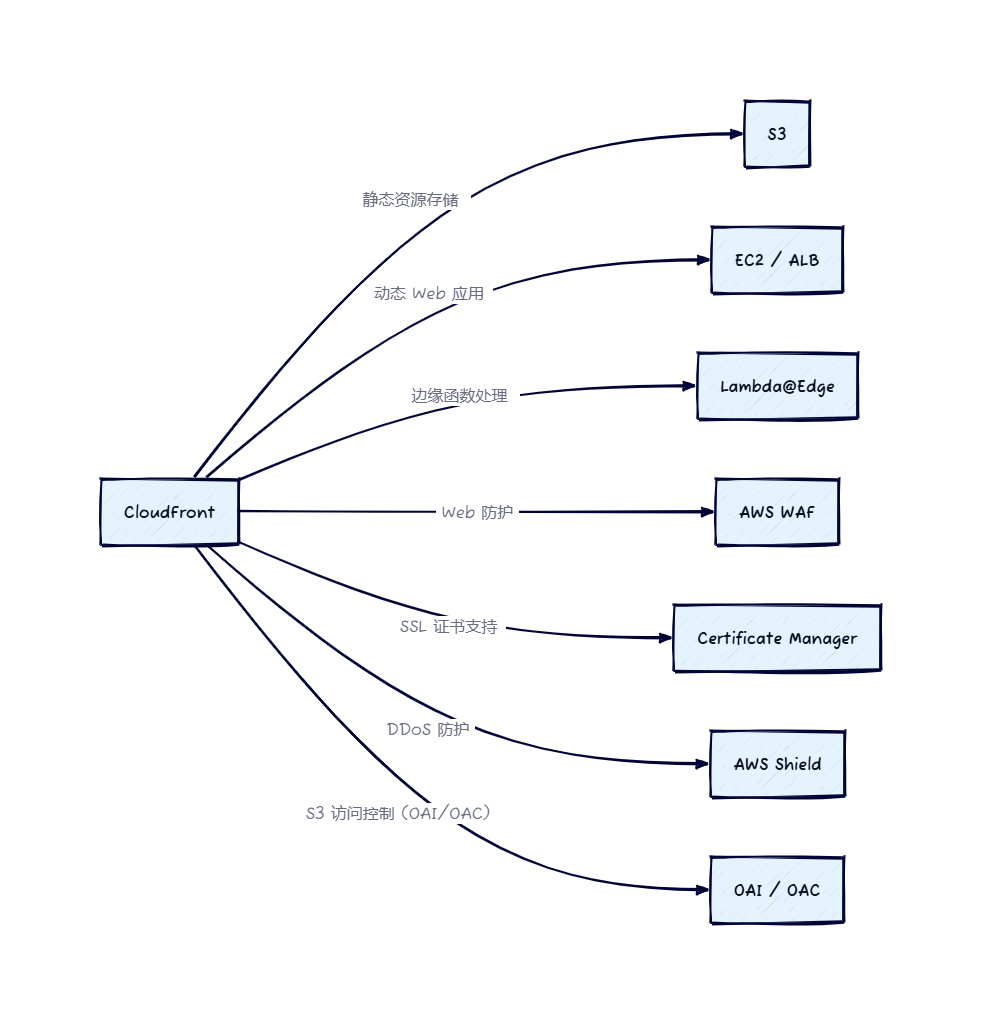
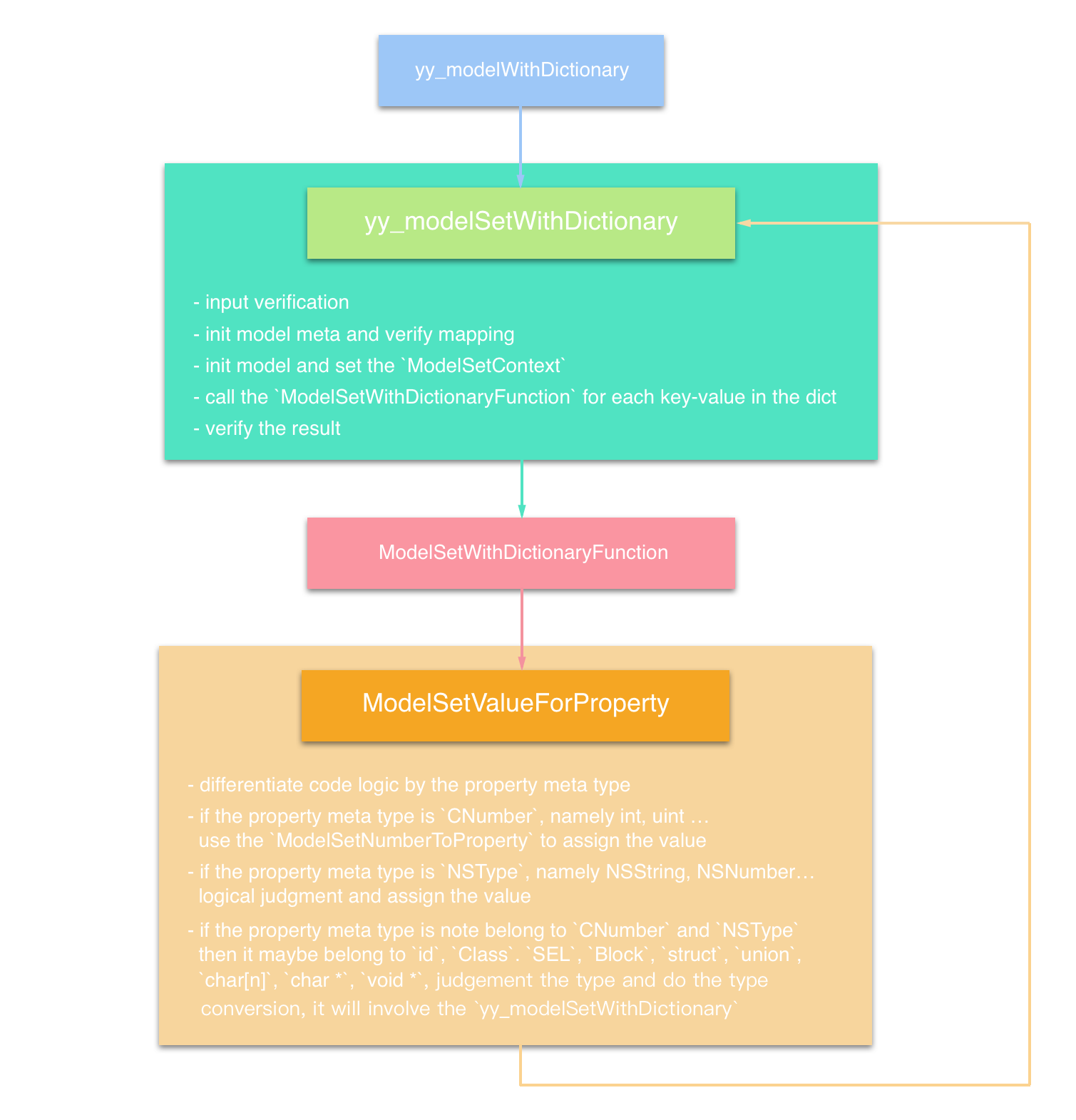
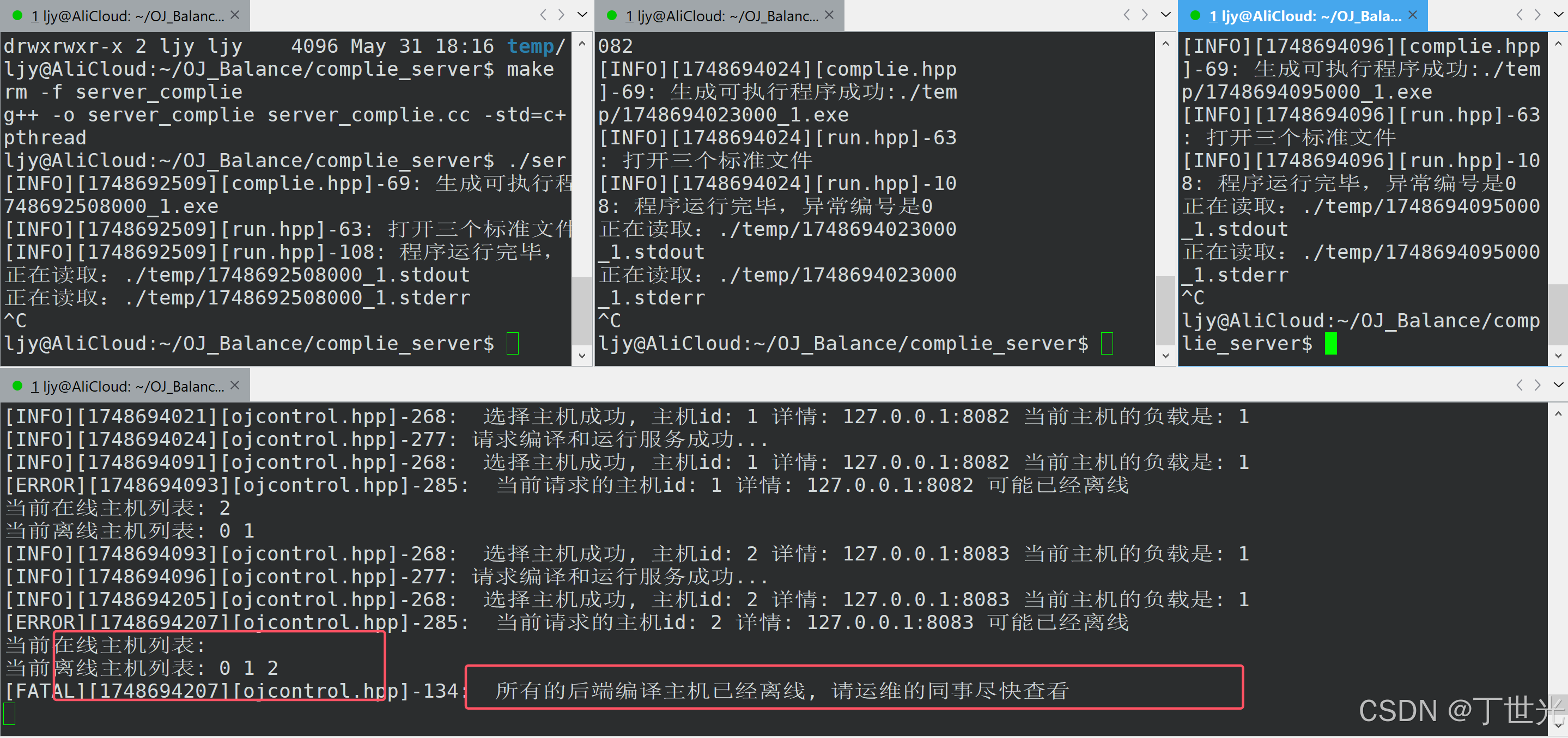
关于性能问题与调试传统 bug(如段错误)之间差异的分析。以下是对这一页内容的详细解释:
主题:传统问题(如段错误)调试流程清晰
问题类型:段错误(Segmentation Fault)
这种问题的特点是:
- 确定性强:大部分时候,问题在同样的输入和运行环境下是可复现的(不包括竞争条件等特殊情况)。
- 结果是明确的:测试阶段会给出一个清晰的答案 —— “修复了”或 “仍然崩溃”。
解决流程:一个典型的调试循环
- Analyze 分析
使用工具(如 gdb、Valgrind 等)定位问题的根源。 - Implement 实现修复
编写可能的修复方案(通常是小的代码更改)。 - Test 测试验证
重跑测试,验证问题是否已解决。 - 可能回退
如果修复方案没效果,可以回滚更改,尝试其他方案。
工具支持
- 这类 bug 工具支持好(比如调试器)。
- 工程师拥有一整套成熟的工作流去应对这种问题。
- 反馈快、迭代快。
性能问题的不同点
相比于段错误(明确、可复现、结果清晰),性能问题更加复杂和模糊,如下:
“测试通过/失败”的二元判断不适用
- 性能不是布尔值(Boolean):
- 没有一个明确的标准说“快”或“慢”是否合格。
- 即使比之前快,也可能还不够快;或者仅在某些输入上快。
- 很难说“问题已经解决”:
- 性能优化是渐进式的过程,而不是一次性的修复。
- 总是可能有进一步优化的空间。
结果容易波动
- 性能测试容易受到:
- 系统噪声(CPU 调度、缓存、IO 干扰等)
- 随机误差
- 导致测试结果不稳定,需要:
- 多次测量
- 统计分析而不是一次结果判断
虽然流程看似一样,但实际更复杂
- Analyze 分析性能瓶颈
- 使用 profiler(如 perf、gprof、VTune 等)
- Implement 实现优化
- 提出一个优化改动
- Test 测试验证
- 多次运行、平均处理、比较基准
- ??? 成功吗?
- 没有明确“成功”标准
- 是否接受优化,取决于目标、收益、代价等综合判断
- Prior fixes may be reverted
- 某些优化会引入副作用,或不适合全部场景,可能需要撤回
总结对比
| 段错误/功能 bug | 性能问题 | |
|---|---|---|
| 明确目标 | 是(不崩溃) | 否(什么算“快”?) |
| 是否完成 | 明确,有终点 | 通常没有“终点” |
| 可重复性 | 高 | 低(受随机因素影响) |
| 工具支持 | 非常成熟 | 相对复杂,需要更精细工具 |
| 成功标准 | 明确(修复/没修复) | 模糊(是否“足够快”?) |
基本但常被忽略的问题:
“什么是性能(Performance)?”
性能 ≠ 一味追求“更快”
我们不是真的在追求“最快”,而是在追求:
“足够快”来满足具体需求的速度。
所以性能要根据上下文具体定义,而非抽象追求“更快”。
不同情境下的性能定义(3类典型)
1. Real-world Metric(真实世界的量化指标)
- 与业务目标直接相关
- 例子:
- 模拟速度:simulation-years/day(每天模拟多少年)
- 网页加载时间:秒数
- 视频转码:帧每秒、完成一个视频需要多少时间
这是最有价值、可落地的性能衡量方式。
2. Roofline Model 指标(理论极限性能,如 FLOP/s)
- 面向 CPU/GPU 的性能建模
- 通常用于高性能计算(HPC)和架构分析
- 示例:
- 浮点运算能力:FLOP/s(Floating Point Operations per Second)
- 内存带宽极限
- 可帮助定位瓶颈:
- 是计算受限(compute-bound)?
- 还是带宽受限(memory-bound)?
用于指导低层优化(如并行计算、SIMD)。
3. Deadline-based(基于时间约束)
- 软件/系统必须在固定时间内完成某任务
- 示例:
- “必须在 50 毫秒内响应用户输入”
- “音频播放延迟不得超过 10 毫秒”
常见于实时系统、游戏、UI/UX、音视频处理等领域。
总结:性能必须“可定义”
你必须能:
- 结合上下文,定义出有意义的性能指标
- 用这个指标来驱动:
- 评估现状
- 设定目标
- 验证优化
否则你根本不知道“快不快”。
> 在性能测试中,“**误差(Error)**是不可避免的”,你必须正视它并加以应对。
什么是 Observational Error(观测误差)?
你实际测到的结果 ≠ 系统“真实”的性能。两者之间的差距叫做:
观测误差(observational error)
它有两种主要来源:
1. Random Error(随机误差)
- 原因:系统运行的自然波动
- 比如:
- CPU 动态调度
- 系统后台任务
- 缓存命中/未命中
- 特点:无法预测,只能通过重复实验、统计分析来抵消
2. Systemic Error(系统性误差)
- 原因:测量方法或工具本身存在系统性偏差
- 举例:
- 使用
clock()可能忽略 I/O 阻塞时间 std::chrono只测 CPU 时间而非 Wall Time- 运行测试时开了调试器、日志记录、性能分析器等,影响性能
- 使用
- 特点:可重复、可纠正,但一开始容易被忽视!
所以结论是:
“观测误差是不可避免的。你必须在性能分析中显式考虑误差。”
如何处理误差?
- 统计分析:比如多次运行,取平均、标准差、置信区间
- 使用基准测试工具:如 Google Benchmark, Criterion 等,它们能自动处理误差范围
- 可视化波动:绘制误差条(error bars)、箱型图(box plots)等
- 对比相对差异:比绝对数值更可靠
性能的波动(Variance)来源于硬件层面的各种“抖动”(jitter),导致性能不可完全复现,尽管计算结果是确定的。
具体的硬件“抖动”来源:
1. 指令流水线(Instruction pipelines)
- 执行一条指令的时间会因为流水线中“填满”程度不同而变化。
- 流水线越满,后续指令等待的时间可能越少,反之亦然。
2. CPU 和内存总线的时钟周期不同
- CPU 和内存之间是异步的,CPU有时需要等待内存数据同步,造成时延波动。
3. CPU 频率调节和电源管理
- CPU根据负载自动调节频率(Turbo Boost、节能模式等),处理能力时高时低。
4. 共享硬件缓存
- 多核或多线程共享缓存,其他线程的缓存访问会影响当前线程的性能表现。
总结
- 这些硬件因素造成性能非确定性波动,这就是“Variance”。
- 因此,在性能测试时必须多次测试,统计波动范围,而不能只看单次测试结果。
性能波动(Variance)的进一步来源:
1. 内存访问时间差异
- 较大内存区域的访问时间不一,因为物理上远离CPU的内存(比如NUMA架构中不同内存节点)访问延迟更高,导致性能不稳定。
2. 操作系统活动
- 硬件中断:中断产生后,OS会立即响应处理,这会打断正在执行的程序,影响性能。
- 进程迁移:非固定绑定(non-pinned)的进程可能被OS调度迁移到不同CPU核,影响CPU缓存利用和调度策略,造成性能差异。
3. 观察者效应(Observer Effect)
- 测量本身会改变性能结果,任何性能监测或调试工具都会引入额外开销,影响程序执行时间。
总结
- 计算结果可以复现,但性能表现不可复现,因为有多种硬件和系统因素影响。
- 性能测试时必须考虑这些非确定性因素,多次测量并采用统计方法分析结果。
统计学在性能分析中的最佳实践流程,包括五个步骤:
- 提出假设
你对性能变化有什么预期?(例如,优化后运行时间会减少) - 设计测试
制定方法来检验这个假设是否成立。 - 收集数据
运行测试,采集性能指标。 - 统计分析数据
用统计方法处理数据,考虑误差和波动。 - 得出结论
根据统计结果判断假设是否成立。
“采集数据”阶段的**摊销(Amortizing)**方法:
high_resolution_timer t; // Start timing.
for (std::size_t i = 0; i < N; ++i) A[i] = A[i] + B[i] * C[i];
double time_per_iteration = t.elapsed() / N;
- 当测量单次很小或很快的事件时,单次测量误差和观察者效应会很大。
- 解决方法是测量多次事件的总时间,然后除以事件次数,得到平均(摊销)时间。
- 例如对一个循环做 N 次相同操作,测量总时间后平均,得到每次操作的耗时。
- 这种处理方法把这 N 次操作看作一个样本,而不是 N 个独立样本。
这可以减少测量误差,提高性能测量的准确度。
“采样(Sampling)”的概念:
- 样本是指每次独立测量得到的数据点。
- 样本应当代表总体(真实的性能表现)。
- 目标是采集足够多且高质量的样本,以便准确反映整体性能。
- 关键点:
- 在同一次执行中采样(测多次)
- 跨多次执行采样(多次运行程序)
- 跨多次执行采样能更好捕捉系统噪声和波动。
这帮助你避免因单次测试偶然因素造成的误导,得到更真实的性能数据。
这页讲“热态(hot)”与“冷态(cold)”执行对性能测量的影响:
- 冷态运行:CPU缓存、分支预测、I/O等还没“预热”,性能可能较差,不稳定。
- 热态运行:缓存和预测已经“预热”,性能稳定且更真实。
- 测试时,要确保整体执行和具体测量区域都处于热态。
- 通常做法是:先执行若干预热运行(warmup),再正式开始测量。
- 避免测量第一次执行或前几次迭代,因为它们可能还处于冷态。
这样可以更准确地反映程序在正常运行中的性能。
“不确定性(Uncertainty)”:
- 不确定性表示测量结果中误差的范围。
- 仪器不确定性(Instrument uncertainty):测量工具本身的误差范围,比如时钟精度。
- 用**样本标准差(sample standard deviation)**来估计样本平均值的不确定性。
- 如果测量的是由多个数据平均得出的指标,可以根据这些数据的误差来计算派生指标的不确定性。
总结就是:测量结果本身会有误差,要用统计方法估计这个误差的范围,才能对性能数据有更准确的理解。
如何计算函数结果的不确定性(标准差),给出了不同函数形式的计算公式:
- 函数形式:
f
=
a
A
f = aA
f=aA
对应标准差: σ f = a σ A \sigma_f = a \sigma_A σf=aσA
— 乘一个常数时,标准差也乘同一个常数。 - 函数形式:
f
=
a
A
±
b
B
f = aA \pm bB
f=aA±bB (两个不相关变量相加减)
对应标准差: σ f = a 2 σ A 2 + b 2 σ B 2 \sigma_f = \sqrt{a^2 \sigma_A^2 + b^2 \sigma_B^2} σf=a2σA2+b2σB2
— 标准差是各项标准差平方的加权平方根。 - 函数形式:
f
=
A
B
f = AB
f=AB 或
f
=
A
B
f = \frac{A}{B}
f=BA
对应近似标准差:
σ f ≈ f ( σ A A ) 2 + ( σ B B ) 2 \sigma_f \approx f \sqrt{\left(\frac{\sigma_A}{A}\right)^2 + \left(\frac{\sigma_B}{B}\right)^2} σf≈f(AσA)2+(BσB)2
— 对乘除法来说,相对误差(标准差除以均值)平方和开根号后乘以函数值。
这是统计学里常用的误差传播公式(Error Propagation),假设 A A A 和 B B B 是不相关的随机变量。
#include <iostream>
#include <cmath>
#include <boost/accumulators/accumulators.hpp>
#include <boost/accumulators/statistics.hpp>
using namespace boost::accumulators;
int main()
{
accumulator_set<
double,
stats<tag::count, tag::mean, tag::median, tag::variance>
> acc;
acc(42);
// 这里可以继续累积更多数据
acc(38);
acc(50);
acc(44);
acc(41);
auto stdev = std::sqrt(variance(acc));
std::cout << "Mean: " << mean(acc) << "\n"
<< "Median: " << median(acc) << "\n"
<< "Stdev: " << stdev << "\n";
return 0;
}
这段代码展示了如何用 Boost.Accumulators 库来计算一组数据的统计量,包括:
- 计数(count)
- 平均值(mean)
- 中位数(median)
- 方差(variance)
用法简要说明:
- 定义一个
accumulator_set,指定要收集的统计信息。 - 用
acc(value)累积数据。 - 通过调用
mean(acc),median(acc),variance(acc)等访问统计结果。 - 标准差用方差开根号计算。
这套工具非常方便,可以高效地计算多种统计量,非常适合性能测试中的数据分析。
标准差的两种计算方式:
- 未修正标准差(总体标准差)
计算的是整个总体的标准差,公式是:
σ = 1 n ∑ i = 1 n ( x i − μ ) 2 \sigma = \sqrt{\frac{1}{n} \sum_{i=1}^n (x_i - \mu)^2} σ=n1i=1∑n(xi−μ)2 - 修正标准差(样本标准差)
用于样本数据的标准差计算,分母减1来校正偏差,公式是:
σ = 1 n − 1 ∑ i = 1 n ( x i − μ ) 2 \sigma = \sqrt{\frac{1}{n-1} \sum_{i=1}^n (x_i - \mu)^2} σ=n−11i=1∑n(xi−μ)2
Boost.Accumulators默认使用的是修正标准差(样本标准差),这也是统计学中大多数情况下更合适的计算方法,因为真实总体均值往往不可得。
如果你需要未修正标准差,需要自行调整计算或者使用其他统计库功能。
#include <iostream>
#include <cmath>
#include <boost/accumulators/accumulators.hpp>
#include <boost/accumulators/statistics.hpp>
using namespace boost::accumulators;
int main() {
accumulator_set<double, stats<tag::count, tag::mean, tag::median, tag::variance>> acc;
// 累积样本数据
acc(42);
acc(35);
acc(50);
acc(48);
acc(40);
auto n = count(acc); // 样本数量
// 计算修正后的标准差,乘以 n/(n-1) 做样本方差校正
auto stdev = std::sqrt(variance(acc) * (n / (n - 1.0)));
std::cout << "Mean: " << mean(acc) << "\n"
<< "Median: " << median(acc) << "\n"
<< "Stdev: " << stdev << "\n";
return 0;
}
这段代码用的是Boost.Accumulators计算统计量,其中:
variance(acc)是样本方差(默认是未修正的,即除以 n)- 你乘上了
n/(n-1.0),相当于做了修正,使得计算的标准差是样本标准差(除以 n-1)
所以这是计算修正后的标准差的正确写法。
这段代码的流程是:
- 用
acc(42)等多次调用来累积数据样本。 - 计算样本数量
n。 - 计算修正后的标准差
stdev = sqrt(variance * n/(n-1))。 - 打印均值、中位数和标准差。
这是关于如何系统地收集并合并性能测量数据的过程,具体要点包括:
- 在代码中多次独立测量(单次测量如果很短可以用均摊法 amortization 减少观测误差)。
- 累积测量值和不确定度估计,以便计算统计量。
- 跨多次测试运行收集数据,然后用公式重新计算总体的不确定度。
你给出的公式是用来合并两个独立数据集的标准差(样本标准差):
设: - 两个数据集分别有样本均值 μ 1 \mu_1 μ1, μ 2 \mu_2 μ2
- 样本标准差 σ 1 \sigma_1 σ1, σ 2 \sigma_2 σ2
- 样本数量 n 1 n_1 n1, n 2 n_2 n2
- 合并后总样本数量
n
=
n
1
+
n
2
n = n_1 + n_2
n=n1+n2
合并的样本标准差 σ \sigma σ 计算如下:
σ = n 1 2 σ 1 2 + n 2 2 σ 2 2 − n 2 σ 1 2 − n 2 σ 2 2 − n 1 σ 1 2 − n 1 σ 2 2 + n y n x σ 1 2 + n y n x σ 2 2 + n 1 n 2 ( μ 1 − μ 2 ) 2 ( n 1 + n 2 − 1 ) ( n 1 + n 2 ) \sigma = \sqrt{ \frac{ n_1^2 \sigma_1^2 + n_2^2 \sigma_2^2 - n_2 \sigma_1^2 - n_2 \sigma_2^2 - n_1 \sigma_1^2 - n_1 \sigma_2^2 + n_y n_x \sigma_1^2 + n_y n_x \sigma_2^2 + n_1 n_2 (\mu_1 - \mu_2)^2 }{ (n_1 + n_2 - 1)(n_1 + n_2) } } σ=(n1+n2−1)(n1+n2)n12σ12+n22σ22−n2σ12−n2σ22−n1σ12−n1σ22+nynxσ12+nynxσ22+n1n2(μ1−μ2)2
这表达了在合并两个样本数据集时,考虑各自的方差和均值差异带来的整体方差变化。
这是置信区间(Confidence Interval, CI)的概念和计算方法:
- 置信区间是用来表示从样本数据推断总体参数时的不确定范围。
- 计算置信区间需要:
- 置信水平 r r r(如90%、95%、99%),表示有多大概率真值落在区间内。
- 样本大小 n n n。
- 估计的标准差(不确定度)
σ
\sigma
σ。
置信区间计算公式是:
C I = z × σ n CI = z \times \frac{\sigma}{\sqrt{n}} CI=z×nσ
- 其中, z z z 是临界值(critical value),代表置信水平对应的分布分位数。
- 对于大样本, z z z 通常查标准正态分布表。
- 对于小样本,使用学生t分布的逆累积分布函数:
z = T inv ( 1 − r , n − 1 ) z = T_{\text{inv}}(1 - r, n-1) z=Tinv(1−r,n−1)
这里的 T inv T_{\text{inv}} Tinv 是t分布的反函数。
这个置信区间表示:我们有 r r r 的信心,总体参数落在样本均值±CI范围内。
如何利用置信区间计算合适的样本大小,基于已有的一组初步样本(pilot samples)来做推断。
公式是:
n
=
z
2
σ
2
e
m
2
μ
2
n = \frac{z^2 \sigma^2}{e_m^2 \mu^2}
n=em2μ2z2σ2
其中:
- n n n 是需要的样本大小
- z z z 是置信水平对应的临界值
- σ \sigma σ 是数据的不确定度(标准差)
- e m e_m em 是允许的误差边界(margin of error)
-
μ
\mu
μ 是样本均值
这个公式告诉你:如果你希望结果误差在 e m e_m em 范围内,需要采集多少样本。
要点: - 如果计算出的 n n n 很大,说明你现在数据的波动太大,要么接受较大的误差,要么重新设计实验(比如降低噪声)。
- 如果标准差和均值大小相当,说明数据噪声很大,难以得到可靠结论。
这段讲的是置信区间的意义,尤其是95%置信区间的正确理解:
- 如果真实的性能指标(population parameter)落在置信区间外,那是一个发生概率≤5%的事件(假设置信水平是95%)。
- 置信区间并不是说“95%的数据点会落在这个区间内”,这是常见误解。
- 置信区间其实是对总体参数(比如总体均值)可能取值范围的估计,而不是对样本均值的一个区间。
简单来说:置信区间反映了对总体性能参数的不确定性,而不是说大部分样本数据都在这个范围。
“均值-中位数测试”的内容。
均值-中位数测试(Mean-Median Test)
这是一个用来判断数据是否服从正态分布的简单方法。
原理:
- 对于正态分布的数据,均值(μ)、中位数(m) 和 众数(mode) 基本上是相等的。
- 因此,可以通过比较均值和中位数的差距来大致判断数据是否近似正态分布。
计算公式:
∣ μ − m ∣ max ( μ , m ) \frac{|\mu - m|}{\max(\mu, m)} max(μ,m)∣μ−m∣
- 这个式子计算的是均值和中位数的相对差异(用百分比的小数表示)。
- 如果这个值大于1%(即0.01),说明均值和中位数差距较大,数据可能不服从正态分布。
- 如果这个值小于1%,说明均值和中位数比较接近,数据可能近似正态分布。
注意:
这个方法比较简单、粗略,适合做快速判断。
如果想更准确判断,可以用更正式的正态性检验方法,比如:
- QQ图(Quantile-Quantile Plot)
- 统计检验方法,如Shapiro-Wilk检验、Kolmogorov-Smirnov检验等。
x86 CPU上基于时间的基准测试(Time-Based Benchmarking),以及用于计时的几种时钟源(clocksources)。
重点总结:
- 系统范围的高精度时钟(System-wide high-resolution clock):
- 是单调时钟(Monotonic),即时间总是递增,不会被系统时间调整影响。
- 频率稳定,但有一定的延迟和开销(比起CPU内部计时器)。
- 分辨率达到纳秒级,非常精细。
- 时间值可以在不同线程之间传递和比较,方便多线程测量。
- 在Linux/Unix系统中,通过
clock_gettime(CLOCK_MONOTONIC)调用获取。 - 在Windows系统中,通过
QueryPerformanceCounter和QueryPerformanceFrequency组合使用获得。 - 适合用来测量大多数事件,尤其是微秒级别及以上的时间段。
简单来说:
你可以用这种时钟来测量函数运行时间、代码块执行时间等,保证时间测量稳定且高精度,尤其适合性能测试和基准测试。
现代x86 CPU上**基于时间的基准测试(Time-Based Benchmarking)**中,三种时钟源里的第一种——时间戳计数器(Timestamp Counter,TSC)。
Timestamp Counter (TSC) 的关键点:
- 单调性(Monotonic):TSC的计数值只会增加,不会倒退。
- 低延迟和低开销:读取TSC非常快,几乎不影响程序执行。
- 分辨率是CPU周期数:
- TSC以CPU的基本时钟周期数为单位计数。
- 不同微架构的基本时钟频率一般是100MHz或133MHz。
- 稳定的频率:
- 新款CPU(过去4-5年内)保证TSC频率恒定,即使CPU动态调频(如Intel Turbo Boost)。
- 这意味着TSC频率不会随CPU实际频率波动而改变。
- 但这也意味着TSC计数不一定反映真实执行的CPU周期数,因为实际CPU频率会变化。
- 使用汇编指令读取:
- 通常通过
RDTSC等汇编指令直接读取。
- 通常通过
- 计数是线程相关的:
- 计数值是针对线程的,可能和其它线程不同步。
- 适用范围:
- 适合测量从极短时间(几个CPU周期)到几分钟的事件。
简单总结:
- TSC是非常精准、开销低的计时方式,适合精细度非常高的基准测试。
- 但因为频率恒定和调频的存在,它测得的时间不完全等同于真实执行的CPU周期数。
C++11标准库中的 <chrono> 头文件,它提供了用于处理时间和日期的标准设施。
<chrono>的核心内容:
- 三种主要类型:
- Duration(持续时间)
- 表示一段时间的长度。
- 由若干个“刻度”(ticks)和时间单位(比如秒、毫秒、微秒)组成。
- 例如:
std::chrono::milliseconds表示毫秒数。
- Time Point(时间点)
- 表示从某个时钟的“纪元”(epoch,起始时间)开始经过的时间。
- 可以理解为某个具体的时间点。
- Clock(时钟)
- 表示一个有起点和刻度率的时间源。
- 通过时钟可以获取当前的时间点。
- 常见的时钟有:
system_clock(系统时钟)、steady_clock(稳定时钟,单调递增)、high_resolution_clock(高分辨率时钟)。
- Duration(持续时间)
适用场景:
<chrono>非常适合用于测量微秒级别或更长时间尺度的时长,比如性能测试、超时设置、延迟测量等。
C++ <chrono> 里三种常用的时钟类型及它们的特点:
| Clock 名称 | 描述 |
|---|---|
| system_clock | 系统级的实时时钟,返回当前的“墙钟时间”(wall clock time),可以转换成时间点和日期,受系统时间调整影响。 |
| steady_clock | 单调递增的时钟,不会被系统时间调整(如手动修改系统时间或网络时间同步)影响,适合测量时间间隔。 |
| high_resolution_clock | 可用时钟中刻度周期最短的时钟,提供最高的时间分辨率。它通常是 steady_clock 或 system_clock 的别名,具体实现依平台而定。 |
简单总结:
- system_clock:反映真实时间,可能会跳变(例如系统时间调整)。
- steady_clock:适合计时和测量时间间隔,保证时间单调递增。
- high_resolution_clock:分辨率最高,但具体表现依平台不同,通常用于精细计时。
代码是用C++ <chrono> 里的 steady_clock 来实现的一个高精度计时器示例。
#include <chrono>
#include <cstdint>
struct high_resolution_timer
{
// 构造函数,初始化计时器,记录起始时间点
high_resolution_timer() : start_time_(take_time_stamp()) {}
// 重新开始计时,更新时间起点
void restart()
{
start_time_ = take_time_stamp();
}
// 返回从计时开始到现在的经过时间(秒,double类型)
double elapsed() const
{
return double(take_time_stamp() - start_time_) * 1e-9;
}
// 返回从计时开始到现在的经过时间(纳秒,uint64_t类型)
std::uint64_t elapsed_nanoseconds() const
{
return take_time_stamp() - start_time_;
}
protected:
// 获取当前时间戳,单位纳秒(steady_clock单调时钟)
static std::uint64_t take_time_stamp()
{
return std::chrono::duration_cast<std::chrono::nanoseconds>(
std::chrono::steady_clock::now().time_since_epoch()
).count();
}
private:
std::uint64_t start_time_; // 计时开始的时间戳,单位纳秒
};
这个 high_resolution_timer 类的作用:
- 构造时记录一个起始时间点(纳秒级别)。
- 可以调用
restart()重新开始计时。 - 通过
elapsed()返回从起始点到当前时间的秒数(double 类型)。 - 通过
elapsed_nanoseconds()返回纳秒数的时间差。 - 内部用
take_time_stamp()获取当前时间戳(纳秒数),是通过steady_clock获取的,这保证了时间是单调且不会被系统时间调整影响。
代码解析要点:
take_time_stamp():
用steady_clock::now()获取当前时间点,
取它的时间跨度(time_since_epoch()),
转换成纳秒数,再用count()得到整数值。start_time_:
存储起始时间戳,单位纳秒。elapsed():
计算当前时间戳和起始时间戳的差值,转成秒返回(纳秒 × 1e-9 = 秒)。
这个计时器适合:
- 测量代码块或函数的运行时间,
- 需要高分辨率且稳定(单调)的计时场景。
**内存性能测试(Memory Benchmarking)**时,可以用的一些方法和策略。下面是内容的中文解释和整理:
目标:我们想观察什么?
- 对象层面:
- 有多少对象被分配(allocated)或释放(deallocated)?
- 内存层面:
- 总共分配了多少内存?
- 每个对象类型或每个对象实例占用了多少内存?
工具方法:
1. 使用外部工具(无需修改代码)
- googleperftools / TCMalloc:
- 支持
MALLOCSTATS之类的接口,可以获取分配统计信息。
- 支持
- MemTrack:
- 其他平台上也有类似工具,用于追踪内存使用情况。
这些工具适合从整体上观察程序的内存分配情况,适合快速定位内存泄漏或分析程序“吃内存”的地方。
- 其他平台上也有类似工具,用于追踪内存使用情况。
2. 重载 operator new 和 operator delete(手动追踪)
- 适合特定类型的对象进行内存跟踪。
- 在类中重载
operator new和operator delete可以精准地控制和记录该类对象的分配/释放行为。 - 建议使用静态成员变量来累计内存使用统计(比如分配次数、字节总量等)。
- 如果程序是多线程的,建议使用 线程局部存储(thread-local storage),线程执行完后再合并统计结果,避免锁竞争带来的性能损耗。
简单总结:
- 快速全局查看 → 用工具(如 TCMalloc)。
- 精细、按类型追踪 → 自己重载 new/delete,配合静态变量或 TLS 存数据。
提供的是一个通过重载 operator new 和 operator new[] 来记录内存分配信息的例子,适用于类 A。这是内存性能检测的经典手法之一。
代码功能解释:
struct A {
static std::size_t allocated;
// 单个对象的 new 操作
static void* operator new(std::size_t sz) {
allocated += sz / sizeof(A); // 记录分配了几个 A 对象的大小
return ::operator new(sz); // 调用全局 new 实际分配内存
}
// 数组 new 操作(如 new A[n])
static void* operator new[](std::size_t sz) {
allocated += sz / sizeof(A); // 同样记录
return ::operator new(sz);
}
};
// 静态成员变量初始化
std::size_t A::allocated = 0;
补充说明:
allocated是一个静态成员变量,用于记录所有A对象的总分配数量(近似估算)。sz / sizeof(A)用来估算分配了多少个A对象(注意这不一定精确,特别是数组 new 可能有额外头部)。- 使用
::operator new(sz)是调用全局版本的 new,实际进行内存分配。 - 这个方法不会追踪 delete,所以你只能看到累计分配的对象数量,不会知道释放了多少。
可选扩展:
- 若要记录释放,也可以重载
operator delete和operator delete[]:
static void operator delete(void* ptr) {
allocated--; // 或者记录释放次数
::operator delete(ptr);
}
static void operator delete[](void* ptr) {
// 注意,这里的释放大小无法获知
::operator delete(ptr);
}
使用示例:
int main() {
A* a = new A;
A* arr = new A[10];
std::cout << "Total A objects allocated (approx): " << A::allocated << std::endl;
delete a;
delete[] arr;
}
如需:
- 精确追踪释放
- 每个对象大小统计
- 多线程安全性(用
thread_local或加锁)
#include <iostream>
#include <cstddef> // for std::size_t
struct A {
static std::size_t allocated;
static std::size_t deallocated;
// 单个对象的 new
static void* operator new(std::size_t sz) {
allocated += sz / sizeof(A);
std::cout << "[Allocating 1 object] Total allocated: " << allocated << "\n";
return ::operator new(sz);
}
// 单个对象的 delete
static void operator delete(void* ptr) {
deallocated += 1;
std::cout << "[Deallocating 1 object] Total deallocated: " << deallocated << "\n";
::operator delete(ptr);
}
// 数组的 new[]
static void* operator new[](std::size_t sz) {
allocated += sz / sizeof(A);
std::cout << "[Allocating array] Total allocated: " << allocated << "\n";
return ::operator new(sz);
}
// 数组的 delete[]
static void operator delete[](void* ptr) {
// 实际无法知道数组大小,这里只做计数演示
std::cout << "[Deallocating array]\n";
::operator delete(ptr);
}
};
// 初始化静态成员
std::size_t A::allocated = 0;
std::size_t A::deallocated = 0;
// 使用测试
int main() {
A* a = new A;
A* arr = new A[5];
delete a;
delete[] arr;
std::cout << "\n=== Summary ===\n";
std::cout << "Total allocated: " << A::allocated << "\n";
std::cout << "Total deallocated: " << A::deallocated << "\n";
return 0;
}
[Allocating 1 object] Total allocated: 1
[Allocating array] Total allocated: 6
[Deallocating 1 object] Total deallocated: 1
[Deallocating array]
=== Summary ===
Total allocated: 6
Total deallocated: 1
C++ 中使用 mock 对象(模拟对象)来统计拷贝和移动操作的次数,目的是验证代码是否正确、高效地使用了移动语义(move semantics),这对像 HPX 这样做异步编程的框架尤其重要。
背景:
- 你们在将 HPX 框架 迁移到支持 C++ 移动语义(C++11 的新特性) 时,需要确认代码:
- 尽量避免不必要的拷贝(copy)
- 尽可能使用移动(move)来提高性能
实践方法:
- 创建一个“统计型 mock 类”:
- 类中统计构造、拷贝构造、移动构造、赋值等的次数。
- 通过传递这个对象来“探测”你们框架中的数据处理流程是否合理使用了移动语义。
- 观察拷贝和移动次数:
- 在测试中打印或断言这些操作的次数。
- 确保例如:
async()只拷贝参数一次等。
- 写单元测试 来保证:
- 在重构或修改代码后,拷贝/移动的次数不会变多。
- 如果变多了,说明可能误用了复制而不是移动。
示例:计数移动/拷贝操作的类
#include <iostream>
struct Tracker {
static int copy_count;
static int move_count;
Tracker() = default;
Tracker(const Tracker&) {
++copy_count;
std::cout << "Copy constructor\n";
}
Tracker(Tracker&&) noexcept {
++move_count;
std::cout << "Move constructor\n";
}
Tracker& operator=(const Tracker&) {
++copy_count;
std::cout << "Copy assignment\n";
return *this;
}
Tracker& operator=(Tracker&&) noexcept {
++move_count;
std::cout << "Move assignment\n";
return *this;
}
static void reset() {
copy_count = 0;
move_count = 0;
}
static void print() {
std::cout << "Copies: " << copy_count << ", Moves: " << move_count << "\n";
}
};
int Tracker::copy_count = 0;
int Tracker::move_count = 0;
示例使用:
#include <vector>
void test_func(Tracker t) {
// Do something...
}
int main() {
Tracker::reset();
Tracker a;
test_func(a); // 会触发 copy
test_func(std::move(a)); // 会触发 move
Tracker::print(); // 打印 copy 和 move 的次数
}
应用场景(比如 HPX):
- 测试
async()、future::then()等 API 中参数是否被合理地 move。 - 防止未来改动引入了隐藏的性能回退(如多余的 copy)。
硬件性能计数器(Hardware Performance Counters, HPC) —— 这是现代 CPU 提供的用于性能分析的底层工具,非常强大但也相对复杂。以下是内容的中文解释与整理:
什么是硬件性能计数器?
硬件性能计数器是由 CPU 提供的内部寄存器,用于统计程序运行期间各种低级事件,比如:
- 指令数(Instructions retired)
- CPU 周期数(Cycles)
- 缓存命中/未命中(Cache hits/misses)
- 分支预测命中/失败
- TLB 命中/失败
- 以及更多与微架构相关的事件
优点(Pros):
- 低开销:不像一些采样工具,它几乎不影响程序性能。
- 信息丰富:可以提供非常详细的性能数据,是调优性能的利器。
缺点(Cons):
- 与 CPU 微架构紧密相关:不同厂商、不同代的 CPU 支持的事件不完全一样。
- 有些计数值是估算的:例如部分缓存事件可能有误差(比如 overcounting)。
- 使用门槛高:需要了解底层 CPU 结构和事件编码,非常专业。
如何访问这些计数器?
不同平台的底层访问框架:
| 平台 | 框架/接口 |
|---|---|
| Linux | PAPI(Portable API) |
| Windows | Performance Counters API |
| macOS | kpc.h(Kernel Performance Counters) |
高层工具推荐:
为了避免手动配置复杂的事件编码,很多人使用了集成工具,比如:
Intel VTune Profiler(原 VTune Amplifier):
- 支持收集并可视化各种硬件事件。
- 可以结合源代码、热点分析、线程分析等信息。
- 跨平台,功能非常强大。
总结一下:
| 类别 | 说明 |
|---|---|
| 工具门槛低 | VTune, perf (Linux), Visual Studio Profiler |
| 工具专业强大 | VTune, PAPI |
| 编码手动复杂 | PAPI raw events, 自己配置 MSR/PMC |
理解了!你讲的是 Intel VTune Amplifier(现称 Intel® VTune™ Profiler)——这是一个非常强大的、基于采样的性能分析工具,用于对 C++、多线程、并行程序等进行深入的性能剖析。
Intel VTune Profiler 总结:
核心特点(Sampling-Based Profiler):
- 通过采样机制在程序运行时周期性地收集性能数据(比如每毫秒获取一次 CPU 使用情况),
而不是全程跟踪(效率更高,开销更低)。 - 不需要修改代码即可使用(0 插桩成本)。
- 可分析:
- 函数级别
- 源代码级别
- 汇编级别
- 多线程、子进程、系统调用等
功能亮点:
1. 数据源丰富:
- 硬件性能计数器(HPC)
- 操作系统指标(如 CPU 利用率、上下文切换等)
- 高精度定时器
- 并能合并多种来源进行综合分析
2. 内置分析功能:
- 自带分析通道(analysis passes),可以将底层硬件事件转换为更易懂的性能瓶颈信息,例如:
- 缓存命中率低
- 分支预测失败
- 指令发射受限
- 内存带宽不足
- 也支持自定义分析通道,适用于特定场景或框架
并行和分布式支持:
- 支持主流并行框架:
std::thread- OpenMP
- Intel TBB
- MPI(消息传递)
- 提供 Instrumentation API:可让你自定义报告线程、任务、事件等数据,方便集成到自定义并行框架中(比如 HPX)
使用方式与界面:
- GUI 强大易用:
- Windows/Linux/macOS 独立 GUI 应用
- 集成在 Visual Studio / Eclipse 中
- 支持远程采样、命令行运行:
- 可以在服务器上收集数据,随后用 GUI 进行分析
- 数据过滤功能强大:
- 比如只查看特定时间段的函数性能、特定线程、某次调用等
- 内置解释文档:
- 每个分析视图都有关于如何理解指标的提示,非常适合学习和调优
示例应用场景:
- 查看某个函数是不是 CPU 占用瓶颈
- 判断线程是否因为锁竞争而阻塞
- 分析内存访问延迟是否导致 pipeline 停顿
- 验证 OpenMP 并行是否有效展开
对开发者的意义:
| 优势 | 说明 |
|---|---|
| 无需改动代码 | 开箱即用,支持黑盒分析 |
| 易与多线程并行代码集成 | 线程识别、任务追踪 |
| 从底层硬件视角优化代码 | 利用 HPC 获取微架构瓶颈 |
| 图形化界面提升调试效率 | 一键分析、过滤、可视化对比 |
| https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler-download.html | |
 |






![[蓝桥杯]图形排版](https://i-blog.csdnimg.cn/direct/b88570d063f646e7bdc5011519d44a5f.png)