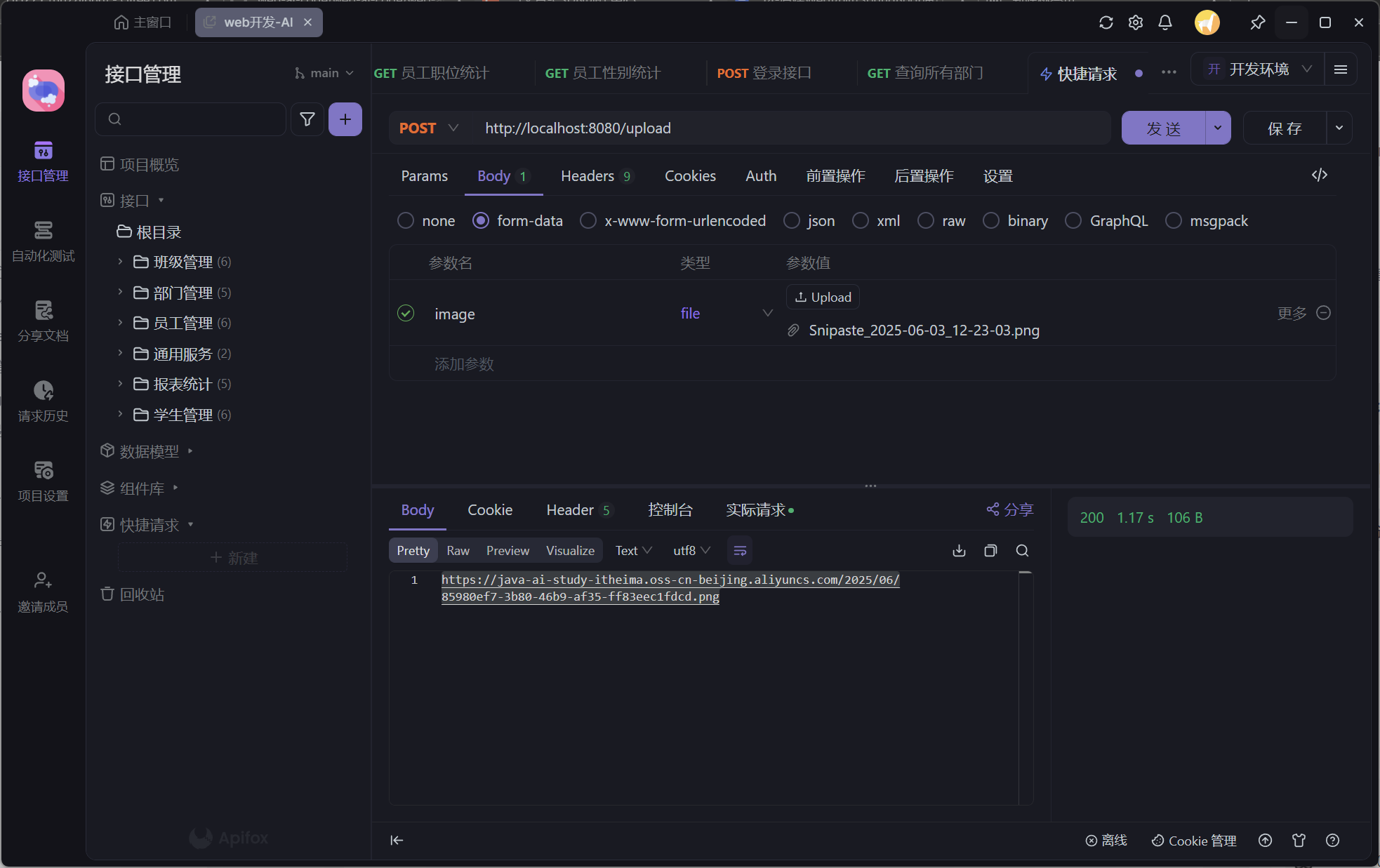
控制 Redis 缓存粒度,即决定是缓存整个对象还是对象的部分字段,是一个需要在性能、内存使用、数据一致性、更新复杂性和开发成本之间进行权衡的决策。没有绝对的“最佳”方案,需要根据具体业务场景来选择。
以下是两种主要策略及其优缺点,以及决策时需要考虑的因素:
一、缓存整个对象 (Cache the Entire Object)
将整个业务对象序列化后(例如 JSON、Protobuf、Kryo 等)存储在单个 Redis Key 下。
- Key 示例:
ecommerce:user_svc:user:12345(存储完整的 User 对象)
优点:
- 简单性: 获取和更新逻辑相对简单。一次读取即可获得所有数据,一次写入即可更新整个对象。
- 减少 Redis 请求次数: 如果应用通常需要对象的多个字段,一次性获取整个对象可以减少网络往返。
- 数据一致性 (对象内部): 对象内的所有字段总是一起被缓存和获取,保证了单个对象内部数据的一致性。
- 易于反序列化: 直接将缓存数据反序列化为完整的业务对象。
缺点:
- 内存占用较高: 如果对象很大,而应用通常只需要其中一小部分字段,会造成内存浪费。
- 网络传输开销大: 即使只需要部分字段,也需要传输整个对象。
- 更新不灵活: 即使只修改了对象的一个小字段,也需要重新序列化并存储整个对象,这可能导致:
- 更高的写操作开销。
- 更容易因并发更新导致数据覆盖问题(需要乐观锁等机制)。
- 缓存失效影响大: 任何字段的变更都可能导致整个对象缓存失效和重新加载,可能增加数据库压力。
适用场景:
- 对象较小。
- 应用通常需要访问对象的大部分或所有字段。
- 对象的字段不经常单独变化,或者变化时通常是多个字段一起变化。
- 读多写少的场景。
二、缓存部分字段 (Cache Partial Fields)
将对象的不同字段或字段组合存储在不同的 Redis Key 下,或者使用 Redis Hash 结构。
1. 使用多个独立的 Key:
- Key 示例:
ecommerce:user_svc:user:12345:profile(存储用户基本信息)ecommerce:user_svc:user:12345:settings(存储用户配置)ecommerce:user_svc:user:12345:balance(存储用户余额)
2. 使用 Redis Hash (HMSET/HGETALL/HGET):
- Key 示例:
ecommerce:user_svc:user_hash:12345- Fields:
name,email,avatar,last_login_ip - 使用
HSET user_hash:12345 name "Alice" - 使用
HGET user_hash:12345 name - 使用
HMGET user_hash:12345 name email - 使用
HGETALL user_hash:12345(获取所有字段,效果类似缓存整个对象,但字段是平铺的)
- Fields:
优点:
- 内存效率高: 只缓存需要的字段,节省内存。
- 网络传输开销小: 只传输需要的字段。
- 更新灵活高效: 只更新变化的字段,减少写操作开销和数据传输。
- 缓存失效影响小: 某个字段的变更只影响该字段或相关字段组的缓存。
- 适用于大对象: 当对象非常大时,这是更优的选择。
缺点:
- 增加 Redis 请求次数: 如果需要对象的多个独立缓存字段,可能需要多次 Redis 请求(除非使用
MGET或Pipeline,或 Redis Hash 的HMGET)。 - 应用层逻辑复杂: 应用层需要知道如何组合这些部分字段来构建完整的视图或业务对象。
- 数据一致性更难保证: 如果多个字段在业务上需要强一致性,而它们被分散存储,更新时需要额外的机制(如 Lua 脚本、分布式事务)来保证原子性。
- Key 数量可能过多: 如果拆分得过细,会导致 Key 数量激增,管理更复杂。
适用场景:
- 对象较大,且应用经常只需要访问对象的特定子集。
- 对象的不同字段更新频率差异很大。
- 希望更精细地控制缓存的生命周期。
- 对内存使用和网络带宽敏感。
三、决策时需要考虑的因素
-
数据访问模式 (Read Patterns):
- 应用通常是如何读取这些数据的?是总是需要整个对象,还是经常只需要一两个字段?
- 是否有明确的字段分组,某些字段总是被一起访问?
-
数据更新模式 (Write Patterns):
- 对象的哪些字段经常变化?是整个对象一起变,还是只有少数几个字段频繁更新?
- 更新频率如何?
-
对象大小:
- 对象序列化后有多大?几十KB?几MB?
-
数据一致性要求:
- 对象内的字段之间是否有强一致性要求?如果部分字段更新了,而另一些没更新,是否会导致业务错误?
-
网络和 Redis 性能:
- 单次大请求 vs. 多次小请求,哪个对你的系统更友好?
- Redis CPU 和内存的压力。
-
开发和维护成本:
- 哪种方案实现起来更简单,后期维护成本更低?
-
缓存命中率:
- 粒度太细可能导致某些字段的缓存命中率不高。
四、混合策略
在实际应用中,也可以采用混合策略:
- 常用字段组合: 将最常一起访问的字段组合成一个部分对象进行缓存。
- 热点高频小字段单独缓存: 例如,商品库存、文章点赞数等,这些字段变化频繁且经常被单独访问。
- 基本不变的大部分信息整体缓存: 例如,商品描述、用户注册信息等。
五、通用建议
- 从简单开始: 如果不确定,可以先尝试缓存整个对象。如果遇到性能瓶颈或内存问题,再考虑优化为部分字段缓存。
- 分析驱动决策: 使用监控工具(如 Redis Slow Log,
INFO命令, 应用性能监控 APM)来分析实际的瓶颈在哪里。 - 优先考虑 Redis Hash: 如果决定缓存部分字段,Redis Hash 通常是一个很好的选择。它允许你在一个 Key 下存储多个字段值,既能原子更新单个字段,也能一次性获取多个或所有字段,兼顾了灵活性和效率。
HSET key field valueHGET key fieldHMGET key field1 field2HGETALL key
- 不要过度优化: 避免过早地将对象拆分得过细,这会增加复杂性。
总结:
选择缓存整个对象还是部分字段,是一个需要基于具体场景分析的权衡过程。理解每种方式的优缺点,并结合你的应用特性(数据大小、访问模式、更新频率、一致性要求等)来做出明智的选择。通常,对于小型、读密集型且字段共同访问频率高的对象,缓存整个对象更简单有效;对于大型、字段更新频率差异大或常被部分访问的对象,缓存部分字段(尤其是使用 Redis Hash)是更优的选择。