1. BaseRetriever 检索器基类
在 LangChain 中,传递一段 query 并返回与这段文本相关联文档的组件被称为 检索器,并且 LangChain 为所有检索器设计了一个基类——BaseRetriever,该类继承了 RunnableSerializable,所以该类是一个 Runnable 可运行组件,支持使用 Runnable 组件的所有配置,在 BaseRetriever 下封装了一些通用的方法,类图如下: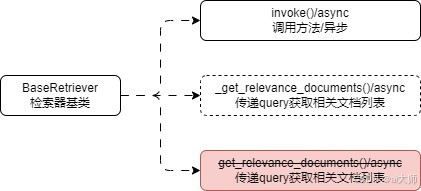
其中 get_relevance_documents() 方法将在 0.3.0 版本开始被遗弃(老版本非 Runnable 写法),使用检索器的技巧也非常简单,按照特定的规则创建好检索器后(通过 as_retriever() 或者 构造函数),调用 invoke() 方法即可。
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
- ✨模型优惠查询
并且针对所有 向量数据库,LangChain 都配置了 as_retriever() 方法,便于快捷将向量数据库转换成检索器,不同的检索器传递的参数会有所差异,需要查看源码或者查看文档搭配使用,例如下方是一个向量数据库检索器的使用示例:
import dotenv
import weaviate
from langchain_core.runnables import ConfigurableField
from langchain_openai import OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
from weaviate.auth import AuthApiKey
dotenv.load_dotenv()
# 1.构建向量数据库
db = WeaviateVectorStore(
client=weaviate.connect_to_wcs(
cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud",
auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0"),
),
index_name="DatasetDemo",
text_key="text",
embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
)
# 2.转换检索器
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"k": 10, "score_threshold": 0.5},
)
# 3.执行基础相似性搜索
similarity_documents = retriever.invoke("关于应用配置的接口有哪些?")
print("相似性搜索: ", similarity_documents)
print("内容长度:", len(similarity_documents))
输出内容:
相似性搜索: [...]
内容长度: 10





![BUUCTF[极客大挑战 2019]Havefun 1题解](https://i-blog.csdnimg.cn/direct/6f6fb22bf0c74355b23576dabbbd24aa.png)


![[yolov11改进系列]基于yolov11使用FasterNet替换backbone用于轻量化网络的python源码+训练源码](https://i-blog.csdnimg.cn/direct/d01dbee25f6f437ebc8190a0c5b26685.jpeg)