GQA(Grouped Query Attention)是近年来在大语言模型中广泛应用的一种注意力机制优化方法,最初由 Google 在 2023 年提出。它是对 Multi-Query Attention (MQA) 的扩展,旨在平衡模型性能与计算效率。
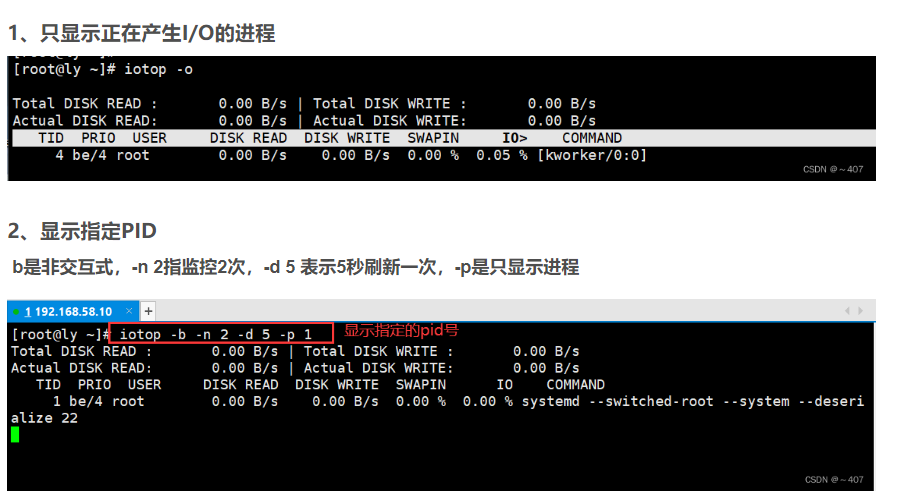
🌟 GQA 是什么?
简单定义:
GQA 是一种将查询头(Query Heads)分组,并共享键(Key)和值(Value)头的注意力机制变体。
它试图在 标准的多头注意力(MHA) 和 多查询注意力(MQA) 之间找到一个折中点:
| 注意力类型 | Query Heads | Key/Value Heads | 共享情况 |
|---|---|---|---|
| MHA | 多个 | 多个 | 不共享 |
| GQA | 多个 | 少于 Query 的多个 | 分组共享 |
| MQA | 多个 | 1 | 完全共享 |
🧠 原理详解
1. 回顾标准 Multi-Head Attention (MHA)
在标准的 Transformer 中:
- 每个 token 的
Q、K、V都是由输入线性变换得到。 - 如果有
H个 attention heads,则每个 head 都有自己的Q、K、V向量。
公式如下:
Q = X W Q , K = X W K , V = X W V Q = XW_Q, \quad K = XW_K, \quad V = XW_V Q=XWQ,K=XWK,V=XWV
其中 $ W_Q, W_K, W_V $ 是可学习参数。
每个 head 的 Q/K/V 是从这些矩阵中切出来的。
2. 引入 GQA:Query 分组 + Key/Value 共享
在 GQA 中:
- Query heads 被分成若干组(比如 4 组)
- 每组共享一组 Key 和 Value 向量(即每组对应一个 K 和 V)
例如:
- 总共 32 个 query heads
- 分成 4 组,每组 8 个 heads
- 每组使用相同的 Key 和 Value 向量
- 所以只需要 4 组 K/V,而不是 32 组
这样做的好处是:
- 减少了 Key/Value 的数量,降低了内存占用(尤其是 KV Cache)
- 保留了比 MQA 更多的表达能力
⚙️ GQA 的优势
| 优势 | 描述 |
|---|---|
| ✅ 推理速度更快 | 更少的 Key/Value 向量意味着更小的 KV Cache,减少解码时的内存访问延迟 |
| ✅ 内存占用更低 | 特别是在批量生成或长文本生成时,KV Cache 占用显著降低 |
| ✅ 比 MQA 表现更好 | 相比完全共享 Key/Value 的 MQA,GQA 保留了部分多样性,模型表现通常更优 |
| ✅ 适合部署 | 对硬件资源友好,特别适合在有限算力设备上运行的大模型 |
🔍 示例说明(来自 Llama 3)
Llama 3 使用了 GQA 技术来提升推理效率。
- 总共 32 个 query heads
- 只使用了 8 个 key/value heads(即每组 4 个 queries 共享一个 key/value)
这意味着:
- 每个 group 包含 4 个 query heads
- 这些 query 共享同一个 key 和 value
这样可以保持大部分 MHA 的表达能力,同时节省内存和计算开销。
📈 MHA vs GQA vs MQA 性能对比(大致)
| 指标 | MHA | GQA | MQA |
|---|---|---|---|
| 表达能力 | 最强 | 中等 | 最弱 |
| 推理速度 | 较慢 | 快 | 最快 |
| 内存占用(KV Cache) | 最高 | 中等 | 最低 |
| 部署友好度 | 一般 | 高 | 最高 |
🧩 应用场景
GQA 特别适用于以下场景:
- 大模型推理优化(如 Llama 3、PaLM 2、Gemini Nano)
- 移动端/边缘端部署
- 需要长上下文处理的任务
- 大批量生成任务
💡 总结
| 项目 | GQA |
|---|---|
| 类型 | 注意力机制变体 |
| 核心思想 | Query 分组 + Key/Value 共享 |
| 优点 | 提升推理速度、降低内存消耗、兼顾模型表现 |
| 缺点 | 表达能力略低于 MHA |
| 应用 | 大语言模型部署、高效推理系统 |






![[蓝桥杯]图形排版](https://i-blog.csdnimg.cn/direct/b88570d063f646e7bdc5011519d44a5f.png)