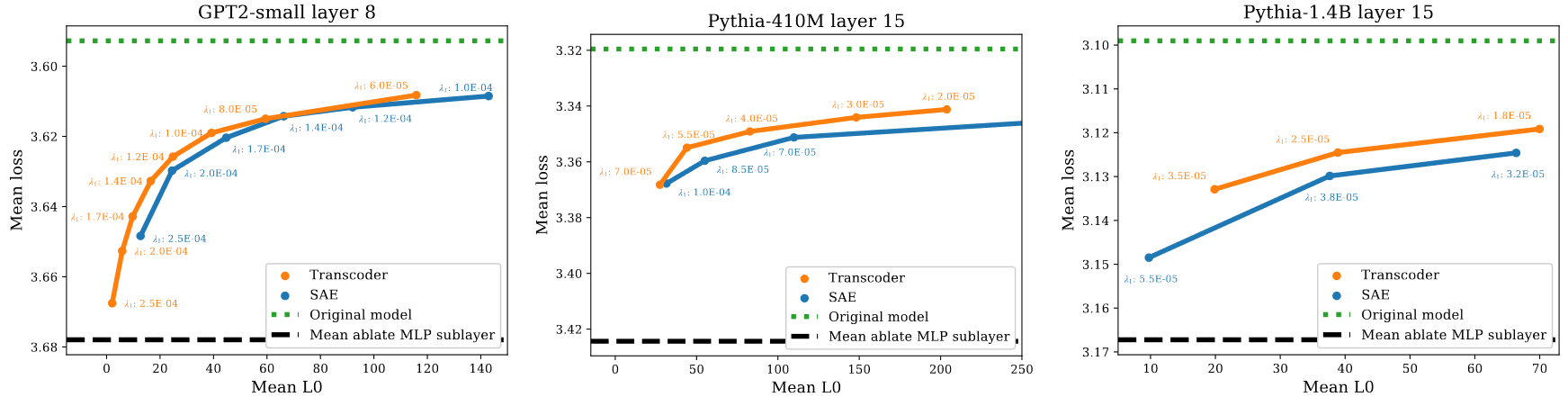
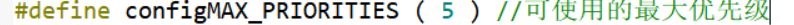本章主要介绍kafka consumer的配置参数及性能调优的点,其kafka的从零开始的安装到生产者,消费者的详解介绍、源码及分析及原理解析请到博主kafka专栏 。
1.消费者Consumer配置参数
| 配置参数 | 默认值 | 含义 |
|---|---|---|
bootstrap.servers | 无(必填) | Kafka 集群的初始连接地址列表,格式为 host:port。 |
key.deserializer | 无(必填) | Key 的反序列化类(如 org.apache.kafka.common.serialization.StringDeserializer)。 |
value.deserializer | 无(必填) | Value 的反序列化类。 |
group.id | 无(必填) | 消费者所属的消费者组 ID。 |
client.id | 空字符串 | 客户端标识符,用于日志和监控。 |
client.dns.lookup | default | DNS 解析方式:default(同时查 A 和 AAAA 记录),use_all_dns_ips(轮询所有 IP),resolve_canonical_bootstrap_servers_only(仅解析规范域名)。 |
group.instance.id | null | 消费者实例的唯一 ID(静态成员配置,减少再平衡)。 |
partition.assignment.strategy | RangeAssignor | 分区分配策略,可选 RangeAssignor、RoundRobinAssignor、StickyAssignor 或自定义类。 |
request.timeout.ms | 30000(ms) | 配置Consumer等待请求响应的最长时间。 |
metadata.timeout.age.ms | 30000(ms) | 配置元数据的过期时间,如果元数据集在此限定时间内没有进行更新,则会被强制更新,即使没有任何分区的变化或新的borker加入。 |
session.timeout.ms | 45000(45秒) | 消费者与 Broker 的心跳超时时间,超时则视为离线触发再平衡。 |
heartbeat.interval.ms | 3000(3秒) | 消费者发送心跳的间隔时间(需小于 session.timeout.ms 的 1/3)。 |
max.poll.interval.ms | 300000(5分钟) | 两次 poll() 调用的最大间隔时间,超时则消费者被踢出组。 |
fetch.min.bytes | 1 | Broker 返回给消费者的最小数据量(字节),不足时等待 fetch.max.wait.ms。 |
fetch.max.bytes | 52428800(50MB) | 单次拉取请求的最大数据量。 |
fetch.max.wait.ms | 500(0.5秒) | Broker 等待满足 fetch.min.bytes 的最长时间。 |
max.partition.fetch.bytes | 1048576(1MB) | 每个分区返回的最大数据量。 |
max.poll.records | 500 | 单次 poll() 返回的最大消息数。 |
auto.offset.reset | latest | 无偏移量或偏移量无效时的策略:earliest(最早)、latest(最新)、none(抛出异常)。 |
enable.auto.commit | true | 是否自动提交偏移量(建议手动提交以避免数据丢失)。 |
auto.commit.interval.ms | 5000(5秒) | 自动提交偏移量的间隔时间(仅当 enable.auto.commit=true 生效)。 |
isolation.level | read_uncommitted | 消息读取隔离级别:read_committed(仅读已提交的事务消息);read_uncommitted(消费到HW处的位置)。 |
request.timeout.ms | 30000(30秒) | 请求 Broker 的超时时间(需大于 max.block.ms)。 |
retry.backoff.ms | 100 | 失败重试前的等待时间。 |
reconnect.backoff.ms | 50 | 断线重连的等待时间。 |
reconnect.backoff.max.ms | 1000 | 断线重连的最大等待时间。 |
connections.max.idle.ms | 540000(9分钟) | 空闲连接关闭的超时时间。 |
security.protocol | PLAINTEXT | 安全协议:PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL。 |
sasl.mechanism | GSSAPI | SASL 机制,如 PLAIN、SCRAM-SHA-256 等。 |
ssl.keystore.location | null | SSL 密钥库路径(客户端双向认证时需配置)。 |
ssl.truststore.location | null | SSL 信任库路径。 |
interceptor.classes | 空列表 | 消费者拦截器类列表(需实现 ConsumerInterceptor)。 |
allow.auto.create.topics | true | 是否允许自动创建不存在的主题(可能导致意外主题生成)。 |
exclude.internal.topics | true | 是否排除内部主题(如 __consumer_offsets)。 |
receive.buff.bytes | 65535(B) | 设置Socket接收消息缓冲区(SO_RECBUF)的大小,如果为1,则使用操作系统的默认是。 |
send.buff.bytes | 131072(B) | 设置Socket发送消息缓冲区(SO_RECBUF)的大小,如果为1,则使用操作系统的默认是。 |
metadata.max.age.ms | 300000(5分钟) | 强制刷新元数据的间隔时间。 |
2.性能优化
2.1.参数调优
- 调整拉取参数
max.poll.records: 控制单次poll()拉取的最大消息数,默认500。若处理耗时较长,需减少此值以避免超时触发Rebalance。max.poll.interval.ms: 设置消费者处理消息的最大时间窗口。若处理逻辑复杂,需增大此值(默认300秒),防止因超时导致消费者被踢出组。fetch.min.bytes & fetch.max.wait.ms: 前者控制Broker返回数据的最小字节,后者为最长等待时间。适当增大可减少网络交互,提升吞吐量。
- 心跳与会话配置
session.timeout.ms: 消费者与Broker的心跳超时时间(默认10秒),需确保业务处理时间加网络延迟小于此值10。heartbeat.interval.ms: 心跳发送间隔(默认3秒),建议设为session.timeout.ms的三分之一,避免频繁Rebalance。
- 位移提交策略
- 关闭自动提交(
enable.auto.commit=false),改为手动异步提交(commitAsync()),避免阻塞主线程并减少重复消费风险。 - 若需更高可靠性,可结合同步提交(
commitSync()),但需权衡吞吐量。
2.2.并行化与多线程优化
-
增加消费者实例
同一消费者组内增加消费者数量,以匹配分区数,实现并行消费。注意分区数需大于等于消费者数量,否则部分消费者闲置。
示例:若主题有10个分区,可启动10个消费者实例,每个处理1个分区。
-
解耦消费与处理逻辑
使用多线程池分离消息拉取与处理: 主线程负责
poll()拉取消息,工作线程池处理消息。需确保分区内消息顺序性(如按Key分发任务)。工具支持: 考虑使用
Kafka Parallel Consumer,支持按分区、Key或无序并发处理,同时维护顺序性。 -
异步处理与批量提交
对拉取的消息异步处理,避免阻塞
poll()循环。例如,将消息存入队列后立即开启下一轮拉取。
2.3.资源管理与配置优化
- 网络与IO优化
-
fetch.max.bytes: 调大Broker返回数据的最大限制(默认50MB),提升单次拉取效率。 -
max.partition.fetch.bytes: 调整单个分区的最大拉取字节数(默认1MB),避免频繁小批量请求。
- JVM与内存配置
-
增大堆内存,避免频繁GC影响吞吐量。监控GC日志,优化垃圾回收策略。
-
使用零拷贝技术(如sendfile)减少数据复制开销。
- 分区与负载均衡
-
合理设计主题分区数,避免过多分区导致元数据管理开销。通常建议分区数为Broker数量的整数倍。
-
选择合适的分区分配策略(如Range、RoundRobin或StickyAssignor),提升负载均衡性。
- 数据压缩与批处理
-
启用消息压缩(如Snappy或GZIP),减少网络传输数据量。
-
生产者端批量发送消息(linger.ms & batch.size),消费者端批量处理,减少IO次数。
- 顺序消费与并发平衡
-
对需顺序消费的场景,按Key哈希到同一分区,保证分区内顺序;分区间可并行处理。
-
使用单分区多线程消费时,需自行管理位移,确保线程安全。