自然语言处理(NLP)的核心挑战在于让机器“理解”人类语言。传统方法依赖独热编码(One-hot Encoding) 表示单词,但它存在严重缺陷:每个单词被视为孤立的符号,无法捕捉词义关联(如“国王”与“王后”的关系),且维度灾难使计算效率低下。
词向量(Word Embedding) 革命性地解决了这些问题。它将单词映射为稠密、低维的实数向量(如50-300维),其核心思想是:具有相似上下文(Context)的单词,其向量表示在向量空间中也应彼此接近。Word2Vec正是实现这一思想的里程碑式模型。
一、Word2Vec:分布式表示的引擎
Word2Vec由Tomas Mikolov等人于2013年在谷歌提出,包含两种高效架构:
-
CBOW(Continuous Bag-of-Words):通过上下文预测中心词
-
Skip-gram:通过中心词预测上下文
两者共享核心目标:优化词向量,使模型能根据上下文/中心词准确预测目标词的概率。
🔍 核心概念:分布式假设
“一个词的意义由其周围经常出现的词所决定。” —— J.R. Firth
Word2Vec完美实践了这一假设。例如:
句子:“猫在沙发上睡觉”
上下文窗口(size=2): [“在”, “沙发”, “上”, “睡觉”] → 中心词“猫”模型通过上下文学习“猫”的向量表示。
二、CBOW模型详解:上下文预测中心词
1. 模型架构
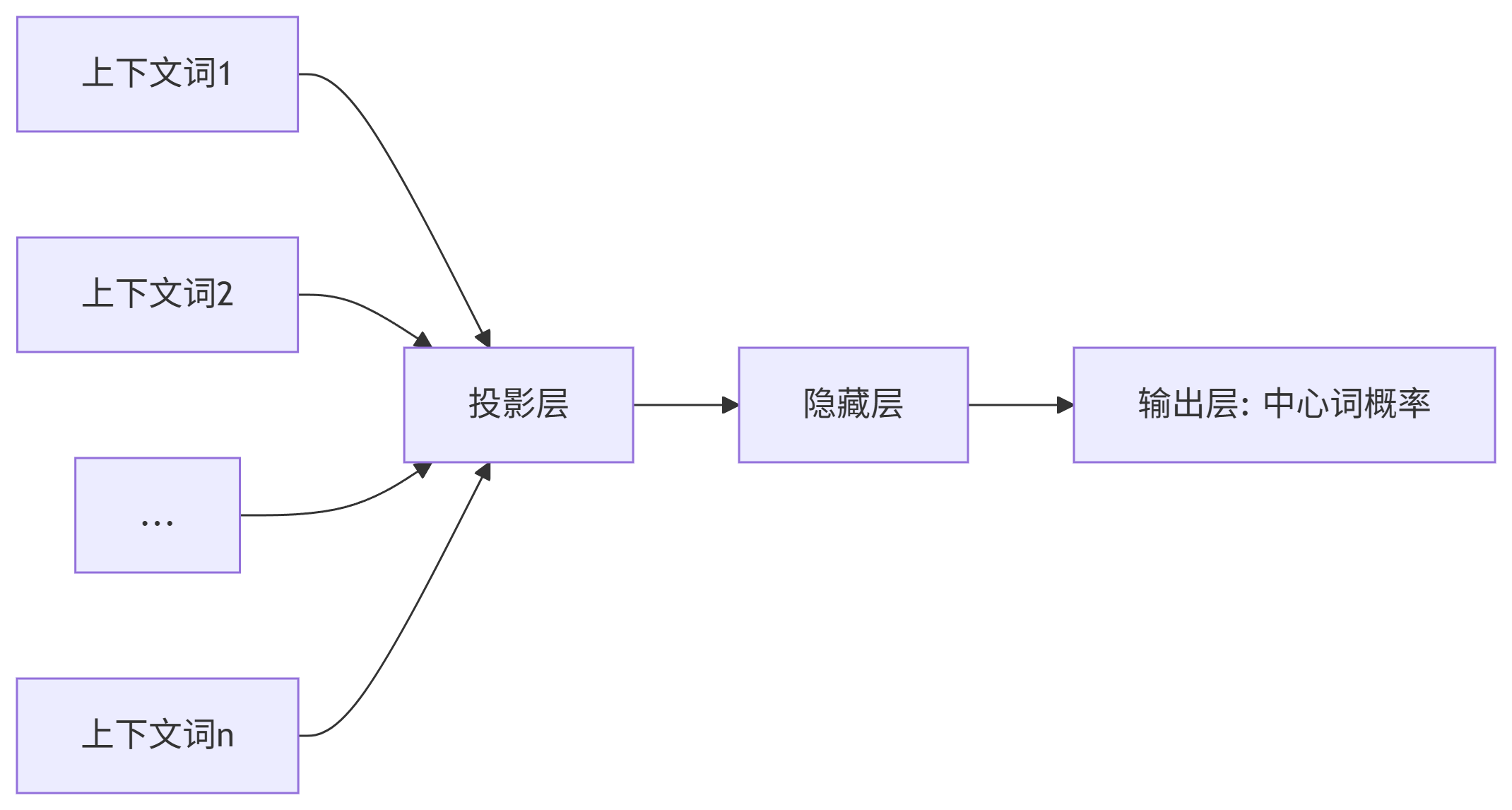
-
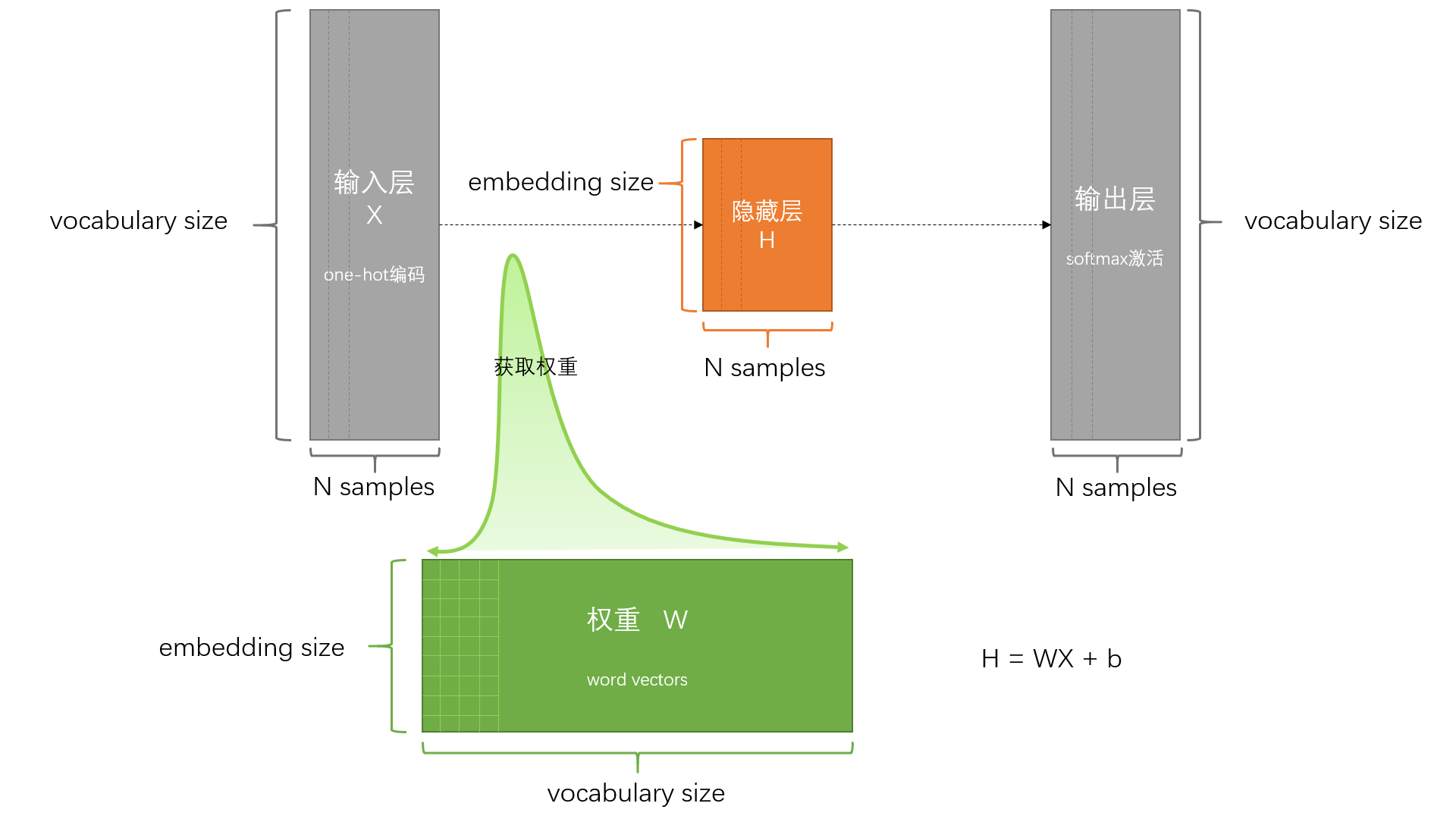
输入层:上下文窗口内所有单词的独热向量(
1×V,V=词汇表大小) -
投影层:上下文词向量求平均(或求和),形成固定长度向量
-
隐藏层:无激活函数的全连接层(本质是词向量查找)
-
输出层:Softmax计算中心词概率分布
2. 数学过程
设上下文词为 c₁, c₂, ..., cₘ,中心词为 w:
-
输入:
one_hot(c₁), ..., one_hot(cₘ) -
查词向量:
v_{c₁} = W_input · one_hot(c₁)(W_input为输入矩阵) -
计算上下文平均向量:
h = (v_{c₁} + ... + v_{cₘ}) / m -
预测中心词概率:
P(w|context) = softmax(W_output · h)
(W_output为输出矩阵)
3. 损失函数:交叉熵
Loss = -log(P(w_true | context))通过反向传播更新 W_input 和 W_output。
✅ 优点:
-
对小规模数据更鲁棒
-
训练速度快(尤其高频词)
-
对中心词预测更平滑
❌ 缺点:
-
上下文词平等对待(忽略位置信息)
-
对低频词学习效果较差
三、Skip-gram模型详解:中心词预测上下文
1. 模型架构
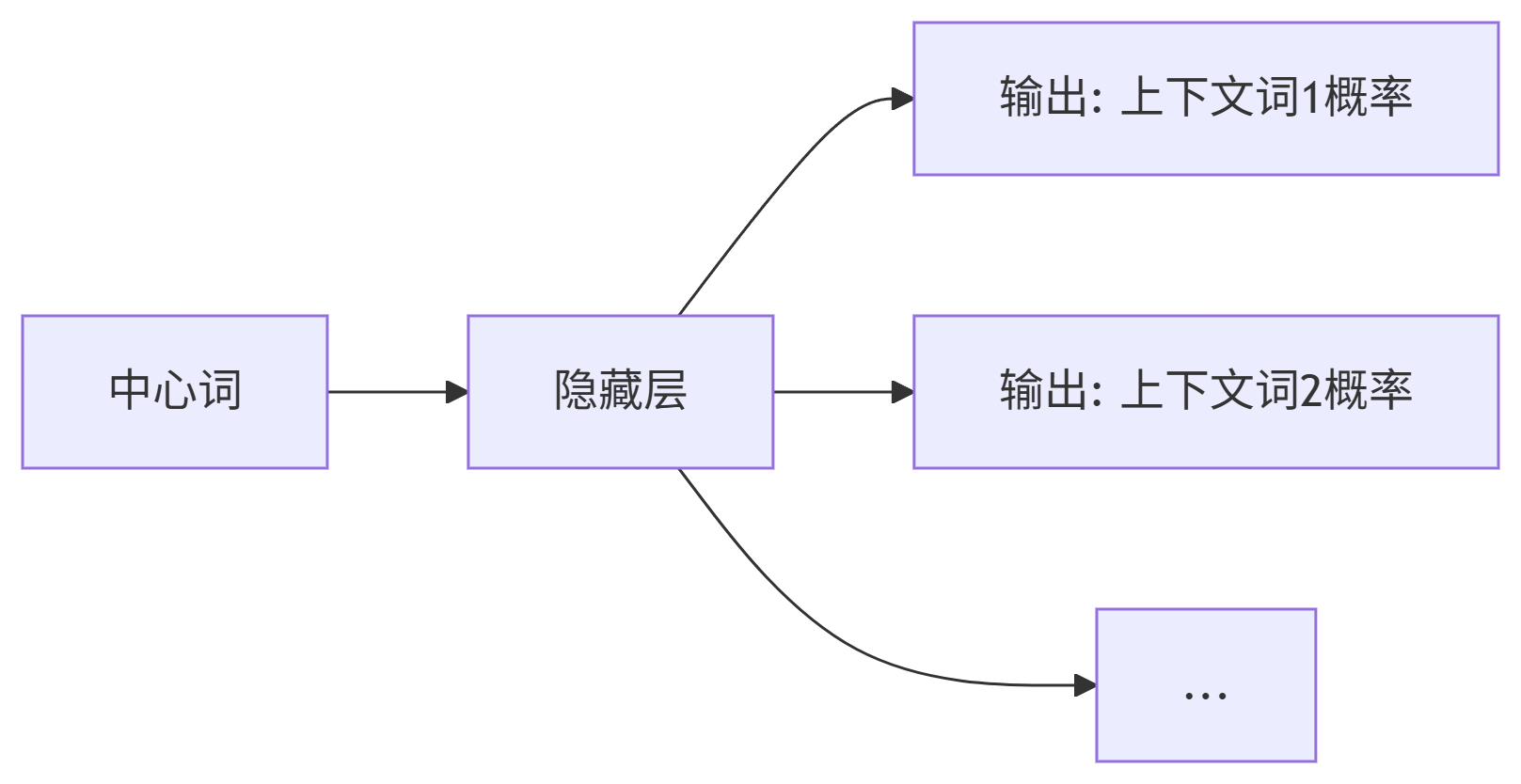
-
输入层:中心词的独热向量
-
隐藏层:直接映射为中心词向量
-
输出层:为每个上下文位置独立预测概率
2. 数学过程
设中心词为 w,上下文词为 c₁, c₂, ..., cₘ:
-
输入:
one_hot(w) -
查中心词向量:
v_w = W_input · one_hot(w) -
对每个上下文位置
j:
P(c_j | w) = softmax(W_output · v_w) -
目标:最大化所有上下文词的概率乘积
3. 损失函数:负对数似然
Loss = -Σ log(P(c_j | w)) (j=1 to m)✅ 优点:
-
在大型语料库上表现优异
-
能有效学习低频词表示
-
生成高质量的词向量(尤其在复杂任务中)
❌ 缺点:
-
训练速度较慢(需预测多个目标)
-
小数据集易过拟合
四、关键技术:优化训练效率
原始Softmax计算成本高昂(O(V)复杂度)。Word2Vec采用两种加速技术:
1. 层次Softmax(Hierarchical Softmax)
-
使用哈夫曼树(Huffman Tree) 组织词汇表(高频词路径短)
-
将V分类问题转化为约
log₂(V)次二分类 -
每个节点有参数向量,概率计算沿路径进行:
P(word=w | context) = ∏ P(branch_decision at node)
2. 负采样(Negative Sampling)
-
核心思想:仅更新少数权重
-
对每个正样本(中心词, 真实上下文词),随机采样K个负样本(中心词, 非上下文词)
-
优化目标变为:
Loss = -log(σ(u_o^T · v_c)) - Σ_{k=1}^K log(σ(-u_k^T · v_c)) -
其中:
-
σ为sigmoid函数 -
u_o是正样本词向量 -
u_k是负样本词向量
-
-
K通常取5~20,大幅减少计算量
⚡ 经验:Skip-gram + 负采样是最常用组合,在语义任务中表现最佳。
五、Word2Vec特性与局限
✨ 核心特性:
-
语义相似性:相似词向量距离小
cosine(v("国王"), v("王后")) ≈ 0.8 -
线性关系:词类比任务表现惊艳
v("国王") - v("男人") + v("女人") ≈ v("王后") -
上下文依赖:一词多义有不同向量(需结合上下文扩展)
⚠️ 重要局限:
-
静态表示:每个词仅一个向量,无法处理一词多义
(如“苹果”在公司和水果语境中含义不同) -
未考虑全局统计:仅依赖局部窗口,忽略文档级共现
-
未建模词序:CBOW/Skip-gram均忽略词位置信息
-
OOV问题:无法处理未登录词
六、实战:训练与评估
🛠️ 训练步骤(Python示例):
from gensim.models import Word2Vec
sentences = [["猫", "坐", "在", "沙发"], ...] # 分词后的语料
# 训练Skip-gram模型
model = Word2Vec(
sentences,
vector_size=100, # 向量维度
window=5, # 上下文窗口
sg=1, # 1=Skip-gram; 0=CBOW
negative=5, # 负采样数
min_count=5, # 忽略低频词
workers=4 # 并行线程
)
# 保存与加载
model.save("word2vec.model")
model = Word2Vec.load("word2vec.model")
# 应用示例
print(model.wv.most_similar("人工智能", topn=5))
# 输出: [('机器学习', 0.88), ('深度学习', 0.85), ...]
result = model.wv.evaluate_word_analogies("analogy-questions.txt")
print("词类比准确率:", result["correct"] / result["total"])📊 评估方法:
-
内部任务:
-
词相似度(如计算与人类判断的相关性)
-
词类比(如
man:woman :: king:?)
-
-
下游任务:
-
文本分类(作为特征输入)
-
命名实体识别(增强上下文表示)
-
情感分析(捕捉情感语义)
-
研究显示:在词类比任务中,Skip-gram比CBOW平均高5-10%准确率。
七、超越Word2Vec:现代嵌入技术
尽管Word2Vec影响深远,后续技术已解决其关键短板:
-
FastText:引入子词(subword)信息,能生成未登录词向量
向量("深度学习") ≈ 向量("深") + 向量("度") + 向量("学习") -
GloVe:结合全局统计与局部窗口,优化共现矩阵分解
-
上下文嵌入(ELMo/BERT):动态生成词向量,解决一词多义
BERT("苹果股价") vs BERT("吃苹果")→ 不同向量表示 -
大规模预训练模型(GPT, T5):基于Transformer架构,生成任务感知嵌入
八、总结:为什么Word2Vec仍是基石?
Word2Vec的成功在于其简洁性与高效性的完美平衡:
-
首次证明浅层神经网络可学习高质量语义表示
-
负采样/层次Softmax 大幅提升训练效率
-
开创了词类比评估范式,直观展示语义关系
-
启发了后续嵌入技术的爆炸性发展






![MCP:让AI工具协作变得像聊天一样简单 [特殊字符]](https://i-blog.csdnimg.cn/direct/e09176c05a7144f8982a633e92c816ca.png)