0、引言
纯视觉检测当前研究基本比较饱和,继续创新提升空间很小,除非在CNN和transformer上提出更强基础建模方式。和文本结合是当前的一大趋势,也是计算机视觉和自然语言处理结合的未来趋势,目前和文本结合的目标检测工作还是有很大的研究空间的,毕竟两种不同模态的数据结合如何达到1+1>2的效果还是值得探索的,目前的结合方式效果也有限,实际还没有达到 >2 的预期效果。
visual grounding,VG,也叫视觉定位,当前有一些较成熟算法使文本和图像可以有效结合,而且文本数据处理比较方便,数据集不复杂,较容易上手,但是局限于提示一句话检测一个目标,缺乏目标检测对目标的通用检测功能。
open vocabulary object detection,OVD,也叫开放词汇目标检测,也是一种和文本结合的目标检测概念,和VG出现的时间都差不多,但是目前OVD的研究还不普遍,究其原因,其中数据集的复杂性是很多人却步的一点,其次网络结构较复杂,新人上手不太友好,所以发布的代码论文也不多。但是它有一个开放检测的优势,这是结合文本所产生的独特优势,并且可以通用检测,具有一定的实用性,可以说是比较理想的结合方式。
这里以Detic网络为例,来梳理如何跑起来一个OVD算法,可以进一步迁移到自制数据集中。
官网GitHub代码:https://github.com/facebookresearch/Detic/tree/main

具体的安装和数据集准备可以结合官网教程进行,主要介绍一些个人觉得官网不太详细的地方,其中我考虑了离线运行的方式,具体是数据集准备和代码框架部分。
1、代码框架安装:
除了直接下载官网代码外,还有子模块安装CenterNet2 和 Deformable DETR, 官网是用git的方式和子模块一并安装,离线的方式就是直接从两个子模块官网下载代码,放到指定路径就行:
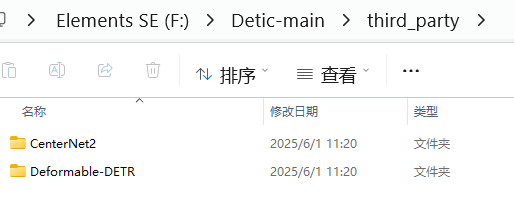
下载下来把main去了,改成如图文件夹名字即可,其中deformable DETR还有模块要编译:
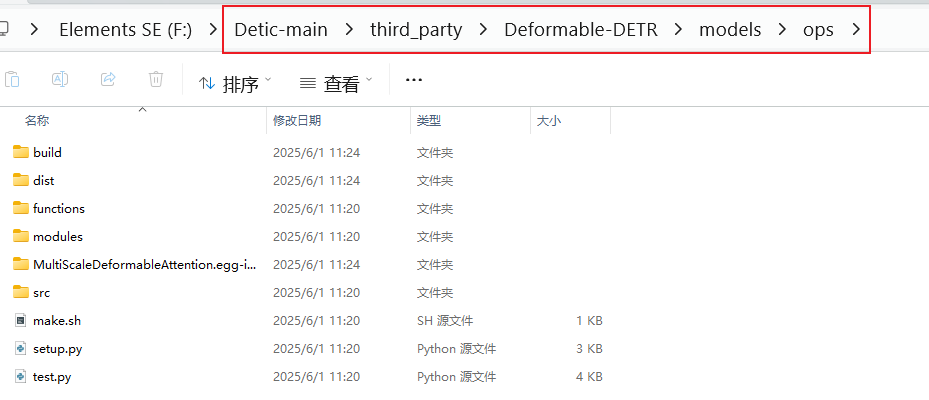
进到图示文件夹,执行命令:
python setup.py build install或者是(LINUX系统可以用下面命令):
cd third_party/Deformable-DETR/models/ops
./make.sh其次就是预训练模型下载,涉及到 R-50.pkl,ViT-B-32.pt等,直接搜索下载即可
2、数据集准备
个人觉得最恶心的就是数据集部分,挺复杂的。这里只对COCO数据集做说明,其他的可类比,整体流程可以按官网来,如下是定义的数据集:

数据集文件夹结构如下,metadata下载自带,都放于datasets文件夹下:
$Detic_ROOT/datasets/
metadata/
coco/
①下载,首先把下面的都给下了,官网coco2017数据集
coco/
train2017/
val2017/
annotations/
captions_train2017.json
instances_train2017.json
instances_val2017.json②类别划分,OVD的一大特点就是对训练集中没有的类别的进行检测,所以要把原有数据集进行划分,一部分类别用于训练,一部分类别用于验证,这个是OVR-CNN中的做法,Detic采用了该方式,后续很多研究也采用该方式,如下是我从OVR-CNN中获取的代码,这个Detic没有直接提供:
"""
Prepare zero-shot split for COCO dataset.
Based on the paper: Bansal, Ankan, et al. "Zero-shot object detection."
Proceedings of the European Conference on Computer Vision (ECCV). 2018.
"""
import json
import numpy as np
import torch
from maskrcnn_benchmark.config import cfg
from maskrcnn_benchmark.modeling.language_backbone.transformers import BERT
def load_coco_annotations():
"""Load COCO annotations for training and validation sets."""
with open('../datasets/coco/annotations/instances_train2017.json', 'r') as fin:
coco_train_anno_all = json.load(fin)
with open('../datasets/coco/annotations/instances_train2017.json', 'r') as fin:
coco_train_anno_seen = json.load(fin)
with open('../datasets/coco/annotations/instances_train2017.json', 'r') as fin:
coco_train_anno_unseen = json.load(fin)
with open('../datasets/coco/annotations/instances_val2017.json', 'r') as fin:
coco_val_anno_all = json.load(fin)
with open('../datasets/coco/annotations/instances_val2017.json', 'r') as fin:
coco_val_anno_seen = json.load(fin)
with open('../datasets/coco/annotations/instances_val2017.json', 'r') as fin:
coco_val_anno_unseen = json.load(fin)
return (coco_train_anno_all, coco_train_anno_seen, coco_train_anno_unseen,
coco_val_anno_all, coco_val_anno_seen, coco_val_anno_unseen)
def load_class_splits():
"""Load seen and unseen class splits."""
with open('../datasets/coco/zero-shot/mscoco_seen_classes.json', 'r') as fin:
labels_seen = json.load(fin)
with open('../datasets/coco/zero-shot/mscoco_unseen_classes.json', 'r') as fin:
labels_unseen = json.load(fin)
return labels_seen, labels_unseen
def create_class_mappings(coco_val_anno_all, labels_seen, labels_unseen):
"""Create mappings between class IDs and splits."""
class_id_to_split = {}
class_name_to_split = {}
for item in coco_val_anno_all['categories']:
if item['name'] in labels_seen:
class_id_to_split[item['id']] = 'seen'
class_name_to_split[item['name']] = 'seen'
elif item['name'] in labels_unseen:
class_id_to_split[item['id']] = 'unseen'
class_name_to_split[item['name']] = 'unseen'
return class_id_to_split, class_name_to_split
def load_glove_embeddings(class_name_to_split):
"""Load GloVe embeddings for classes."""
class_name_to_glove = {}
with open('../datasets/coco/zero-shot/glove.6B.300d.txt', 'r', encoding='utf-8') as fin:
for row in fin:
row_tk = row.split()
if row_tk[0] in class_name_to_split:
class_name_to_glove[row_tk[0]] = [float(num) for num in row_tk[1:]]
return class_name_to_glove
def get_bert_embeddings(class_name_to_split):
"""Get BERT embeddings for classes."""
bert = BERT(cfg)
bert = bert.to('cuda')
class_name_to_bertemb = {}
for c in class_name_to_split:
if c not in bert.tokenizer.vocab:
print(f'{c} not found')
continue
cid = bert.tokenizer.vocab[c]
class_name_to_bertemb[c] = bert.embeddings[cid]
class_list = list(class_name_to_split.keys())
encoded_class_list = bert(class_list)
mask = (1 - encoded_class_list['special_tokens_mask']).to(torch.float32)
embeddings = (encoded_class_list['input_embeddings'] * mask[:, :, None]).sum(1) / mask.sum(1)[:, None]
embeddings = embeddings.cpu().numpy()
class_name_to_bertemb = {}
for c, emb in zip(class_list, embeddings.tolist()):
class_name_to_bertemb[c] = emb
return class_name_to_bertemb
def filter_annotation(anno_dict, split_name_list, class_id_to_split, class_name_to_glove, class_name_to_bertemb):
"""Filter annotations based on split names."""
filtered_categories = []
for item in anno_dict['categories']:
if class_id_to_split.get(item['id']) in split_name_list:
item['embedding'] = {}
item['embedding']['GloVE'] = class_name_to_glove[item['name']]
item['embedding']['BertEmb'] = class_name_to_bertemb[item['name']]
item['split'] = class_id_to_split.get(item['id'])
filtered_categories.append(item)
anno_dict['categories'] = filtered_categories
filtered_images = []
filtered_annotations = []
useful_image_ids = set()
for item in anno_dict['annotations']:
if class_id_to_split.get(item['category_id']) in split_name_list:
filtered_annotations.append(item)
useful_image_ids.add(item['image_id'])
for item in anno_dict['images']:
if item['id'] in useful_image_ids:
filtered_images.append(item)
anno_dict['annotations'] = filtered_annotations
anno_dict['images'] = filtered_images
def save_filtered_annotations(coco_train_anno_seen, coco_train_anno_unseen, coco_train_anno_all,
coco_val_anno_seen, coco_val_anno_unseen, coco_val_anno_all):
"""Save filtered annotations to JSON files."""
with open('../datasets/coco/zero-shot/instances_train2017_seen_2.json', 'w') as fout:
json.dump(coco_train_anno_seen, fout)
with open('../datasets/coco/zero-shot/instances_train2017_unseen_2.json', 'w') as fout:
json.dump(coco_train_anno_unseen, fout)
with open('../datasets/coco/zero-shot/instances_train2017_all_2.json', 'w') as fout:
json.dump(coco_train_anno_all, fout)
with open('../datasets/coco/zero-shot/instances_val2017_seen_2.json', 'w') as fout:
json.dump(coco_val_anno_seen, fout)
with open('../datasets/coco/zero-shot/instances_val2017_unseen_2.json', 'w') as fout:
json.dump(coco_val_anno_unseen, fout)
with open('../datasets/coco/zero-shot/instances_val2017_all_2.json', 'w') as fout:
json.dump(coco_val_anno_all, fout)
def main():
# Load annotations
(coco_train_anno_all, coco_train_anno_seen, coco_train_anno_unseen,
coco_val_anno_all, coco_val_anno_seen, coco_val_anno_unseen) = load_coco_annotations()
# Load class splits
labels_seen, labels_unseen = load_class_splits()
# Create class mappings
class_id_to_split, class_name_to_split = create_class_mappings(coco_val_anno_all, labels_seen, labels_unseen)
# Load GloVe embeddings
class_name_to_glove = load_glove_embeddings(class_name_to_split)
# Get BERT embeddings
class_name_to_bertemb = get_bert_embeddings(class_name_to_split)
# Filter annotations
filter_annotation(coco_train_anno_seen, ['seen'], class_id_to_split, class_name_to_glove, class_name_to_bertemb)
filter_annotation(coco_train_anno_unseen, ['unseen'], class_id_to_split, class_name_to_glove, class_name_to_bertemb)
filter_annotation(coco_train_anno_all, ['seen', 'unseen'], class_id_to_split, class_name_to_glove, class_name_to_bertemb)
filter_annotation(coco_val_anno_seen, ['seen'], class_id_to_split, class_name_to_glove, class_name_to_bertemb)
filter_annotation(coco_val_anno_unseen, ['unseen'], class_id_to_split, class_name_to_glove, class_name_to_bertemb)
filter_annotation(coco_val_anno_all, ['seen', 'unseen'], class_id_to_split, class_name_to_glove, class_name_to_bertemb)
# Save filtered annotations
save_filtered_annotations(coco_train_anno_seen, coco_train_anno_unseen, coco_train_anno_all,
coco_val_anno_seen, coco_val_anno_unseen, coco_val_anno_all)
if __name__ == '__main__':
main()
把这个代码放到tools文件夹,直接python tools/xxx.py执行即可,
但是要提前准备好 glove.6B.300d.txt,mscoco_seen_classes.json,mscoco_unseen_classes.json几个文件,后面两个直接去GitHub的OVR-CNN官网去下载,glove.6B.300d.txt直接搜索自行下载,统一放到 coco/zero-shot文件夹下,执行后会生成6个新的文件:
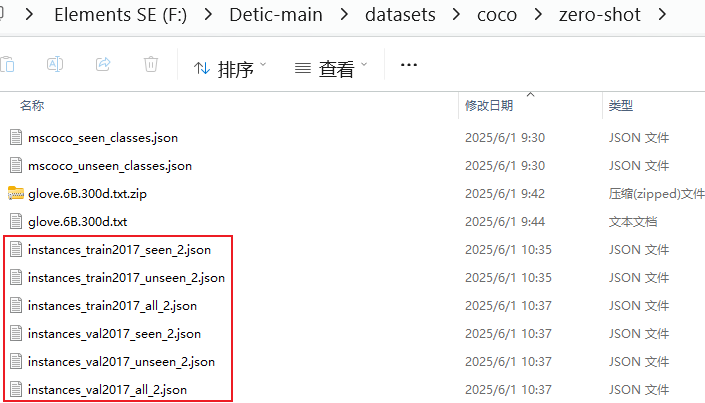
剩下的数据集操作就和Detic官网一致了,
python tools/get_coco_zeroshot_oriorder.py --data_path datasets/coco/zero-shot/instances_train2017_seen_2.json
python tools/get_coco_zeroshot_oriorder.py --data_path datasets/coco/zero-shot/instances_val2017_all_2.json执行如上两条命令得到如下绿框的两个标签文件: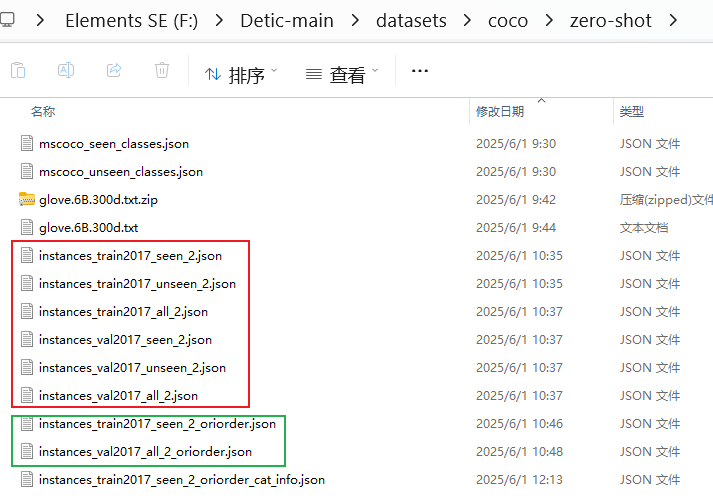 然后是上图最后一个标签文件:
然后是上图最后一个标签文件:
python tools/get_lvis_cat_info.py --ann datasets/coco/zero-shot/instances_train2017_seen_2_oriorder.py如上就把coco/zero-shot所需要的标签都生成好了
③coco文本描述标签生成
python tools/get_cc_tags.py --cc_ann datasets/coco/annotations/captions_train2017.json --out_path datasets/coco/captions_train2017_tags_allcaps.json --allcaps --convert_caption --cat_path datasets/coco/annotations/instances_val2017.json
这会生成一个captions_train2017_tags_allcaps.json文件,需要放入coco/annotations文件夹下,至此,coco支持OVD训练的数据就都准备好了
④其他数据说明。从配置文件中可以看到,会使用metadata下面的 datasets/metadata/coco_clip_a+cname.npy
coco_clip_a+cname.npy 文件是通过 tools/dump_clip_features.py 脚本生成的。生成过程如下:
脚本功能:
- 读取数据集的类别信息(从 JSON 文件)
- 使用 CLIP 模型生成每个类别的文本嵌入向量
- 将生成的嵌入向量保存为 numpy 文件
命令如下:
python tools/dump_clip_features.py \
--ann datasets/coco/annotations/instances_val2017.json \
--out_path datasets/metadata/coco_clip_a+cname.npy3、进行训练
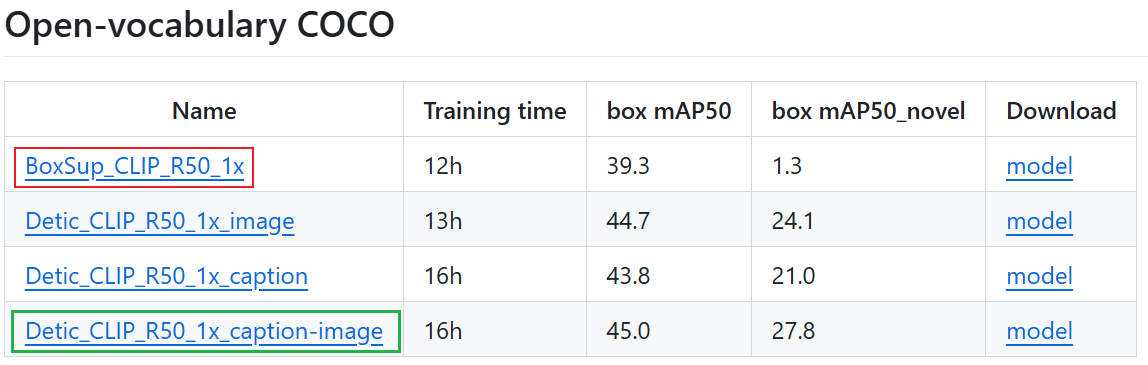
单卡就可以训练,把batch size调小一点。根据提供的模型来看,是先进行有监督训练,如下红框的配置文件,在有监督的基础上得到预训练模型用来训绿框的配置,以此得到具有OVD功能的模型
单卡训练代码:
python train_net.py --num-gpus 1 --config-file .\configs\BoxSup_OVCOCO_CLIP_R50_1x.yaml训练界面:
Command Line Args: Namespace(config_file='.\\configs\\BoxSup_OVCOCO_CLIP_R50_1x.yaml', dist_url='tcp://127.0.0.1:14167', eval_only=False, machine_rank=0, num_gpus=1, num_machines=1, opts=[], resume=False)
[06/01 18:32:26 detectron2]: Rank of current process: 0. World size: 1
[06/01 18:32:27 detectron2]: Environment info:
---------------------- -------------------------------------------------------------------------------------------------
sys.platform win32
Python 3.8.18 (default, Sep 11 2023, 13:39:12) [MSC v.1916 64 bit (AMD64)]
numpy 1.23.2
detectron2 0.6 @f:\llava_grounding_main\detectron2\detectron2
Compiler MSVC 193732825
CUDA compiler CUDA 12.1
detectron2 arch flags f:\llava_grounding_main\detectron2\detectron2\_C.cp38-win_amd64.pyd; cannot find cuobjdump
DETECTRON2_ENV_MODULE <not set>
PyTorch 2.4.0+cu121 @C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torch
PyTorch debug build False
GPU available Yes
GPU 0 NVIDIA GeForce RTX 3060 (arch=8.6)
Driver version 560.94
CUDA_HOME C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
Pillow 9.5.0
torchvision 0.19.0+cu121 @C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torchvision
torchvision arch flags C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torchvision\_C.pyd; cannot find cuobjdump
fvcore 0.1.5.post20221221
iopath 0.1.7
cv2 4.8.1
---------------------- -------------------------------------------------------------------------------------------------
PyTorch built with:
- C++ Version: 201703
- MSVC 192930154
- Intel(R) oneAPI Math Kernel Library Version 2024.2-Product Build 20240605 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v3.4.2 (Git Hash 1137e04ec0b5251ca2b4400a4fd3c667ce843d67)
- OpenMP 2019
- LAPACK is enabled (usually provided by MKL)
- CPU capability usage: AVX2
- CUDA Runtime 12.1
- NVCC architecture flags: -gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_90,code=sm_90
- CuDNN 90.1 (built against CUDA 12.4)
- Magma 2.5.4
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=12.1, CUDNN_VERSION=9.1.0, CXX_COMPILER=C:/actions-runner/_work/pytorch/pytorch/builder/windows/tmp_bin/sccache-cl.exe, CXX_FLAGS=/DWIN32 /D_WINDOWS /GR /EHsc /Zc:__cplusplus /bigobj /FS /utf-8 -DUSE_PTHREADPOOL -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE /wd4624 /wd4068 /wd4067 /wd4267 /wd4661 /wd4717 /wd4244 /wd4804 /wd4273, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=2.4.0, USE_CUDA=ON, USE_CUDNN=ON, USE_CUSPARSELT=OFF, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_GLOO=ON, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=OFF, USE_NNPACK=OFF, USE_OPENMP=ON, USE_ROCM=OFF, USE_ROCM_KERNEL_ASSERT=OFF,
[06/01 18:32:27 detectron2]: Command line arguments: Namespace(config_file='.\\configs\\BoxSup_OVCOCO_CLIP_R50_1x.yaml', dist_url='tcp://127.0.0.1:14167', eval_only=False, machine_rank=0, num_gpus=1, num_machines=1, opts=[], resume=False)
[06/01 18:32:27 detectron2]: Contents of args.config_file=.\configs\BoxSup_OVCOCO_CLIP_R50_1x.yaml:
_BASE_: "Base_OVCOCO_C4_1x.yaml"
[06/01 18:32:27 detectron2]: Running with full config:
CUDNN_BENCHMARK: false
DATALOADER:
ASPECT_RATIO_GROUPING: true
DATASET_ANN:
- box
- box
DATASET_BS:
- 8
- 32
DATASET_INPUT_SCALE:
- &id001
- 0.1
- 2.0
- - 0.5
- 1.5
DATASET_INPUT_SIZE:
- 896
- 384
DATASET_MAX_SIZES:
- 1333
- 667
DATASET_MIN_SIZES:
- - 640
- 800
- - 320
- 400
DATASET_RATIO:
- 1
- 1
FILTER_EMPTY_ANNOTATIONS: true
MULTI_DATASET_GROUPING: false
NUM_WORKERS: 4
REPEAT_THRESHOLD: 0.0
SAMPLER_TRAIN: TrainingSampler
TARFILE_PATH: datasets/imagenet/metadata-22k/tar_files.npy
TAR_INDEX_DIR: datasets/imagenet/metadata-22k/tarindex_npy
USE_DIFF_BS_SIZE: false
USE_RFS:
- false
- false
USE_TAR_DATASET: false
DATASETS:
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
PROPOSAL_FILES_TEST: []
PROPOSAL_FILES_TRAIN: []
TEST:
- coco_generalized_zeroshot_val
TRAIN:
- coco_zeroshot_train_oriorder
DEBUG: false
DEBUG_SHOW_NAME: false
EVAL_AP_FIX: false
EVAL_CAT_SPEC_AR: false
EVAL_PRED_AR: false
EVAL_PROPOSAL_AR: false
FIND_UNUSED_PARAM: true
FP16: true
GEN_PSEDO_LABELS: false
GLOBAL:
HACK: 1.0
INPUT:
CROP:
ENABLED: false
SIZE:
- 0.9
- 0.9
TYPE: relative_range
CUSTOM_AUG: ''
FORMAT: BGR
MASK_FORMAT: polygon
MAX_SIZE_TEST: 1333
MAX_SIZE_TRAIN: 1333
MIN_SIZE_TEST: 800
MIN_SIZE_TRAIN:
- 800
MIN_SIZE_TRAIN_SAMPLING: choice
NOT_CLAMP_BOX: false
RANDOM_FLIP: horizontal
SCALE_RANGE: *id001
TEST_INPUT_TYPE: default
TEST_SIZE: 640
TRAIN_SIZE: 640
IS_DEBUG: false
MODEL:
ANCHOR_GENERATOR:
ANGLES:
- - -90
- 0
- 90
ASPECT_RATIOS:
- - 0.5
- 1.0
- 2.0
NAME: DefaultAnchorGenerator
OFFSET: 0.0
SIZES:
- - 32
- 64
- 128
- 256
- 512
BACKBONE:
FREEZE_AT: 2
NAME: build_resnet_backbone
BIFPN:
NORM: GN
NUM_BIFPN: 6
NUM_LEVELS: 5
OUT_CHANNELS: 160
SEPARABLE_CONV: false
CAP_BATCH_RATIO: 4
CENTERNET:
AS_PROPOSAL: false
CENTER_NMS: false
FPN_STRIDES:
- 8
- 16
- 32
- 64
- 128
HM_FOCAL_ALPHA: 0.25
HM_FOCAL_BETA: 4
HM_MIN_OVERLAP: 0.8
IGNORE_HIGH_FP: -1.0
INFERENCE_TH: 0.05
IN_FEATURES:
- p3
- p4
- p5
- p6
- p7
LOC_LOSS_TYPE: giou
LOSS_GAMMA: 2.0
MIN_RADIUS: 4
MORE_POS: false
MORE_POS_THRESH: 0.2
MORE_POS_TOPK: 9
NEG_WEIGHT: 1.0
NMS_TH_TEST: 0.6
NMS_TH_TRAIN: 0.6
NORM: GN
NOT_NMS: false
NOT_NORM_REG: true
NO_REDUCE: false
NUM_BOX_CONVS: 4
NUM_CLASSES: 80
NUM_CLS_CONVS: 4
NUM_SHARE_CONVS: 0
ONLY_PROPOSAL: false
POST_NMS_TOPK_TEST: 100
POST_NMS_TOPK_TRAIN: 100
POS_WEIGHT: 1.0
PRE_NMS_TOPK_TEST: 1000
PRE_NMS_TOPK_TRAIN: 1000
PRIOR_PROB: 0.01
REG_WEIGHT: 2.0
SIGMOID_CLAMP: 0.0001
SOI:
- - 0
- 80
- - 64
- 160
- - 128
- 320
- - 256
- 640
- - 512
- 10000000
USE_DEFORMABLE: false
WITH_AGN_HM: false
DATASET_LOSS_WEIGHT: []
DETR:
CLS_WEIGHT: 2.0
DEC_LAYERS: 6
DEEP_SUPERVISION: true
DIM_FEEDFORWARD: 2048
DROPOUT: 0.1
ENC_LAYERS: 6
FOCAL_ALPHA: 0.25
FROZEN_WEIGHTS: ''
GIOU_WEIGHT: 2.0
HIDDEN_DIM: 256
L1_WEIGHT: 5.0
NHEADS: 8
NO_OBJECT_WEIGHT: 0.1
NUM_CLASSES: 80
NUM_FEATURE_LEVELS: 4
NUM_OBJECT_QUERIES: 100
PRE_NORM: false
TWO_STAGE: false
USE_FED_LOSS: false
WEAK_WEIGHT: 0.1
WITH_BOX_REFINE: false
DEVICE: cuda
DLA:
DLAUP_IN_FEATURES:
- dla3
- dla4
- dla5
DLAUP_NODE: conv
MS_OUTPUT: false
NORM: BN
NUM_LAYERS: 34
OUT_FEATURES:
- dla2
USE_DLA_UP: true
DYNAMIC_CLASSIFIER: false
FPN:
FUSE_TYPE: sum
IN_FEATURES: []
NORM: ''
OUT_CHANNELS: 256
KEYPOINT_ON: false
LOAD_PROPOSALS: false
MASK_ON: false
META_ARCHITECTURE: CustomRCNN
NUM_SAMPLE_CATS: 50
PANOPTIC_FPN:
COMBINE:
ENABLED: true
INSTANCES_CONFIDENCE_THRESH: 0.5
OVERLAP_THRESH: 0.5
STUFF_AREA_LIMIT: 4096
INSTANCE_LOSS_WEIGHT: 1.0
PIXEL_MEAN:
- 103.53
- 116.28
- 123.675
PIXEL_STD:
- 1.0
- 1.0
- 1.0
PROPOSAL_GENERATOR:
MIN_SIZE: 0
NAME: RPN
RESET_CLS_TESTS: false
RESNETS:
DEFORM_MODULATED: false
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE:
- false
- false
- false
- false
DEPTH: 50
NORM: FrozenBN
NUM_GROUPS: 1
OUT_FEATURES:
- res4
RES2_OUT_CHANNELS: 256
RES5_DILATION: 1
STEM_OUT_CHANNELS: 64
STRIDE_IN_1X1: true
WIDTH_PER_GROUP: 64
RETINANET:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_WEIGHTS: &id003
- 1.0
- 1.0
- 1.0
- 1.0
FOCAL_LOSS_ALPHA: 0.25
FOCAL_LOSS_GAMMA: 2.0
IN_FEATURES:
- p3
- p4
- p5
- p6
- p7
IOU_LABELS:
- 0
- -1
- 1
IOU_THRESHOLDS:
- 0.4
- 0.5
NMS_THRESH_TEST: 0.5
NORM: ''
NUM_CLASSES: 80
NUM_CONVS: 4
PRIOR_PROB: 0.01
SCORE_THRESH_TEST: 0.05
SMOOTH_L1_LOSS_BETA: 0.1
TOPK_CANDIDATES_TEST: 1000
ROI_BOX_CASCADE_HEAD:
BBOX_REG_WEIGHTS:
- &id002
- 10.0
- 10.0
- 5.0
- 5.0
- - 20.0
- 20.0
- 10.0
- 10.0
- - 30.0
- 30.0
- 15.0
- 15.0
IOUS:
- 0.5
- 0.6
- 0.7
ROI_BOX_HEAD:
ADD_FEATURE_TO_PROP: false
ADD_IMAGE_BOX: false
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: *id002
CAPTION_WEIGHT: 1.0
CAT_FREQ_PATH: datasets/coco/zero-shot/instances_train2017_seen_2_oriorder_cat_info.json
CLS_AGNOSTIC_BBOX_REG: true
CONV_DIM: 256
EQL_FREQ_CAT: 200
FC_DIM: 1024
FED_LOSS_FREQ_WEIGHT: 0.5
FED_LOSS_NUM_CAT: 50
IGNORE_ZERO_CATS: true
IMAGE_BOX_SIZE: 1.0
IMAGE_LABEL_LOSS: max_size
IMAGE_LOSS_WEIGHT: 0.1
MULT_PROPOSAL_SCORE: false
NAME: ''
NEG_CAP_WEIGHT: 0.125
NORM: ''
NORM_TEMP: 50.0
NORM_WEIGHT: true
NUM_CONV: 0
NUM_FC: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
PRIOR_PROB: 0.01
SMOOTH_L1_BETA: 0.0
SOFTMAX_WEAK_LOSS: false
TRAIN_ON_PRED_BOXES: false
USE_BIAS: 0.0
USE_EQL_LOSS: false
USE_FED_LOSS: false
USE_SIGMOID_CE: true
USE_ZEROSHOT_CLS: true
WITH_SOFTMAX_PROP: false
WS_NUM_PROPS: 128
ZEROSHOT_WEIGHT_DIM: 512
ZEROSHOT_WEIGHT_PATH: datasets/metadata/coco_clip_a+cname.npy
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES:
- res4
IOU_LABELS:
- 0
- 1
IOU_THRESHOLDS:
- 0.5
MASK_WEIGHT: 1.0
NAME: CustomRes5ROIHeads
NMS_THRESH_TEST: 0.5
NUM_CLASSES: 80
ONE_CLASS_PER_PROPOSAL: false
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: true
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS:
- 512
- 512
- 512
- 512
- 512
- 512
- 512
- 512
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: true
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: false
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM: ''
NUM_CONV: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: *id003
BOUNDARY_THRESH: -1
CONV_DIMS:
- -1
HEAD_NAME: StandardRPNHead
IN_FEATURES:
- res4
IOU_LABELS:
- 0
- -1
- 1
IOU_THRESHOLDS:
- 0.3
- 0.7
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 2000
PRE_NMS_TOPK_TEST: 6000
PRE_NMS_TOPK_TRAIN: 12000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
COMMON_STRIDE: 4
CONVS_DIM: 128
IGNORE_VALUE: 255
IN_FEATURES:
- p2
- p3
- p4
- p5
LOSS_WEIGHT: 1.0
NAME: SemSegFPNHead
NORM: GN
NUM_CLASSES: 54
SWIN:
OUT_FEATURES:
- 1
- 2
- 3
SIZE: T
USE_CHECKPOINT: false
SYNC_CAPTION_BATCH: false
TEST_CLASSIFIERS: []
TEST_NUM_CLASSES: []
TIMM:
BASE_NAME: resnet50
FREEZE_AT: 0
NORM: FrozenBN
OUT_LEVELS:
- 3
- 4
- 5
PRETRAINED: false
WEIGHTS: models/R-50.pkl
WITH_CAPTION: false
OUTPUT_DIR: output/Detic-COCO/BoxSup_OVCOCO_CLIP_R50_1x
QUICK_DEBUG: false
SAVE_DEBUG: false
SAVE_DEBUG_PATH: output/save_debug/
SAVE_PTH: false
SEED: -1
SOLVER:
AMP:
ENABLED: false
BACKBONE_MULTIPLIER: 1.0
BASE_LR: 0.02
BASE_LR_END: 0.0
BIAS_LR_FACTOR: 1.0
CHECKPOINT_PERIOD: 1000000000
CLIP_GRADIENTS:
CLIP_TYPE: value
CLIP_VALUE: 1.0
ENABLED: false
NORM_TYPE: 2.0
CUSTOM_MULTIPLIER: 1.0
CUSTOM_MULTIPLIER_NAME: []
GAMMA: 0.1
IMS_PER_BATCH: 2
LR_SCHEDULER_NAME: WarmupMultiStepLR
MAX_ITER: 90000
MOMENTUM: 0.9
NESTEROV: false
OPTIMIZER: SGD
REFERENCE_WORLD_SIZE: 0
RESET_ITER: false
STEPS:
- 60000
- 80000
TRAIN_ITER: -1
USE_CUSTOM_SOLVER: false
WARMUP_FACTOR: 0.001
WARMUP_ITERS: 1000
WARMUP_METHOD: linear
WEIGHT_DECAY: 0.0001
WEIGHT_DECAY_BIAS: null
WEIGHT_DECAY_NORM: 0.0
TEST:
AUG:
ENABLED: false
FLIP: true
MAX_SIZE: 4000
MIN_SIZES:
- 400
- 500
- 600
- 700
- 800
- 900
- 1000
- 1100
- 1200
DETECTIONS_PER_IMAGE: 100
EVAL_PERIOD: 0
EXPECTED_RESULTS: []
KEYPOINT_OKS_SIGMAS: []
PRECISE_BN:
ENABLED: false
NUM_ITER: 200
VERSION: 2
VIS_PERIOD: 0
VIS_THRESH: 0.3
WITH_IMAGE_LABELS: false
[06/01 18:32:27 detectron2]: Full config saved to output/Detic-COCO/BoxSup_OVCOCO_CLIP_R50_1x\config.yaml
[06/01 18:32:28 d2.utils.env]: Using a generated random seed 28139170
[06/01 18:32:29 detectron2]: Model:
CustomRCNN(
(backbone): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
)
(proposal_generator): RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(
1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(objectness_logits): Conv2d(1024, 15, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(1024, 60, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
(roi_heads): CustomRes5ROIHeads(
(pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
(box_predictor): DeticFastRCNNOutputLayers(
(cls_score): ZeroShotClassifier(
(linear): Linear(in_features=2048, out_features=512, bias=True)
)
(bbox_pred): Sequential(
(0): Linear(in_features=2048, out_features=2048, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=2048, out_features=4, bias=True)
)
)
)
)
[06/01 18:32:29 fvcore.common.checkpoint]: [Checkpointer] Loading from models/R-50.pkl ...
[06/01 18:32:29 d2.checkpoint.c2_model_loading]: Renaming Caffe2 weights ......
[06/01 18:32:29 d2.checkpoint.c2_model_loading]: Following weights matched with model:
| Names in Model | Names in Checkpoint | Shapes |
|:----------------------------|:-------------------------|:------------------------------------------------|
| backbone.res2.0.conv1.* | res2_0_branch2a_{bn_*,w} | (64,) (64,) (64,) (64,) (64,64,1,1) |
| backbone.res2.0.conv2.* | res2_0_branch2b_{bn_*,w} | (64,) (64,) (64,) (64,) (64,64,3,3) |
| backbone.res2.0.conv3.* | res2_0_branch2c_{bn_*,w} | (256,) (256,) (256,) (256,) (256,64,1,1) |
| backbone.res2.0.shortcut.* | res2_0_branch1_{bn_*,w} | (256,) (256,) (256,) (256,) (256,64,1,1) |
| backbone.res2.1.conv1.* | res2_1_branch2a_{bn_*,w} | (64,) (64,) (64,) (64,) (64,256,1,1) |
| backbone.res2.1.conv2.* | res2_1_branch2b_{bn_*,w} | (64,) (64,) (64,) (64,) (64,64,3,3) |
| backbone.res2.1.conv3.* | res2_1_branch2c_{bn_*,w} | (256,) (256,) (256,) (256,) (256,64,1,1) |
| backbone.res2.2.conv1.* | res2_2_branch2a_{bn_*,w} | (64,) (64,) (64,) (64,) (64,256,1,1) |
| backbone.res2.2.conv2.* | res2_2_branch2b_{bn_*,w} | (64,) (64,) (64,) (64,) (64,64,3,3) |
| backbone.res2.2.conv3.* | res2_2_branch2c_{bn_*,w} | (256,) (256,) (256,) (256,) (256,64,1,1) |
| backbone.res3.0.conv1.* | res3_0_branch2a_{bn_*,w} | (128,) (128,) (128,) (128,) (128,256,1,1) |
| backbone.res3.0.conv2.* | res3_0_branch2b_{bn_*,w} | (128,) (128,) (128,) (128,) (128,128,3,3) |
| backbone.res3.0.conv3.* | res3_0_branch2c_{bn_*,w} | (512,) (512,) (512,) (512,) (512,128,1,1) |
| backbone.res3.0.shortcut.* | res3_0_branch1_{bn_*,w} | (512,) (512,) (512,) (512,) (512,256,1,1) |
| backbone.res3.1.conv1.* | res3_1_branch2a_{bn_*,w} | (128,) (128,) (128,) (128,) (128,512,1,1) |
| backbone.res3.1.conv2.* | res3_1_branch2b_{bn_*,w} | (128,) (128,) (128,) (128,) (128,128,3,3) |
| backbone.res3.1.conv3.* | res3_1_branch2c_{bn_*,w} | (512,) (512,) (512,) (512,) (512,128,1,1) |
| backbone.res3.2.conv1.* | res3_2_branch2a_{bn_*,w} | (128,) (128,) (128,) (128,) (128,512,1,1) |
| backbone.res3.2.conv2.* | res3_2_branch2b_{bn_*,w} | (128,) (128,) (128,) (128,) (128,128,3,3) |
| backbone.res3.2.conv3.* | res3_2_branch2c_{bn_*,w} | (512,) (512,) (512,) (512,) (512,128,1,1) |
| backbone.res3.3.conv1.* | res3_3_branch2a_{bn_*,w} | (128,) (128,) (128,) (128,) (128,512,1,1) |
| backbone.res3.3.conv2.* | res3_3_branch2b_{bn_*,w} | (128,) (128,) (128,) (128,) (128,128,3,3) |
| backbone.res3.3.conv3.* | res3_3_branch2c_{bn_*,w} | (512,) (512,) (512,) (512,) (512,128,1,1) |
| backbone.res4.0.conv1.* | res4_0_branch2a_{bn_*,w} | (256,) (256,) (256,) (256,) (256,512,1,1) |
| backbone.res4.0.conv2.* | res4_0_branch2b_{bn_*,w} | (256,) (256,) (256,) (256,) (256,256,3,3) |
| backbone.res4.0.conv3.* | res4_0_branch2c_{bn_*,w} | (1024,) (1024,) (1024,) (1024,) (1024,256,1,1) |
| backbone.res4.0.shortcut.* | res4_0_branch1_{bn_*,w} | (1024,) (1024,) (1024,) (1024,) (1024,512,1,1) |
| backbone.res4.1.conv1.* | res4_1_branch2a_{bn_*,w} | (256,) (256,) (256,) (256,) (256,1024,1,1) |
| backbone.res4.1.conv2.* | res4_1_branch2b_{bn_*,w} | (256,) (256,) (256,) (256,) (256,256,3,3) |
| backbone.res4.1.conv3.* | res4_1_branch2c_{bn_*,w} | (1024,) (1024,) (1024,) (1024,) (1024,256,1,1) |
| backbone.res4.2.conv1.* | res4_2_branch2a_{bn_*,w} | (256,) (256,) (256,) (256,) (256,1024,1,1) |
| backbone.res4.2.conv2.* | res4_2_branch2b_{bn_*,w} | (256,) (256,) (256,) (256,) (256,256,3,3) |
| backbone.res4.2.conv3.* | res4_2_branch2c_{bn_*,w} | (1024,) (1024,) (1024,) (1024,) (1024,256,1,1) |
| backbone.res4.3.conv1.* | res4_3_branch2a_{bn_*,w} | (256,) (256,) (256,) (256,) (256,1024,1,1) |
| backbone.res4.3.conv2.* | res4_3_branch2b_{bn_*,w} | (256,) (256,) (256,) (256,) (256,256,3,3) |
| backbone.res4.3.conv3.* | res4_3_branch2c_{bn_*,w} | (1024,) (1024,) (1024,) (1024,) (1024,256,1,1) |
| backbone.res4.4.conv1.* | res4_4_branch2a_{bn_*,w} | (256,) (256,) (256,) (256,) (256,1024,1,1) |
| backbone.res4.4.conv2.* | res4_4_branch2b_{bn_*,w} | (256,) (256,) (256,) (256,) (256,256,3,3) |
| backbone.res4.4.conv3.* | res4_4_branch2c_{bn_*,w} | (1024,) (1024,) (1024,) (1024,) (1024,256,1,1) |
| backbone.res4.5.conv1.* | res4_5_branch2a_{bn_*,w} | (256,) (256,) (256,) (256,) (256,1024,1,1) |
| backbone.res4.5.conv2.* | res4_5_branch2b_{bn_*,w} | (256,) (256,) (256,) (256,) (256,256,3,3) |
| backbone.res4.5.conv3.* | res4_5_branch2c_{bn_*,w} | (1024,) (1024,) (1024,) (1024,) (1024,256,1,1) |
| backbone.stem.conv1.norm.* | res_conv1_bn_* | (64,) (64,) (64,) (64,) |
| backbone.stem.conv1.weight | conv1_w | (64, 3, 7, 7) |
| roi_heads.res5.0.conv1.* | res5_0_branch2a_{bn_*,w} | (512,) (512,) (512,) (512,) (512,1024,1,1) |
| roi_heads.res5.0.conv2.* | res5_0_branch2b_{bn_*,w} | (512,) (512,) (512,) (512,) (512,512,3,3) |
| roi_heads.res5.0.conv3.* | res5_0_branch2c_{bn_*,w} | (2048,) (2048,) (2048,) (2048,) (2048,512,1,1) |
| roi_heads.res5.0.shortcut.* | res5_0_branch1_{bn_*,w} | (2048,) (2048,) (2048,) (2048,) (2048,1024,1,1) |
| roi_heads.res5.1.conv1.* | res5_1_branch2a_{bn_*,w} | (512,) (512,) (512,) (512,) (512,2048,1,1) |
| roi_heads.res5.1.conv2.* | res5_1_branch2b_{bn_*,w} | (512,) (512,) (512,) (512,) (512,512,3,3) |
| roi_heads.res5.1.conv3.* | res5_1_branch2c_{bn_*,w} | (2048,) (2048,) (2048,) (2048,) (2048,512,1,1) |
| roi_heads.res5.2.conv1.* | res5_2_branch2a_{bn_*,w} | (512,) (512,) (512,) (512,) (512,2048,1,1) |
| roi_heads.res5.2.conv2.* | res5_2_branch2b_{bn_*,w} | (512,) (512,) (512,) (512,) (512,512,3,3) |
| roi_heads.res5.2.conv3.* | res5_2_branch2c_{bn_*,w} | (2048,) (2048,) (2048,) (2048,) (2048,512,1,1) |
WARNING [06/01 18:32:29 fvcore.common.checkpoint]: Some model parameters or buffers are not found in the checkpoint:
proposal_generator.rpn_head.anchor_deltas.{bias, weight}
proposal_generator.rpn_head.conv.{bias, weight}
proposal_generator.rpn_head.objectness_logits.{bias, weight}
roi_heads.box_predictor.bbox_pred.0.{bias, weight}
roi_heads.box_predictor.bbox_pred.2.{bias, weight}
roi_heads.box_predictor.cls_score.linear.{bias, weight}
roi_heads.box_predictor.cls_score.zs_weight
roi_heads.box_predictor.freq_weight
WARNING [06/01 18:32:29 fvcore.common.checkpoint]: The checkpoint state_dict contains keys that are not used by the model:
fc1000.{bias, weight}
stem.conv1.bias
[06/01 18:32:29 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in training: [ResizeShortestEdge(short_edge_length=(800,), max_size=1333, sample_style='choice'), RandomFlip()]
[06/01 18:32:45 d2.data.datasets.coco]: Loading datasets\coco/zero-shot/instances_train2017_seen_2_oriorder.json takes 16.23 seconds.
[06/01 18:32:46 d2.data.datasets.coco]: Loaded 107761 images in COCO format from datasets\coco/zero-shot/instances_train2017_seen_2_oriorder.json
[06/01 18:32:52 d2.data.build]: Removed 0 images with no usable annotations. 107761 images left.
[06/01 18:32:59 d2.data.build]: Distribution of instances among all 80 categories:
| category | #instances | category | #instances | category | #instances |
|:-------------:|:-------------|:------------:|:-------------|:-------------:|:-------------|
| person | 257253 | bicycle | 7056 | car | 43533 |
| motorcycle | 8654 | airplane | 0 | bus | 0 |
| train | 4570 | truck | 9970 | boat | 10576 |
| traffic light | 0 | fire hydrant | 0 | stop sign | 0 |
| parking meter | 0 | bench | 9820 | bird | 10542 |
| cat | 0 | dog | 0 | horse | 6567 |
| sheep | 9223 | cow | 0 | elephant | 0 |
| bear | 1294 | zebra | 5269 | giraffe | 5128 |
| backpack | 8714 | umbrella | 0 | handbag | 12342 |
| tie | 0 | suitcase | 6112 | frisbee | 2681 |
| skis | 6623 | snowboard | 0 | sports ball | 0 |
| kite | 8802 | baseball bat | 0 | baseball gl.. | 0 |
| skateboard | 0 | surfboard | 6095 | tennis racket | 0 |
| bottle | 24070 | wine glass | 0 | cup | 0 |
| fork | 5474 | knife | 0 | spoon | 6159 |
| bowl | 14323 | banana | 9195 | apple | 5776 |
| sandwich | 4356 | orange | 6302 | broccoli | 7261 |
| carrot | 7758 | hot dog | 0 | pizza | 5807 |
| donut | 7005 | cake | 0 | chair | 38073 |
| couch | 0 | potted plant | 0 | bed | 4192 |
| dining table | 0 | toilet | 4149 | tv | 5803 |
| laptop | 4960 | mouse | 2261 | remote | 5700 |
| keyboard | 0 | cell phone | 0 | microwave | 1672 |
| oven | 3334 | toaster | 225 | sink | 0 |
| refrigerator | 2634 | book | 24077 | clock | 6320 |
| vase | 6577 | scissors | 0 | teddy bear | 0 |
| hair drier | 0 | toothbrush | 1945 | | |
| total | 656232 | | | | |
[06/01 18:32:59 d2.data.build]: Using training sampler TrainingSampler
[06/01 18:32:59 d2.data.common]: Serializing 107761 elements to byte tensors and concatenating them all ...
[06/01 18:33:02 d2.data.common]: Serialized dataset takes 361.37 MiB
train_net.py:141: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
[06/01 18:33:04 detectron2]: Starting training from iteration 0
F:\Detic-main\detic\modeling\meta_arch\custom_rcnn.py:133: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torch\functional.py:513: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\TensorShape.cpp:3610.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torch\optim\lr_scheduler.py:216: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn(
[06/01 18:33:44 d2.utils.events]: eta: 19:57:04 iter: 20 total_loss: 2.692 loss_cls: 1.654 loss_box_reg: 0.1041 loss_rpn_cls: 0.6569 loss_rpn_loc: 0.2909 time: 0.8569 data_time: 1.1773 lr: 0.00039962 max_mem: 4648M
[06/01 18:34:00 d2.utils.events]: eta: 19:50:43 iter: 40 total_loss: 3.211 loss_cls: 1.362 loss_box_reg: 0.4589 loss_rpn_cls: 0.5044 loss_rpn_loc: 0.5539 time: 0.8242 data_time: 0.0033 lr: 0.00079922 max_mem: 4648M
[06/01 18:34:14 d2.utils.events]: eta: 19:41:28 iter: 60 total_loss: 3.191 loss_cls: 2.113 loss_box_reg: 0.1936 loss_rpn_cls: 0.5298 loss_rpn_loc: 0.3124 time: 0.7772 data_time: 0.0035 lr: 0.0011988 max_mem: 4648M
[06/01 18:34:28 d2.utils.events]: eta: 19:30:39 iter: 80 total_loss: 2.688 loss_cls: 1.888 loss_box_reg: 0.0985 loss_rpn_cls: 0.489 loss_rpn_loc: 0.2139 time: 0.7650 data_time: 0.0029 lr: 0.0015984 max_mem: 4648M
[06/01 18:34:43 d2.utils.events]: eta: 19:26:52 iter: 100 total_loss: 2.677 loss_cls: 1.859 loss_box_reg: 0.1172 loss_rpn_cls: 0.4848 loss_rpn_loc: 0.1601 time: 0.7560 data_time: 0.0059 lr: 0.001998 max_mem: 4648M
[06/01 18:34:56 d2.utils.events]: eta: 19:14:31 iter: 120 total_loss: 2.585 loss_cls: 1.628 loss_box_reg: 0.1362 loss_rpn_cls: 0.4333 loss_rpn_loc: 0.2356 time: 0.7354 data_time: 0.0089 lr: 0.0023976 max_mem: 4648M
[06/01 18:35:08 d2.utils.events]: eta: 18:31:02 iter: 140 total_loss: 2.278 loss_cls: 1.44 loss_box_reg: 0.1201 loss_rpn_cls: 0.4139 loss_rpn_loc: 0.199 time: 0.7191 data_time: 0.0030 lr: 0.0027972 max_mem: 4648M
[06/01 18:35:22 d2.utils.events]: eta: 17:49:20 iter: 160 total_loss: 1.838 loss_cls: 1.102 loss_box_reg: 0.1764 loss_rpn_cls: 0.4233 loss_rpn_loc: 0.1694 time: 0.7117 data_time: 0.0030 lr: 0.0031968 max_mem: 4648M
[06/01 18:35:36 d2.utils.events]: eta: 18:02:41 iter: 180 total_loss: 2.179 loss_cls: 0.8355 loss_box_reg: 0.212 loss_rpn_cls: 0.4705 loss_rpn_loc: 0.3198 time: 0.7143 data_time: 0.0083 lr: 0.0035964 max_mem: 4648M
[06/01 18:35:52 d2.utils.events]: eta: 18:30:17 iter: 200 total_loss: 2.071 loss_cls: 0.7756 loss_box_reg: 0.1469 loss_rpn_cls: 0.4746 loss_rpn_loc: 0.297 time: 0.7191 data_time: 0.0031 lr: 0.003996 max_mem: 4648M
[06/01 18:36:06 d2.utils.events]: eta: 18:20:54 iter: 220 total_loss: 1.531 loss_cls: 0.4182 loss_box_reg: 0.214 loss_rpn_cls: 0.4799 loss_rpn_loc: 0.2744 time: 0.7186 data_time: 0.0031 lr: 0.0043956 max_mem: 4648M
[06/01 18:36:18 d2.utils.events]: eta: 17:59:07 iter: 240 total_loss: 1.333 loss_cls: 0.4441 loss_box_reg: 0.1751 loss_rpn_cls: 0.4943 loss_rpn_loc: 0.2628 time: 0.7098 data_time: 0.0034 lr: 0.0047952 max_mem: 4648M
[06/01 18:36:31 d2.utils.events]: eta: 17:45:09 iter: 260 total_loss: 1.232 loss_cls: 0.3432 loss_box_reg: 0.1424 loss_rpn_cls: 0.4351 loss_rpn_loc: 0.2283 time: 0.7027 data_time: 0.0027 lr: 0.0051948 max_mem: 4648M
[06/01 18:36:44 d2.utils.events]: eta: 17:41:25 iter: 280 total_loss: 1.024 loss_cls: 0.2882 loss_box_reg: 0.09724 loss_rpn_cls: 0.4378 loss_rpn_loc: 0.2105 time: 0.7011 data_time: 0.0028 lr: 0.0055944 max_mem: 4648M
[06/01 18:36:58 d2.utils.events]: eta: 17:39:48 iter: 300 total_loss: 1.087 loss_cls: 0.2558 loss_box_reg: 0.08751 loss_rpn_cls: 0.4812 loss_rpn_loc: 0.2395 time: 0.6986 data_time: 0.0033 lr: 0.005994 max_mem: 4648M
[06/01 18:37:11 d2.utils.events]: eta: 17:19:01 iter: 320 total_loss: 1.097 loss_cls: 0.2909 loss_box_reg: 0.1351 loss_rpn_cls: 0.4473 loss_rpn_loc: 0.212 time: 0.6949 data_time: 0.0046 lr: 0.0063936 max_mem: 4648M
[06/01 18:37:26 d2.utils.events]: eta: 17:38:27 iter: 340 total_loss: 0.9854 loss_cls: 0.2784 loss_box_reg: 0.1124 loss_rpn_cls: 0.4079 loss_rpn_loc: 0.1789 time: 0.6995 data_time: 0.0034 lr: 0.0067932 max_mem: 4648M
[06/01 18:37:38 d2.utils.events]: eta: 17:16:29 iter: 360 total_loss: 0.9864 loss_cls: 0.2833 loss_box_reg: 0.09979 loss_rpn_cls: 0.3913 loss_rpn_loc: 0.16 time: 0.6935 data_time: 0.0042 lr: 0.0071928 max_mem: 4648M
[06/01 18:37:52 d2.utils.events]: eta: 17:14:32 iter: 380 total_loss: 1.31 loss_cls: 0.3687 loss_box_reg: 0.1613 loss_rpn_cls: 0.4713 loss_rpn_loc: 0.2502 time: 0.6926 data_time: 0.0035 lr: 0.0075924 max_mem: 4648M
[06/01 18:38:05 d2.utils.events]: eta: 17:10:56 iter: 400 total_loss: 1.053 loss_cls: 0.2638 loss_box_reg: 0.1124 loss_rpn_cls: 0.4462 loss_rpn_loc: 0.1738 time: 0.6917 data_time: 0.0028 lr: 0.007992 max_mem: 4648M
[06/01 18:38:17 d2.utils.events]: eta: 16:59:19 iter: 420 total_loss: 1.155 loss_cls: 0.3765 loss_box_reg: 0.103 loss_rpn_cls: 0.4749 loss_rpn_loc: 0.2382 time: 0.6855 data_time: 0.0028 lr: 0.0083916 max_mem: 4648M
[06/01 18:38:33 d2.utils.events]: eta: 17:13:50 iter: 440 total_loss: 1.132 loss_cls: 0.2836 loss_box_reg: 0.1157 loss_rpn_cls: 0.4713 loss_rpn_loc: 0.2449 time: 0.6905 data_time: 0.0034 lr: 0.0087912 max_mem: 4648M
[06/01 18:38:46 d2.utils.events]: eta: 17:11:50 iter: 460 total_loss: 1.144 loss_cls: 0.2744 loss_box_reg: 0.1068 loss_rpn_cls: 0.445 loss_rpn_loc: 0.2166 time: 0.6892 data_time: 0.0036 lr: 0.0091908 max_mem: 4648M
[06/01 18:39:01 d2.utils.events]: eta: 17:14:07 iter: 480 total_loss: 0.8858 loss_cls: 0.268 loss_box_reg: 0.08814 loss_rpn_cls: 0.4031 loss_rpn_loc: 0.143 time: 0.6918 data_time: 0.0028 lr: 0.0095904 max_mem: 4648M
[06/01 18:39:17 d2.utils.events]: eta: 17:23:01 iter: 500 total_loss: 1.236 loss_cls: 0.3258 loss_box_reg: 0.1566 loss_rpn_cls: 0.4449 loss_rpn_loc: 0.2385 time: 0.6957 data_time: 0.0038 lr: 0.00999 max_mem: 4648M绿框的:
python train_net.py --num-gpus 1 --config-file .\configs\Detic_OVCOCO_CLIP_R50_1x_max-size_caption.yaml训练界面:
Command Line Args: Namespace(config_file='.\\configs\\Detic_OVCOCO_CLIP_R50_1x_max-size_caption.yaml', dist_url='tcp://127.0.0.1:20594', eval_only=False, machine_rank=0, num_gpus=1, num_machines=1, opts=[], resume=False)
[06/01 18:10:49 detectron2]: Rank of current process: 0. World size: 1
[06/01 18:10:50 detectron2]: Environment info:
---------------------- -------------------------------------------------------------------------------------------------
sys.platform win32
Python 3.8.18 (default, Sep 11 2023, 13:39:12) [MSC v.1916 64 bit (AMD64)]
numpy 1.23.2
detectron2 0.6 @f:\llava_grounding_main\detectron2\detectron2
Compiler MSVC 193732825
CUDA compiler CUDA 12.1
detectron2 arch flags f:\llava_grounding_main\detectron2\detectron2\_C.cp38-win_amd64.pyd; cannot find cuobjdump
DETECTRON2_ENV_MODULE <not set>
PyTorch 2.4.0+cu121 @C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torch
PyTorch debug build False
GPU available Yes
GPU 0 NVIDIA GeForce RTX 3060 (arch=8.6)
Driver version 560.94
CUDA_HOME C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
Pillow 9.5.0
torchvision 0.19.0+cu121 @C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torchvision
torchvision arch flags C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torchvision\_C.pyd; cannot find cuobjdump
fvcore 0.1.5.post20221221
iopath 0.1.7
cv2 4.8.1
---------------------- -------------------------------------------------------------------------------------------------
PyTorch built with:
- C++ Version: 201703
- MSVC 192930154
- Intel(R) oneAPI Math Kernel Library Version 2024.2-Product Build 20240605 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v3.4.2 (Git Hash 1137e04ec0b5251ca2b4400a4fd3c667ce843d67)
- OpenMP 2019
- LAPACK is enabled (usually provided by MKL)
- CPU capability usage: AVX2
- CUDA Runtime 12.1
- NVCC architecture flags: -gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_90,code=sm_90
- CuDNN 90.1 (built against CUDA 12.4)
- Magma 2.5.4
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=12.1, CUDNN_VERSION=9.1.0, CXX_COMPILER=C:/actions-runner/_work/pytorch/pytorch/builder/windows/tmp_bin/sccache-cl.exe, CXX_FLAGS=/DWIN32 /D_WINDOWS /GR /EHsc /Zc:__cplusplus /bigobj /FS /utf-8 -DUSE_PTHREADPOOL -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE /wd4624 /wd4068 /wd4067 /wd4267 /wd4661 /wd4717 /wd4244 /wd4804 /wd4273, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=2.4.0, USE_CUDA=ON, USE_CUDNN=ON, USE_CUSPARSELT=OFF, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_GLOO=ON, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=OFF, USE_NNPACK=OFF, USE_OPENMP=ON, USE_ROCM=OFF, USE_ROCM_KERNEL_ASSERT=OFF,
[06/01 18:10:50 detectron2]: Command line arguments: Namespace(config_file='.\\configs\\Detic_OVCOCO_CLIP_R50_1x_max-size_caption.yaml', dist_url='tcp://127.0.0.1:20594', eval_only=False, machine_rank=0, num_gpus=1, num_machines=1, opts=[], resume=False)
[06/01 18:10:50 detectron2]: Contents of args.config_file=.\configs\Detic_OVCOCO_CLIP_R50_1x_max-size_caption.yaml:
_BASE_: "Base_OVCOCO_C4_1x.yaml"
MODEL:
WEIGHTS: "models/BoxSup_OVCOCO_CLIP_R50_1x.pth"
WITH_CAPTION: True
SYNC_CAPTION_BATCH: True
ROI_BOX_HEAD:
WS_NUM_PROPS: 32
ADD_IMAGE_BOX: True # caption loss is added to the image-box
IMAGE_LABEL_LOSS: 'max_size'
NEG_CAP_WEIGHT: 1.0
SOLVER:
IMS_PER_BATCH: 16
BASE_LR: 0.02
STEPS: (60000, 80000)
MAX_ITER: 90000
DATASETS:
TRAIN: ("coco_zeroshot_train_oriorder", "coco_caption_train_tags")
INPUT:
CUSTOM_AUG: ResizeShortestEdge
MIN_SIZE_TRAIN_SAMPLING: range
MIN_SIZE_TRAIN: (800, 800)
DATALOADER:
SAMPLER_TRAIN: "MultiDatasetSampler"
DATASET_RATIO: [1, 4]
USE_DIFF_BS_SIZE: True
DATASET_BS: [2, 8]
USE_RFS: [False, False]
DATASET_MIN_SIZES: [[800, 800], [400, 400]]
DATASET_MAX_SIZES: [1333, 667]
FILTER_EMPTY_ANNOTATIONS: False
MULTI_DATASET_GROUPING: True
DATASET_ANN: ['box', 'captiontag']
NUM_WORKERS: 8
WITH_IMAGE_LABELS: True
[06/01 18:10:50 detectron2]: Running with full config:
CUDNN_BENCHMARK: false
DATALOADER:
ASPECT_RATIO_GROUPING: true
DATASET_ANN:
- box
- captiontag
DATASET_BS:
- 2
- 8
DATASET_INPUT_SCALE:
- &id001
- 0.1
- 2.0
- - 0.5
- 1.5
DATASET_INPUT_SIZE:
- 896
- 384
DATASET_MAX_SIZES:
- 1333
- 667
DATASET_MIN_SIZES:
- - 800
- 800
- - 400
- 400
DATASET_RATIO:
- 1
- 4
FILTER_EMPTY_ANNOTATIONS: false
MULTI_DATASET_GROUPING: true
NUM_WORKERS: 8
REPEAT_THRESHOLD: 0.0
SAMPLER_TRAIN: MultiDatasetSampler
TARFILE_PATH: datasets/imagenet/metadata-22k/tar_files.npy
TAR_INDEX_DIR: datasets/imagenet/metadata-22k/tarindex_npy
USE_DIFF_BS_SIZE: true
USE_RFS:
- false
- false
USE_TAR_DATASET: false
DATASETS:
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
PROPOSAL_FILES_TEST: []
PROPOSAL_FILES_TRAIN: []
TEST:
- coco_generalized_zeroshot_val
TRAIN:
- coco_zeroshot_train_oriorder
- coco_caption_train_tags
DEBUG: false
DEBUG_SHOW_NAME: false
EVAL_AP_FIX: false
EVAL_CAT_SPEC_AR: false
EVAL_PRED_AR: false
EVAL_PROPOSAL_AR: false
FIND_UNUSED_PARAM: true
FP16: true
GEN_PSEDO_LABELS: false
GLOBAL:
HACK: 1.0
INPUT:
CROP:
ENABLED: false
SIZE:
- 0.9
- 0.9
TYPE: relative_range
CUSTOM_AUG: ResizeShortestEdge
FORMAT: BGR
MASK_FORMAT: polygon
MAX_SIZE_TEST: 1333
MAX_SIZE_TRAIN: 1333
MIN_SIZE_TEST: 800
MIN_SIZE_TRAIN:
- 800
- 800
MIN_SIZE_TRAIN_SAMPLING: range
NOT_CLAMP_BOX: false
RANDOM_FLIP: horizontal
SCALE_RANGE: *id001
TEST_INPUT_TYPE: default
TEST_SIZE: 640
TRAIN_SIZE: 640
IS_DEBUG: false
MODEL:
ANCHOR_GENERATOR:
ANGLES:
- - -90
- 0
- 90
ASPECT_RATIOS:
- - 0.5
- 1.0
- 2.0
NAME: DefaultAnchorGenerator
OFFSET: 0.0
SIZES:
- - 32
- 64
- 128
- 256
- 512
BACKBONE:
FREEZE_AT: 2
NAME: build_resnet_backbone
BIFPN:
NORM: GN
NUM_BIFPN: 6
NUM_LEVELS: 5
OUT_CHANNELS: 160
SEPARABLE_CONV: false
CAP_BATCH_RATIO: 4
CENTERNET:
AS_PROPOSAL: false
CENTER_NMS: false
FPN_STRIDES:
- 8
- 16
- 32
- 64
- 128
HM_FOCAL_ALPHA: 0.25
HM_FOCAL_BETA: 4
HM_MIN_OVERLAP: 0.8
IGNORE_HIGH_FP: -1.0
INFERENCE_TH: 0.05
IN_FEATURES:
- p3
- p4
- p5
- p6
- p7
LOC_LOSS_TYPE: giou
LOSS_GAMMA: 2.0
MIN_RADIUS: 4
MORE_POS: false
MORE_POS_THRESH: 0.2
MORE_POS_TOPK: 9
NEG_WEIGHT: 1.0
NMS_TH_TEST: 0.6
NMS_TH_TRAIN: 0.6
NORM: GN
NOT_NMS: false
NOT_NORM_REG: true
NO_REDUCE: false
NUM_BOX_CONVS: 4
NUM_CLASSES: 80
NUM_CLS_CONVS: 4
NUM_SHARE_CONVS: 0
ONLY_PROPOSAL: false
POST_NMS_TOPK_TEST: 100
POST_NMS_TOPK_TRAIN: 100
POS_WEIGHT: 1.0
PRE_NMS_TOPK_TEST: 1000
PRE_NMS_TOPK_TRAIN: 1000
PRIOR_PROB: 0.01
REG_WEIGHT: 2.0
SIGMOID_CLAMP: 0.0001
SOI:
- - 0
- 80
- - 64
- 160
- - 128
- 320
- - 256
- 640
- - 512
- 10000000
USE_DEFORMABLE: false
WITH_AGN_HM: false
DATASET_LOSS_WEIGHT: []
DETR:
CLS_WEIGHT: 2.0
DEC_LAYERS: 6
DEEP_SUPERVISION: true
DIM_FEEDFORWARD: 2048
DROPOUT: 0.1
ENC_LAYERS: 6
FOCAL_ALPHA: 0.25
FROZEN_WEIGHTS: ''
GIOU_WEIGHT: 2.0
HIDDEN_DIM: 256
L1_WEIGHT: 5.0
NHEADS: 8
NO_OBJECT_WEIGHT: 0.1
NUM_CLASSES: 80
NUM_FEATURE_LEVELS: 4
NUM_OBJECT_QUERIES: 100
PRE_NORM: false
TWO_STAGE: false
USE_FED_LOSS: false
WEAK_WEIGHT: 0.1
WITH_BOX_REFINE: false
DEVICE: cuda
DLA:
DLAUP_IN_FEATURES:
- dla3
- dla4
- dla5
DLAUP_NODE: conv
MS_OUTPUT: false
NORM: BN
NUM_LAYERS: 34
OUT_FEATURES:
- dla2
USE_DLA_UP: true
DYNAMIC_CLASSIFIER: false
FPN:
FUSE_TYPE: sum
IN_FEATURES: []
NORM: ''
OUT_CHANNELS: 256
KEYPOINT_ON: false
LOAD_PROPOSALS: false
MASK_ON: false
META_ARCHITECTURE: CustomRCNN
NUM_SAMPLE_CATS: 50
PANOPTIC_FPN:
COMBINE:
ENABLED: true
INSTANCES_CONFIDENCE_THRESH: 0.5
OVERLAP_THRESH: 0.5
STUFF_AREA_LIMIT: 4096
INSTANCE_LOSS_WEIGHT: 1.0
PIXEL_MEAN:
- 103.53
- 116.28
- 123.675
PIXEL_STD:
- 1.0
- 1.0
- 1.0
PROPOSAL_GENERATOR:
MIN_SIZE: 0
NAME: RPN
RESET_CLS_TESTS: false
RESNETS:
DEFORM_MODULATED: false
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE:
- false
- false
- false
- false
DEPTH: 50
NORM: FrozenBN
NUM_GROUPS: 1
OUT_FEATURES:
- res4
RES2_OUT_CHANNELS: 256
RES5_DILATION: 1
STEM_OUT_CHANNELS: 64
STRIDE_IN_1X1: true
WIDTH_PER_GROUP: 64
RETINANET:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_WEIGHTS: &id003
- 1.0
- 1.0
- 1.0
- 1.0
FOCAL_LOSS_ALPHA: 0.25
FOCAL_LOSS_GAMMA: 2.0
IN_FEATURES:
- p3
- p4
- p5
- p6
- p7
IOU_LABELS:
- 0
- -1
- 1
IOU_THRESHOLDS:
- 0.4
- 0.5
NMS_THRESH_TEST: 0.5
NORM: ''
NUM_CLASSES: 80
NUM_CONVS: 4
PRIOR_PROB: 0.01
SCORE_THRESH_TEST: 0.05
SMOOTH_L1_LOSS_BETA: 0.1
TOPK_CANDIDATES_TEST: 1000
ROI_BOX_CASCADE_HEAD:
BBOX_REG_WEIGHTS:
- &id002
- 10.0
- 10.0
- 5.0
- 5.0
- - 20.0
- 20.0
- 10.0
- 10.0
- - 30.0
- 30.0
- 15.0
- 15.0
IOUS:
- 0.5
- 0.6
- 0.7
ROI_BOX_HEAD:
ADD_FEATURE_TO_PROP: false
ADD_IMAGE_BOX: true
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: *id002
CAPTION_WEIGHT: 1.0
CAT_FREQ_PATH: datasets/coco/zero-shot/instances_train2017_seen_2_oriorder_cat_info.json
CLS_AGNOSTIC_BBOX_REG: true
CONV_DIM: 256
EQL_FREQ_CAT: 200
FC_DIM: 1024
FED_LOSS_FREQ_WEIGHT: 0.5
FED_LOSS_NUM_CAT: 50
IGNORE_ZERO_CATS: true
IMAGE_BOX_SIZE: 1.0
IMAGE_LABEL_LOSS: max_size
IMAGE_LOSS_WEIGHT: 0.1
MULT_PROPOSAL_SCORE: false
NAME: ''
NEG_CAP_WEIGHT: 1.0
NORM: ''
NORM_TEMP: 50.0
NORM_WEIGHT: true
NUM_CONV: 0
NUM_FC: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
PRIOR_PROB: 0.01
SMOOTH_L1_BETA: 0.0
SOFTMAX_WEAK_LOSS: false
TRAIN_ON_PRED_BOXES: false
USE_BIAS: 0.0
USE_EQL_LOSS: false
USE_FED_LOSS: false
USE_SIGMOID_CE: true
USE_ZEROSHOT_CLS: true
WITH_SOFTMAX_PROP: false
WS_NUM_PROPS: 32
ZEROSHOT_WEIGHT_DIM: 512
ZEROSHOT_WEIGHT_PATH: datasets/metadata/coco_clip_a+cname.npy
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES:
- res4
IOU_LABELS:
- 0
- 1
IOU_THRESHOLDS:
- 0.5
MASK_WEIGHT: 1.0
NAME: CustomRes5ROIHeads
NMS_THRESH_TEST: 0.5
NUM_CLASSES: 80
ONE_CLASS_PER_PROPOSAL: false
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: true
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS:
- 512
- 512
- 512
- 512
- 512
- 512
- 512
- 512
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: true
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: false
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM: ''
NUM_CONV: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: *id003
BOUNDARY_THRESH: -1
CONV_DIMS:
- -1
HEAD_NAME: StandardRPNHead
IN_FEATURES:
- res4
IOU_LABELS:
- 0
- -1
- 1
IOU_THRESHOLDS:
- 0.3
- 0.7
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 2000
PRE_NMS_TOPK_TEST: 6000
PRE_NMS_TOPK_TRAIN: 12000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
COMMON_STRIDE: 4
CONVS_DIM: 128
IGNORE_VALUE: 255
IN_FEATURES:
- p2
- p3
- p4
- p5
LOSS_WEIGHT: 1.0
NAME: SemSegFPNHead
NORM: GN
NUM_CLASSES: 54
SWIN:
OUT_FEATURES:
- 1
- 2
- 3
SIZE: T
USE_CHECKPOINT: false
SYNC_CAPTION_BATCH: true
TEST_CLASSIFIERS: []
TEST_NUM_CLASSES: []
TIMM:
BASE_NAME: resnet50
FREEZE_AT: 0
NORM: FrozenBN
OUT_LEVELS:
- 3
- 4
- 5
PRETRAINED: false
WEIGHTS: models/BoxSup_OVCOCO_CLIP_R50_1x.pth
WITH_CAPTION: true
OUTPUT_DIR: output/Detic-COCO/Detic_OVCOCO_CLIP_R50_1x_max-size_caption
QUICK_DEBUG: false
SAVE_DEBUG: false
SAVE_DEBUG_PATH: output/save_debug/
SAVE_PTH: false
SEED: -1
SOLVER:
AMP:
ENABLED: false
BACKBONE_MULTIPLIER: 1.0
BASE_LR: 0.02
BASE_LR_END: 0.0
BIAS_LR_FACTOR: 1.0
CHECKPOINT_PERIOD: 1000000000
CLIP_GRADIENTS:
CLIP_TYPE: value
CLIP_VALUE: 1.0
ENABLED: false
NORM_TYPE: 2.0
CUSTOM_MULTIPLIER: 1.0
CUSTOM_MULTIPLIER_NAME: []
GAMMA: 0.1
IMS_PER_BATCH: 16
LR_SCHEDULER_NAME: WarmupMultiStepLR
MAX_ITER: 90000
MOMENTUM: 0.9
NESTEROV: false
OPTIMIZER: SGD
REFERENCE_WORLD_SIZE: 0
RESET_ITER: false
STEPS:
- 60000
- 80000
TRAIN_ITER: -1
USE_CUSTOM_SOLVER: false
WARMUP_FACTOR: 0.001
WARMUP_ITERS: 1000
WARMUP_METHOD: linear
WEIGHT_DECAY: 0.0001
WEIGHT_DECAY_BIAS: null
WEIGHT_DECAY_NORM: 0.0
TEST:
AUG:
ENABLED: false
FLIP: true
MAX_SIZE: 4000
MIN_SIZES:
- 400
- 500
- 600
- 700
- 800
- 900
- 1000
- 1100
- 1200
DETECTIONS_PER_IMAGE: 100
EVAL_PERIOD: 0
EXPECTED_RESULTS: []
KEYPOINT_OKS_SIGMAS: []
PRECISE_BN:
ENABLED: false
NUM_ITER: 200
VERSION: 2
VIS_PERIOD: 0
VIS_THRESH: 0.3
WITH_IMAGE_LABELS: true
[06/01 18:10:50 detectron2]: Full config saved to output/Detic-COCO/Detic_OVCOCO_CLIP_R50_1x_max-size_caption\config.yaml
[06/01 18:10:50 d2.utils.env]: Using a generated random seed 50341023
Loading pretrained CLIP
[06/01 18:10:56 detectron2]: Model:
CustomRCNN(
(backbone): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
)
(proposal_generator): RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(
1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(objectness_logits): Conv2d(1024, 15, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(1024, 60, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
(roi_heads): CustomRes5ROIHeads(
(pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
(box_predictor): DeticFastRCNNOutputLayers(
(cls_score): ZeroShotClassifier(
(linear): Linear(in_features=2048, out_features=512, bias=True)
)
(bbox_pred): Sequential(
(0): Linear(in_features=2048, out_features=2048, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=2048, out_features=4, bias=True)
)
)
)
(text_encoder): CLIPTEXT(
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(1): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(2): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(3): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(4): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(5): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(6): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(7): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(8): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(9): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(10): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(11): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
)
(token_embedding): Embedding(49408, 512)
(ln_final): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
[06/01 18:10:56 fvcore.common.checkpoint]: [Checkpointer] Loading from models/BoxSup_OVCOCO_CLIP_R50_1x.pth ...
C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\fvcore\common\checkpoint.py:252: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
return torch.load(f, map_location=torch.device("cpu"))
WARNING [06/01 18:10:56 fvcore.common.checkpoint]: Some model parameters or buffers are not found in the checkpoint:
roi_heads.box_predictor.freq_weight
text_encoder.ln_final.{bias, weight}
text_encoder.token_embedding.weight
text_encoder.transformer.resblocks.0.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.0.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.0.ln_1.{bias, weight}
text_encoder.transformer.resblocks.0.ln_2.{bias, weight}
text_encoder.transformer.resblocks.0.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.0.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.1.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.1.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.1.ln_1.{bias, weight}
text_encoder.transformer.resblocks.1.ln_2.{bias, weight}
text_encoder.transformer.resblocks.1.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.1.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.10.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.10.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.10.ln_1.{bias, weight}
text_encoder.transformer.resblocks.10.ln_2.{bias, weight}
text_encoder.transformer.resblocks.10.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.10.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.11.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.11.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.11.ln_1.{bias, weight}
text_encoder.transformer.resblocks.11.ln_2.{bias, weight}
text_encoder.transformer.resblocks.11.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.11.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.2.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.2.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.2.ln_1.{bias, weight}
text_encoder.transformer.resblocks.2.ln_2.{bias, weight}
text_encoder.transformer.resblocks.2.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.2.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.3.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.3.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.3.ln_1.{bias, weight}
text_encoder.transformer.resblocks.3.ln_2.{bias, weight}
text_encoder.transformer.resblocks.3.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.3.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.4.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.4.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.4.ln_1.{bias, weight}
text_encoder.transformer.resblocks.4.ln_2.{bias, weight}
text_encoder.transformer.resblocks.4.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.4.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.5.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.5.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.5.ln_1.{bias, weight}
text_encoder.transformer.resblocks.5.ln_2.{bias, weight}
text_encoder.transformer.resblocks.5.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.5.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.6.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.6.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.6.ln_1.{bias, weight}
text_encoder.transformer.resblocks.6.ln_2.{bias, weight}
text_encoder.transformer.resblocks.6.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.6.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.7.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.7.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.7.ln_1.{bias, weight}
text_encoder.transformer.resblocks.7.ln_2.{bias, weight}
text_encoder.transformer.resblocks.7.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.7.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.8.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.8.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.8.ln_1.{bias, weight}
text_encoder.transformer.resblocks.8.ln_2.{bias, weight}
text_encoder.transformer.resblocks.8.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.8.mlp.c_proj.{bias, weight}
text_encoder.transformer.resblocks.9.attn.out_proj.{bias, weight}
text_encoder.transformer.resblocks.9.attn.{in_proj_bias, in_proj_weight}
text_encoder.transformer.resblocks.9.ln_1.{bias, weight}
text_encoder.transformer.resblocks.9.ln_2.{bias, weight}
text_encoder.transformer.resblocks.9.mlp.c_fc.{bias, weight}
text_encoder.transformer.resblocks.9.mlp.c_proj.{bias, weight}
text_encoder.{positional_embedding, text_projection}
[06/01 18:10:57 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in training: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='range'), RandomFlip()]
[06/01 18:11:13 d2.data.datasets.coco]: Loading datasets\coco/zero-shot/instances_train2017_seen_2_oriorder.json takes 16.05 seconds.
[06/01 18:11:14 d2.data.datasets.coco]: Loaded 107761 images in COCO format from datasets\coco/zero-shot/instances_train2017_seen_2_oriorder.json
[06/01 18:11:21 detic.data.datasets.lvis_v1]: Loaded 100646 images in the LVIS v1 format from datasets\coco/annotations/captions_train2017_tags_allcaps.json
dataset sizes [107761, 100646]
[06/01 18:11:24 d2.data.common]: Serializing 208407 elements to byte tensors and concatenating them all ...
[06/01 18:11:28 d2.data.common]: Serialized dataset takes 412.78 MiB
train_net.py:141: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
[06/01 18:11:29 detectron2]: Starting training from iteration 0
F:\Detic-main\detic\modeling\meta_arch\custom_rcnn.py:133: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torch\functional.py:513: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\TensorShape.cpp:3610.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
C:\ProgramData\miniconda3\envs\llavag\lib\site-packages\torch\nn\functional.py:5560: UserWarning: 1Torch was not compiled with flash attention. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:555.)
attn_output = scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
[06/01 18:12:47 d2.utils.events]: eta: 13:30:02 iter: 20 total_loss: 0.9656 loss_cls: 0 loss_box_reg: 0 image_loss: 0.9482 loss_rpn_cls: 0 loss_rpn_loc: 0 time: 0.7746 data_time: 3.1242 lr: 0.00039962 max_mem: 4891M
[06/01 18:13:00 d2.utils.events]: eta: 14:16:59 iter: 40 total_loss: 0.8001 loss_cls: 0.1149 loss_box_reg: 0.07416 image_loss: 0 loss_rpn_cls: 0.0408 loss_rpn_loc: 0.04454 time: 0.7132 data_time: 0.0090 lr: 0.00079922 max_mem: 4891M
[06/01 18:13:13 d2.utils.events]: eta: 14:16:47 iter: 60 total_loss: 0.7527 loss_cls: 0.03435 loss_box_reg: 0.02981 image_loss: 0.3297 loss_rpn_cls: 0.01289 loss_rpn_loc: 0.01264 time: 0.6837 data_time: 0.0076 lr: 0.0011988 max_mem: 4892M
[06/01 18:13:26 d2.utils.events]: eta: 17:05:51 iter: 80 total_loss: 0.6891 loss_cls: 0.03277 loss_box_reg: 0.03636 image_loss: 0 loss_rpn_cls: 0.02024 loss_rpn_loc: 0.01448 time: 0.6751 data_time: 0.0089 lr: 0.0015984 max_mem: 4892M
[06/01 18:13:39 d2.utils.events]: eta: 17:05:37 iter: 100 total_loss: 0.7607 loss_cls: 0.02319 loss_box_reg: 0.03272 image_loss: 0.3596 loss_rpn_cls: 0.01089 loss_rpn_loc: 0.008463 time: 0.6667 data_time: 0.0054 lr: 0.001998 max_mem: 4892M
[06/01 18:13:51 d2.utils.events]: eta: 13:29:08 iter: 120 total_loss: 0.6448 loss_cls: 0 loss_box_reg: 0 image_loss: 0.546 loss_rpn_cls: 0 loss_rpn_loc: 0 time: 0.6546 data_time: 0.0066 lr: 0.0023976 max_mem: 4892M
[06/01 18:14:03 d2.utils.events]: eta: 12:56:32 iter: 140 total_loss: 0.6852 loss_cls: 0 loss_box_reg: 0 image_loss: 0.5059 loss_rpn_cls: 0 loss_rpn_loc: 0 time: 0.6474 data_time: 0.0054 lr: 0.0027972 max_mem: 4893M
[06/01 18:14:17 d2.utils.events]: eta: 14:15:50 iter: 160 total_loss: 0.6721 loss_cls: 0.07292 loss_box_reg: 0.05914 image_loss: 0 loss_rpn_cls: 0.04195 loss_rpn_loc: 0.02563 time: 0.6494 data_time: 0.0055 lr: 0.0031968 max_mem: 4893M
[06/01 18:14:30 d2.utils.events]: eta: 19:33:53 iter: 180 total_loss: 0.8056 loss_cls: 0.0753 loss_box_reg: 0.08548 image_loss: 0 loss_rpn_cls: 0.03067 loss_rpn_loc: 0.02844 time: 0.6500 data_time: 0.0056 lr: 0.0035964 max_mem: 4893M
[06/01 18:14:41 d2.utils.events]: eta: 12:56:01 iter: 200 total_loss: 0.6465 loss_cls: 0 loss_box_reg: 0 image_loss: 0.5738 loss_rpn_cls: 0 loss_rpn_loc: 0 time: 0.6403 data_time: 0.0066 lr: 0.003996 max_mem: 4893M
[06/01 18:14:54 d2.utils.events]: eta: 13:28:14 iter: 220 total_loss: 0.6347 loss_cls: 0.09051 loss_box_reg: 0.1167 image_loss: 0 loss_rpn_cls: 0.03716 loss_rpn_loc: 0.01069 time: 0.6408 data_time: 0.0051 lr: 0.0043956 max_mem: 4893M
[06/01 18:15:07 d2.utils.events]: eta: 14:15:04 iter: 240 total_loss: 0.6625 loss_cls: 0.1059 loss_box_reg: 0.09115 image_loss: 0 loss_rpn_cls: 0.07941 loss_rpn_loc: 0.06764 time: 0.6406 data_time: 0.0055 lr: 0.0047952 max_mem: 4893M
[06/01 18:15:20 d2.utils.events]: eta: 14:14:53 iter: 260 total_loss: 0.7402 loss_cls: 0.05906 loss_box_reg: 0.05109 image_loss: 0.3339 loss_rpn_cls: 0.03409 loss_rpn_loc: 0.02727 time: 0.6397 data_time: 0.0051 lr: 0.0051948 max_mem: 4894M
[06/01 18:15:32 d2.utils.events]: eta: 14:14:41 iter: 280 total_loss: 0.7019 loss_cls: 0.04317 loss_box_reg: 0.03996 image_loss: 0.2476 loss_rpn_cls: 0.02012 loss_rpn_loc: 0.01788 time: 0.6384 data_time: 0.0060 lr: 0.0055944 max_mem: 4895M
[06/01 18:15:45 d2.utils.events]: eta: 14:14:30 iter: 300 total_loss: 0.6237 loss_cls: 0.05511 loss_box_reg: 0.04056 image_loss: 0.2471 loss_rpn_cls: 0.01661 loss_rpn_loc: 0.004652 time: 0.6382 data_time: 0.0059 lr: 0.005994 max_mem: 4895M
[06/01 18:15:58 d2.utils.events]: eta: 17:01:22 iter: 320 total_loss: 0.6549 loss_cls: 0.05796 loss_box_reg: 0.04952 image_loss: 0 loss_rpn_cls: 0.04849 loss_rpn_loc: 0.01719 time: 0.6385 data_time: 0.0053 lr: 0.0063936 max_mem: 4895M
[06/01 18:16:11 d2.utils.events]: eta: 17:01:09 iter: 340 total_loss: 0.6248 loss_cls: 0.04142 loss_box_reg: 0.05109 image_loss: 0.2425 loss_rpn_cls: 0.02078 loss_rpn_loc: 0.008507 time: 0.6378 data_time: 0.0057 lr: 0.0067932 max_mem: 4895M
[06/01 18:16:24 d2.utils.events]: eta: 19:29:57 iter: 360 total_loss: 0.908 loss_cls: 0.0986 loss_box_reg: 0.0627 image_loss: 0 loss_rpn_cls: 0.08474 loss_rpn_loc: 0.01765 time: 0.6386 data_time: 0.0060 lr: 0.0071928 max_mem: 4895M
[06/01 18:16:36 d2.utils.events]: eta: 17:00:41 iter: 380 total_loss: 0.861 loss_cls: 0 loss_box_reg: 0 image_loss: 0.6764 loss_rpn_cls: 0 loss_rpn_loc: 0 time: 0.6375 data_time: 0.0059 lr: 0.0075924 max_mem: 4895M
[06/01 18:16:50 d2.utils.events]: eta: 19:30:29 iter: 400 total_loss: 0.7996 loss_cls: 0.2128 loss_box_reg: 0.1527 image_loss: 0 loss_rpn_cls: 0.0739 loss_rpn_loc: 0.06048 time: 0.6394 data_time: 0.0064 lr: 0.007992 max_mem: 4895M
[06/01 18:17:02 d2.utils.events]: eta: 19:27:32 iter: 420 total_loss: 0.8131 loss_cls: 0 loss_box_reg: 0 image_loss: 0.6404 loss_rpn_cls: 0 loss_rpn_loc: 0 time: 0.6384 data_time: 0.0086 lr: 0.0083916 max_mem: 4895M
[06/01 18:17:15 d2.utils.events]: eta: 16:59:12 iter: 440 total_loss: 0.7116 loss_cls: 0 loss_box_reg: 0 image_loss: 0.5867 loss_rpn_cls: 0 loss_rpn_loc: 0 time: 0.6374 data_time: 0.0052 lr: 0.0087912 max_mem: 4895M
[06/01 18:17:28 d2.utils.events]: eta:至此完成了如上两个网络配置的训练所需做的准备,走通了也便于开展数据集迁移研究。

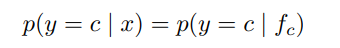

![2025年渗透测试面试题总结-匿名[校招]安全工程师(甲方)(题目+回答)](https://i-blog.csdnimg.cn/direct/2ea6508e11f348769528e86055da4fc5.png)