DAY 43 复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
关于 Dataset
从谷歌图片中抓取了 1000 多张猫和狗的图片。问题陈述是构建一个模型,该模型可以尽可能准确地在图像中的猫和狗之间进行分类。
图像大小范围从大约 100x100 像素到 2000x1000 像素。
图像格式为 jpeg。
已删除重复项。
猫狗图像分类 --- Cats and Dogs image classification
步骤
导入所需的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset, Subset
from torchvision import transforms, datasets
import random
import os
数据准备和预处理
# 设置随机种子确保可复现
torch.manual_seed(42)
np.random.seed(42)
random.seed(42)
# 设置设备(优先使用GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# --- 关键修改1:调整为本地绝对路径并检查目录存在性 ---
data_dir = "d:\\code\\trae\\python_60\\Cat_and_Dog" # 你的本地项目根目录
train_dir = os.path.join(data_dir, "train") # 指向你的实际训练数据目录(需包含类别子文件夹)
# 检查训练目录是否存在
if not os.path.isdir(train_dir):
raise FileNotFoundError(
f"训练目录不存在: {train_dir}\n"
"请按以下结构准备数据:\n"
f"{data_dir}\n"
"└── train\n"
" ├── cat\n" # 类别子文件夹1(如猫)
" └── dog\n" # 类别子文件夹2(如狗)
"(每个子文件夹存放对应类别的图片)"
)
# --- 关键修改2:优化数据划分逻辑(修正索引生成问题) ---
proportion = 0.2 # 验证集比例
batch_size = 32 # 批量大小
# 加载数据集(使用训练目录)
data = datasets.ImageFolder(root=train_dir, transform=transforms.Compose([
transforms.Resize(256), # 缩放到256x256
transforms.CenterCrop(224), # 中心裁剪224x224
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转
transforms.ColorJitter( # 颜色抖动增强
brightness=0.2,
contrast=0.2,
saturation=0.2
),
transforms.ToTensor(),
transforms.Normalize( # ImageNet标准化参数
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
]))
n_total = len(data) # 总样本数
all_indices = list(range(n_total)) # 生成0~n_total-1的索引(修正原range(1,n)的0索引遗漏问题)
random.shuffle(all_indices) # 打乱索引确保随机划分
# 按比例分割训练集和验证集
n_val = int(proportion * n_total)
val_indices = all_indices[:n_val] # 前n_val个作为验证集
train_indices = all_indices[n_val:] # 剩余作为训练集
train_set = Subset(data, train_indices)
val_set = Subset(data, val_indices)
# 数据加载器(补充num_workers提升加载效率)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False, num_workers=4)定义卷积神经网络模型
实例化模型并移至计算设备(GPU或CPU)
定义损失函数和优化器(调整学习率和权重衰减)
学习率调度(移除不兼容的verbose参数)
# 定义卷积神经网络模型(优化版)
class SimpleCNN(nn.Module):
def __init__(self, dropout_rate=0.5):
super().__init__()
# 卷积特征提取模块(含残差连接)
self.conv_layers = nn.Sequential(
# 第一层:输入3通道(RGB)→16通道
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2), # 224x224 → 112x112
# 第二层:16→32通道 + 残差连接
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1), # 残差分支
nn.BatchNorm2d(32),
nn.MaxPool2d(2), # 112x112 → 56x56
# 第三层:32→64通道
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Dropout2d(0.1),
nn.MaxPool2d(2), # 56x56 → 28x28
# 第四层:64→128通道
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Dropout2d(0.1),
nn.MaxPool2d(2) # 28x28 → 14x14(与原计算一致)
)
# 动态计算全连接层输入维度(避免硬编码错误)
with torch.no_grad(): # 虚拟输入计算特征尺寸
dummy_input = torch.randn(1, 3, 224, 224) # 输入尺寸与数据预处理一致
dummy_output = self.conv_layers(dummy_input)
self.feature_size = dummy_output.view(1, -1).size(1)
# 全连接分类模块(增加正则化)
self.fc_layers = nn.Sequential(
nn.Linear(self.feature_size, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(256, 2) # 修正:二分类输出维度为2
)
def forward(self, x):
x = self.conv_layers(x)
x = x.view(x.size(0), -1) # 展平特征
x = self.fc_layers(x)
return x
# 实例化模型并移至计算设备(GPU或CPU)
model = SimpleCNN(dropout_rate=0.3).to(device) # 调整Dropout率(0.3比0.5更温和)
# 定义损失函数和优化器(调整学习率和权重衰减)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # 学习率降至0.001,权重衰减微调
# 学习率调度(移除不兼容的verbose参数)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='max', # 监控指标为验证准确率(越大越好)
factor=0.5, # 学习率衰减因子
patience=2 # 等待2个epoch无提升再衰减
)构建深度学习模型
训练主模型
# 训练模型主函数(优化版)
def train_model(
model: nn.Module,
train_loader: DataLoader,
val_loader: DataLoader,
criterion: nn.Module,
optimizer: optim.Optimizer,
scheduler: optim.lr_scheduler._LRScheduler,
epochs: int
) -> tuple[list[float], list[float], list[float], list[float]]:
# 初始化训练和验证过程中的监控指标
train_losses: list[float] = [] # 存储每个epoch的训练损失
val_losses: list[float] = [] # 存储每个epoch的验证损失
train_accuracies: list[float] = [] # 存储每个epoch的训练准确率
val_accuracies: list[float] = [] # 存储每个epoch的验证准确率
# 新增:早停相关变量(可选)
best_val_loss: float = float('inf')
early_stop_counter: int = 0
early_stop_patience: int = 5 # 连续5个epoch无提升则停止
# 主训练循环 - 遍历指定轮数
for epoch in range(epochs):
# 设置模型为训练模式(启用Dropout和BatchNorm等训练特定层)
model.train()
train_loss: float = 0.0 # 累积训练损失
correct: int = 0 # 正确预测的样本数
total: int = 0 # 总样本数
# 批次训练循环 - 遍历训练数据加载器中的所有批次
for inputs, targets in train_loader:
# 将数据移至计算设备(GPU或CPU)
inputs, targets = inputs.to(device), targets.to(device)
# 梯度清零 - 防止梯度累积(每个批次独立计算梯度)
optimizer.zero_grad()
# 前向传播 - 通过模型获取预测结果
outputs = model(inputs)
# 计算损失 - 使用预定义的损失函数(如交叉熵)
loss = criterion(outputs, targets)
# 反向传播 - 计算梯度
loss.backward()
# 参数更新 - 根据优化器(如Adam)更新模型权重
optimizer.step()
# 统计训练指标
train_loss += loss.item() # 累积批次损失
_, predicted = outputs.max(1) # 获取预测类别
total += targets.size(0) # 累积总样本数
correct += predicted.eq(targets).sum().item() # 累积正确预测数
# 计算当前epoch的平均训练损失和准确率
train_loss /= len(train_loader) # 平均批次损失
train_accuracy = 100.0 * correct / total # 计算准确率百分比
train_losses.append(train_loss) # 记录损失
train_accuracies.append(train_accuracy) # 记录准确率
# 模型验证部分
model.eval() # 设置模型为评估模式(禁用Dropout等)
val_loss: float = 0.0 # 累积验证损失
correct = 0 # 正确预测的样本数
total = 0 # 总样本数
# 禁用梯度计算 - 验证过程不需要计算梯度,节省内存和计算资源
with torch.no_grad():
# 遍历验证数据加载器中的所有批次
for inputs, targets in val_loader:
# 将数据移至计算设备
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播 - 获取验证预测结果
outputs = model(inputs)
# 计算验证损失
loss = criterion(outputs, targets)
# 统计验证指标
val_loss += loss.item() # 累积验证损失
_, predicted = outputs.max(1) # 获取预测类别
total += targets.size(0) # 累积总样本数
correct += predicted.eq(targets).sum().item() # 累积正确预测数
# 计算当前epoch的平均验证损失和准确率
val_loss /= len(val_loader) # 平均验证损失
val_accuracy = 100.0 * correct / total # 计算验证准确率
val_losses.append(val_loss) # 记录验证损失
val_accuracies.append(val_accuracy) # 记录验证准确率
# 打印当前epoch的训练和验证指标
print(f'Epoch {epoch+1}/{epochs}')
print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_accuracy:.2f}%')
print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_accuracy:.2f}%')
print('-' * 50)
# 更新学习率调度器(修正mode为min,匹配验证损失)
scheduler.step(val_loss) # 传入验证损失,mode='min'
# 新增:早停逻辑(可选)
if val_loss < best_val_loss:
best_val_loss = val_loss
early_stop_counter = 0
# 可选:保存最佳模型权重
torch.save(model.state_dict(), 'best_model.pth')
else:
early_stop_counter += 1
if early_stop_counter >= early_stop_patience:
print(f"Early stopping at epoch {epoch+1}")
break
# 返回训练和验证过程中的所有指标,用于后续分析和可视化
return train_losses, val_losses, train_accuracies, val_accuracies
# 训练模型(保持调用方式不变)
epochs = 20
train_losses, val_losses, train_accuracies, val_accuracies = train_model(
model, train_loader, val_loader, criterion, optimizer, scheduler, epochs
)
# 可视化训练过程(保持原函数不变)
def plot_training(train_losses, val_losses, train_accuracies, val_accuracies):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='Train Accuracy')
plt.plot(val_accuracies, label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.title('Training and Validation Accuracy')
plt.tight_layout()
plt.show()
plot_training(train_losses, val_losses, train_accuracies, val_accuracies)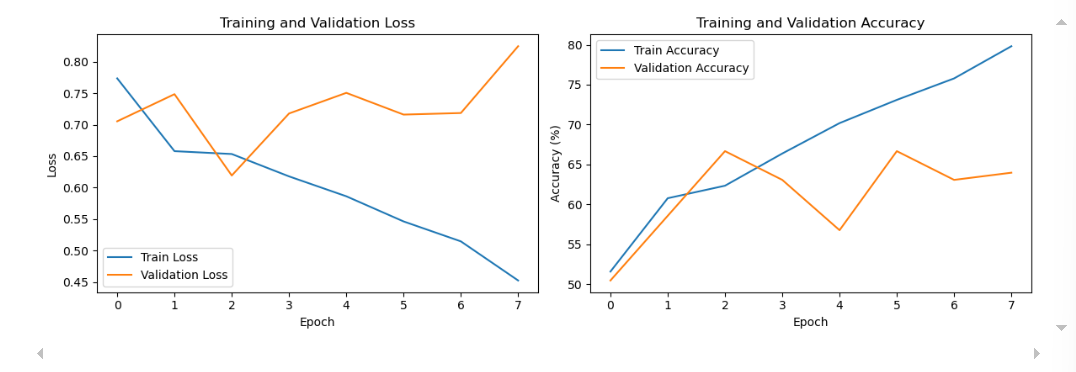
模型评估结构
获取预测
@浙大疏锦行