既有锦绣前程可奔赴,亦有往日岁月可回首
—— 25.5.25
选择排序回顾
① 遍历数组:从索引 0 到 n-1(n 为数组长度)。
② 每轮确定最小值:假设当前索引 i 为最小值索引 min_index。从 i+1 到 n-1 遍历,若找到更小元素,则更新 min_index。
③ 交换元素:若 min_index ≠ i,则交换 arr[i] 与 arr[min_index]。
'''
① 遍历数组:从索引 0 到 n-1(n 为数组长度)。
② 每轮确定最小值:假设当前索引 i 为最小值索引 min_index。从 i+1 到 n-1 遍历,若找到更小元素,则更新 min_index。
③ 交换元素:若 min_index ≠ i,则交换 arr[i] 与 arr[min_index]。
'''
def selectionSort(arr: List[int]):
n = len(arr)
for i in range(n):
min_index = i
for j in range(i+1, n):
if arr[j] < arr[min_index]:
min_index = j
if min_index != i:
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr冒泡排序回顾
① 初始化:设数组长度为 n。
② 外层循环:遍历 i 从 0 到 n-1(共 n 轮)。
③ 内层循环:对于每轮 i,遍历 j 从 0 到 n-i-2。
④ 比较与交换:若 arr[j] > arr[j+1],则交换两者。
⑤ 结束条件:重复步骤 2-4,直到所有轮次完成。
'''
① 初始化:设数组长度为 n。
② 外层循环:遍历 i 从 0 到 n-1(共 n 轮)。
③ 内层循环:对于每轮 i,遍历 j 从 0 到 n-i-1。
④ 比较与交换:若 arr[j] > arr[j+1],则交换两者。
⑤ 结束条件:重复步骤 2-4,直到所有轮次完成。
'''
def bubbleSort(arr: List[int]):
n = len(arr)
for i in range(n):
for j in range(n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr插入排序回顾
① 遍历未排序元素:从索引 1 到 n-1。
② 保存当前元素:将 arr[i] 存入 current。
③ 元素后移:从已排序部分的末尾(索引 j = i-1)向前扫描,将比 current 大的元素后移。直到找到第一个不大于 current 的位置或扫描完所有元素。
④ 插入元素:将 current 放入 j+1 位置。
'''
① 遍历未排序元素:从索引 1 到 n-1。
② 保存当前元素:将 arr[i] 存入 current。
③ 元素后移:从已排序部分的末尾(索引 j = i-1)向前扫描,将比 current 大的元素后移。直到找到第一个不大于 current 的位置或扫描完所有元素。
④ 插入元素:将 current 放入 j+1 位置。
'''
def insertSort(arr: List[int]):
n = len(arr)
for i in range(n):
current = arr[i]
j = i - 1
while current < arr[j] and j >0:
arr[j+1] = arr[j]
j -= 1
arr[j + 1] = current
return arr计数排序回顾
① 初始化:设数组长度为 n,元素最大值为 r。创建长度为 r+1 的计数数组 count,初始值全为 0。
② 统计元素频率:遍历原数组 arr,对每个元素 x,将 count[x] 加 1。
③ 重构有序数组:初始化索引 index = 0。遍历计数数组 count,索引 v 从 0 到 r,若 count[v] > 0,则将 v 填入原数组 arr[index],并将 index 加 1。count[v] - 1,重复此步骤直到 count[v] 为 0。
④ 结束条件:当计数数组遍历完成时,排序结束。
'''
输入全为非负整数,且所有元素 ≤ r
① 初始化:设数组长度为 n,元素最大值为 r。创建长度为 r+1 的计数数组 count,初始值全为 0。
② 统计元素频率:遍历原数组 arr,对每个元素 x,将 count[x] 加 1。
③ 重构有序数组:初始化索引 index = 0。遍历计数数组 count,索引 v 从 0 到 r,
若 count[v] > 0,则将 v 填入原数组 arr[index],并将 index 加 1。
count[v] - 1,重复此步骤直到 count[v] 为 0。
④ 结束条件:当计数数组遍历完成时,排序结束。
'''
def countingSort(arr: List[int], r: int):
# count = [0] * len(r + 1)
count = [0 for i in range(r + 1)]
for x in arr:
count[x] += 1
index = 0
for v in range(r + 1):
while count[v] > 0:
arr[index] = v
index += 1
count[v] -= 1
return arr归并排序回顾
Ⅰ、递归分解列表
① 终止条件:若链表为空或只有一个节点(head is None 或 head.next is None),直接返回头节点。
② 快慢指针找中点:初始化 slow 和 fast 指针,slow 指向头节点,fast 指向头节点的下一个节点。fast 每次移动两步,slow 每次移动一步。当 fast 到达末尾时,slow 恰好指向链表的中间节点。
③ 分割链表:将链表从中点断开,head2 指向 slow.next(后半部分的头节点)。将 slow.next 置为 None,切断前半部分与后半部分的连接。
④ 递归排序子链表:对前半部分(head)和后半部分(head2)分别递归调用 mergesort 函数。
Ⅱ、合并两个有序列表
① 创建虚拟头节点:创建一个值为 -1 的虚拟节点 zero,用于简化边界处理。使用 current 指针指向 zero,用于构建合并后的链表。
② 比较并合并节点:遍历两个子链表 head1 和 head2,比较当前节点的值:若 head1.val <= head2.val,将 head1 接入合并链表,并移动 head1 指针。否则,将 head2 接入合并链表,并移动 head2 指针。每次接入节点后,移动 current 指针到新接入的节点。
③ 处理剩余节点:当其中一个子链表遍历完后,将另一个子链表的剩余部分直接接入合并链表的末尾。
④ 返回合并后的链表:虚拟节点 zero 的下一个节点即为合并后的有序链表的头节点。
'''
Ⅰ、递归分解列表
① 终止条件:若链表为空或只有一个节点(head is None 或 head.next is None),直接返回头节点。
② 快慢指针找中点:初始化 slow 和 fast 指针,slow 指向头节点,fast 指向头节点的下一个节点。fast 每次移动两步,slow 每次移动一步。当 fast 到达末尾时,slow 恰好指向链表的中间节点。
③ 分割链表:将链表从中点断开,head2 指向 slow.next(后半部分的头节点)。将 slow.next 置为 None,切断前半部分与后半部分的连接。
④ 递归排序子链表:对前半部分(head)和后半部分(head2)分别递归调用 mergesort 函数。
Ⅱ、合并两个有序列表
① 创建虚拟头节点:创建一个值为 -1 的虚拟节点 zero,用于简化边界处理。使用 current 指针指向 zero,用于构建合并后的链表。
② 比较并合并节点:遍历两个子链表 head1 和 head2,比较当前节点的值:若 head1.val <= head2.val,将 head1 接入合并链表,并移动 head1 指针。否则,将 head2 接入合并链表,并移动 head2 指针。每次接入节点后,移动 current 指针到新接入的节点。
③ 处理剩余节点:当其中一个子链表遍历完后,将另一个子链表的剩余部分直接接入合并链表的末尾。
④ 返回合并后的链表:虚拟节点 zero 的下一个节点即为合并后的有序链表的头节点。
'''
def mergesort(self, head: ListNode):
if head is None or head.next is None:
return head
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
head2 = slow.next
slow.next = None
return self.merge(self.mergesort(head), self.mergesort(head2))
def merge(self, head1: ListNode, head2: ListNode):
zero = ListNode(-1)
current = zero
while head1 and head2:
if head1.val <= head2.val:
current.next = head1
head1 = head1.next
else:
current.next = head2
head2 = head2.next
current = current.next
current.next = head1 if head1 else head2
return zero.next一、引言
快速排序(Quick Sort)是一种分而治之的排序算法。它通过选择一个基准元素,将数组分为两部分,一部分的元素都比基准小,另一部分的元素都比基准大,然后对这两部分再进行快速排序,最终得到有序的数组。
二、算法思想
① 选择基准元素:从数组中随机选择一个元素作为基准。将基准元素放在数组的最左边。
② 分割数组:从头遍历数组,将比基准小的元素放在基准的左边,比基准大的元素放在基准的右边。
③ 递归排序:对基准左边和右边的子数组分别进行快速排序。
④ 重复步骤 ① 至 ③:直到子数组的长度为 1 或 0。
首先随机选择了一个数字作为【基准数】,并且将它和最左边的数交换,然后依次遍历,小于这个数字的值存储在一起,大于这个数字的值存储在一起,遍历完毕后,将这个【基准数】和下标最大的那个比【基准数】小的数字交换位置,至此,这个 、基准数左边位置上的数都小于它,右边位置上的数字都大于它,左边与右边两部分数字继续递归求解即可
三、算法分析
1.时间复杂度
最优情况:当每次选择的基准元素正好将数组分成两等分时,快速排序的时间复杂度是 O(n*logn)
最坏情况:当每次选择的基准元素是最大或最小元素时,快速排序的时间复杂度是 O(n^2)
平均情况:在平均情况下,快速排序的时间复杂度也是 O(n*logn)
2.空间复杂度
快速排序的空间复杂度是 O(logn),因为在递归调用中需要使用栈来存储中间结果。这意味着在排序过程中,最多需要 O(logn) 的额外空间来保存递归调用的栈帧。
3.算法的优点
① 高效性:快速排序在大多数情况下具有较高的排序效率。
② 适应性:适用于各种数据类型的排序。
③ 原地排序:不需要额外的存储空间。
4.算法的缺点
① 最坏情况性能:在最坏情况下,快速排序的时间复杂度可能退化为 O(n^2)。
② 不稳定性:快速排序可能会破坏排序的稳定性,即相同元素的相对顺序可能会改变
四、实战练习
217. 存在重复元素
给你一个整数数组
nums。如果任一值在数组中出现 至少两次 ,返回true;如果数组中每个元素互不相同,返回false。示例 1:
输入:nums = [1,2,3,1]
输出:true
解释:
元素 1 在下标 0 和 3 出现。
示例 2:
输入:nums = [1,2,3,4]
输出:false
解释:
所有元素都不同。
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
提示:
1 <= nums.length <= 105-109 <= nums[i] <= 109
思路与算法
Ⅰ、分区函数 Partition
① 随机选择基准元素:根据左右边界下标随机选择基准元素(选择的是元素并非下标),将基准元素赋值变量进行后续比较
② 交换基准元素:将基准元素移动到最左边,将基准元素存储在变量中,
③ 分区操作:对于基准元素右边的元素,找到第一个小于基准元素的值,移动到最左边;对于基准元素左边的元素,找到第一个大于基准元素的值,移动到最右边
④ 返回基准元素的最终位置:循环执行完毕后,基准元素左边的值都小于它,基准元素右边的值都大于它
Ⅱ、递归排序函数
① 定义递归终止条件:当左索引小于右索引时,结束递归
② 分区操作: 执行第一次分区操作,找到基准元素
③ 递归调用分区函数:将基准元素的左边、右边部分分别传入递归函数进行排序
Ⅲ、验证是否存在重复元素
① 排序数组:将数组传入快速排序的实现中,返回排好序的数组
② 遍历数组,寻找是否存在重复元素:遍历数组,如果发现相邻两个元素相等,则返回True,否则遍历完数组后,返回False
class Solution:
def Partition(self, arr: List, left, right):
index = random.randint(left, right)
arr[left], arr[index] = arr[index], arr[left]
i = left
j = right
x = arr[i]
while i < j:
while i < j and arr[j] > x:
j -= 1
if i < j:
arr[i], arr[j] = arr[j], arr[i]
i += 1
while i < j and arr[i] < x:
i += 1
if i < j:
arr[i], arr[j] = arr[j], arr[i]
j -= 1
return i
def quickSort(self, arr: List, left: int, right: int) -> List[int]:
if left >= right:
return
node = self.Partition(arr, left, right)
self.quickSort(arr, left, node - 1)
self.quickSort(arr, node + 1, right)
def containsDuplicate(self, nums: List[int]) -> bool:
n = len(nums)
self.quickSort(nums, 0, n - 1)
for i in range(1, n):
if nums[i] == nums[i - 1]:
return True
return False 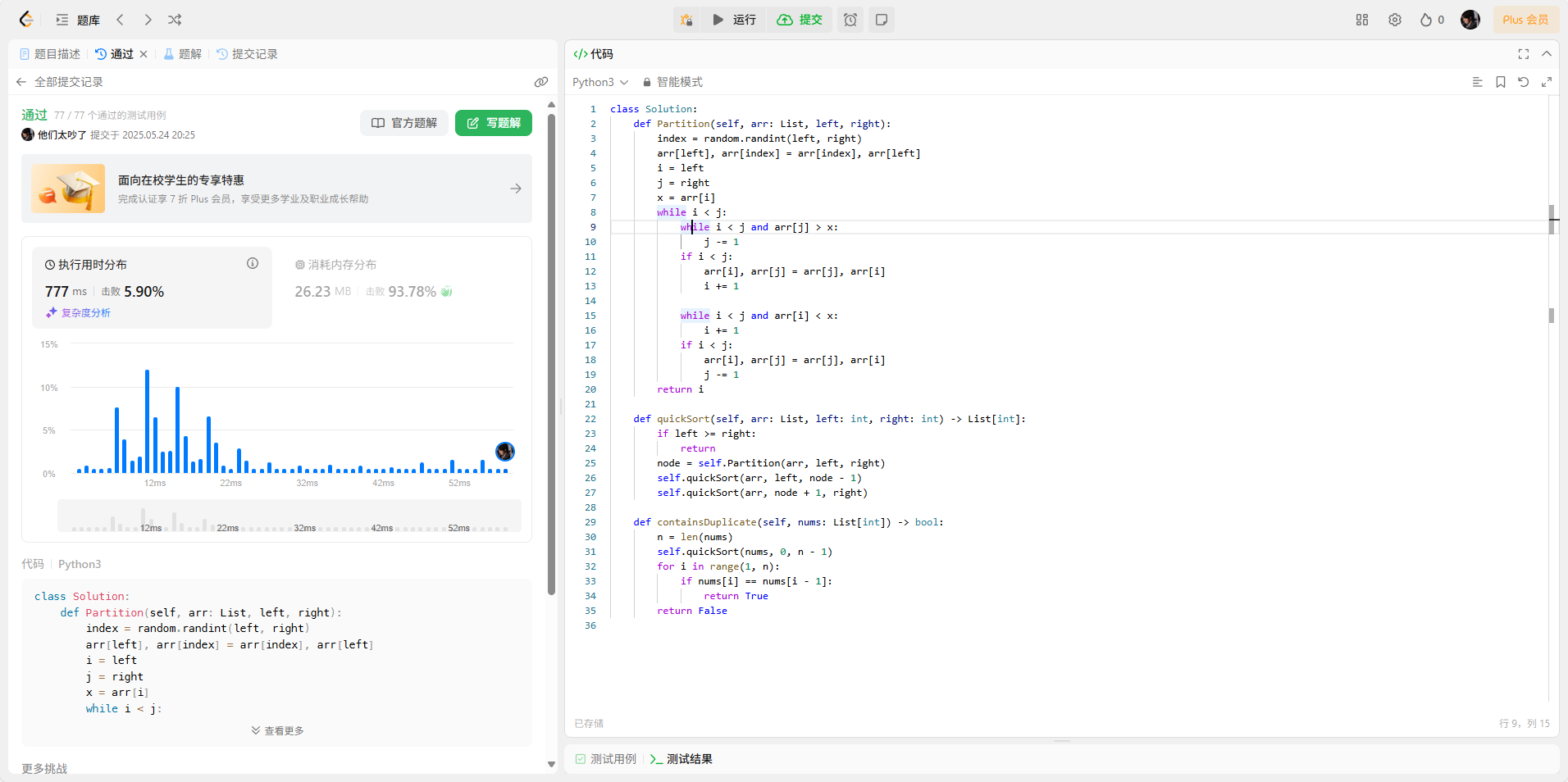
169. 多数元素
给定一个大小为
n的数组nums,返回其中的多数元素。多数元素是指在数组中出现次数 大于⌊ n/2 ⌋的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3] 输出:3示例 2:
输入:nums = [2,2,1,1,1,2,2] 输出:2提示:
n == nums.length1 <= n <= 5 * 104-109 <= nums[i] <= 109进阶:尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
思路与算法
Ⅰ、分区函数 Partition
① 随机选择基准元素:根据左右边界下标随机选择基准元素
② 交换基准元素:将基准元素移动到最左边
③ 分区操作:对于基准元素右边的元素,找到第一个小于基准元素的值,移动到最左边;对于基准元素左边的元素,找到第一个大于基准元素的值,移动到最右边
④ 返回基准元素的最终位置:循环执行完毕后,基准元素左边的值都小于它,基准元素右边的值都大于它
Ⅱ、递归排序函数
① 定义递归终止条件:当左索引小于右索引时,结束递归
② 分区操作: 执行第一次分区操作,找到基准元素
③ 递归调用分区函数:将基准元素的左边、右边部分分别传入递归函数进行排序
Ⅲ、在排好序的数组中返回多数元素
① 排序数组:将数组传入实现的快速排序函数中,返回已排序的数组
② 返回多数元素:因为题目中保证一定存在多数元素,所以排序好的数组中,多数一定是多数元素,所以直接返回排序后数组中间位置的值即可
class Solution:
def Partition(self, arr: List, left, right):
index = random.randint(left, right)
arr[left], arr[index] = arr[index], arr[left]
i = left
j = right
x = arr[i]
while i < j:
while i < j and arr[j] > x:
j -= 1
if i < j:
arr[i], arr[j] = arr[j], arr[i]
i += 1
while i < j and arr[i] < x:
i += 1
if i < j:
arr[i], arr[j] = arr[j], arr[i]
j -= 1
return i
def quickSort(self, arr: List, left: int, right: int) -> List[int]:
if left >= right:
return
node = self.Partition(arr, left, right)
self.quickSort(arr, left, node - 1)
self.quickSort(arr, node + 1, right)
def majorityElement(self, nums: List[int]) -> int:
n = len(nums)
self.quickSort(nums, 0, n - 1)
return nums[n//2]