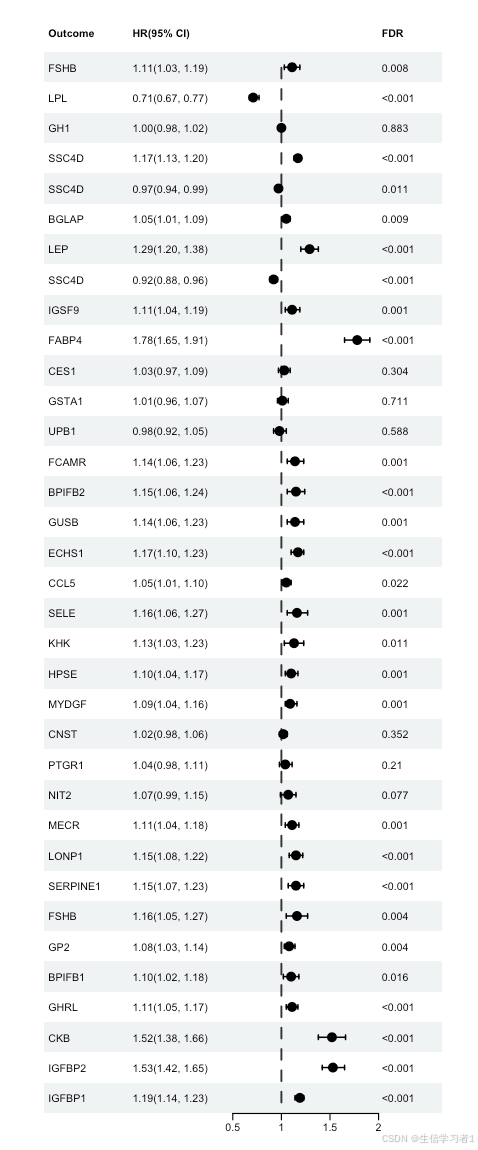
Variational Auto-Encoder(VAE)详解
本节内容完整介绍 VAE 的模型结构、优化目标、重参数化技巧及其生成机制。
回顾:Autoencoder(自编码器)
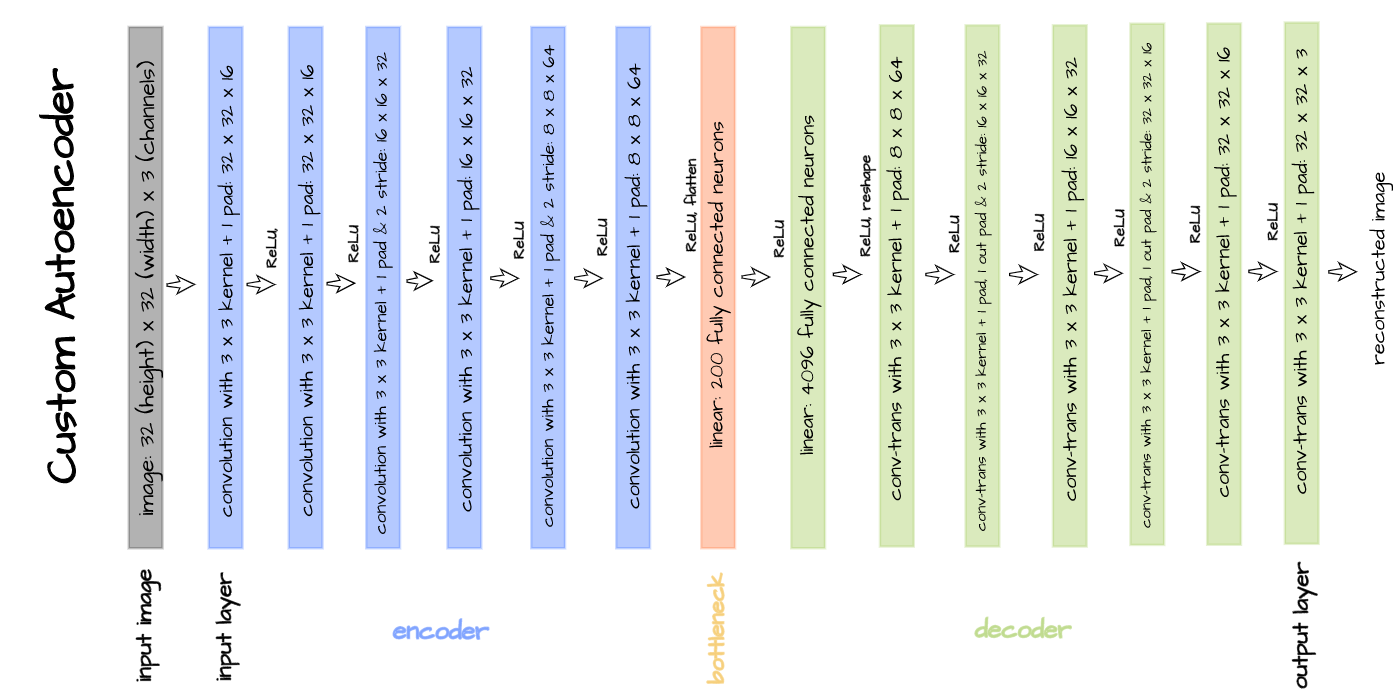
Autoencoder 是一种无监督学习模型,旨在从未标注的数据中学习压缩表示。其结构包括:
- Encoder:将输入 x x x 映射为潜在空间的表示 z z z
- Decoder:将 z z z 重构为 x ^ \hat{x} x^,使其尽可能接近原始输入 x x x
通常设置潜在变量 z z z 的维度低于 x x x,实现降维和特征提取。
Autoencoder 的训练目标
目标是最小化重构误差:
L ( x , x ^ ) = ∥ x − x ^ ∥ 2 L(x, \hat{x}) = \| x - \hat{x} \|^2 L(x,x^)=∥x−x^∥2
模型通过优化参数使得 x ^ = f ( g ( x ) ) \hat{x} = f(g(x)) x^=f(g(x)) 尽可能接近 x x x,其中 g g g 是 Encoder, f f f 是 Decoder。
Encoder 的用途
自动编码器可以重构数据,并且可以学习特征来初始化监督模型。特征捕获训练数据中的变化因素
训练完成后,Encoder 可以作为特征提取器用于其他下游任务。通常在分类等监督任务中:
- 预训练阶段训练 Autoencoder
- 丢弃 Decoder,仅保留 Encoder
- 添加分类器,进行微调训练
这种方式可利用无标签数据提升有标签任务效果。
Variational Auto-Encoder(VAE)的提出
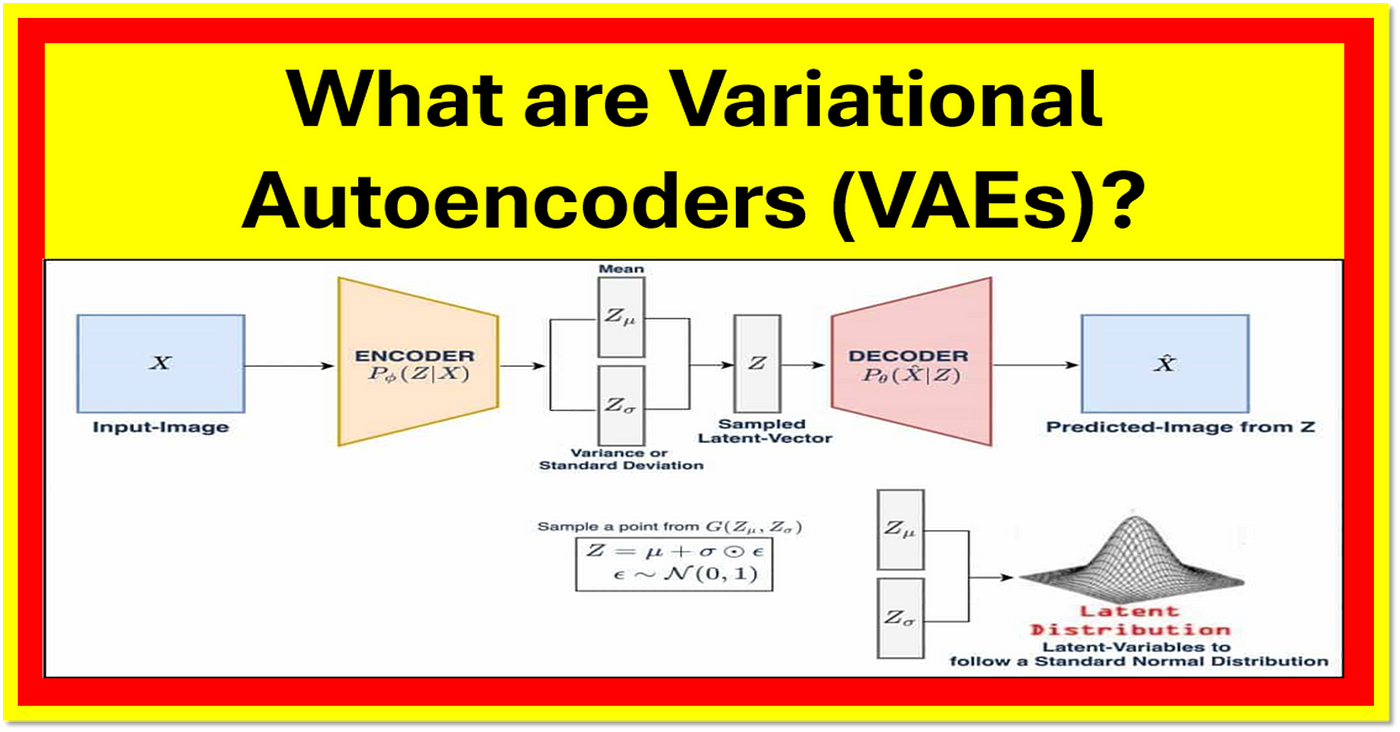
注意图中写的Variance or standard deviation有误,应该是log_var!
Autoencoder 能学习数据表示,但无法从潜在空间采样生成新样本。为此,VAE 将其扩展为生成模型:
- 假设存在潜变量 z z z,从先验分布 p ( z ) p(z) p(z)(通常是 N ( 0 , I ) \mathcal{N}(0, I) N(0,I),高斯分布)中采样
- 使用生成网络从 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z) 中生成 x x x
完整生成过程为:
- 从 p ( z ) p(z) p(z) 中采样 z z z
- 用 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z) 生成样本 x x x
但 p ( z ∣ x ) p(z|x) p(z∣x) 往往难以直接推导,因此采用变分推断,引入近似后验分布 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)。
1. 输入与编码(Encoder)
输入样本 x x x 被送入编码器(Encoder),输出两个变量:
- z mean = μ z_{\text{mean}} = \mu zmean=μ
- z log_var = log σ 2 z_{\text{log\_var}} = \log \sigma^2 zlog_var=logσ2
这些构成了潜在变量 z z z 的高斯分布参数。
2. KL 散度项(先验正则化)
使用高斯分布的 KL 散度公式计算 q ϕ ( z ∣ x ) ∼ N ( μ , σ 2 ) q_\phi(z|x) \sim \mathcal{N}(\mu, \sigma^2) qϕ(z∣x)∼N(μ,σ2) 与 p ( z ) ∼ N ( 0 , 1 ) p(z) \sim \mathcal{N}(0,1) p(z)∼N(0,1) 之间的距离:
D K L ( N ( μ , σ 2 ) ∥ N ( 0 , 1 ) ) = − 1 2 ( 1 + log σ 2 − μ 2 − σ 2 ) D_{KL}(\mathcal{N}(\mu, \sigma^2) \| \mathcal{N}(0,1)) = -\frac{1}{2} \left( 1 + \log \sigma^2 - \mu^2 - \sigma^2 \right) DKL(N(μ,σ2)∥N(0,1))=−21(1+logσ2−μ2−σ2)
这项鼓励 q ( z ∣ x ) q(z|x) q(z∣x) 与标准高斯分布接近,使得从 p ( z ) p(z) p(z) 中采样具有可行性。
3. 重参数化技巧(Reparameterization Trick)
为了使得 z z z 可导,引入噪声变量 ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0, 1) ϵ∼N(0,1),用如下方式采样 z z z:
z = μ + σ ⋅ ϵ z = \mu + \sigma \cdot \epsilon z=μ+σ⋅ϵ
这样,整个采样过程对网络参数 μ , σ \mu, \sigma μ,σ 可导,允许使用反向传播训练网络。
我们知道在神经网络中,如果某个操作是“不可导的”或者“不确定的(stochastic)”,我们就无法对它的参数进行梯度传播。
而在 VAE 中,如果我们直接从 z ∼ N ( μ , σ 2 ) z \sim \mathcal{N}(\mu, \sigma^2) z∼N(μ,σ2) 中采样,那么这个采样过程本身是随机的、不可导的,无法对 μ \mu μ 和 σ \sigma σ 求导!
所以怎么解决?
我们使用重参数化技巧,将随机性“从参数中移除”,变成一个确定性的函数:
z = μ + σ ⋅ ϵ , ϵ ∼ N ( 0 , 1 ) z = \mu + \sigma \cdot \epsilon,\quad \epsilon \sim \mathcal{N}(0,1) z=μ+σ⋅ϵ,ϵ∼N(0,1)
这个时候:
- ϵ \epsilon ϵ 是一个常量样本(在每次前向传播时采一次)
- z z z 是 μ \mu μ 和 σ \sigma σ 的一个确定函数(因为 ϵ \epsilon ϵ 视为已知)
为什么 ϵ \epsilon ϵ 不影响反向传播?
因为反向传播的目标是对损失函数 L L L 关于参数 μ \mu μ 和 σ \sigma σ 求导,比如:
$ ∂μ∂L=∂z∂L⋅∂μ∂z,∂μ∂z=1$
∂ L ∂ σ = ∂ L ∂ z ⋅ ∂ z ∂ σ , ∂ z ∂ σ = ϵ ∂L∂σ=∂L∂z⋅∂z∂σ,∂z∂σ=ϵ ∂L∂σ=∂L∂z⋅∂z∂σ,∂z∂σ=ϵ
- 虽然 ϵ \epsilon ϵ 是随机变量,但在一次前向过程中是常数(采样好了)
- 所以我们仍然可以对 μ \mu μ 和 σ \sigma σ 使用链式法则求导,反向传播不需要对 ϵ \epsilon ϵ 求导!
每次前向传播时, ϵ \epsilon ϵ 都要重新采样一次!
为什么?
在 VAE 中,我们采样的目的是从一个 随机潜在变量 z z z 中生成样本。为了能让 z z z 具有“随机性”,我们必须在每次前向传播时,从 ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0,1) ϵ∼N(0,1) 中重新采样,否则模型生成的 z z z 就是确定的了,完全失去生成模型的意义。
4. 解码与重建误差
将 z z z 输入 Decoder 得到重建样本 x ^ \hat{x} x^。再与原始输入 x x x 比较,计算重建误差:
- 若像素值为 [ 0 , 1 ] [0, 1] [0,1],常使用 二值交叉熵损失(Binary Cross Entropy):
L recon = ∑ i = 1 n [ − x i log x ^ i − ( 1 − x i ) log ( 1 − x ^ i ) ] L_{\text{recon}} = \sum_{i=1}^n \left[ -x_i \log \hat{x}_i - (1 - x_i) \log(1 - \hat{x}_i) \right] Lrecon=i=1∑n[−xilogx^i−(1−xi)log(1−x^i)]
- 若为连续实值向量(如图像灰度),可使用 均方误差(MSE):
L recon = ∑ i = 1 n ( x i − x ^ i ) 2 L_{\text{recon}} = \sum_{i=1}^n (x_i - \hat{x}_i)^2 Lrecon=i=1∑n(xi−x^i)2
VAE 的完整损失函数
VAE 的最终损失函数由两个部分组成:
L VAE = L recon + D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \mathcal{L}_{\text{VAE}} = L_{\text{recon}} + D_{KL}(q_\phi(z|x) \| p(z)) LVAE=Lrecon+DKL(qϕ(z∣x)∥p(z))
其中:
- L recon L_{\text{recon}} Lrecon:重建误差(衡量生成的 x ^ \hat{x} x^ 与 x x x 的差距)
- D K L D_{KL} DKL:先验正则化项(限制潜变量空间服从 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1))
最终优化目标:
min θ , ϕ E q ϕ ( z ∣ x ) [ − log p θ ( x ∣ z ) ] + D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \min_{\theta, \phi} \mathbb{E}_{q_\phi(z|x)}[-\log p_\theta(x|z)] + D_{KL}(q_\phi(z|x) \| p(z)) θ,ϕminEqϕ(z∣x)[−logpθ(x∣z)]+DKL(qϕ(z∣x)∥p(z))
VAE + GAN:Variational Autoencoder 与 GAN 的结合
本图展示了由 Makhzani 等人于 2015 年提出的 Adversarial Autoencoders (AAE) 架构,它结合了 Variational Autoencoder (VAE) 的编码思想与 Generative Adversarial Network (GAN) 的对抗训练机制。
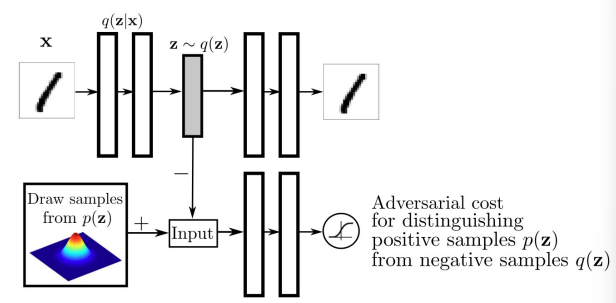
模型结构解析
1. 编码器(Encoder)
-
输入图像 x x x(如 MNIST 的手写数字图像)
-
编码器输出两个向量: z mean z_{\text{mean}} zmean 和 z log_var z_{\text{log\_var}} zlog_var
-
通过重参数技巧采样得到 z z z:
z = μ + σ ⋅ ϵ , ϵ ∼ N ( 0 , 1 ) z = \mu + \sigma \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, 1) z=μ+σ⋅ϵ,ϵ∼N(0,1)
2. 解码器(Decoder)
- 接收采样的隐变量 z z z,重建图像 x ^ \hat{x} x^
- 使用重建误差(如 CrossEntropy 或 MSE)作为训练信号
3. 判别器(Discriminator)
-
判别器用于判断隐变量 z z z 是否来自:
- 编码器生成的 q ( z ) q(z) q(z),即编码器输出的 z z z
- 还是先验分布 p ( z ) p(z) p(z),如 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)
-
编码器的目标是欺骗判别器,使 q ( z ) q(z) q(z) 与 p ( z ) p(z) p(z) 的样本无法区分,从而用 GAN 的方式逼近先验分布。
数学公式说明
图中展示了边缘分布 q ( z ) q(z) q(z) 的定义:
q ( z ) = ∫ x q ( z ∣ x ) p data ( x ) d x q(z) = \int_x q(z|x) \, p_{\text{data}}(x) \, dx q(z)=∫xq(z∣x)pdata(x)dx
即:将所有数据 x x x 编码后的隐变量 z z z 分布汇总起来形成 q ( z ) q(z) q(z)。我们希望 q ( z ) q(z) q(z) 与先验 p ( z ) p(z) p(z) 尽可能接近。
而对抗目标则是:
最小化判别器无法区分 q ( z ) q(z) q(z) 与 p ( z ) p(z) p(z) 的能力
用 GAN 代替 KL 散度进行对齐。
总结
- 传统 VAE 使用 KL 散度来匹配 q ( z ) q(z) q(z) 与 p ( z ) p(z) p(z),容易不稳定
- VAE + GAN (或 AAE) 使用判别器对抗训练,让隐空间更贴合先验分布
- 优势:
- 更高质量生成样本
- 更结构化的 latent space
- 支持复杂先验(如高斯混合)
这种结构为生成建模提供了更加稳定与表达力强的框架。