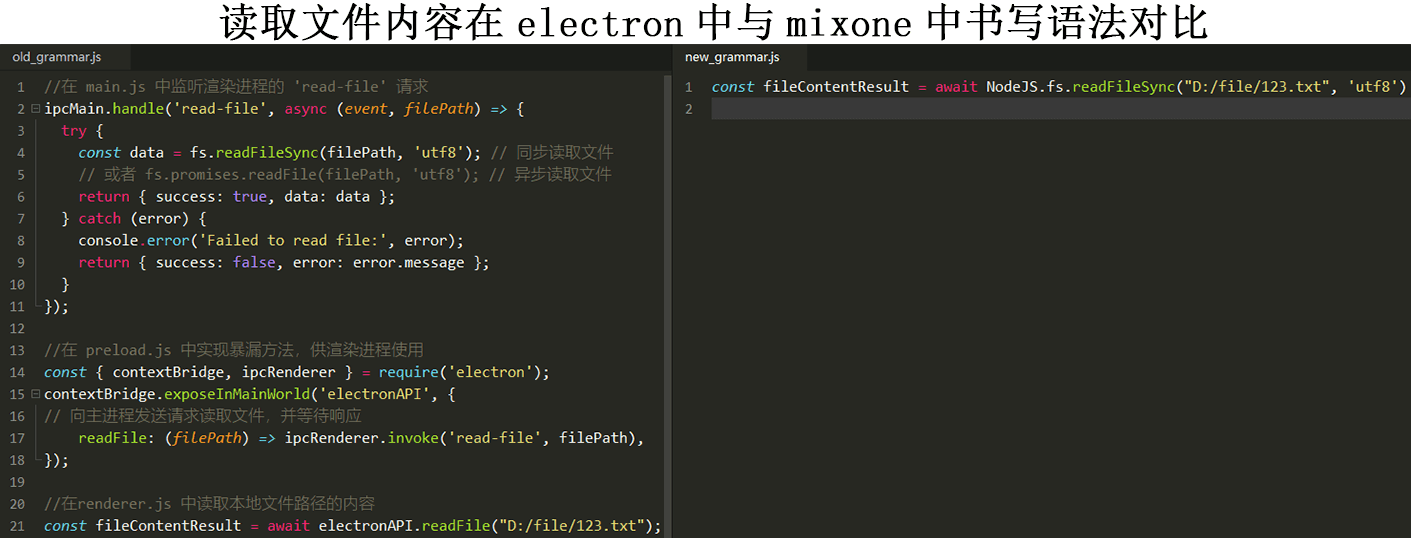
上一篇博客将C++进行实现消息队列的用到的核心技术以及环境配置进行了详细的说明,这一篇博客进行记录消息队列进行实现的核心模块的设计
五、项目的需求分析
5.1、项目框架的概念性理解
5.1.1、消息队列的设计和生产消费者模型的关系
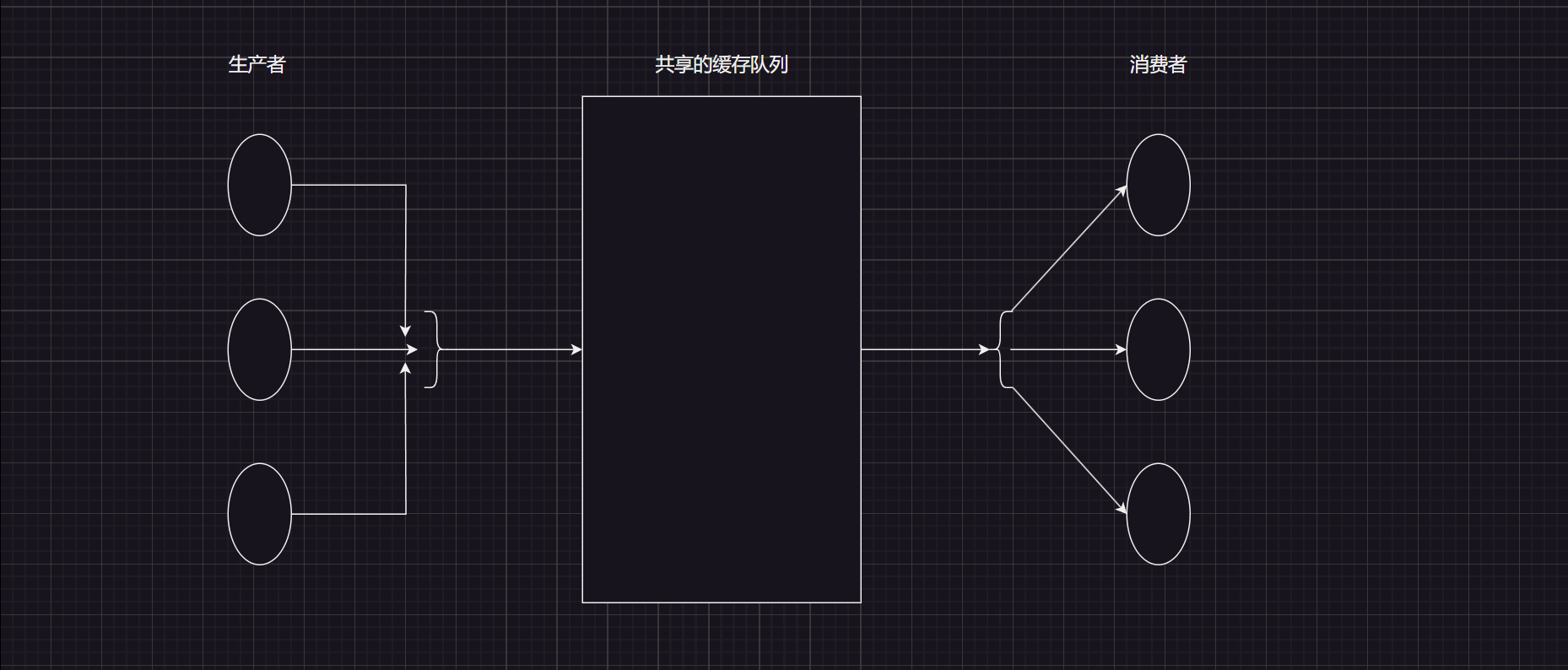
在现代系统架构中,消息队列(Message Queue)已经成为高并发、分布式、微服务系统中的关键组件。而它的设计思想,正是源自于我们熟悉的生产者-消费者模型。
当我们需要多个进程、甚至跨网络通信时,仅靠内存中的队列已经不够,这时候就轮到消息队列这个中间件登场了。
5.1.2、AMQP协议的概念性理解
AMQP协议和RabbitMQ的关系
AMQP 是规范标准的协议,RabbitMQ 是实现这个标准的代表,仿 RabbitMQ 的实现就是在“遵循 AMQP 标准”的框架下构建一个消息队列系统。
AMQP协议的组成
- 交换机
- 队列
- 绑定
- 消息
各司其职
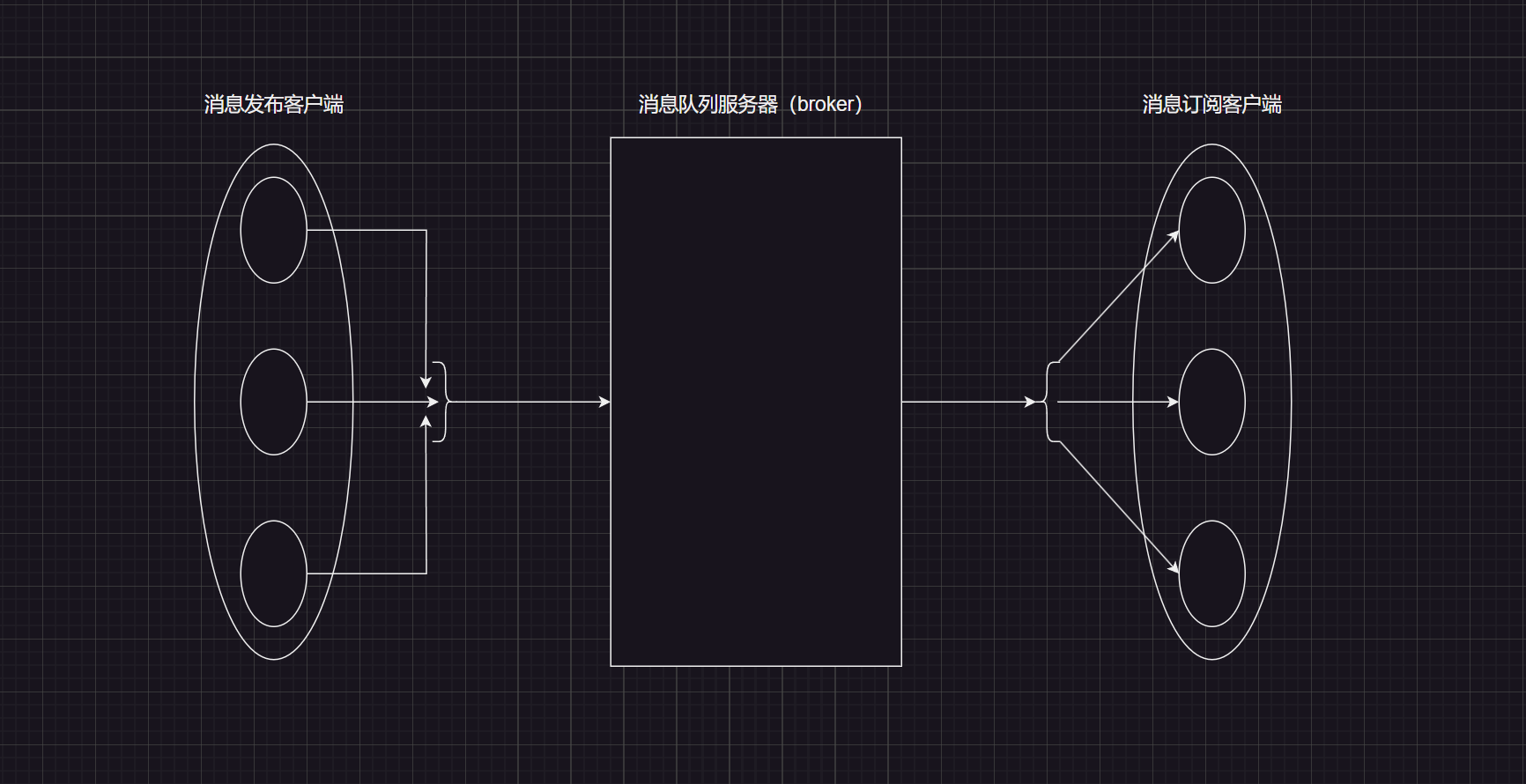
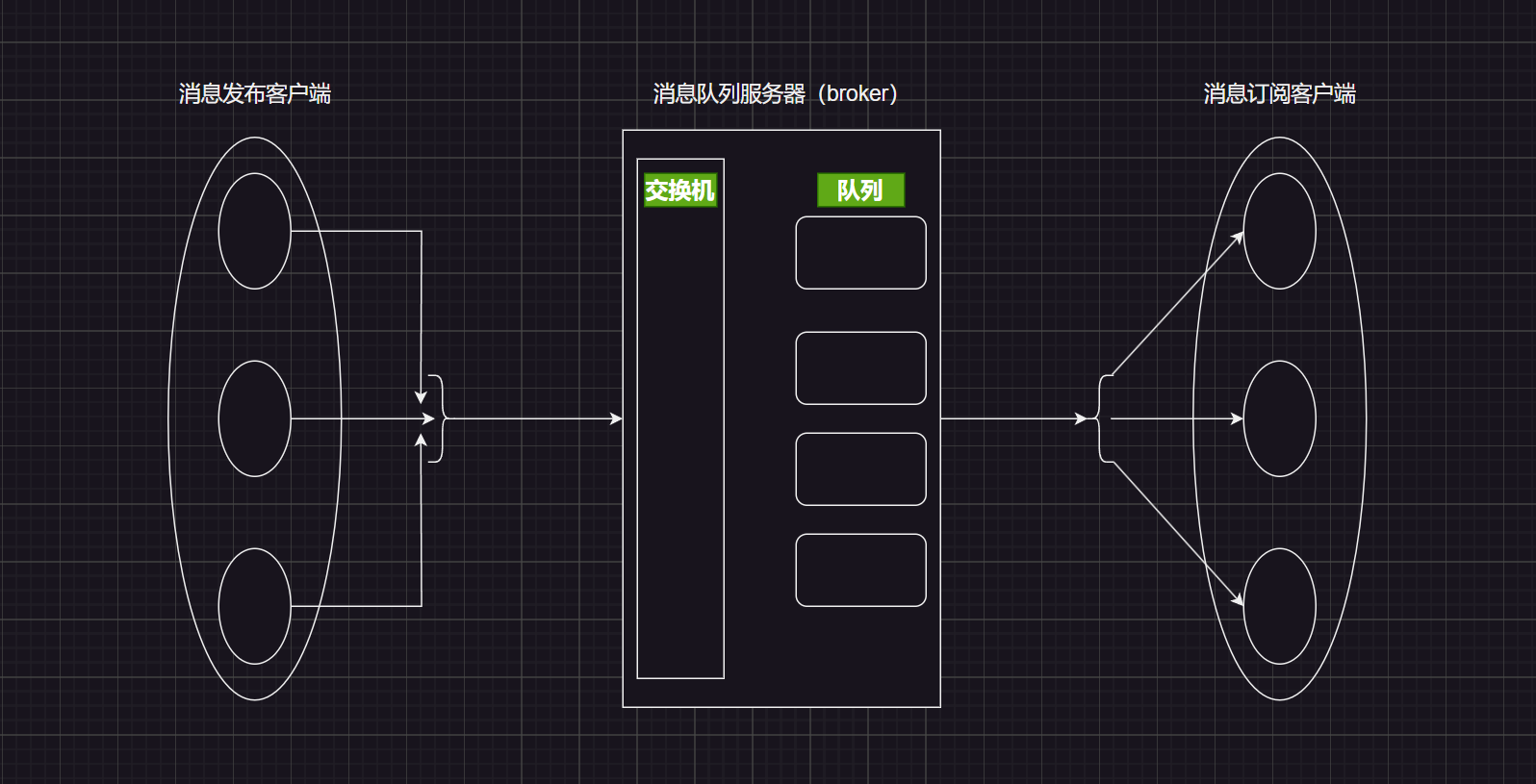 当消息发布客户端进行发布了一个消息 某某明星的某某歌曲上线了,假设消息队列服务器中的AMQP协议下的队列有音乐类的、明星类的等等,这个歌曲首先肯定是属于音乐的,其次是这个歌曲也是明星类的队列中的一个重要通知,所以说消息发布客户端进行发布了这个歌曲需要同时在两个消息队列中进行更新,这个工作就是有交换机进行完成的,交换机需要进行绑定一个或者若干个队列,消息订阅客户端要是订阅了某个队列就会收到该消息的推送。
当消息发布客户端进行发布了一个消息 某某明星的某某歌曲上线了,假设消息队列服务器中的AMQP协议下的队列有音乐类的、明星类的等等,这个歌曲首先肯定是属于音乐的,其次是这个歌曲也是明星类的队列中的一个重要通知,所以说消息发布客户端进行发布了这个歌曲需要同时在两个消息队列中进行更新,这个工作就是有交换机进行完成的,交换机需要进行绑定一个或者若干个队列,消息订阅客户端要是订阅了某个队列就会收到该消息的推送。
至于交换机是如何进行绑定消息队列的,放到交换机类型模块进行说明
5.2、核心的API接口
5.2.1、消息队列服务器提供的API接口
1.创建交换机(exchangeDeclare)
2.销毁交换机(exchangeDelete)
3.创建队列(queueDeclare)
4.销毁队列(queueDelete)
5.创建绑定(queueBind)5.
6.解除绑定(queueUnbind)
7.发布消息(basicPublish)
8.订阅消息(basicConsume)
9.确认消息(basicAck)10.取消订阅(basicCancel)
5.2.2、客户端提供的API接
1.创建 Connection
2.关闭 Connection
3.创建 Channel
4.关闭 Channel
5.创建队列(queueDeclare)
6.销毁队列(queueDelete)
7.创建交换机(exchangeDeclare)
8.销毁交换机(exchangeDelete)9.创建绑定(queueBind)
10.解除绑定(queueUnbind)
11.发布消息(basicPublish)
12.订阅消息(basicConsume)
13.确认消息(basicAck)客户端相对于服务器来说API接口增加了 关于连接和信道的API接口,客户端是需要进行网络通信的。
5.3、交换机的类型
上面谈到了交换机是如何进行绑定队列的,其实交换机进行绑定队列是按照交换机的类型来决定的。
直接交换机(Direct Exchange)
-
路由机制:基于 精确匹配 的
routing key(路由键),消息会被发送到binding key完全匹配的队列。 -
适用场景:点对点(1:1)精确路由,例如任务分发、日志级别过滤。
广播交换机(Fanout Exchange)
-
路由机制:广播模式,忽略
routing key,将消息发送到所有绑定的队列。 -
适用场景:发布/订阅(1:N)场景,如新闻推送、事件通知。
主题交换机(Topic Exchange)
-
路由机制:基于
routing key和binding key的 模糊匹配(支持通配符*和#)。-
*匹配一个单词(如order.*匹配order.paid,但不匹配order.paid.shipped)。 -
#匹配零或多个单词(如order.#匹配order.paid和order.paid.shipped)。
-
-
适用场景:灵活的多条件路由,如日志分类、多维度事件处理。
5.4、持久化
为了保证消息的持久化,需要在内存中和硬盘中都进行讲消息队列进行存储,在内存中进行存储是为了提高订阅客户端进行获取消息的高效性,在硬盘中进行存储是为了维持消息的持久化。
5.6、消息应答
自动应答:消费者只要消费了数据就算应答完毕,Brokei直接进行从队列中进行删除这个消息
手动应答:消费者进行手动调用应答接口,Broker接收到应答请求之后才真正删除这个消息
5.7、模块划分
5.7.1、服务端模块
- 虚拟机数据管理模块
对交换机数据管理模块、队列数据管理模块、绑定数据管理模块、消息数据管理模块这几个Broker内的几个模块进行实现数据的管理(增删查)以及数据的持久化存储
交换机数据管理
要管理的数据:描述了交换机应该有什么数据
交换机名称:交换机的唯一标识
交换机类型
持久化标志:决定了当前交换机信息是否需要持久化存储
自动删除标志:关联了当前交换机的客户端都退出了,是否要自动删除交换机
交换机的其他参数:这里是使用map进行存储的,当前未使用,方便后续进行扩展
对交换机的管理操作
声明交换机(创建):强断言的思想,有就OK,没有就创建
删除交换机:注意事项:每个交换机都会进行绑定一个或多个队列,因此需要进行删除相关的绑定信息
获取指定名称的交换机
获取当前交换机的数量:方便后续进行调试
队列数据管理
要管理的数据:描述了队列应该有什么数据
队列名称:队列的唯一标识
持久化的存储标志:决定了是否讲队列的消息进行存储起来,决定重启后这个队列是否依然存在
是否独占标识:是否只有当前客户端可以进行订阅队列消息
自动删除标志:当订阅了队列的所有客户端推出后是否进行删除队列
其他参数:键值对进行描述的其他信息
提供的管理操作:增删查
获取指定队列信息
获取队列的数量
获取所有队列的名称
当系统进行重启后需要进行加载历史数据,根据队列名称进行创建文件进行存储,一个队列的消息进行存储一个文件,进行顺序存储,当系统重启后,我得知道有哪些队列我才能去加载对应的消息
补充:一个队列的持久化如果是false,那么当系统进行重启后,这个队列就没了,也就是说没有必要进行消息持久化,队列都没了客户端无法进行订阅设置为持久化的消息,消息持久化也就没有意义了。
绑定数据管理模块
要管理的数据 :描述了那个队列和哪个交换机进行绑定到了一起
管理的数据
交换机名称
队列的名称
绑定密钥(binding_key):描述了交换机不同烈性的消息发布的匹配规则
管理的操作
添加绑定
解除绑定
获取交换机所有的绑定信息:删除叫交换机的时候进行删除相关的绑定信息;消息进行发布到交换机时,交换机需要进行向绑定的队列进行同步消息
获取队列相关的所有帮i的那个信息:删除队列的时候需要进行删除相关的绑定信息
获取绑定信息的数量:用于进行调试
消息数据管理
要管理的数据:每一条消息里面应该有哪些信息
消息属性:
ID:消息的唯一标识,当要进行消息确认时,通过消息ID进行确认消息的唯一性
持久化标志:消息是否需要进行持久化存储
routing_key: 和绑定队列的binding_key进行比对,决定消息要进行发布的队列
消息主体(消息的内容):
消息的主题时服务端为了进行管理消息所进行添加的
存储的偏移量:消息以队列为单元存储到文件中,这个偏移量是对当前文件起始位置的偏移量
消息长度:从偏移量位置进行取出指定长度的消息,目的是为了进行解决粘包问题
是否有效的标志:标识当前的消息是否已经被删除,删除消息的过程中并不是将队列中进行删除消息的位置的后面消息进行往前进行拷贝,而是将删除消息的位置的标志位进行设置成无效即可,当一个文件中的有效消息占据总消息的比例不超过50%,且数据量超过2000,则进行垃圾回收,重新进行整理文件数据存储,当系统进行重启后,只需要进行加载有效消息即可
消息的管理
管理方式:因为消息的操作都是以队列为单元进行的,所有说进行消息的管理也需要以队列为单元
管理数据:
消息链表:通过链表的方式进行保存所有待推送的消息
待确认的消息哈希:消息进行推送到订阅客户端时,需要进行等待客户端进行确认消息,消息被确认在队列中进行删除消息(思考为什么要进行使用hash的结构)
持久化消息的哈希:假设消息都会进行持久化存储,操作过程中可能会进行存在垃圾回收的操作,进行垃圾回收会进行改变原来消息存储的位置,因为垃圾回收的操作是将有效的数据进行识别,然后进行截断文件,将消息进行连续写入文件中。所以说每次进行垃圾回收后都需要进行更新持久化的消息。
持久化消息的有效数量
持久化消息的总数量:与有效数量进行配合决定什么时候进行执行垃圾回收机制
管理操作:向内提供的类
向队列进行新增消息
获取队首的消息:获取消息后就会将消息从待推动消息链表中进行删除,加入到待确认消息中
对消息进行确认:从待确认消息中进行移除消息,并进行持久化的数据删除,待确认消息的处理常见的两种方式:死等和取出重新进行添加到队列并向其他客户端进行推送
恢复队列的历史消息:主要在构造函数中进行,只有在重启的时候才会进行
垃圾回收(消息持久化子模块完成)
删除队列相关消息文件:当一个队列被删除了,那他的消息也就没有存在的意义了。
队列消息管理:向外提供的类
初始化消息队列结构:
移除消息队列结构:
向队列进行新增消息:
向队列进行消息确认:
恢复队列的历史消息:
- 虚拟机数据管理模块
虚拟机就是交换机、队列、绑定、消息的整体逻辑单元,虚拟机数据管理其实就是对以上四个模块进行合并管理。
每一个模块虽然都是独立的,但是这些模块之间的关系并不是独立的
管理的数据
交换机数据管理句柄
队列数据管理句柄
绑定信息数据管理句柄
消息数据管理句柄
管理的操作
声明/删除交换机:在进行删除交换机的时候需要进行删除相关的绑定信息
声明/删除队列:在进行删除队列的时候删除相关的绑定信息以及消息数据
队列大绑定/解绑:绑定的时候交换机和队列都必须是存在的
获取队列的消息
对指定队列的指定消息进行确认
获取交换机相关的多有绑定信息 :一条消息进行发布给指定的交换机的时候,交换机获取所有的绑定信息来确定要发布到哪个队列。
- 交换路由模块
消息的发布,将一条新消息发布到交换机上,由交换机决定放入哪些队列
而决定交给哪个队列,其中交换机类型起了很大作用(直接交换,广播交换,主题交换)直接交换和广播交换思想都较为简单,而主题交换涉及到了一个规则匹配的流程
而交换路由模块就是专门做匹配过程的。路由匹配模块:决定了一条消息能够进行发布到指定的队列
在每个队列跟交换机的绑定信息中都有一个binding_key——这是队列队列进行发布的匹配规则;在每条要进行发布的消息中都有一个routing_key——是消息进行发布的匹配规则
路由器匹配模块的本质上来说,没有要进行管理的数据,只有向外进行提供的路由匹配操作
- 提供一个判断routing_key与binding_key是否能够匹配成功的接口
- 判断routing_key是否符合规定
格式约定:只能由数字、字母、_、. 构成- 判断binding_key是否符合规定
格式约定:只能由数字、字母、_、. 、# 、* 构成通常以队列名称进行作为routing_key和binding_key
- 消费者管理模块
消费者指的是订阅了一个队列消息的客户端,一旦这个队列有了消息就会推送给这个客户端
在核心API中有个订阅消息的服务----注意了,这里的订阅不是订阅某条消息,而是订阅了某个队列的消息
当前主要实现了消息推送功能,因此一旦有了消息就要能找到消费者相关的信息(消费者对应的信道)
消费者管理模块:
客户端有两种:发布消息,订阅消息
因此订阅了指定队列消息的客户端才是一个消费者。消费者数据存在的意义:当指定队列有了消息以后,就需要将消息推送给这个消费者客户端(推送的时候就需要找到这个客户端相关的信息--连接)
- 消费者信息:
1.消费者标识--tag
2.订阅队列名称:当当前队列有消息就会推送给这个客户端,以及当客户端收到消息,需要对指定队列的消息进行确认
3、白动确认标志:自动确认---推送消息后,直接删除消息不需要额外确认,手动确认--推送消息后,需要等到收到确认回复再去删除消息
4.消费处理回调函数指针:队列有一条消息后,通过哪个函数进行处理(函数内部其实逻辑固定---向指定客户端推送消息)
- 消费者管理:
管理思想:
以队列为单元进行管理每个消费者订阅的都是指定队列的消息,消费者对消息进行确认也是以队列进行确认。最关键的是:当指定队列中有消息了,必然是获取订阅了这个队列的
队列消费者管理结构
数据信息:消费者链表--保存当前队列的所有消费者信息(RR轮转每次取出下一个消费者进行消息推送---条消息只需要被一个客户端处理即可)
管理操作:
1.新增消费者;2.RR轮转获取一个消费者;3.删除消费者; 4.队列消费者数量; 5. 是否为空
- 管理操作:
1.初始化队列消费者结构。 2.删除队列消费者结构; 3.向指定队列添加消费者; 4.获取指定队列消费者; 5.删除指定队列消费者
具体的回调函数是在信道中进行实现的
具有多个发布消息的消费者想要进行发布消息时,只采用一个消费者即可
- 信道(通信通道)管理模块:
一个连接可能会对应有多个通信通道,
一旦某个客户端要关闭通信,关闭的不是连接,而是自己对应的通信通道,关闭信道我们就需要将客户端的订阅给取消
信道管理:Channel
信道是网络通信中的一个概念,叫做通信通道。
网络通信的时候,必然都是通过网络通信连接来完成的,为了能够更加充分的利用资源,因此对通信连接又进行了进一步的细化,细化出了通信通道。对于用户来说,一个通信通道,就是进行网络通信的载体,而一个真正的通信连接,可以创建出多个通信通道每一个信道之间,在用户的眼中是相互独立的,而在本质的底层它们使用同一个通信连接进行网络通信。
因此,因为信道是用户眼中的一个通信通道,所以所有的网络通信服务都是由信道提供的。
- 信道提供的服务操作:
1.声明/删除交换机
2.声明/删除队列
3.绑定/解绑队列与交换机
4.发布消息/订阅队列消息/取消队列订阅/队列消息确认
- 信道要管理的数据:
0.信道ID
1.信道关联的虚拟机句柄:
2.信道关联的消费者句柄:当信道关闭的时候,所有关联的消费者订阅都要取消,相当于删除所有的相关消费者。
3.工作线程池句柄:信道进行了消息发布到指定队列操作之后;从指定队列获取一个消费者,对这条消息进行消费。
也就是将这条消息推送给一个客户端的操作交给线程池执行。
并非每个信道都有一个线程池,而是整个服务器有一个线程池,大家所有的信道都是通过同一个线程池进行异步操作而已信道的管理操作
1.创建一个信道
2.关闭一个信道
3.获取指定信道的句柄
- 连接管理模块:
就是一个网络通信对应的连接。因为当一个连接要关闭的时候,就应该把连接关联的信道全部关闭,因此也有数据管理至少要管理关联的信道
连接管理:
概念:网络通信连接
在网络通信模块中,我们使用muduo库来实现底层通信,muduo库中本身就有Connection连接的概念和对象类但是我们的连接中,还有一个上层通信信道的概念,这个概念在muduo库中是没有的。因此,我们需要在用户的层面,对这个muduo库中的Connection连接进行二次封装。形成我们
- 自己所需的连接管理管理数据:
1.muduo库的通信连接
2.当前连接关联的信道管理句柄连接提供的操作:
1.创建信道
2.关闭信道
- 管理的操作:
1.新增连接
2.关闭连接
3.获取指定连接信息备注:muduo库中也是有chanel信道的,但是这个信道不是进行面向用户的,是面向底层的socket的。
5.7.2、客户端模块
- 消费者管理模块
一个订阅客户端,当订阅一个队列消息的时候,其就相当于创建了一个消费者
消费者管理模块
1.消费者标识
2.订阅的队列名称
3.自嶼敖禦朏劄涺鍺躪吖哙輅蹽獼蓐自嗫蔞镲泱金标志
4.消息回调处理函数指针
当前消费者订阅了某一个队列的消息,这个队列有了消息后,就会将消息推送给这个客户端,这时候收到了消息则使用回调函数进行处理,处理完毕后根据确认标志决定是否进行消息确认。
管理操作:增删查
- 信道管理模块
客户端的信道与服务端的信道是一一对应的,服务端信道提供的服务,客户端都有相当于,服务端为客户端提供服务,客户端为用户提供服务
信道管理模块
所有提供的操作与服务端雷同,因为客户端给用户要提供什么服务,服务器就要给客户端提供什么服务
- 管理信息:
0.信道ID
1.消费者管理句柄:每个信道都有自己相关的消费者
2.线程池句柄:对推送过来的消息进行回调处理,处理过程通过工作线程来进行
3.信道关联的连接
- 信道提供的服务:
1.声明/删除交换机
2.声明/删除队列
3.绑定/解绑队列与交换机4.发布消息/确认消息
5.订阅队列消息/取消订阅队列消息信道的管理:信道的增删查
6.创建/关闭信道
- 连接管理模块
对于用户来说,所有的服务都是通过信道完成的,信道在用户的角度就是一个通信通道(而不是连接)
因此所有的请求都是通过信道来完成的连接的管理就包含了客户端资源的整合
基于以上的三个模块封装实现:订阅客户端/发布客户端订阅客户端:订阅一个队列的消息,收到推送过来的消息进行处理
发布客户端:向一个交换机发布消息。
连接管理模块
客户端连接的管理,本质上是对客户端TcpClient的二次封装和管理面对用户,不需要有客户端的概念,连接对于用户来说就是客户端,通过连接创建信道,通过信道完成自己所需服务因此,当前客户端这边的连接,对于用户来说就是一个资源的载体管理操作:
1.连接服务器
2.创建信道
3.关闭信道
4.关闭连接
管理的资源:工作线程池,连接关联的信道管理句柄
- 异步工作模块
异步工作池模块
1.TcpClient模块需要一个EventLoopThread模块进行IO事件监控
2、收到推送消息后,需要对推送过来的消息进行处理,因此需要一个线程池来帮助我们完成消息处理的过程
将异步工作线程模块单独拎出来,原因是多个连接用一个EventoopThread进行!0事件监控就够了,以及所有的推送消息处理也只需要有一个线程池
就够了并不需要每个连接都有一个EventLoop,也不需要每个信道的消息处理都有自己的线程池。
5.7.3、模块整合
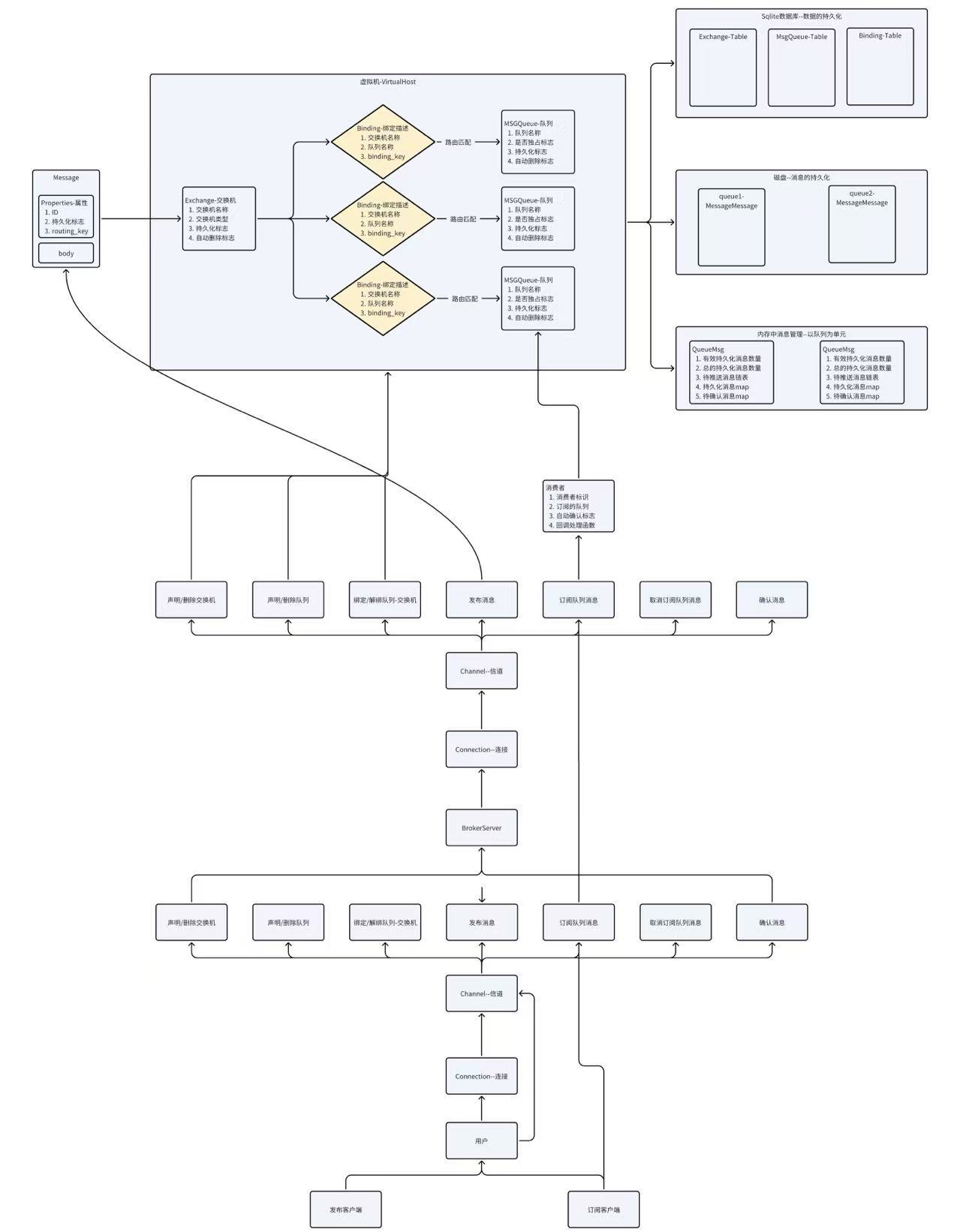
客户端想要进行将消息进行发布到broker 消息队列服务器,首先要先进行connection 进行与 broker建立TCP网络通信通道,建立TCP通过后进行通过信道进行声明交换机、绑定、队列的资源,观察是否已经在消息队列服务器中创建完成,如果没有进行创建完成,则broker进行创建缺失的资源,反之broker服务器直接进行接收发布客户端的声明,进行注册到相对应的Exchange Table、Bingding Table、Queue Table中,这三张表又进行组成一个虚拟主机,每个broker中有若干个虚拟主机,在进行建立TCP网络通道时就确定了以后进行通过这个发布客户端的信道进行并发的发送消息的时候都进行注册到指定的虚拟主机进行管理。
当发布客户端进行向消息队列服务器中进行发布消息,消息首先交给交换机进行处理,交换机根据自身的类型,通过消息中携带的routing_key 进行和队列中的 binding_key进行比较,确定消息应该进行放到哪个队列中。
消息进行来到消息队列中,会进行两种方式的存储,分别是内存存储和磁盘持久化存储。数据库的方式进行存储本质就是将数据进行结构化的存储的到磁盘中,数据库就是对磁盘的封装与管理。
当消费者客户端上线时,它也会建立 Connection 和 Channel,并通过 Channel 发起对队列的订阅请求。
服务端接收到订阅请求后,会从内存中的队列读取消息,并通过 Channel 发送给消费者。如果队列中的消息已被持久化但不在内存,还会从磁盘中拉取并恢复。
消费者收到消息后,会在处理完成后向服务端发送 ACK(确认)信号。这时,服务端会从内存队列中移除该消息,同时更新磁盘存储,将消息从队列文件中标记为已消费,最终达到消息消费完成的状态。
六、公共模块
先进行实现工具模块,因为工具模块在后续核心代码逻辑部分会进行用到,先将所有工具模块进行实现完成,可以进行防止后续进行实现核心模块时需要进行用到工具模块还需要进行重新实现,打乱代码核心模块的设计。
6.1、日志模块的设计
日志模块的设计主要是快速进行定位错误的位置
日志模块的设计
- 默认的日志打印信息
首先最先进行考虑的就是这个自定义进行实现的这个日志首先进行打印的信息,日志进行打印时首先就是时间、文件和该文件中代码的行数。
先进行利用time函数进行生成时间戳,然后利用localtime将时间戳进行转换成本地的时间,然后通过strftime将struct tm 时间格式转化为字符串,字符串的格式为 时:分:妙。最后通过日志级别、当前时间、当前文件名和当前行号的方式进行打印日志。
#ifndef __M_LOG_H__
#define __M_LOG_H__
#include<iostream>
#include<ctime>
#define DBG_LEVEL 0
#define INF_LEVEL 1
#define ERR_LEVEL 2
#define DEFAULT_LEVEL DBG_LEVEL
#define LOG(lev_str,lev,format,...)\
{\
if(lev>=DEFAULT_LEVEL)\
{\
time_t t=time(nullptr);\
struct tm* ptm=localtime(&t);\
char time_str[32];\
strftime(time_str,31,"%H:%M:%S",ptm);\
printf("[%s][%s][%s:%d]\t" format "\n",lev_str,time_str,__FILE__,__LINE__,##__VA_ARGS__);\
}\
}
#define DLOG(format, ...) LOG("DBG", DBG_LEVEL, format,##__VA_ARGS__)
#define ILOG(format, ...) LOG("INF", INF_LEVEL, format,##__VA_ARGS__)
#define ELOG(format, ...) LOG("ERR", ERR_LEVEL, format,##__VA_ARGS__)
#endif6.2、数据库工具模块的设计
简单封装了一个 SQLite3 基本操作的 C++ 辅助类,便于在项目中进行 SQLite 数据库操作
class SqliteHelper
{
public:
typedef int (*SqliteCallback)(void *, int, char **, char **);
SqliteHelper(const std::string &dbfile)
: _handler(nullptr), _dbfile(dbfile)
{
}
// 1、创建打开数据库
bool open(int safe_leve = SQLITE_OPEN_FULLMUTEX)
{
// safe_leve: 是可选参数,默认为 SQLITE_OPEN_FULLMUTEX,表示**线程安全(完全互斥)**的打开方式。
// int sqlite3_open(const char *filename, sqlite3 **ppDb) // 成功返回SQLITE_OK
// int sqlite3_open_v2(const char *filename, sqlite3 **ppDb, int flags, const char *zVfs );
int ret = sqlite3_open_v2(_dbfile.c_str(), &_handler, SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | safe_leve, nullptr);
if (ret != SQLITE_OK)
{
ELOG("创建/打开sqlite失败:", sqlite3_errmsg(_handler));
return false;
}
return true;
}
// 2、针对打开的数据库进行执行操作
bool exec(const std::string &sql, SqliteCallback cb, void *arg)
{
// int sqlite3_exec(sqlite3*, char *sql, int (*callback)(void*,int,char**,char**), void* arg,char **err)
int ret = sqlite3_exec(_handler, sql.c_str(), cb, arg, nullptr);
if (ret != SQLITE_OK)
{
ELOG("%s \n语句执行失败: %s", sql.c_str(), sqlite3_errmsg(_handler));
return false;
}
return true;
}
// 3、进行关闭数据库
void close()
{
// int sqlite3_close_v2(sqlite3*);
if (_handler)
{
sqlite3_close_v2(_handler);
}
}
private:
std::string _dbfile; // 表示数据库文件路径,是 SQLite 要打开或创建的文件。
sqlite3 *_handler; // 指向 SQLite 的数据库句柄(sqlite3*),所有操作都基于此句柄进行。
};类成员概述
-
_dbfile:记录要操作的数据库文件路径。
-
_handler:SQLite 提供的数据库句柄,几乎所有数据库操作(打开、执行、关闭等)都基于它进行。
构造函数
构造时传入数据库文件路径,初始化句柄为 nullptr,表示尚未打开数据库。
open函数--打开(创建)数据库
默认使用 SQLITE_OPEN_FULLMUTEX,这是 线程安全(完全互斥)模式。
使用 sqlite3_open_v2 打开(或创建)数据库:
SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE:可读写,若文件不存在则创建。
如果打开失败,通过 sqlite3_errmsg 获取错误信息并打印(ELOG 函数,应该是用户自己封装的日志宏)。
exec函数--执行SQL语句
- 参数:
sql:要执行的 SQL 语句。
cb:回调函数,查询类 SQL(如 SELECT)时用于逐行处理结果。
arg:传递给回调函数的用户数据指针(可用于上下文等)。
- 使用 sqlite3_exec 统一执行 SQL:
如果是查询(如 SELECT),会调用回调函数处理结果。
如果是非查询(如 INSERT/UPDATE/DELETE),则不调用回调函数。
执行失败时,同样打印错误信息。
close函数--关闭数据库
如果 _handler 存在,则调用 sqlite3_close_v2 关闭数据库连接。
6.3、字符串分割工具模块的设计
将字符串进行打散成若干字串,后续项目中将用于消息队列中其他元素从数据库中进行的反序列化以及路由模块规则的指定和主题路由时候的规则匹配。
class StrHelper
{
public:
static size_t split(const std::string &str, const std::string &sep, std::vector<std::string> &result)
{
int pos = 0;
int idx = 0;
while (idx < str.size())
{
pos = str.find(sep, idx);
if (pos == std::string::npos)
{
result.push_back(str.substr(idx));
return result.size();
}
if (pos == idx)
{
idx = pos + sep.size();
continue;
}
result.push_back(str.substr(idx, pos - idx));
idx = pos + sep.size();
}
return result.size();
}
};6.4、唯一ID生成类
class UUIDHelper
{
public:
static std::string uuid()
{
std::random_device rd;
std::mt19937_64 gernator(rd());
std::uniform_int_distribution<int> distribution(0, 255);
std::stringstream ss;
for (int i = 0; i < 8; i++)
{
ss << std::setw(2) << std::setfill('0') << std::hex << distribution(gernator);
if (i == 3 || i == 5 || i == 7)
{
ss << "-";
}
}
static std::atomic<size_t> seq(1);
size_t num = seq.fetch_add(1);
for (int i = 7; i >= 0; i--)
{
ss << std::setw(2) << std::setfill('0') << std::hex << ((num >> (i * 8)) & (0xff));
if (i == 6)
{
ss << "-";
}
}
std::cout << ss.str() << std::endl;
return ss.str();
}
};
6.5、文件工具模块的设计
文件类的模块在整个项目中起到了队列中消息持久化的作用,你或许会有疑问,为什么不使用数据库进行持久化存储,而是采用文件的方式?
- 队列数据文件:
队列里的消息数据以二进制块顺序写到文件里(类似 Kafka 的 Segment 文件)。
只要按偏移顺序写,性能非常高。
文件的偏移管理、顺序读取,逻辑比数据库更简单。
- 队列恢复时,直接文件顺序读:
不需要 SQL 查询,直接顺序 read() 文件,效率高。
- 日志、元数据、垃圾回收:
例如队列快照、临时备份文件,可能更适合文件操作。
数据库并不一定适合频繁“追加-回收-追加”的场景。
class FileHelper
{
public:
FileHelper(const std::string& filename)
:_filename(filename)
{
}
bool exists()
{
struct stat st;
return (stat(_filename.c_str(),&st))==0;
}
size_t size()
{
struct stat st;
int ret=stat(_filename.c_str(),&st);
if(ret<0)
{
return 0;
}
return st.st_size;
}
bool read(char* body,size_t offset,size_t len)
{
//1、进行打开文件
std::ifstream ifs(_filename,std::ios::binary|std::ios::in);
if(ifs.is_open()==false)
{
ELOG("%s 文件打开失败",_filename);
return false;
}
//2、跳转到文件的读写位置
ifs.seekg(offset,std::ios::beg);
//3、进行读取文件的内容
ifs.read(body,len);
if(ifs.good()==false)
{
ELOG("%s 文件读取失败",_filename);
ifs.close();
return false;
}
//4、关闭文件
ifs.close();
return true;
}
bool read(std::string& body)
{
//1、获取当前文件的大小
size_t fsize=this->size();
body.resize(fsize);
return read(&body[0],0,fsize);
}
bool write(const char* body,size_t offset,size_t len)
{
//1、进行打开文件
std::fstream fs(_filename,std::ios::binary|std::ios::in|std::ios::out);
if(fs.is_open()==false)
{
ELOG("%s 文件打开失败",_filename);
return false;
}
//2、跳转到文件的读写位置
fs.seekg(offset,std::ios::beg);
//3、向文件中进行写入数据
fs.write(body, len);
if (fs.good() == false)
{
ELOG("%s 文件写入数据失败!!", _filename.c_str());
fs.close();
return false;
}
//4. 关闭文件
fs.close();
return true;
}
bool write(const std::string& body)
{
return write(body.c_str(), 0, body.size());
}
static std::string parentDirectory(const std::string& filename)
{
//aa/bb/cc/text
size_t pos=filename.find_last_of("/");
if(pos==std::string::npos)
{
return "./";
}
std::string path=filename.substr(0,pos);
return path;
}
bool rename(const std::string& nname)
{
int ret=::rename(_filename.c_str(),nname.c_str());
return ret==0;
}
static bool createFile(const std::string& filename)
{
//进行打开文件,如果文件不存在则自动进行创建
std::fstream ofs(filename,std::ios::binary|std::ios::out);
if(ofs.is_open()==false)
{
ELOG("打开文件失败 %s ",filename);
return false;
}
ofs.close();
return true;
}
static bool removeFile(const std::string& filename)
{
return ::remove(filename.c_str())==0;
}
static bool createDirectory(const std::string& path)
{
//aaa/bb/c/
size_t pos=0;
size_t index=0;
while(index<path.size())
{
pos=path.find('/',index);
if(pos==std::string::npos)
{
return mkdir(path.c_str(),0775)==0;
}
std::string subpath=path.substr(0,pos);
int ret=mkdir(subpath.c_str(),0775);
if(ret!=0 && errno!=EEXIST)
{
ELOG("%s 创建目录 失败:%s",subpath.c_str(),strerror(errno));
return false;
}
index=pos+1;
}
return true;
}
static bool removeDirectory(const std::string& path)
{
std::string cmd = "rm -rf " + path;
return (system(cmd.c_str()) != -1);
}
private:
std::string _filename;
};判断文件是否存在
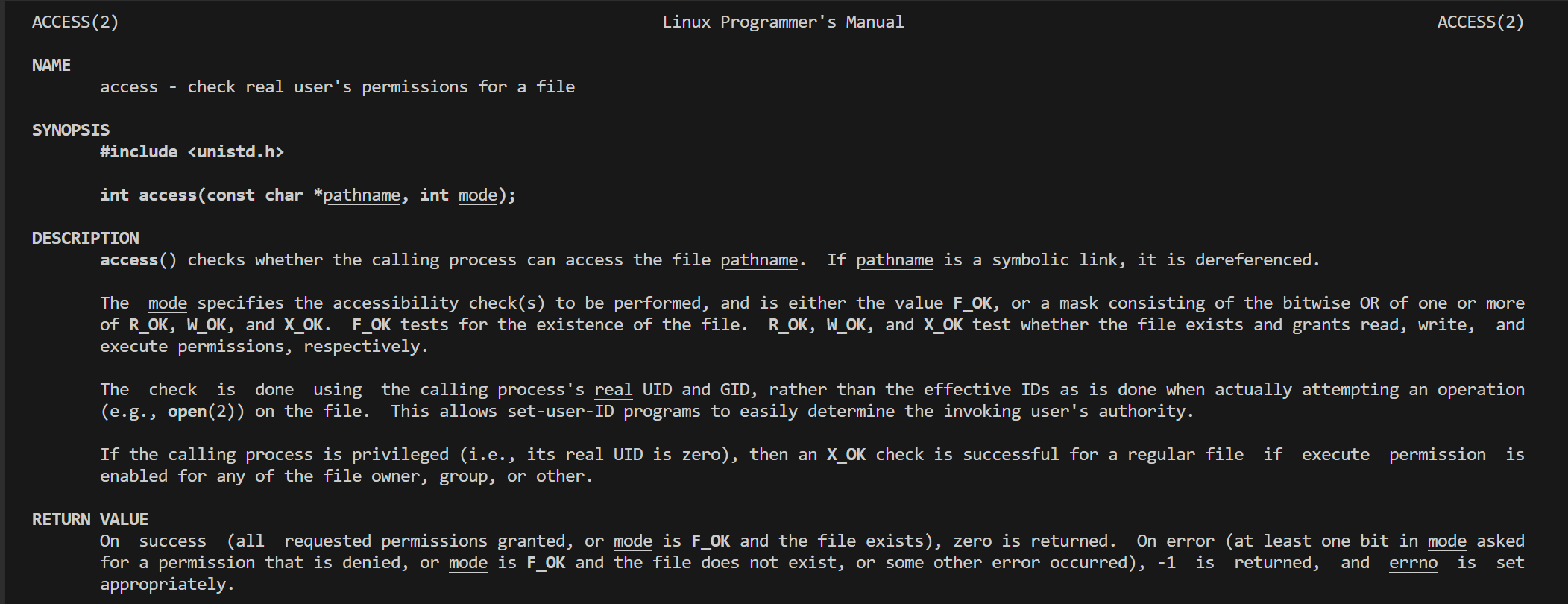
exists: man access 专门进行判断文件是否存在 或者进行观察文件有哪些操作权限
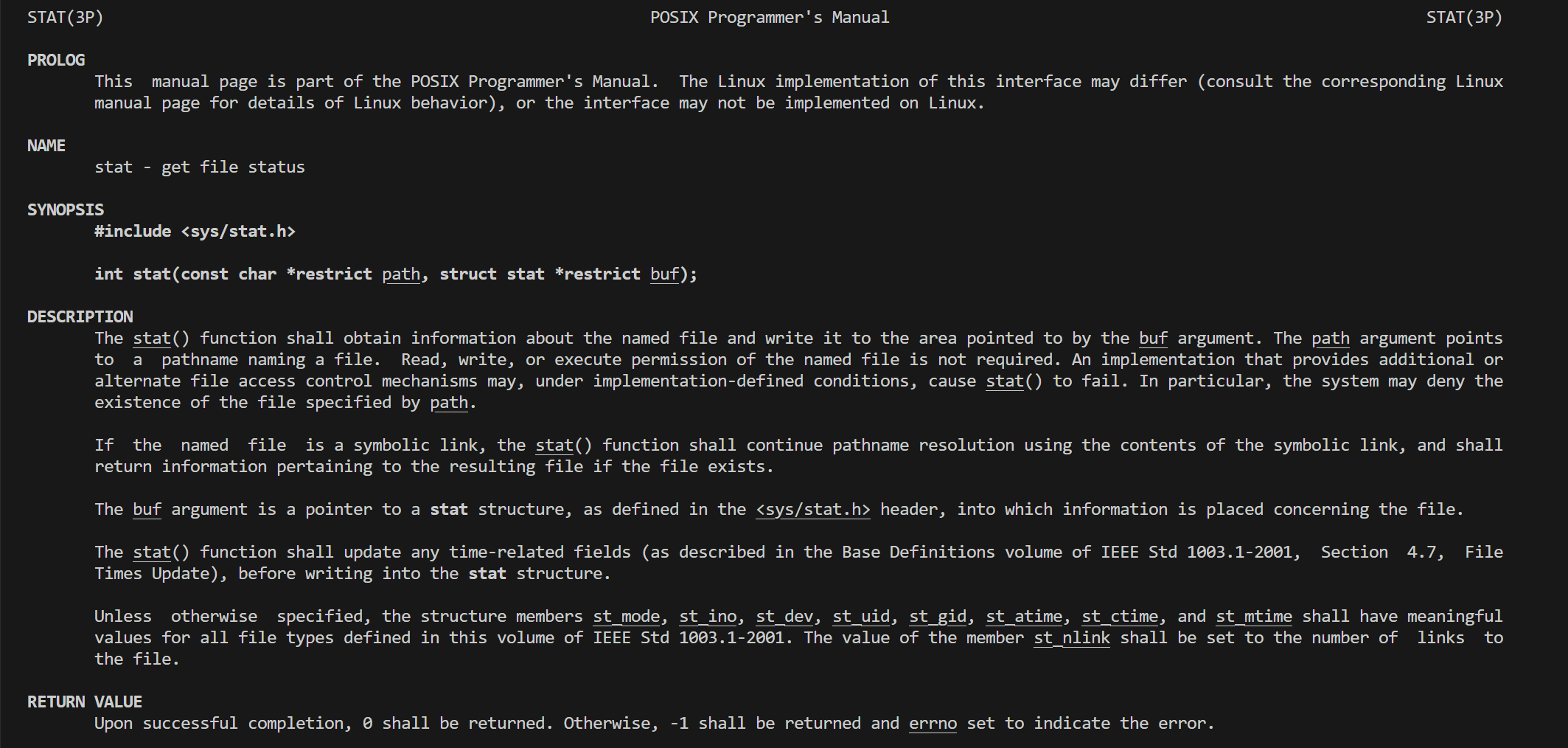
man stat 获取文件状态属性的接口 获取文件的属性直接进行放到stat结构体中
- 函数参数
const char *pathname: 要查询的文件或目录的路径。
struct stat *statbuf: 指向 stat 结构体的指针,用于接收文件状态信息。
- 返回值:
成功返回 0
失败返回 -1,并设置 errno,例如文件不存在会设置 ENOENT
stat 保存了文件的各种信息(数据),具体结构如下:
struct stat
{
dev_t st_dev; // 所在设备
ino_t st_ino; // inode 号
mode_t st_mode; // 文件类型和权限
nlink_t st_nlink; // 硬链接数
uid_t st_uid; // 文件所有者的用户 ID
gid_t st_gid; // 文件所有者的组 ID
dev_t st_rdev; // 设备类型(如果是特殊文件)
off_t st_size; // 文件大小(字节数)
blksize_t st_blksize; // 块大小(文件系统 I/O 优化)
blkcnt_t st_blocks; // 文件所占的块数
time_t st_atime; // 最近访问时间
time_t st_mtime; // 最近修改时间
time_t st_ctime; // 状态最后更改时间
};获取文件的大小
通过stat直接进行获取文件的大小
读取文件中的内容
用二进制模式打开文件,跳转到 offset 处,读取 len 字节到 body 中
进行传参是&body[ 0 ] 的解释:
read函数需要一个可写入的缓冲区(char*),把文件内容直接读到这个缓冲区里。在 C++11 及之后,std::string 的底层是一个连续的字符数组(和 std::vector<char> 类似)。因此,&body[0] 就是把 std::string 当成一个 char* 缓冲区使用,指向首元素。
写入文件内容
以二进制读写模式打开文件,写入数据到指定 offset。
同样记录日志和返回写入是否成功。
获取父目录路径
取到最后一个 / 之前的字符串,得到文件所在的目录。
文件重命名
使用C库中的rename函数进行文件的重命名
创建文件(打开文件)
通过流的方式进行打开文件,并不是真正意义上的创建新文件。
移动文件(删除文件)
直接通过C标准库中的remove进行删除文件。
创建目录
先进行依次进行找到最长目录然后进行创建。
删除目录
用系统命令删除目录及其所有内容,这种方式还是比较少见的。
6.6、消息类型proto文件的编写
我们进行实现的消息队列是需要进行在网络中进行通信的,所以说消息在网络中进行传输的过程中是需要设计到序列化和反序列化
将哪些消息的数据进行序列化和反序列化?
消息本身的因素
- 消息的属性
- 消息的ID
- 是否需要进行持久化存储
- routing_key
- 消息的内容
- 消息是否有效
消息额外的因素
- 消息的存储位置
- 消息的长度
syntax="proto3";
package ys;
enum ExchangeType
{
UNKNOWTYPE=0;
DIRECT=1;
FANOUT=2;
TOPIC=3;
};
enum DeliveryMode
{
UNKONWMODE=0;
UNDURABLE=1;
DURABLE=2;
};
message BasicProperties
{
string id=1;
DeliveryMode delivery_mode=2;
string routing_key=3;
};
message Message
{
message Payload
{
BasicProperties properties = 1;
string body = 2;
string valid = 3;
};
Payload payload = 1;
uint32 offset = 2;
uint32 length = 3;
};6.7、消息队列的协议定制proto文件的编写
定义标准化的通信协议
客户端和服务端在进行 MQ 相关的操作(如信道、交换机、队列的管理,消息的收发)时,需要明确的请求/响应格式。
这个 proto 文件就定义了这些操作的“标准数据结构”。
syntax = "proto3";
package ys;
import "mq_msg.proto";
//信道的打开与关闭
message openChannelRequest
{
string rid=1; //请求ID
string cid=2; //信道ID
}
message closeChannelRequest
{
string rid=1;
string cid=2;
}
//交换机的声明与删除
message declareExchangeRequest
{
string rid=1;
string cid=2;
string exchange_name=3;
ExchangeType exchange_type=4;
bool durable=5;
bool auto_delete=6;
map<string,string> args=7;
}
message deleteExchangeRequest
{
string rid=1;
string cid=2;
string exchange_name=3;
}
//队列的声明与删除
message declareQueueRequest
{
string rid=1;
string cid=2;
string queue_name=3;
bool exclusive=4;
bool durable=5;
bool auto_delete=6;
map<string,string> args=7;
}
message deleteQueueRequest
{
string rid=1;
string cid=2;
string queue_name=3;
}
//队列的绑定与解绑
message queueBindRequest
{
string rid=1;
string cid=2;
string exchange_name=3;
string queue_name=4;
string binding_key=5;
}
message queueUnBindRequest
{
string rid=1;
string cid=2;
string exchange_name=3;
string queue_name=4;
}
//消息的发布
message basicPublishRequest
{
string rid=1;
string cid=2;
string exchange_name=3;
string body=4;
BasicProperties properties=5;
}
//消息的确认
message basicAckRequest
{
string rid=1;
string cid=2;
string queue_name=3;
string message_id=4;
}
//队列的订阅
message basicConsumeRequest
{
string rid=1;
string cid=2;
string consume_tag=3;
string queue_name=4;
bool auto_ack=5;
}
//队列的取消
message basicCancelRequest
{
string rid=1;
string cid=2;
string consume_tag=3;
string queue_name=4;
}
//消息的推送
message basicConsumeResponse
{
string cid=1;
string consume_tag=2;
string body=3;
BasicProperties properties=4;
}
//通用的响应
message basicCommonResponse
{
string rid=1;
string cid=2;
bool ok=3;
}