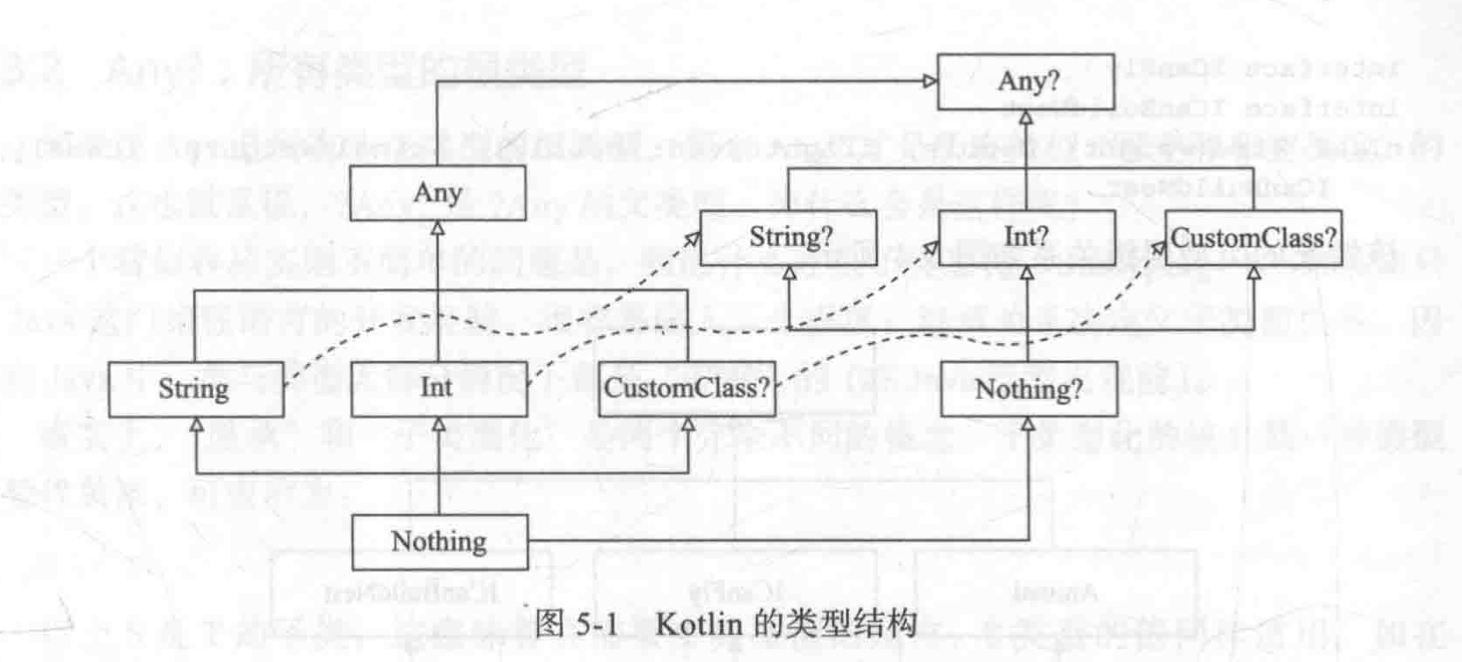
Adobe 提供了多种方案可以快速提取 PDF 文件中的文字以及图片中的文字,主要依赖其 Acrobat 系列产品和 OCR(光学字符识别)技术。以下是具体解决方案的概述,涵盖了文字和图片文字的提取方法:
1. 提取 PDF 中的文字
如果 PDF 文件本身包含可编辑的文字(即非扫描件或图片生成的 PDF),Adobe Acrobat 提供了直接提取文字的功能:
使用 Adobe Acrobat Pro 或 Acrobat Standard:
1. 打开 PDF 文件。
2. 使用“选择工具”(Select Tool)选中需要提取的文字。
3. 右键点击选中文字,选择“复制”(Copy),然后粘贴到其他应用程序(如 Microsoft Word、记事本等)。
4. 或者,点击“文件” > “另存为”(Save As),选择导出为 TXT、DOCX 或其他格式,将整个文档的文字提取出来。[](https://www.nucleustechnologies.com/blog/extracttextfrompdffile/)
批量导出:
如果需要提取整个 PDF 的文字,可以通过“文件” > “另存为” > 选择“文本(纯文本)”或“Microsoft Word 文档”来导出所有文字内容。[](https://helpx.adobe.com/acrobat/using/exportingpdfsfileformats.html)
2. 提取图片中的文字(基于 OCR 技术)
对于扫描的 PDF 或包含图片的 PDF(即图片中的文字),Adobe Acrobat 提供了强大的 OCR 功能来识别和提取文字:
使用 Adobe Acrobat Pro 的 OCR 功能:
1. 打开 PDF 文件。
2. 进入“工具”(Tools) > “增强扫描”(Enhance Scans)或“扫描与 OCR”(Scan & OCR,视版本而定)。
3. 选择“识别文本”(Recognize Text) > “在此文件中”(In This File)。
4. 设置语言(支持多种语言,包括中文),点击“确定”运行 OCR。
5. OCR 完成后,文字变为可编辑状态,可以直接选中、复制并粘贴到其他文档中,或者导出为 Word、TXT 等格式。[](https://www.cisdem.com/resource/extracttextfrompdfimage.html)[](https://help.illinoisstate.edu/accessibility/websiteanddigital/pdfaccessibilitywithadobeacrobatpro/convertanimageonlypdfwithtextrecognitioninadobeacrobatpro)
使用 Adobe Scan 移动应用:
1. 使用 Adobe Scan 应用(支持 iOS 和 Android)扫描纸质文档或图片。
2. 应用会自动运行 OCR,识别图片中的文字。
3. 扫描完成后,可以选择提取文字,编辑或分享到其他应用程序。[](https://www.adobe.com/uk/acrobat/resources/howtoextracttextfromimage.html)
Adobe Acrobat 在线服务:
1. 访问 Adobe Acrobat 在线工具(如 JPG to PDF 工具,支持多种图片格式如 PNG)。
2. 将图片上传并转换为 PDF,部分情况下 Acrobat 会自动识别图片中的文字。
3. 如果未自动识别,可下载 PDF 后使用 Acrobat Pro 或其他 OCR 工具进一步处理。[](https://www.adobe.com/acrobat/hub/howimagetextextractionhelpsstudents.html?msockid=3276904a2dcc6e5b276e85e62c646f87)
3. 使用 Adobe PDF Extract API(开发者方案)
对于需要自动化或批量提取 PDF 中文字和图片文字的场景,Adobe 提供了 PDF Extract API,适合开发者集成到应用程序中:
功能:通过 Adobe Sensei AI 技术,提取 PDF 中的文字、表格、图片等内容,并以结构化 JSON 格式输出。支持扫描和非扫描 PDF,自动识别文字、字体、样式和阅读顺序。
优势:无需手动训练机器学习模型,适合复杂文档处理,适用于 RPA(机器人流程自动化)或 NLP(自然语言处理)工作流。
使用方法:
1. 注册 Adobe 开发者账户,获取 API 密钥。
2. 将 PDF 文件上传至 API,API 会返回包含文字和结构化数据的 JSON 文件。
3. 可选择将图片提取为 PNG 格式,文字提取为可编辑内容。[](https://developer.adobe.com/documentservices/apis/pdfextract/)
免费额度:每月提供 500 次免费文档处理,适合测试或小规模使用。
4. 提取 PDF 中的图片
若 PDF 中包含图片,Adobe Acrobat 也支持提取图片,方便后续处理:
手动提取:
1. 打开 PDF,点击图片,右键选择“复制”(Copy)。
2. 粘贴到图片编辑软件(如 Photoshop)或直接保存为 JPEG/PNG 格式。
批量提取:
1. 在 Acrobat 中选择“工具” > “导出 PDF”(Export PDF)。
2. 选择导出为图片格式(如 JPEG 或 PNG)。
3. 勾选“导出所有图片”(Export all images),即可将 PDF 中的所有图片提取为单独文件。[](https://www.adobe.com/acrobat/hub/howtoextractimagesfrompdf.html)
提取后处理:提取的图片可进一步通过 Adobe Scan 或 Acrobat 的 OCR 功能识别其中的文字。
5. 注意事项与优化建议
图片质量:OCR 效果依赖于图片质量。确保图片清晰、光线良好、文字无遮挡。低分辨率或复杂排版(如文字与图形混杂)可能影响识别准确性。[](https://www.adobe.com/acrobat/hub/useocrtoreadtextfromimage.html)
语言支持:Adobe 的 OCR 支持多种语言,包括中文,但需在设置中选择正确的语言以提高识别准确率。
成本:Adobe Acrobat Pro 和 API 服务需要订阅,免费版功能有限。如果预算有限,可考虑在线工具(如 Google Docs)或第三方软件(如 UPDF、PDFgear),但功能和准确性可能不如 Adobe。[](https://www.pdfgear.com/pdfeditorreader/howtocopytextfrompdfimage.htm)[](https://updf.com/ocr/extracttextfrompdfwithandwithoutocr/)
隐私与安全:对于敏感数据,建议使用 Adobe 的离线软件或 API,避免上传到不可信的在线工具。[](https://www.nucleustechnologies.com/blog/extracttextfrompdffile/)
6. 替代方案
虽然 Adobe 的解决方案功能强大,但成本较高。如果需要更经济的选择,可以考虑:
Google Drive:上传图片或 PDF 至 Google Drive,右键选择“用 Google Docs 打开”,即可提取文字(格式可能不完美)。[](https://www.adobe.com/acrobat/hub/howimagetextextractionhelpsstudents.html?msockid=3276904a2dcc6e5b276e85e62c646f87)
UPDF:支持 OCR 和文字提取,价格更低,跨平台支持(Windows、Mac、iOS、Android)。[](https://updf.com/ocr/extracttextfrompdfwithandwithoutocr/)
PDFgear:提供免费的 OCR 功能,支持批量处理,适合 Windows 和 Mac 用户。[](https://www.pdfgear.com/pdfeditorreader/howtocopytextfrompdfimage.htm)
开源工具:如 MinerU(由上海人工智能实验室开发),支持 PDF 文字、图片、表格和 LaTeX 公式的提取,适合技术用户。
总结
Adobe 提供了全面的 PDF 文字和图片文字提取方案:
简单需求:使用 Acrobat Pro 或 Acrobat 在线工具,通过复制粘贴或导出功能提取文字。
图片文字提取:借助 Acrobat 的 OCR 功能或 Adobe Scan 应用,快速识别图片中的文字。
自动化需求:使用 PDF Extract API,适合批量处理或集成到工作流中。
注意:确保图片质量高、选择正确语言,并根据需求权衡成本与功能。如果需要更经济或开源的替代方案,可以参考 Google Drive、UPDF 或 MinerU。




![洛谷P12610 ——[CCC 2025 Junior] Donut Shop](https://i-blog.csdnimg.cn/img_convert/61abfa2405c3559aeeafde74066a1a3a.png)





![[蓝桥杯]对局匹配](https://i-blog.csdnimg.cn/direct/e84955877a0b483b8f81d4a106cf4489.png)