UDP, length 336
09:25:31.944580 IP RS-ESXi01.23086 > 10.101.101.200.902: UDP, length 336
09:25:41.950656 IP RS-ESXi01.52895 > 10.101.101.200.902: UDP, length 336
09:25:51.956734 IP RS-ESXi01.37494 > 10.101.101.200.902: UDP, length 336
09:26:01.962682 IP RS-ESXi01.36495 > 10.101.101.200.902: UDP, length 336
5 packets captured
5 packets received by filter
0 packets dropped by kernel
小结
其实到最后也没排查到问题发生的根本原因,整体来说,本篇文章适用于以下情况:
vCenter与ESXi主机的周期性断连,造成的原因包括但不限于:
- 更改了vCenter的IP (主要)
- 配置过vCenter的防火墙规则
- ESXi主机来回更改过管理IP
- 其他未知原因
参考KB:
1.https://knowledge.broadcom.com/external/article/323612/esxi-host-disconnects-from-vcenter-serve.html
2.https://knowledge.broadcom.com/external/article?legacyId=1001493
3.https://knowledge.broadcom.com/external/article/316377/verifying-the-vcenter-server-managed-ip.html
4.https://knowledge.broadcom.com/external/article/318647/esxi-host-disconnects-intermittently-fro.html
5.https://knowledge.broadcom.com/external/article/337654/changing-vcenter-server-ip-address-cause.html


![[ Qt ] | 与系统相关的操作(一):鼠标相关事件](https://i-blog.csdnimg.cn/direct/5a438c4ede9445b2bbe3a948bbe5577d.png)