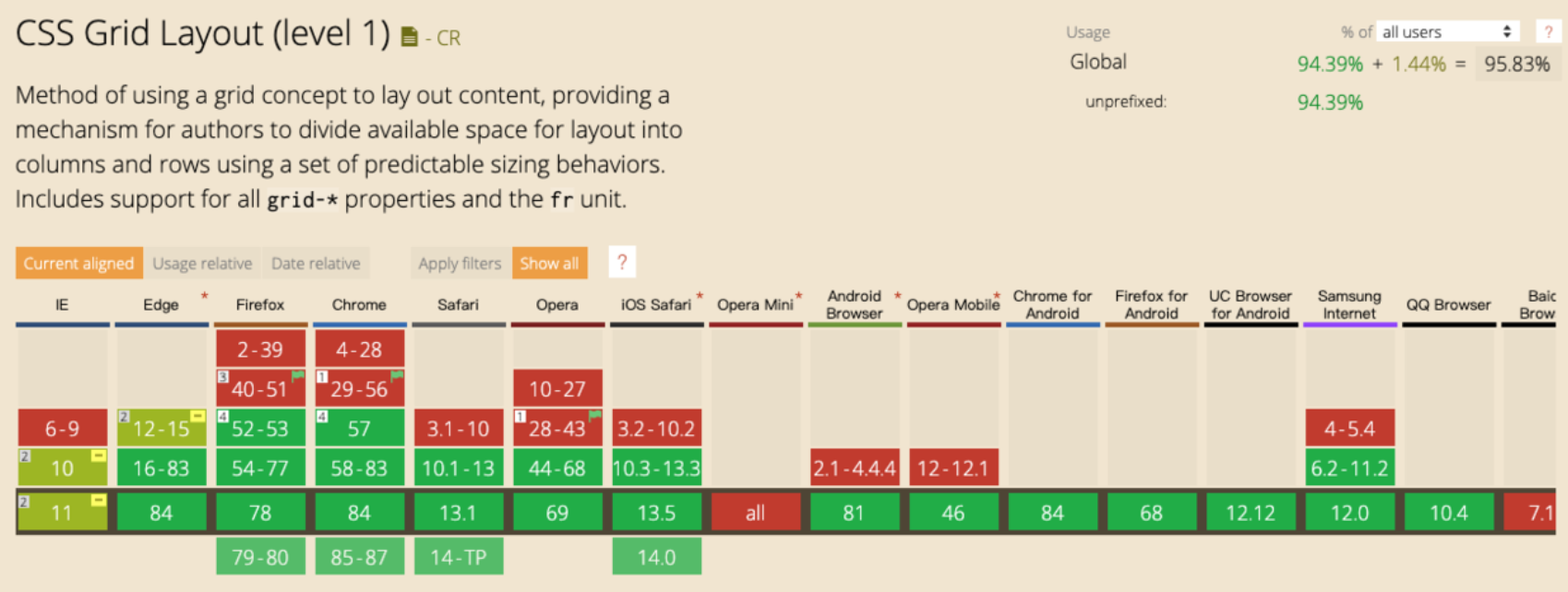
当你熟练地用正则表达式查找替换代码时,这个工具的历史可以追溯到1943年。那时候还没有计算机,更别说编程语言了。
从神经网络到文本匹配
故事要从两个神经生理学家说起。1943年,Warren McCulloch和Walter Pitts发表了一篇论文《A logical calculus of the ideas immanent in nervous activity》。这篇论文不仅是正则表达式的起点,同时也提出了第一个神经网络的数学模型。
很有意思,对吧?今天我们用来处理文本的正则表达式,竟然和人工智能有着共同的起源。这或许说明了一个道理:很多看似不相关的技术,在底层往往有着相似的数学基础。
真正给正则表达式命名的是数学家Stephen Kleene。1956年,他在论文《Representation of events in nerve nets and finite automata》中首次提出了"regular sets"和"regular expressions"这两个术语。数学家就是数学家,总能把复杂的概念用精确的语言表达出来。
Unix之父的贡献
12年后,一个传奇人物登场了。1968年,Ken Thompson发表了《Regular Expression Search Algorithm》。这个名字你可能不熟悉,但他的作品你肯定知道:Unix操作系统、B编程语言、UTF-8编码。可以说,没有Ken Thompson,就没有今天的计算机世界。
Ken Thompson不满足于只写论文,他把正则表达式集成到了自己的QED编辑器里。当时要用正则表达式搜索,需要这样写:
g/<regular expression>/p这里g表示global search(全局搜索),p表示print(打印)。如果把"regular expression"缩写成"re",就变成了g/re/p。没错,这就是Unix命令行工具grep的由来。
每次用grep命令的时候,你实际上都在致敬这段历史。工具的命名往往蕴含着深刻的设计思想,grep这个看似随意的名字,其实承载着几代程序员的智慧结晶。
Perl推动的普及
后来的发展有两个关键节点。首先是Henry Spence发布了第一个非专有的regex库,让更多人能够使用这个工具。然后是Larry Wall创造了Perl语言,真正把正则表达式推向了主流。
Perl的实现往前走了一大步,在原有语法基础上增加了很多修改,形成了所谓的"Perl flavor"。后来大多数编程语言的正则表达式实现都基于Perl风格。这说明了一个道理:技术的传播往往不是最初的版本获胜,而是最实用、最易用的版本胜出。
Python的选择
今天,Python的标准模块re只支持Perl风格的正则表达式。这里有个有趣的现象。很多程序员对正则表达式又爱又恨。它功能强大,但学习曲线陡峭,写出来的表达式往往难以阅读。于是就有了这样一句名言:
"Some people, when confronted with a problem, think 'I know, I'll use regular expressions.' Now they have two problems."
—Jamie Zawinski, 1997
这句话道出了一个深刻的问题:工具的复杂性和实用性之间的平衡。正则表达式虽然强大,但如果不注意写法,很容易变成维护的噩梦。
无处不在的存在
今天,正则表达式真的是无处不在。从最新的JavaScript框架到70年代的Unix工具,从办公软件到现代编程语言,你很难找到一个不支持正则表达式的地方。可以说,一个编程语言如果不支持正则表达式,就不能称为完整的现代语言。
但是,尽管正则表达式在各种语言和框架中都很常见,它们在现代程序员的工具箱中还不够普及。原因就是那个陡峭的学习曲线。很多人觉得正则表达式太复杂,读起来像天书一样。
这其实说明了一个道理:技术的广泛应用和深度掌握是两回事。很多强大的工具都有这个特点,表面上看起来很普及,但真正能熟练运用的人并不多。
回顾正则表达式的发展历程,我们可以看到几个有趣的模式:
首先,真正有影响力的技术往往起源于基础研究,然后在工程实践中发扬光大。从神经网络研究到文本处理工具,这个跨越说明了基础科学研究的重要性。
其次,好的工具往往是在使用过程中不断演化的。从QED到grep,从Kleene的数学定义到Perl的实用扩展,每一步都是在解决实际问题的过程中自然发生的。