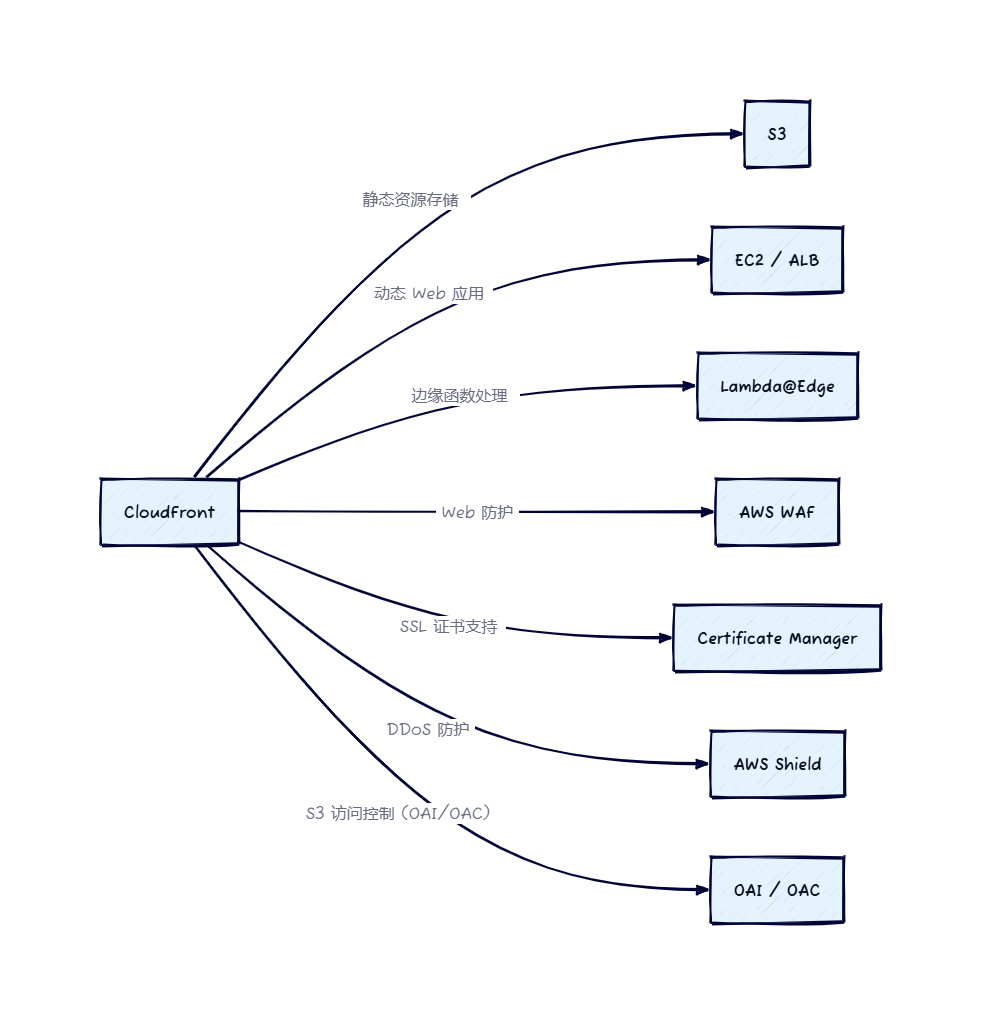
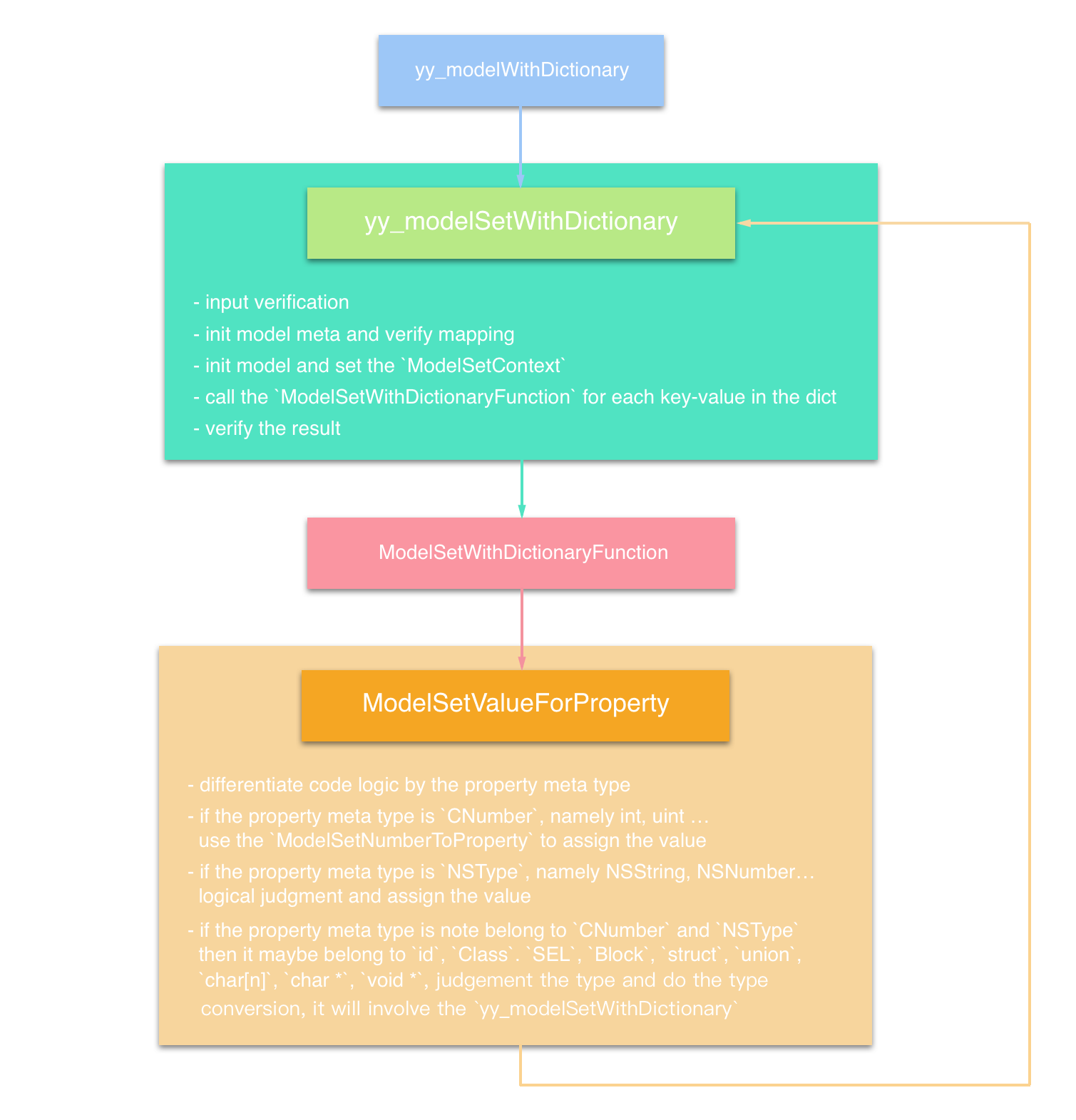
当不同CPU厂商未能就统一的宽松内存模型(Relaxed Memory Model)达成一致,很多软件的可移植性会收到限制或损害,主要体现在以下几个方面:
1. 可能的理论限制
1.1. 并发程序的行为不一致
现象上,同一段多线程代码在不同CPU架构(如x86、ARM、PowerPC)上可能产生不同的结果。
其原因在于,不同架构对内存重排序(Memory Reordering)的允许程度不同。例如:x86/64 是强有序模型(TSO),仅允许有限的存储-加载重排序。而 ARM/PowerPC是弱有序模型,允许更激进的重排序(如加载-加载、存储-存储重排序)。
导致的后果为,依赖特定内存顺序的无锁算法(如自旋锁、RCU)可能在弱有序架构上失败。从而需要重新实现一个相同功能的api函数。
1.2. 内存屏障(Memory Barrier)的显式需求差异
现象上,为一种CPU编写的代码在另一种CPU上可能需要额外插入内存屏障。例如,在ARM上需要显式使用DMB(数据内存屏障)保证顺序,而在x86上可能无需屏障。错误地省略屏障可能导致数据竞争或可见性问题。
导致的后果为,开发者必须为不同平台适配屏障指令,增加代码复杂性和维护成本。
1.3. 编译器优化的不确定性
现象上,编译器(如GCC、Clang)可能根据目标CPU的默认内存模型进行不同优化。例如,在弱有序模型下,编译器可能重排指令以提升性能,但在强有序模型下不会。这样,使用 volatile 或原子操作时,编译后的代码行为可能因平台而异。
导致的后果为,开发者需通过显式约束(如C11 atomic或内联汇编)限制优化,牺牲性能换取可移植性。
1.4. 标准库和语言实现的差异
现象上,高级语言(如 Java 的 volatile、C++ 的 memory_order)的语义可能因底层CPU模型而不同。例如,C++ 的 memory_order_relaxed 在 ARM 上可能允许更多重排序,而在x86上接近顺序一致。而在 Java JVM 中时,需要针对不同平台实现不同的内存屏障策略。
导致的后果为,语言标准的行为可能难以跨平台一致,需依赖运行时或库的额外适配。
1.5. 调试和测试的复杂性
现象上,并发 Bug 可能仅在特定 CPU 上复现,难以定位和修复。
其原因在于,内存模型差异导致问题仅在弱有序或强有序架构下暴露。
导致的后果为,开发者需在多平台上测试,并可能依赖工具(如 TSAN、模型检查器)验证内存行为。
1.6. 生态分裂与工具链支持
现象上,工具链(调试器、模拟器、形式化验证工具)需针对不同模型适配。例如,ARM 的 DSB/ISB 指令在 x86 模拟器中可能无直接对应。而且,验证工具需配置不同的内存模型参数。
导致的后果为,工具链的碎片化进一步加剧开发难度。
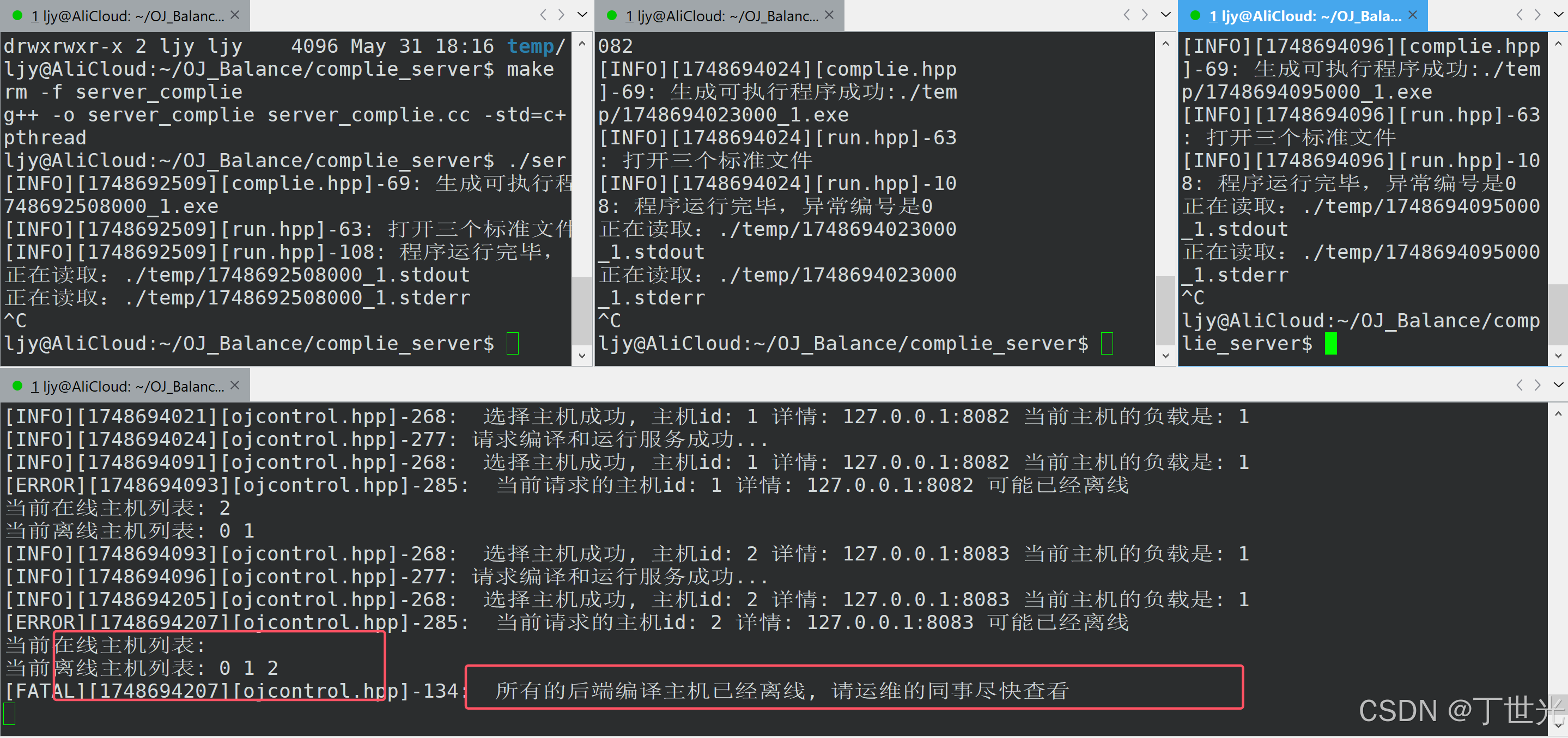
2. 现实案例
自然是跨平台的软件产品首当其冲, 例如,Linux kernel,java JVM 和 gcc的实现。
Linux kernel 为支持多种架构,包含大量平台相关的内存屏障和原子操作(如 smp_mb())。
Java JVM 通过 JSR-133规范 统一内存模型,但实际实现仍需针对不同 CPU 调整。
这里稍微详述 gcc 遇到的问题,
内存模型的不统一会显著增加GCC编译器在多个关键环节的开发难度,主要体现在以下几个方面:
2.1. 中间表示(IR)优化阶段的约束处理
问题是这样的,GCC 的 GIMPLE/RTL 优化器需要确保优化后的代码在不同内存模型下的行为符合预期。
例如,难点1,在 指令重排、公共子表达式消除等优化 pass 中可能违反弱有序架构(如ARM)的内存可见性规则。难点2,必须保守处理涉及共享内存的操作,避免跨 CPU 架构的优化错误。
具体来说,例如,在x86上可以安全删除冗余的LOAD指令(因TSO保证),但在ARM上做同样的删除就有可能导致读取到陈旧数据。
2.2. 原子操作和内存屏障的代码生成
问题是这样的,GCC 需将高级语言(如C++ atomic 或 Java volatile)映射到不同 CPU 的底层指令。
例如,难点1,原子操作:同一 atomic_fetch_add 在 x86 可能生成 LOCK XADD,而在 ARM 上需生成 LDREX+STREX 循环。
难点2,内存屏障下降时的指令选择上,std::memory_order_seq_cst 在 x86 可能仅需 MFENCE,而在 ARM 上需要 DMB SY。
难点3,维护成本也会增加,例如每种后端(如 aarch64.md、x86.md)需单独实现原子操作和屏障逻辑。
2.3. 目标后端(Backend)的指令选择与调度
这个问题是指,后端指令选择器需考虑内存模型对指令顺序的约束。
需要注意的是,弱有序架构(如PowerPC)的指令调度器需避免激进重排跨屏障的指令。但,强有序架构(如x86)的调度器可以更自由地优化,但需处理隐式屏障(如LOCK前缀)。
更具体的,例如,ARM后端需在原子操作前后插入屏障指令,而 x86 后端可能会省略部分屏障。
2.4. 编译器内置函数(Intrinsics)的实现
问题是这样的,内存模型的差异会影响 __sync_* 和 __atomic_* 等编译器内置函数的行为。
难点:
内置函数需根据目标 CPU 选择正确的指令序列(如 ARM 的 LDREX/STREX vs. x86 的 CMPXCHG)。于是,相同内置函数在不同平台可能生成完全不同的指令流。
这显然增加了维护负担,每个架构的后端需维护一套独立的内置函数实现。
2.5. 语言标准合规性(如C++11/C11内存模型)
问题是这样的,GCC需确保生成的代码符合语言标准定义的内存顺序语义。
难点1,关于 memory_order_relaxed, 在 ARM 上允许更多重排序,而 x86 上接近顺序一致。
另一难点2,编译器需插入隐式屏障以满足 memory_order_acquire/release 的跨平台语义。
增加了编译器实现的复杂性,标准合规性需通过大量平台相关的条件逻辑实现。
2.6. 调试与诊断工具的支持
问题是这样的,内存模型差异导致调试信息(如-fsanitize=thread)需分别适配不同架构。
这样,数据竞争检测器(如TSAN)需理解目标平台的内存模型以生成准确报告。而且错误消息提示需要提供平台相关的解决方案(如“在 ARM 上需添加 DMB”)。
2.7. 测试与验证的复杂性
进一步,GCC的测试套件需覆盖不同内存模型下的边缘情况。
于是,同一测试用例(如无锁队列)需在 x86、ARM 等架构上分别验证正确性。需模拟弱有序行为(如通过QEMU或硬件测试台)暴露潜在问题。
2.8. 文档与开发者指南的维护
同样的,需为不同架构提供内存模型相关的开发指南。
例如,需要分别解释 volatile、atomic 和屏障在具体平台上的行为差异。
需要提供平台特定的最佳实践(如 ARM 避免过度使用屏障)。
2.9. 具体案例
在现实上,这里举两个更细节的案例,
GCC 的 <atomic> 实现上,在 libatomic 库中为不同架构提供原子操作的软件回退(如CAS循环)。
另一个是内存屏障宏,__sync_synchronize() 在 x86 生成 MFENCE,在 ARM 则需要生成 DMB ISH。
2.10. 解决方案
可以参考的方向有,
<1> 抽象后端接口:通过统一的中端(Middle-end)表示(如MEM标记)隔离平台差异。
<2> 形式化验证:使用工具(如CAT模型)验证优化在不同内存模型下的正确性。
<3> 共享基础设施:复用LLVM等项目的内存模型处理逻辑(如通过__atomic内置函数)。
归纳一下,内存模型的不统一迫使GCC在优化、代码生成、标准合规性和测试等环节增加大量平台相关逻辑,显著提高了开发复杂性和维护成本。这种碎片化是编译器开发者在追求性能与可移植性时面临的核心挑
3. 解决方案方向
努力标准化,通过语言标准(如 C++11/C11 内存模型)或跨厂商协议(如 RISC-V 的内存模型)统一抽象。
增加抽象层,使用高级库(如LLSC原子操作、并发数据结构)屏蔽底层差异。
强调形式化验证,通过工具(如 Herding Cats 模型)验证代码在不同模型下的正确性。
综上,内存模型的分裂导致开发者必须在性能、正确性和可移植性之间做出艰难权衡,而统一的标准化的内存模型(如 RISC-V 的 WMO 或 C++ 的内存模型)是减少这类问题的关键。





![[蓝桥杯]图形排版](https://i-blog.csdnimg.cn/direct/b88570d063f646e7bdc5011519d44a5f.png)