注:本人不懂Hadoop是什么,问的大模型,让它用生动浅显的语言向我解释。为了防止忘记,我把它说的记录下来。接下来的解释都是大模型生成的,如果有错误的地方欢迎指正 。
Hadoop 是什么?(一句话解释)
Hadoop 是一个开源的分布式计算框架,专门用来存储和处理海量数据(比如几百TB甚至PB级的数据),它的核心思想是:
“用一堆便宜的普通电脑,组合成一台超级计算机”。
为什么需要 Hadoop?
- 数据太大:传统数据库(如MySQL)存不下,也算不动(比如全网用户行为分析)。
- 容错性强:机器坏了数据不丢(自动备份)。
- 便宜:用普通服务器集群,不用买昂贵的高端硬件。
类比:
- 传统方式:像一个人用计算器算100万道数学题 → 慢到崩溃。
- Hadoop方式:找1万台小学生,每人算100道题 → 瞬间算完。
Hadoop 的三大核心组件
1. HDFS(分布式文件系统)
- 作用:把超大文件拆成小块,分散存储在多台机器上。
- 特点:
- 默认每块数据存3个副本(坏2台机器也不丢数据)。
- 适合“一次写入,多次读取”的场景(比如日志分析)。
示例:
- 存一个1TB的电影:HDFS会自动切成128MB的小块,存到不同机器上。
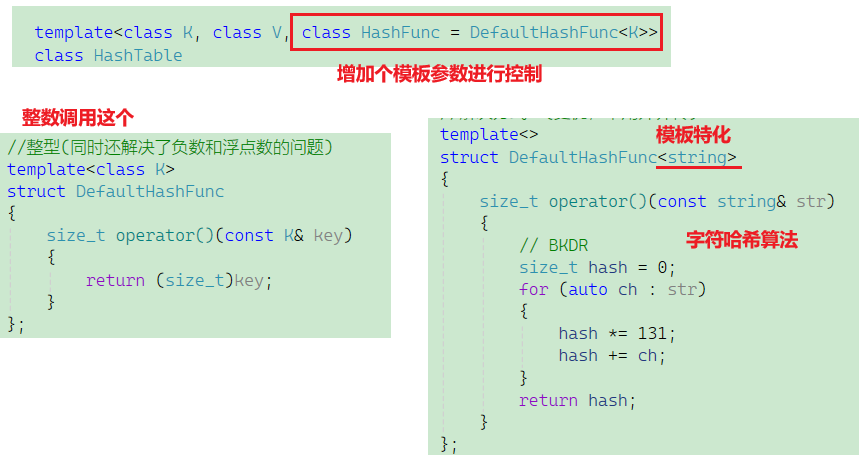
2. MapReduce(分布式计算模型)
- 作用:把计算任务拆成“Map(分任务)”和“Reduce(汇总)”两步。
- 特点:
- Map阶段:各机器并行处理自己本地数据(如统计每个文件的词频)。
- Reduce阶段:合并所有结果(如汇总总词频)。
示例:
- 统计100本书里每个单词出现的次数:
- Map:让100台机器各自统计1本书的词频。
- Reduce:把100份结果合并成最终词频表。
3. YARN(资源调度器)
- 作用:管理集群中的CPU和内存,分配任务给不同的机器。
- 类比:像公司的HR,负责把任务分配给合适的员工。
Hadoop 能做什么?
- 大数据分析(如电商分析用户行为)。
- 日志处理(如分析服务器访问日志)。
- 推荐系统(如抖音的“猜你喜欢”)。
- 数据仓库(如企业级数据存储和查询)。
典型用户:
- 互联网公司(阿里、腾讯)、银行、电信运营商等有海量数据的机构。
Hadoop 的优缺点
| 优点 | 缺点 |
|---|---|
| 可处理PB级数据 | 不适合实时计算(延迟高) |
| 成本低(普通硬件) | 配置和维护复杂 |
| 容错性强(自动恢复) | MapReduce编程模型较笨重 |
Hadoop vs 传统数据库
| 对比项 | Hadoop | MySQL/Oracle |
|---|---|---|
| 数据规模 | PB级 | TB级以下 |
| 速度 | 批量处理(分钟级) | 实时响应(毫秒级) |
| 成本 | 低(普通服务器) | 高(高端硬件) |
| 适用场景 | 离线分析、数据挖掘 | 在线交易、业务系统 |
一句话总结
Hadoop 是用一堆便宜电脑合力处理海量数据的工具,适合“离线、大规模、容错性强”的场景,但学习成本较高,现在很多公司也在用更简单的替代方案(如Spark)。
面试回答示例:
“Hadoop 是一个分布式系统框架,核心通过 HDFS 存储数据、MapReduce 处理数据、YARN 调度资源,解决单机无法处理的大数据问题,比如电商用户行为分析或日志存储。”
![【拓扑排序】P6560 [SBCOI2020] 时光的流逝|普及+](https://i-blog.csdnimg.cn/direct/0e13f43eeb0f44a195135eee0d1801bf.png)