😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本专栏《八股消消乐》旨在记录个人所背的八股文,包括Java/Go开发、Vue开发、系统架构、大模型开发、具身智能、机器学习、深度学习、力扣算法等相关知识点,期待与你一同探索、学习、进步,一起卷起来叭!
目录
- 题目
- 答案
- B树
- 二分查找树
- AVL树(平衡二叉树)
- B树
- B+树
- MySQL 索引存储结构
- 调优
- 覆盖索引优化查询
- 自增字段作主键优化查询
- 前缀索引优化
- 防止索引失效
题目
💬技术栈:MySQL、索引
🔍简历内容:熟悉MySQL索引存储结构,如B+tree索引、Hash索引、R-Tree索引、Full-text索引,有一定的索引调优经验。
🚩面试问:某业务需要根据商品类型、订单状态筛选出需要的订单,并以订单时间进行排序,目前sku索引已存在,该SQL存在的问题以及如何优化:select * from order where status =1 and sku=10001 order by create_time asc

💡建议暂停思考10s,你有答案了嘛?如果你有不同题解,欢迎评论区留言、打卡。
答案
重建 sku、status 以及 create_time 组合索引
查询顺序修改为 sku=10001 and status=1
B树
二分查找树

特点:一个节点的左子树的所有节点都小于这个节点,右子树的所有节点都大于这个节点,这样我们在查询数据时,不需要计算中间节点的位置了,只需将查找的数据与节点的数据进行比较。
查询示例:

插入示例:

AVL树(平衡二叉树)
二分查找树 + 每个节点的左子树和右子树的高度差不能超过 1。
目标:实现节点的左子树和右子树仍然为平衡二叉树,这样查询操作的时间复杂度就会一直维持在 O(logn)。

B树
不再限制一个节点就只能有2 个子节点,而是允许 M 个子节点(M>2),从而降低树的高度。
假设 M =3,那么就是一棵 3 阶的 B 树,特点就是每个节点最多有 2 个(M-1个)数据和最多有 3 个(M个)子节点,超过这些要求的话,就会分裂节点。

目标:降低了树的高度。
B+树
(1)叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;
(2)所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
(3)非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小);
(4)非叶子节点中有多少个子节点,就有多少个索引;

MySQL 索引存储结构
索引分类:
- 按「数据结构」分类:B+tree索引、Hash索引、R-Tree索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。

在创建表时,无论使用 InnoDB 还是 MyISAM 存储引擎,默认都会创建一个主键索引,而创建的主键索引默认使用的是 B+Tree 索引。
InnoDB 默认创建的主键索引是聚族索引(Clustered Index),其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚族索引。
(1)MyISAM 使用的是辅助索引,索引中每一个叶子节点仅仅记录的是每行数据的物理地址,即行指针。

(2)InnoDB 使用的是聚族索引,聚族索引中的叶子节点则记录了主键值、事务 id、用于事务和 MVVC 的回流指针以及所有的剩余列。
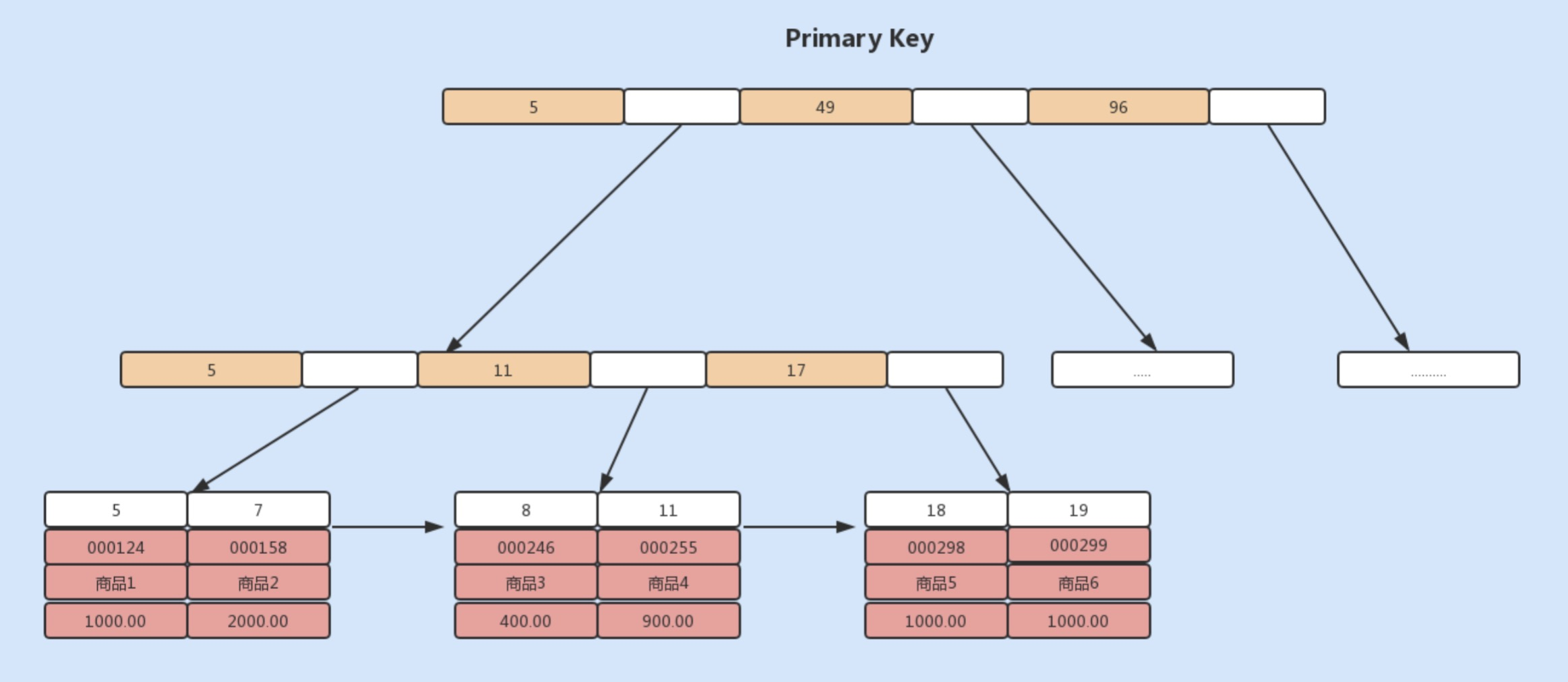
当我们使用主键索引查询商品,则会按照 B+ 树的索引找到对应的叶子节点,直接获取到行数据:
select * from merchandise where id=7
当我们使用商品编码查询商品,即
使用辅助索引进行查询,则会先检索辅助索引中的 B+ 树的 serial_no,找到对应的叶子节点,获取主键值,然后再通过聚族索引中的 B+ 树检索到对应的叶子节点,然后获取整行数据。这个过程叫做回表。
调优
覆盖索引优化查询
覆盖索引:从辅助索引中查询得到记录,而不需要通过聚族索引查询获得。不需要查询出包含整行记录的所有信息,从而减少大量的 I/O 操作。
常见的应用场景:
(1)查询部分字段。做法:将这些字段构建一个组合索引,如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。
(2)统计数量。例如 SELECT COUNT(*) 时,如果不存在辅助索引,此时会通过查询聚族索引来统计行数,如果此时正好存在一个辅助索引,则会通过查询辅助索引来统计行数,减少 I/O 操作。

自增字段作主键优化查询
页分裂:如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需要从一个页面复制数据到另外一个页面。
问题:页分裂会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
InnoDB 创建主键索引默认为聚族索引,数据被存放在了 B+ 树的叶子节点上。也就是说,同一个叶子节点内的各个数据是按主键顺序存放的,因此,每当有一条新的数据插入时,数据库会根据主键将其插入到对应的叶子节点中。所以我们在使用 InnoDB 存储引擎时,如果没有特别的业务需求,建议使用自增字段作为主键。
前缀索引优化
前缀索引:使用某个字段中字符串的前几个字符建立索引。
场景:在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
原因:索引文件是存储在磁盘中的,而磁盘中最小分配单元是页,通常一个页的默认大小为 16KB,假设我们建立的索引的每个索引值大小为 2KB,则在一个页中,我们能记录 8 个索引值,假设我们有 8000 行记录,则需要 1000 个页来存储索引。如果我们使用该索引查询数据,可能需要遍历大量页,这显然会降低查询效率。
前缀索引是有一定的局限性的,例如 order by 就无法使用前缀索引,无法把前缀索引用作覆盖索引。(order by 需要
基于完整列值排序)
防止索引失效
Hash 索引(Memory 引擎):如果使用到范围查询,那么该索引将无法被优化器使用到。
最左匹配原则:使用复合索引时,需要使用索引中的最左边的列进行查询。
例如复合索引:order_no, status, user_id
组合查询:order_no、order_no+status、order_no+status+user_id、order_no+user_id 可以利用到索引。
组合查询:status、status+user_id 不可以利用到索引。


如果查询条件中使用 or,且 or 的前后条件中有一个列没有索引,那么涉及的索引都不会被使用到。

对索引进行函数操作或者表达式计算也会导致索引的失效
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2025.6.3
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!